










数据清洗
- 赋值:
#Nan值
data.fillna(values,method = 'ffill/bfill','axis=0/1')values: 可以使用标量,变量,方法,字典等
method = 'ffill' 补充行/列的前一个值,method = 'bfill' 补充行/列的后一个值
axis默认为0,按行处理,axis = 1 按列处理
实例:
method = 'ffill':
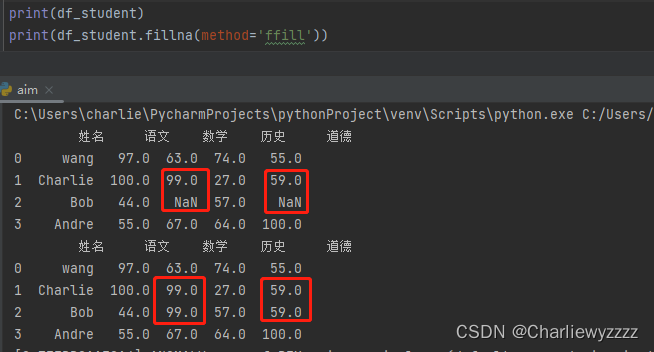
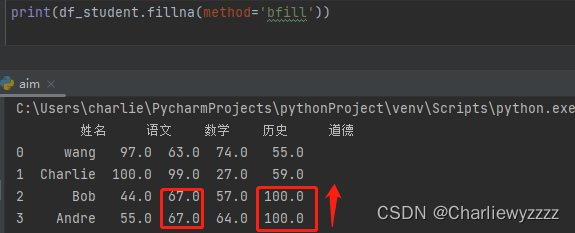
method = 'bfill' :
- 删除:
- Nan值:
#Nan值
df.dropna(how='any/all', axis = 0/1)
how = any: 行/列中任意值为Nan,删除整行/列,how = all: 行/列中所有值为Nan,删除整行/列
实例:
how = 'all' :
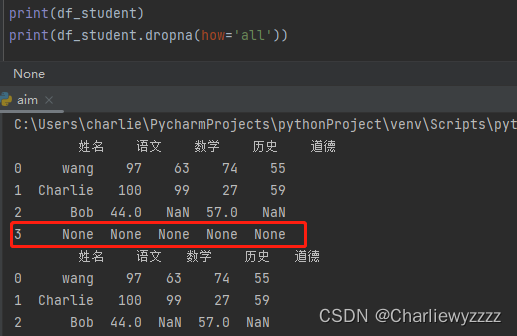
how = 'any':

- 删除重复值:
#重复值
df.drop_duplicates(keep = 'first/last')
keep 默认为first,保留第一个观测值,keep = 'last' 保留最后一个观测值
- 替换:
df.replace('查找值','替换值')值的类型:可为列表/标量/字典等
数值格式:
df[item] = df[item].astype('float') 数据筛选
- 索引筛选
#iloc筛选
df.iloc[:10,:8] #筛选0-9行,0-7列的数据的数据
#loc筛选
df.loc[:10,:8] #筛选行索名称引为0-9,列索引名称为0-7的数据
实例:
iloc根据数剧列实际的位置进行筛选:
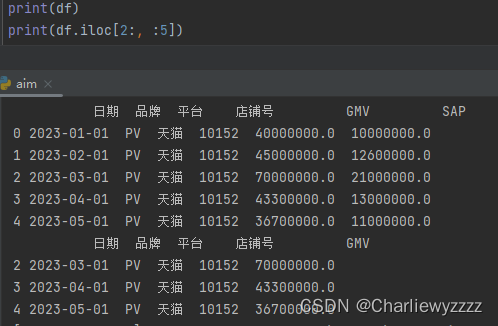
loc根据行列对应的名称进行筛选:
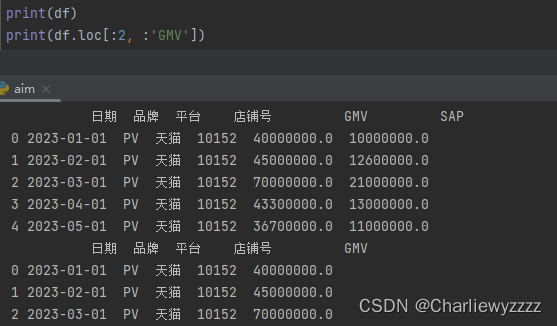
注:":"代表全部数据,:2代表2行/列以前的全部数据,2:代表2行/列以后的全部数据
- 精确查找
loc+条件:
#isin筛选
df[df['item1'].isin(['condition1','condition2'])]
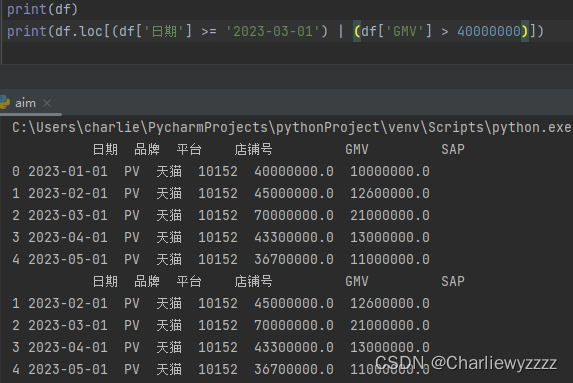
#loc筛选+条件(或)
df.loc[(df[item1] == 'condition1')|(df[item1] == 'conditon2')]
#loc筛选+条件(且)
df.loc[(df[item1] == 'condition1')&(df[item1] == 'conditon2')]
实例:
loc+条件中:“&”是并的关系

loc+条件中"|”是并的关系
query条件筛选:
#query筛选
df.query('colume1 == ["condition1","condition2"]')
df.query('colume1 == "condition1" or colume1 == "condition2"')
实例:
单一字段多条件筛选:

多字段多条件筛选:

'or'为或的关系,可以替换为'and'且的关系
注:query函数中需要注意条件需要用 ' ' 括起来,中间的文本条件需要用 " " 括起来
- 模糊查找
#模糊筛选
#1.类似SQL中like'%string1%'
df.loc[df[item1].str.contains('string1'|'string2')]
#2.类似SQL中like'string1%'
df.loc[df[item1].str.startwith('string1')]
#3.类似SQL中like'%string1'
df.loc[df[item1].str.endwith('string1')]
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











