







🧡💛💚💙💜OpenCV实战系列总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在Pycharm中进行
本篇文章配套的代码资源已经上传
中篇内容:
openCV实战-系列教程13:文档扫描OCR识别中(图像轮廓/模版匹配)项目实战、源码解读
下篇内容:
openCV实战-系列教程14:文档扫描OCR识别下(图像轮廓/模版匹配)项目实战、源码解读
1、运行效果演示
项目界面:

1.1 输入参数
在运行参数配置界面输入以下指令即可运行
--image ./images/receipt.jpg
2023版pycharm配置运行参数教程
新版本openCV中的cv2.findContours返回值从3个变成了两个
通过修改参数receipt.jpg,可以处理其他的图像数据。
1.2 整体流程与效果
运行打印结果:
C:\Users\Alex\anaconda3\envs\CV\python.exe A:\2_gupao\ocr\scan.py --image ./images/receipt.jpg
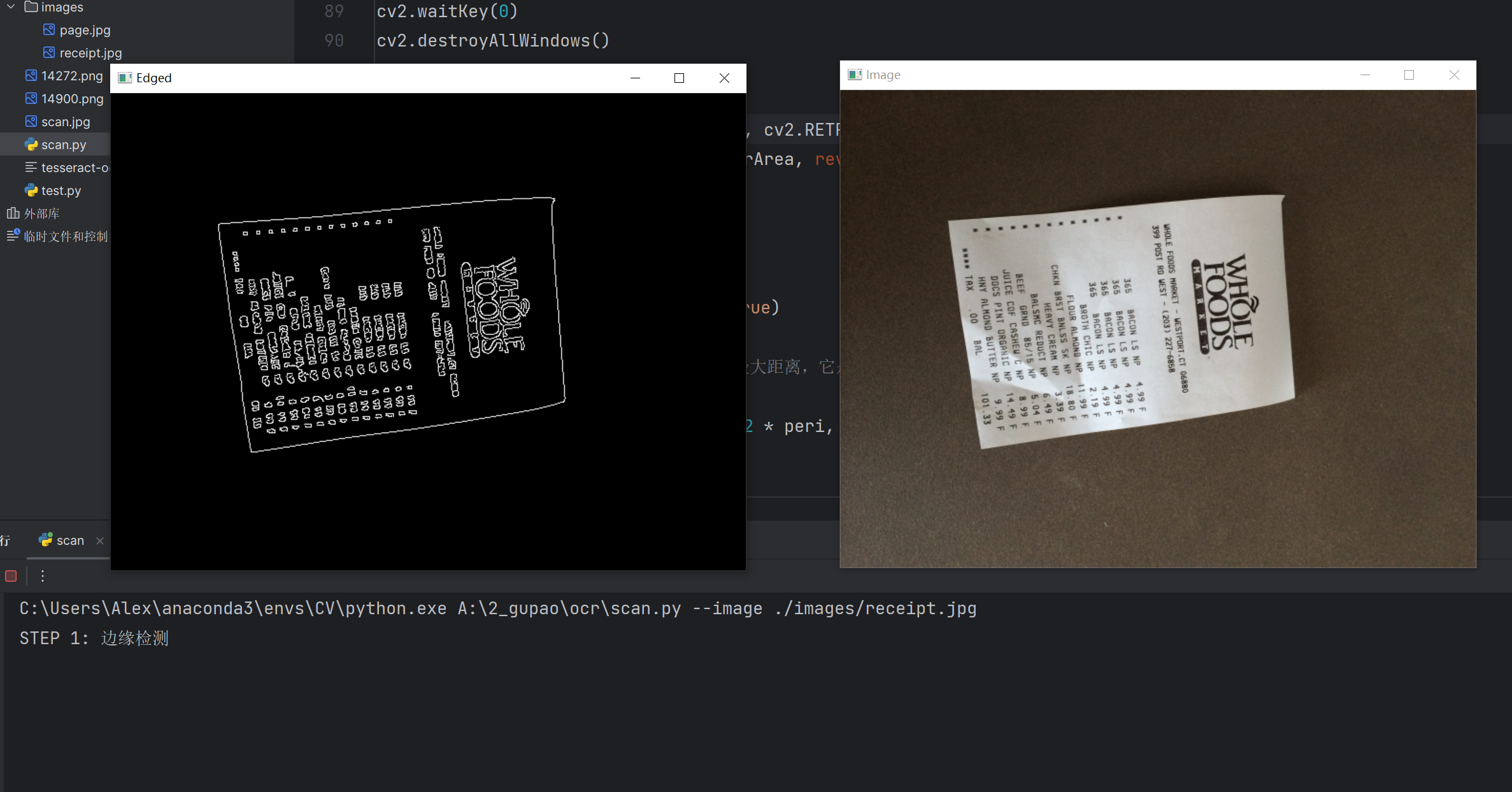
STEP 1: 边缘检测
STEP 2: 获取轮廓
STEP 3: 变换
进程已结束,退出代码为 0
原始图像是一张购物小票,是从任意角度拍摄的,需要把这个小票调整到一个正确的角度,然后才能进行文字识别。第一步需要进行边缘检测,得到这个小票。
第二步框出这个小票,这个框起来的过程就是一个轮廓检测。

第三张就需要把这个小票放正了,整齐的排列出来,才能识别出里面的文字,做字符识别的操作。

第四步将这个小票的内容的文字识别出来,即OCR文字识别。
2、图像读取与处理
2.1 数据读取
读取输入
image = cv2.imread(args["image"])
ratio = image.shape[0] / 500.0
orig = image.copy()
image = resize(orig, height=500)
- 读取图像
- image.shape[0]是原始图像高,500是等下需要resize的高,保存这个比例,因为后续需要对原始图像进行处理,这个时候需要获取这个比例值
- 深度复制原始图像
- resize原始图像,设置高为500,宽会自动根据比例计算给出,这里的resize函数是我自己写的,主要是通过给定的h,安装原始的长宽比例计算出宽,再用openCV的resize函数(cv2.resize)
2.2 预处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(gray, 75, 200)
print("STEP 1: 边缘检测")
cv2.imshow("Image", image)
cv2.imshow("Edged", edged)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 原始图像灰度处理
- 高斯滤波,过滤一些干扰噪声
- 边缘检测
- 打印文字
- 打印原始图像
- 打印边缘检测图像
- 等待按任意键
- 关闭所有窗口
打印结果:


STEP 1: 边缘检测
3、轮廓检测
3.1 获取轮廓
cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5]
for c in cnts:
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
if len(approx) == 4:
screenCnt = approx
break
- 获取轮廓,edged.copy()深度复制图像,RETR_LIST检索所有的轮廓,并将其保存到一条链表当中,CHAIN_APPROX_SIMPLE轮廓逼近方法,获取第一个返回值,全部轮廓
- 排序轮廓,这个函数是我自己写的(解析参考这个教程3.3),取出前5个轮廓,因为根据任务不同可能有多个复合的轮廓,比如有三张小票
- 遍历每一个轮廓
- 计算当前轮廓周长
- 计算近似轮廓,实际中的轮廓可能是一些点组成的,因为不规则的轮廓即拟合出大量的点,根据周长百分比0.02 * peri来近似轮廓,这个值设置的大近似出的轮廓可能就是多边形,小可能就是矩形或者三角形
- 如果点数是四就是矩形
- 如果是矩形,就是我们想要的轮廓,因为小票的轮廓最好是一个矩形,保存这个轮廓
- break
3.2 画出轮廓
print("STEP 2: 获取轮廓")
cv2.drawContours(image, [screenCnt], -1, (0, 255, 0), 2)
cv2.imshow("Outline", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
打印结果:
- 打印文字
- 画出轮廓,参数分别是原始图像、轮廓信息、全部轮廓、轮廓颜色、轮廓线条粗细
- 打印轮廓图像
STEP 2: 获取轮廓

4 顶点排序函数
我们有A、B、C、D四个点,组成一个不规整的四边形,现在通过下面这个函数,将这四个点的顺序调整到合适的顺序,调整后的结果方便我们把四个点映射成规整的矩形的四个点
def order_points(pts):
rect = np.zeros((4, 2), dtype="float32")
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
- pts是一个存放原始数据的二维list,一共有4个元素,分别对应ABCD四个点,然后每个元素对应两个值,分别是横坐标和纵坐标。
- 构造一个名为rect 结构和pts一样的二维list,里面全部存放0
- 把pts的每个点的横纵坐标加起来,保存一个名为s的有4个元素的list,每个元素分别为A、B、C、D四个点的坐标之和
- 求出s最小数对应的索引对应在pts的点的两个坐标值,作为rect 的第1个点的两个坐标
- 求出s最大数对应的索引对应在pts的点的两个坐标值,作为rect 的第3个点的两个坐标
- 把pts的每个点的纵坐标减去横坐标,保存一个名为diff 的有4个元素的list,每个元素分别为A、B、C、D四个点的坐标之差
- 求出diff最小数对应的索引对应在pts的点的两个坐标值,作为rect 的第2个点的两个坐标
- 求出diff最大数对应的索引对应在pts的点的两个坐标值,作为rect 的第4个点的两个坐标
- 返回rect
中篇内容:
openCV实战-系列教程13:文档扫描OCR识别中(图像轮廓/模版匹配)项目实战、源码解读
下篇内容:
openCV实战-系列教程14:文档扫描OCR识别下(图像轮廓/模版匹配)项目实战、源码解读
















 2111
2111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











