







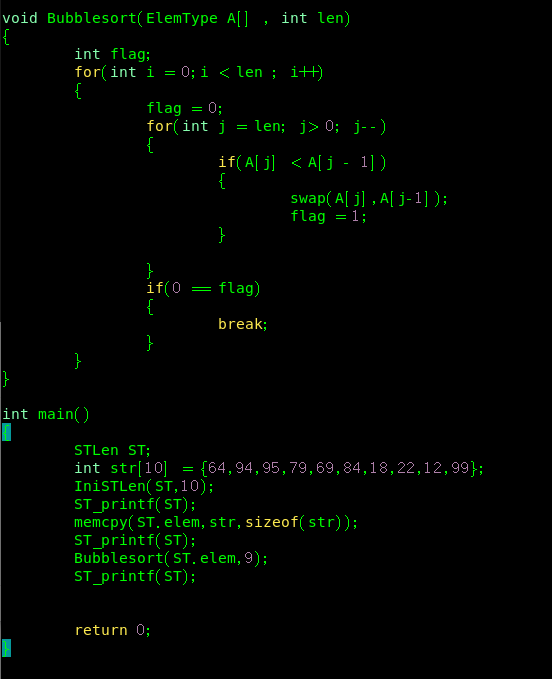
一、交换排序
1.冒泡排序
对于冒泡排序的理解有问题,它不是只针对最后一个元素进行依次交换,而是针对所有元素,相当于第一遍从最后一个元素遍历到第一个元素,第二遍从倒数第二个元素遍历到第一个元素,依次如此
上机测试
一遍过,没有问题
2.快速排序
(挖坑法与交换法对比)
下面两个代码分别是挖坑法和交换法:

以最左边作为分隔值,而交换法则是以最右边作为分隔值
发现一个问题,这个的前题条件是low和hight,它是代表着数组的空间位置,并不是数组中的数据
所以low刚开始一定是小于hight的
两者最本质的区别就是,挖坑法需要设置一个单独的坑,也就是一个整形,来存放我们用来标定的值(如最左边的值),而交换法,无需这一步,只需要右边不动,左边不断进行交换(方法是设置一个k和一个i,不断加1,与右边的值比较)。当然也可以反过来。
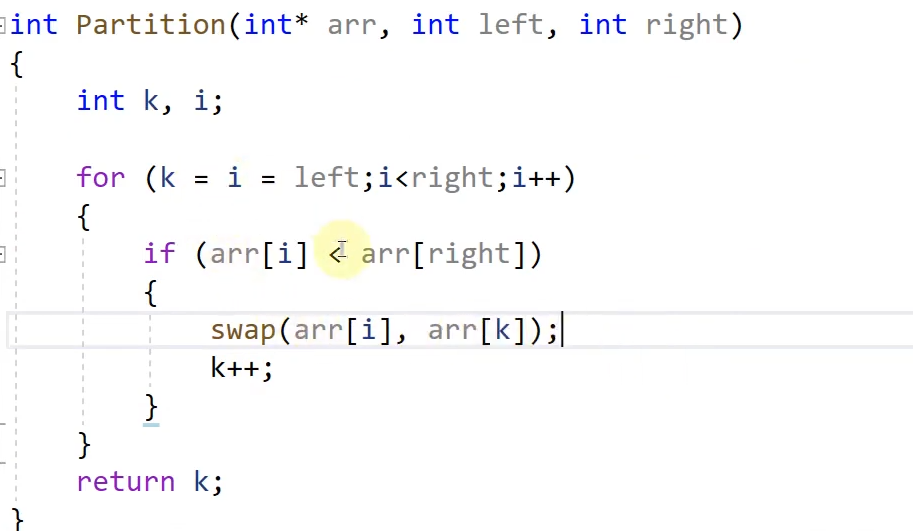
(1).交换法
两个单词的学习 partition (分隔) pivot point(枢纽点)
首先,这个代码的关键在于partition 也就是分隔,必须要找到分隔的这个位置,我们设为k
首先我们先确定他的low和high 也就是数组的最小下标和最大下标,low<high 时开始循环
然后我们就要找枢纽点,就是中间的那个位置,此时就是交换法与挖坑法的根本区别,交换法是直接确定数组最后一个位置为枢纽点的值,然后利用i(从数组第一位到最后一位遍历)利用循环让i与枢纽点不断比较,若是i小,那么就让i与k进行交换,因为我们最后要从小到大排序,(k一开始与i相同,只有当交换后才进行+1),
当i等于最右边的位置时(i = right),这时则不再循环,返回到qsort函数中,继续再一次调用**qsort*(因为我们不止排一次,我们要排好几次,直到数据从小到大有序);(递归)
上机测试
这个代码问题大了
首先这个代码要有三个函数值,我一开始感觉不需要第二个也可以,这儿的问题是没有理解递归,这儿递归调用自己本身,一开始认为调用的是partition,脑子有点不在线,注意递归一定是用if绝对不可以用while
然后partition函数只有小于最右边的值,这时我们才交换,也就是做到从小到大的顺序。
最后,其实我感觉很简单
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6060
6060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









