







15.5.5 数据存储
1. 列式存储
-
理解
- 数据文件以分区目录的形式被组织存放,所以在
.bin文件中只会保存当前分区片段内的这一部分数据 - 在MergeTree中,数据按列存储。而具体到每个列字段,数据也是独立存储的,每个列字段都拥有一个与之对应的.bin数据文件。也正是这些.bin文件,最终承载着数据的物理存储
- 数据文件以分区目录的形式被组织存放,所以在
-
列式存储的优势
- 更好地进行数据压缩
- 能够最小化数据扫描的范围
-
存储方式
- 数据是经过压缩的,目前支持LZ4、ZSTD、Multiple和Delta几种算法,默认使用LZ4算法;
- 其次,数据会事先依照ORDER BY的声明排序;
- 最后,数据是以压缩数据块的形式被组织并写入.bin文件中的
2. 数据压缩
-
压缩数据组成
一个压缩数据块由头信息和压缩数据两部分组成,bin压缩文件是由多个压缩数据块组成的,而每个压缩数据块的头信息则是基于CompressionMethod_CompressedSize_UncompressedSize公式生成的
- 头信息
- 固定使用9位字节表示,具体由1个UInt8(1字节)整型和2个UInt32(4字节)整型组成
- 分别代表使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小
- 压缩数据
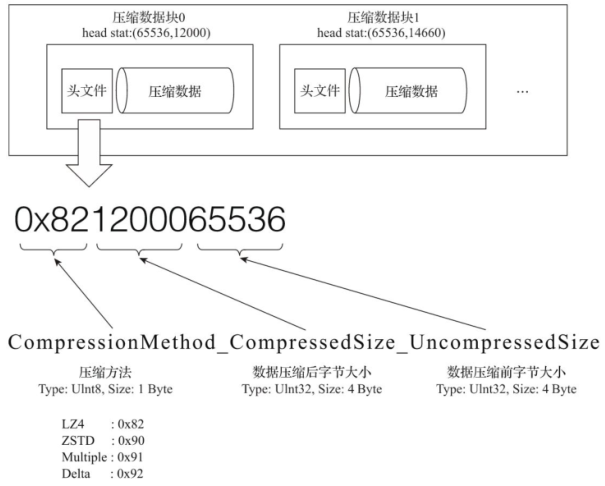
- 头信息
-
压缩数据块的体积
- 每个压缩数据块的体积,按照其压缩前的数据字节大小,都被严格控制在64KB~1MB
- 其上下限分别由min_compress_block_size(默认65536)与max_compress_block_size(默认1048576)参数指定。
- 而一个压缩数据块最终的大小,则和一个间隔(index_granularity)内数据的实际大小相关
-
数据写入过程
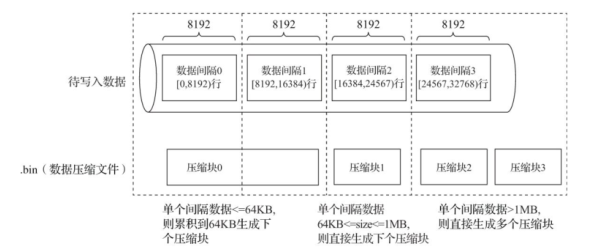
- MergeTree在数据具体的写入过程中,会依照索引粒度(默认8192行),按批次获取数据并进行处理
- 单个批次数据 size<64KB:
- 继续获取下一批数据,直至累积到size>=64KB时,生成下一个压缩数据块
- 单个批次数据 64KB<=size<=1MB
- 直接生成下一个压缩数据块
- 单个批次数据size>1MB
- 首先按照1MB大小截断并生成下一个压缩数据块,剩余数据继续依照上述规则执行
-
数据压缩的优势
-
数据被压缩后能够有效减少数据大小,降低存储空间并加速数据传输效率
- 但是压缩和解压的同时也会带来额外的性能损耗,所以要控制被压缩数据的大小,以求在性能损耗和压缩率之间寻求一种平衡。
-
在具体读取某一列数据时(.bin文件),首先需要将需要的压缩数据加载到内存并解压,这样才能进行后续的数据处理,通过压缩数据块,可以在不读取整个
.bin文件的情况下将读取粒度降低到压缩数据块级别,从而进一步缩小数据读取范围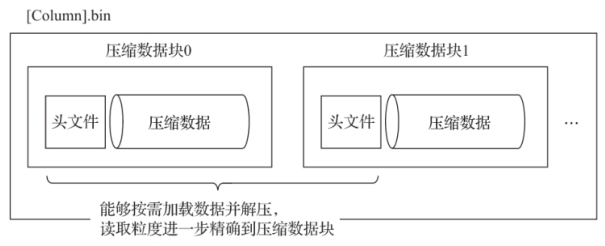
-
15.5.6 数据标记
-
定义
- 数据标记作为衔接一级索引和数据的桥梁,像极了书签,而且书本总每一个章节目录都有各自的书签
-
理解数据标记
-
如果把 MergeTree 比作一本书,primary.idx(一级索引)就类似书的一级章节目录,但是这个目录具体对应书中( .bin 文件)的哪一页呢?

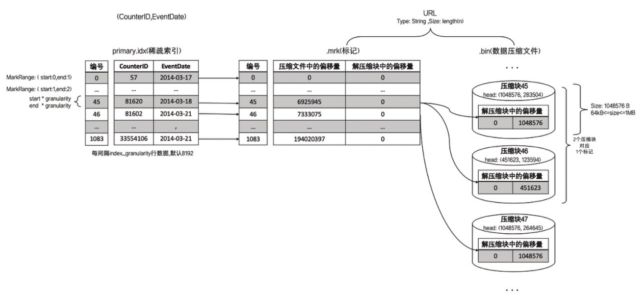
显然每个目录后面的页码会告诉你,该目录位于书中的哪一页,而页码就相当于数据标记文件(.mrk)中记录的偏移量(数据标记),标记索引在数据文件中的具体位置。因此对于数据标记文件而言,它记录了两点关键信息:
1. 与一级章节目录对应的页码信息2. 一段文字在某一页中的起始位置信息
这样一来,通过数据标记文件可以很快地从一本书中立即翻到关注内容所在的那一页,并知道从第几行开始阅读。
-
1. 生成规则
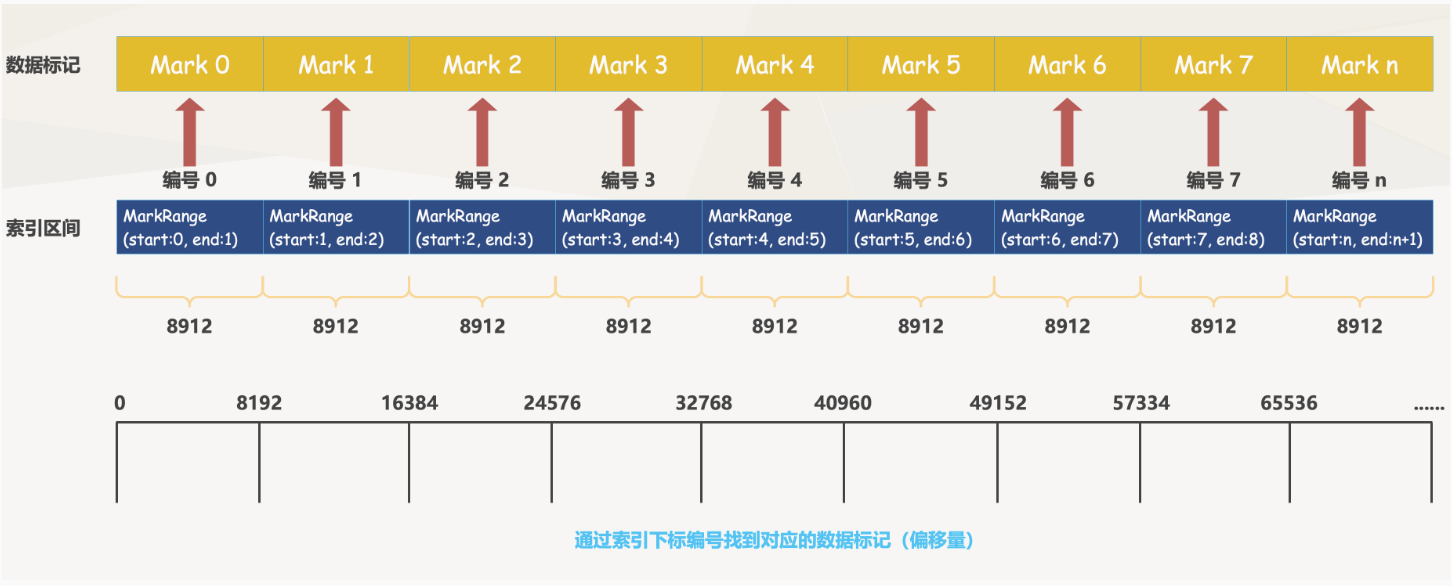
- 数据标记和索引区间是对齐的,均按照index_granularity的粒度间隔
- 只需要简单通过索引下标编号即可直接找到对应的数据标记
- 为了能够与数据衔接,
.bin文件和数据标记文件是一一对应的- 即每一个
[Column].bin文件都有一个[Column].mrk数据标记文件与之对应,用于记录数据在.bin文件中的偏移量信息
- 即每一个
-
一行标记数据使用一个元组表示,元组内包含两个整型数值的偏移量信息,分别表示在此段数据区间内:
-
对应 .bin 压缩文件中,压缩数据块的起始偏移量
-
将该数据块解压缩后,未压缩数据的起始偏移量
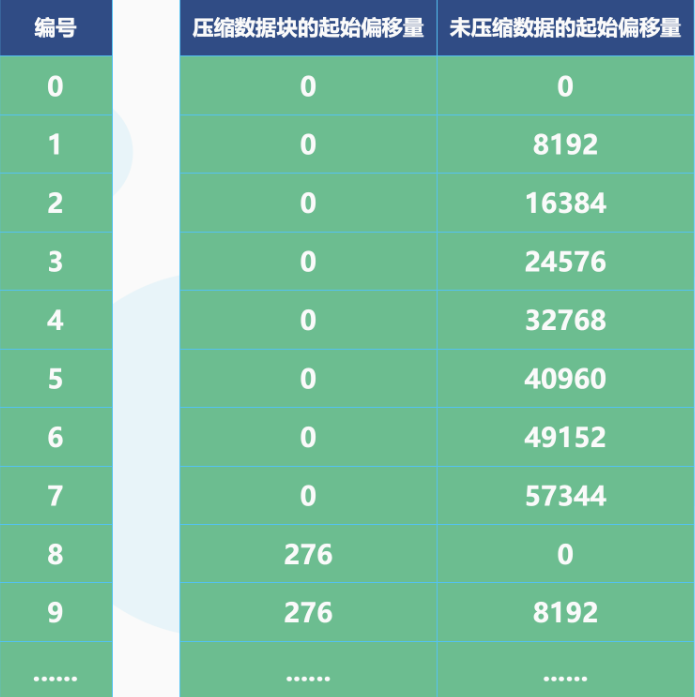
-
对于上图的解释:
每一行标记数据都标记了一个片段的数据(默认 8192 行)在 .bin 压缩文件中的读取位置信息,因为 Age 占 1 字节,所以每次读取 8912 行相当于每次读取 8192 个字节,因此 “未压缩数据的起始偏移量” 就是 0、8192、16384、24576、…。但是需要注意图中的 57344,它表示第 8 批未压缩数据的起始偏移量,因为此时已经达到了 64KB,所以会生成一个压缩数据块,于是接下来读取第 9 批未压缩数据的时候就会对应新的压缩数据块,因此起始偏移量会重置为 0,而不是 65536。
我们这里是 Age 字段为例,至于其它列也是同理,只不过由于每一行字符串的长度不同,所以我们很难计算每次读 8192 行的话会读多少个字节,但它们的原理是很明显都是一样的。
然后是 “压缩数据块的起始偏移量”,因为读了 8 批才生成了第一个压缩数据块,因此前 8 行都是 0。然后由于第一个压缩数据块的大小是 276,因此第 9 行、即索引为 8 的位置,存储的值就是 276,表示第二个压缩数据块的起始偏移量
- 标记数据的存储
- 每一行标记数据都表示了一个片段的数据(默认8192行)在.bin压缩文件中的读取位置信息。标记
数据与一级索引数据不同,它并不能常驻内存,而是使用LRU(最近最少使用)缓存策略加快其取
用速度
- 每一行标记数据都表示了一个片段的数据(默认8192行)在.bin压缩文件中的读取位置信息。标记
2. 工作方式
MergeTree 在读取数据时,必须通过标记文件中的偏移量才能找到所需要的数据,因此整个查找过程可以分为读取压缩数据块和读取数据两个步骤
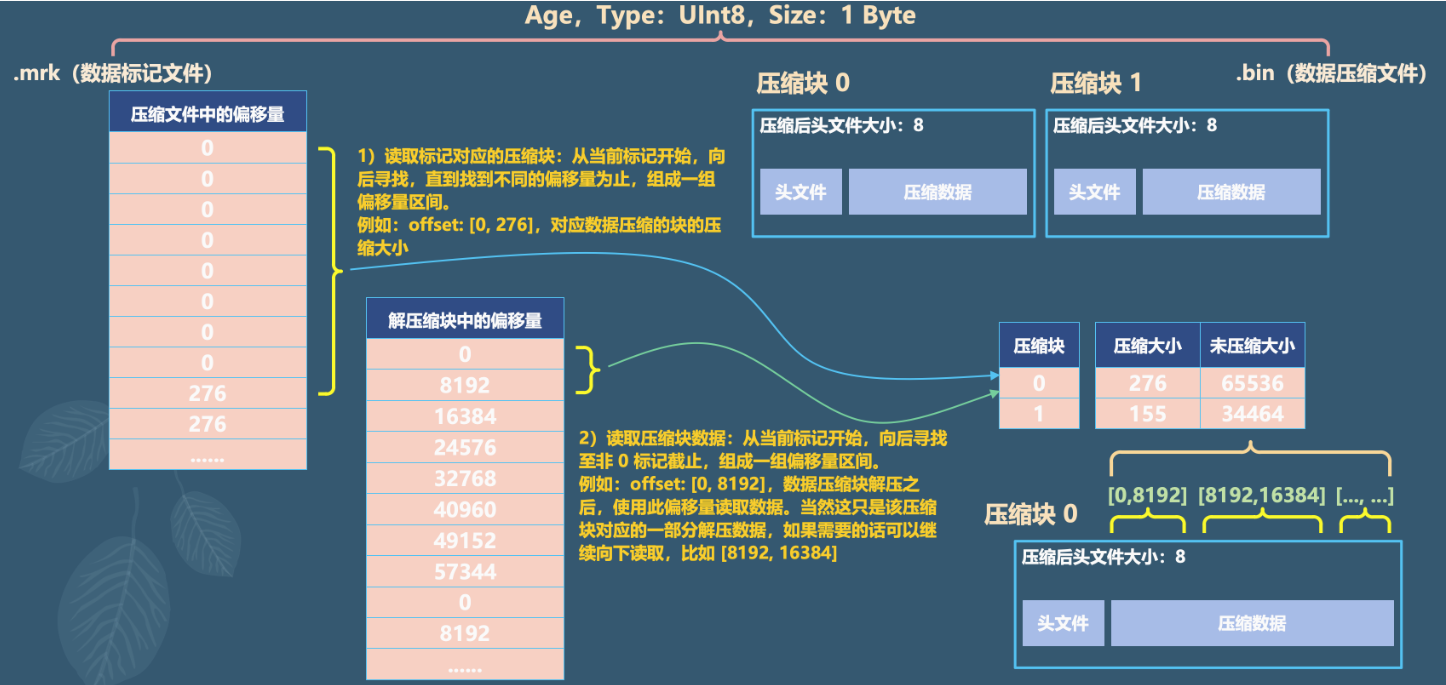
- 读取压缩数据块
- 在查询某一列数据时,MergeTree无需加载整个
.bin文件,而是可以根据需要只加载特定的压缩数据块,而这向特性则要借助.mrk文件中所保存的偏移量信息 - 从图中可以看到,上下相邻的两个压缩数据块的起始偏移量,构成了与当前标记对应的压缩数据块的偏移量区间,说人话就是通过第 n 个压缩数据块的起始偏移量和第 n + 1 个压缩数据块的起始偏移量,可以获取第 n 个压缩数据块。具体做法就是从当前偏移量开始向下寻找(当前块的起始位置 start),直到找到不同的偏移量位置(当前块的下一个块的起始位置 next_start),此时 start 到 next_start 便是当前块对应的偏移量区间,比如图中的 0 到 276。通过偏移量区间,即可获得当前的压缩块
- 在查询某一列数据时,MergeTree无需加载整个
- 读取数据
- 在读取解压后的数据时,MergeTree 并不需要一次性扫描整段解压数据,它可以根据需要,以 index_granularity 的粒度加载特定的一小段,而为了实现这种特性,需要借助标记文件中保存的解压数据块的偏移量。
- 通过偏移量,ClickHouse 可以按需读取数据,比如通过 [0, 8192] 即可读取压缩数据块 0 中第一个数据片段对应的解压数据
15.5.7 数据标记与数据压缩关系
由于压缩数据块的划分,与一个间隔(index_granularity)内的数据大小相关,每个压缩数据块的体积都被严格控制在64KB~1MB。而一个间隔(index_granularity)的数据,又只会产生一行数据标记。那么根据一个间隔内数据的实际字节大小,数据标记和压缩数据块之间会产生三种不同的对应关系。
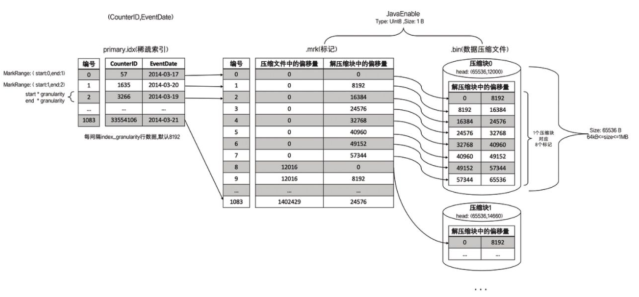
1. 多对一
-
理解
-
多个数据标记对应一个压缩数据块
-
当一个间隔(index_granularity) 内的数据为压缩大小 size<64KB时,会出现这种对应关系
-
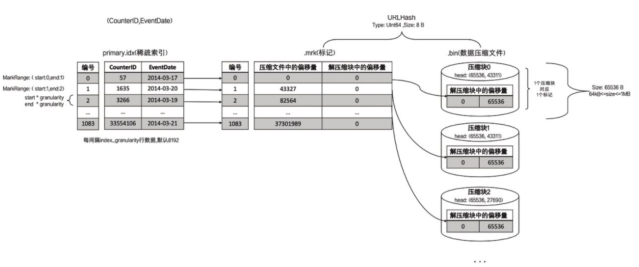
2. 一对一
-
理解
- 一个数据标记对应一个压缩数据块
- 当一个间隔(index_granularity)内的数据未压缩大小size小于64KB时,会出现这种对应关系
3. 一对多
-
理解
- 一个数据标记对应多个压缩数据块
- 当一个间隔(index_granularity)内的数据未压缩大小size直接大于1MB时,会出现这种对应关系
15.5.8 数据读写流程⭐️
分区、索引、标记和压缩数据,就类似于 MergeTree 的一套组合拳,使用恰当的话威力无穷。那么在依次介绍了各自的特点之后,现在将它们聚在一起总结一下
1. 写入数据
-
生成分区目录,并在后续进行合并相同分区目
- 数据写入的第一步是生成分区目录,伴随着每一批数据的写入,都会生成一个新的分区目录。在后续的某一时刻,属于相同分区的分区目录会被合并到一起
-
生成一级索引、压缩数据文件、数据标记文件
- 紧接着按照 index_granularity 索引粒度,会分别生成 primary.idx 一级索引(如果声明了二级索引,还会创建二级索引文件)、每一个列字段的压缩数据文件(.bin)和数据标记文件(.mrk),如果数据量不大,则是 data.bin 和 data.mrk 文件。
-
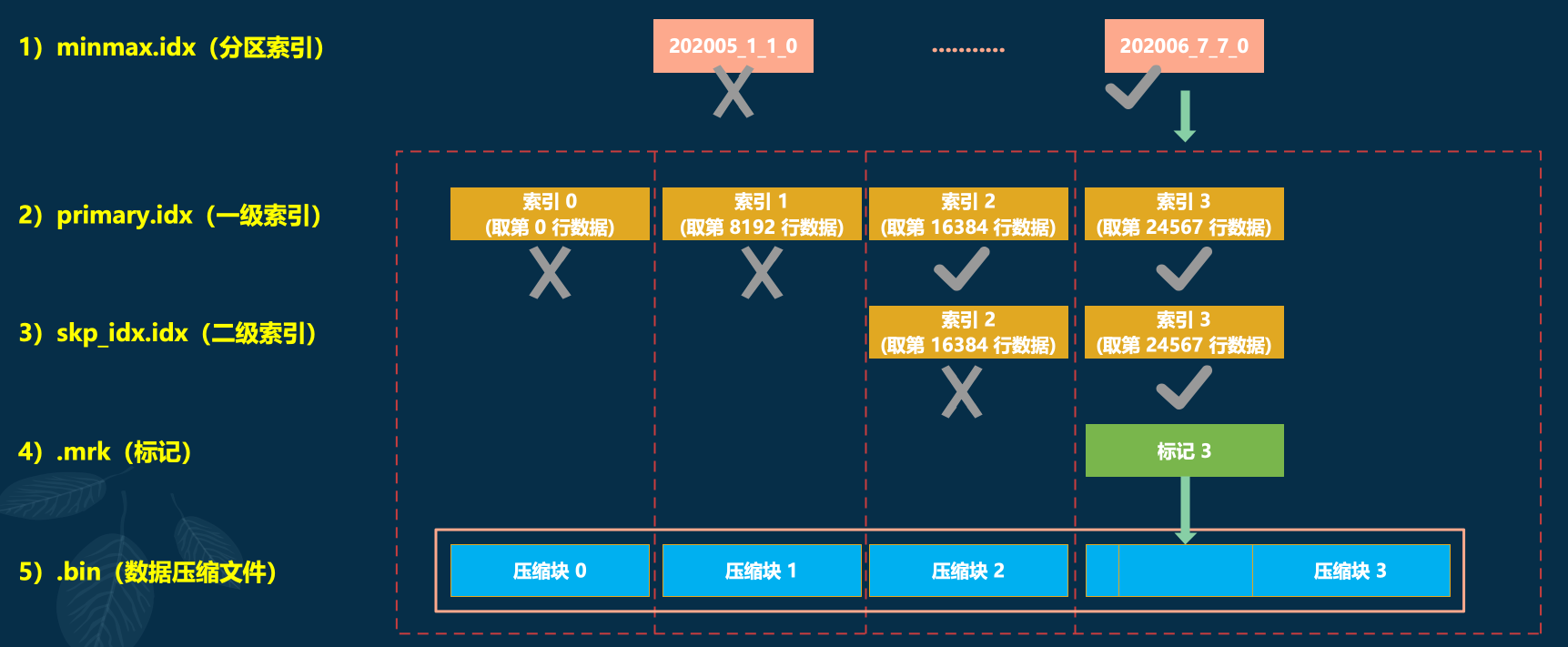
MergeTree表在写入数据时的分区目录、索引、标记和压缩数据的生成图解

从分区目录 202006_1_34_3 能够得知,该分区数据总共分 34 批写入,期间发生过 3 次合并。
在数据写入的过程中,依据 index_granularity 的粒度,依次为每个区间的数据生成索引、标记和压缩数据块。其中索引和标记区间是对齐的,而标记与压缩块则是根据区间大小的不同,会生成多对一、一对一、一对多的关系
2. 查询数据
-
本质
- 数据查询的本质,可以看作一个不断减小数据范围的过程
-
过程简述
- 在最理想的情况下,MergeTree首先可以依次借助分区索引、一级索引和二级索引,将数据扫描范围缩至最小。然后再借助数据标记,将需要解压与计算的数据范围缩至最小
-
查询数据图解
🚩Day26-ClickHouse 的使用
重点掌握
1、掌握Clickhouse的MergeTree的数据读写流程
2、掌握Clickhouse中MergeTree的6个变种表引擎的使用场景
3、掌握Clickhouse的数据查询的操作语法理解内容
1、Clickhouse的MergeTree之列式存储与数据压缩 -24
2、Clickhouse的MergeTree之数据标记的生成与使用方式 -25~26
3、Clickhouse的MergeTreeFamily之多路径存储 -30
4、Clickhouse的外部存储引擎 -36~39
5、Clickhouse的内存类型引擎 -40~42
6、Clickhouse的日志类型引擎 -43~45
15.6 MergeTree Family⭐️
15.6.1 MergeTree
1. 数据TTL
2. 多路径存储策略
-
19.15版本之前
- MergeTree只支持单路径存储,所有的数据都会被写入config.xml配置中path指定的路径下,即使服务器挂载了多块磁盘,也无法有效利用这些存储空间
-
19.15版本开始
- MergeTree实现了自定义存储策略的功能,支持以数据分区为最小移动单元,将分区目录写入多块磁盘目录
-
存储策略
- 默认策略:
- MergeTree原本的存储策略,无须任何配置,所有分区会自动保存到config.xml配置中path指定的路径下
- JBOD策略:
- 这种策略适合服务器挂载了多块磁盘,但没有做RAID的场景。
- JBOD的全称是Just a Bunch of Disks,它是一种轮询策略,每执行一次INSERT或者MERGE,所产生的新分区会轮询写入各个磁盘。
- HOT/COLD策略:
- 这种策略适合服务器挂载了不同类型磁盘的场景。
- 将存储磁盘分为HOT与COLD两类区域。
- HOT区域使用SSD这类高性能存储媒介,注重存取性能;
- COLD区域则使用HDD这类高容量存储媒介,注重存取经济性。
- 数据在写入MergeTree之初,首先会在HOT区域创建分区目录用于保存数据,当分区数据大小累积到阈值时,数据会自行移动到COLD区域
- 默认策略:
-
配置方式
- 存储配置需要预先定义在config.xml配置文件中,由storage_configuration标签表示
- 在storage_configuration之下又分为disks和policies两组标签,分别表示磁盘与存储策略
<storage_configuration> <disks> <disk_name_a> <!--自定义磁盘名称 --> <path>/chbase/data</path><!—磁盘路径 --> <keep_free_space_bytes>1073741824</keep_free_space_bytes> </disk_name_a> <disk_name_b> <path>… </path> <keep_free_space_bytes>...</keep_free_space_bytes> </disk_name_b> </disks> <policies> <default_jbod> <!--自定义策略名称 --> <volumes> <jbod> <!—自定义名称 磁盘组 --> <disk>disk_name_a</disk> <disk>disk_name_b</disk> </jbod> </volumes> </default_jbod> </policies> </storage_configuration>
15.6.2 ReplacingMergeTree
-
产生背景
- MergeTree拥有主键,但是它的主键却没有唯一键的约束。这意味着即便多行数据的主键相同,它们还是能够被正常写入。
- ReplacingMergeTree就是在这种背景下为了数据去重而设计的,它能够在合并分区时删除重复的数据
-
以分区为单位删除重复数据
- 只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除。
- 如果要求主键完全不重复,那么这张表就不能分区
-
操作方式
-
ENGINE = ReplacingMergeTree(ver)- ver是选填参数,会指定一个UInt*、Date或者DateTime类型的字段作为版本号。这个参数决定了数据去重时所使用的算法
--排序键ORDER BY所声明的表达式是后续作为判断数据是否重复的依据。 --如果没有设置ver版本号,则保留同一组重复数据中的最后一行。 CREATE TABLE replace_table( id String, code String, create_time DateTime )ENGINE = ReplacingMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY (id,code) PRIMARY KEY id -- 2021-05_1_1_0 insert into replace_table select number%10 ,'code', '2021-05-01' from numbers(20); -- 2021-05_2_2_0 insert into replace_table select number%10 ,'code', '2021-05-03' from numbers(20); -- 2021-05_1_2_1 optimize table replace_table final; -- 2021-06_3_3_0 insert into replace_table select number%10 ,'code', '2021-06-01' from numbers(20); -- 2021-07_4_4_0 insert into replace_table select number%10 ,'code', '2021-07-01' from numbers(20); -- 2021-07_5_5_0 insert into replace_table select number%10 ,'code', '2021-07-03' from numbers(20); -- 2021-05_1_2_2 -- 2021-06_3_3_1 optimize table replace_table final; select * from replace_table; --基于id字段去重,并且使用create_time字段作为版本号 --删除重复数据的时候,会保留同一组数据内create_time时间最大的那一行 CREATE TABLE replace_table_v( id String, code String, create_time DateTime )ENGINE = ReplacingMergeTree(create_time) PARTITION BY toYYYYMM(create_time) ORDER BY id
-
15.6.3 SummingMergeTree
-
产生背景
- 终端用户只需要查询数据的汇总结果,不关系明细数据,并且数据的汇总条件是预先明确的(GROUP BY条件明确,且不会随意改变)
-
原始解决方案 :通过GROUP BY聚合查询,并利用SUM聚合函数汇总结果
- 存在额外的存储开销:终端用户不会查询任何明细数据,只关心汇总结果,所以不应该一直保存所有的明细数据。
- 存在额外的查询开销:终端用户只关心汇总结果,虽然MergeTree性能强大,但是每次查询都进行实时聚合计算也是一种性能消耗。
-
SummingMergeTree就是为了应对这类查询场景而生的。
- 它能够在合并分区的时候按照预先定义的条件聚合汇总数据,将同一分组下的多行数据汇总合并成一行
- 这样既减少了数据行,又降低了后续汇总查询的开销。
-
操作方式
CREATE TABLE summing_table( id String, city String, v1 UInt32, v2 Float64, create_time DateTime )ENGINE = SummingMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY (id, city) PRIMARY KEY id insert into summing_table select '1','上海',1,1.0,'2021-05-01' from numbers(100); insert into summing_table select '2','广州',1,1.0,'2021-05-01' from numbers(100); insert into summing_table select '3','武汉',1,1.0,'2021-05-01' from numbers(100); insert into summing_table select '1','上海',1,1.0,'2021-05-01' from numbers(100); optimize table summing_table final; select * from summing_table; --用ORBER BY排序键作为聚合数据的条件Key --只有在合并分区的时候才会触发汇总的逻辑 --以数据分区为单位来聚合数据。当分区合并时,同一数据分区内聚合Key相同的数据会被合并汇 总,而不同分区之间的数据则不会被汇总。 --如果在定义引擎时指定了columns汇总列,则SUM汇总这些列字段;如果未指定,则聚合所有非 主键的数值类型字段。 --在进行数据汇总时,因为分区内的数据已经基于ORBER BY排序,所以能够找到相邻且拥有相同 聚合Key的数据。 --在汇总数据时,同一分区内,相同聚合Key的多行数据会合并成一行。其中,汇总字段会进行 SUM计算;对于那些非汇总字段,则会使用第一行数据的取值。
15.6.4 AggregatingMergeTree
-
数据立方体
- 通过空间换时间的方法来提升查询性能,将需要聚合的数据预先计算出来,并将结果保存起来
- 在后续进行聚合查询的时候,直接使用结果数据
-
操作方式
--GROUP BY id,city --UNIQ(code), SUM(value) CREATE TABLE agg_table( id String, city String, code AggregateFunction(uniq,String), value AggregateFunction(sum,UInt32), create_time DateTime )ENGINE = AggregatingMergeTree() PARTITION BY toYYYYMM(create_time) ORDER BY (id,city) PRIMARY KEY id INSERT INTO TABLE agg_table SELECT 'A000','wuhan',uniqState('code1'),sumState(toUInt32(100)),'2019-08-10 17:00:00' -
AggregatingMergeTree更为常见的应用方式是结合物化视图使用(结合kafka),将它作为物化视图的表引擎
CREATE TABLE agg_table_basic( id String, city String, code String, value UInt32 )ENGINE = MergeTree() PARTITION BY city ORDER BY (id,city) CREATE MATERIALIZED VIEW agg_view ENGINE = AggregatingMergeTree() PARTITION BY city ORDER BY (id,city) AS SELECT id, city, uniqState(code) AS code, sumState(value) AS value FROM agg_table_basic GROUP BY id, city INSERT INTO TABLE agg_table_basic VALUES ('A000','wuhan','code1',100),('A000','wuhan','code2',200), ('A000','zhuhai', 'code1',200) SELECT id, sumMerge(value), uniqMerge(code) FROM agg_view GROUP BY id,city
15.6.5 CollapsingMergeTree
-
产生背景
- CollapsingMergeTree就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个sign标记位字段,记录数据行的状态。
- 如果sign标记为1,则表示这是一行有效的数据;
- 如果sign标记为-1,则表示这行数据需要被删除
- CollapsingMergeTree就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个sign标记位字段,记录数据行的状态。
-
数据的“删除”
- 当CollapsingMergeTree分区合并时,同一数据分区内,sign标记为1和-1的一组数据会被抵消删除。这种1和-1相互抵消的操作,犹如将一张瓦楞纸折叠了一般
-
操作方式
ENGINE = CollapsingMergeTree(sign)
--sign用于指定一个Int8类型的标志位字段。 CREATE TABLE collpase_table( id String, code Int32, create_time DateTime, sign Int8 )ENGINE = CollapsingMergeTree(sign) PARTITION BY toYYYYMM(create_time) ORDER BY id --修改前的源数据, 它需要被修改 INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',1) --镜像数据, ORDER BY字段与源数据相同(其他字段可以不同),sign取反为-1,它会和源数据折叠 INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',-1) --修改后的数据 ,sign为1 INSERT INTO TABLE collpase_table VALUES('A000',120,'2019-02-20 00:00:00',1) --修改前的源数据, 它需要被删除 INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',1) --镜像数据, ORDER BY字段与源数据相同, sign取反为-1, 它会和源数据折叠 INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',-1) -
折叠规则
- 如果sign=1比sign=-1的数据多一行,则保留最后一行sign=1的数据。
- 如果sign=-1比sign=1的数据多一行,则保留第一行sign=-1的数据。
- 如果sign=1和sign=-1的数据行一样多,并且最后一行是sign=1,则保留第一行sign=-1和最后一行sign=1的数据。
- 如果sign=1和sign=-1的数据行一样多,并且最后一行是sign=-1,则什么也不保留。
- 其余情况,ClickHouse会打印警告日志,但不会报错,在这种情形下,查询结果不可预知
-
特点
-
折叠数据并不是实时触发的,和所有其他的MergeTree变种表引擎一样,这项特性也只有在分区合并的时候才会体现。
-
所以在分区合并之前,用户还是会看到旧的数据。解决这个问题的方式有两种
- 在查询数据之前,使用optimize TABLE table_name FINAL命令强制分区合并,但是这种方法效率极低,在实际生产环境中慎用。
- 改变我们的查询方式
SELECT id,SUM(code),COUNT(code),AVG(code),uniq(code) FROM collpase_table GROUP BY id SELECT id,SUM(code * sign),COUNT(code * sign),AVG(code * sign),uniq(code * sign) FROM collpase_table GROUP BY id HAVING SUM(sign) > 0 -
只有相同分区内的数据才有可能被折叠
-
CollapsingMergeTree对于写入数据的顺序有着严格要求。
- 先写入sign=1,再写入sign=-1,则能够正常折叠
- 先写入sign=-1,再写入sign=1,则不能够折叠
-
15.6.6 VersionedCollapsingMergeTree
-
理解
- VersionedCollapsingMergeTree表引擎的作用与CollapsingMergeTree完全相同
- 它们的不同之处在于,VersionedCollapsingMergeTree对数据的写入顺序没有要求,在同一个分区内,任意顺序的数据都能够完成折叠操作
-
操作方式
ENGINE = VersionedCollapsingMergeTree(sign,ver)
CREATE TABLE ver_collpase_table( id String, code Int32, create_time DateTime, sign Int8, ver UInt8 )ENGINE = VersionedCollapsingMergeTree(sign,ver) PARTITION BY toYYYYMM(create_time) ORDER BY id --删除 INSERT INTO TABLE ver_collpase_table VALUES('A000',101,'2019-02-20 00:00:00',-1,1) INSERT INTO TABLE ver_collpase_table VALUES('A000',102,'2019-02-2000:00:00',1,1) --修改 INSERT INTO TABLE ver_collpase_table VALUES('A001',101,'2019-02-20 00:00:00',-1,1) INSERT INTO TABLE ver_collpase_table VALUES('A001',102,'2019-02-20 00:00:00',1,1) INSERT INTO TABLE ver_collpase_table VALUES('A001',103,'2019-02-20 00:00:00',1,2)
15.6.7 MergeTree关系梳理
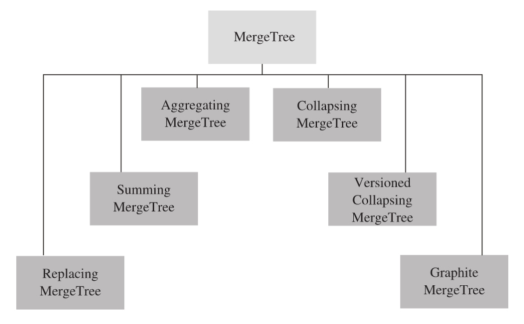
MergeTree表引擎向下派生出6个变种表引擎
15.7 常见类型表引擎
15.7.1 外部存储
- 理解外部存储
- 外部存储表引擎直接从其他的存储系统读取数据
- 例如直接读取HDFS的文件或MySQL数据库的表
- 这些表引擎只负责元数据管理和数据查询,而他们自身通常并不负责数据的写入,数据文件直接由外部系统提供
- 外部存储表引擎直接从其他的存储系统读取数据
1. HDFS表引擎
- 操作方式
--在HDFS上创建用于存放文件的目录
hadoop fs -mkdir /clickhouse
--在HDFS上给ClickHouse用户授权
hadoop fs -chown -R clickhouse:clickhouse /clickhouse
--hdfs_uri表示HDFS的文件存储路径,format表示文件格式
ENGINE = HDFS(hdfs_uri,format)
CREATE TABLE hdfs_table1(
id UInt32,
code String,
name String
)ENGINE = HDFS('hdfs://node01:8020/clickhouse/hdfs_table1','CSV');
INSERT INTO hdfs_table1 SELECT
number,concat('code',toString(number)),concat('n',toString(number)) FROM numbers(5)
--其他方式,只能读取
ENGINE =HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/*','CSV')
ENGINE =HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/organization_{1..3}.csv','CSV')
ENGINE =HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/organization_?.cs v','CSV')
2. MySQL表引擎
-
MySQL表引擎可以与MySQL数据库中的数据表建立映射,并通过SQL向其发起远程查询,包括SELECT和INSERT
ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[,replace_query, 'on_duplicate_clause'])- host:port表示MySQL的地址和端口。
- database表示数据库的名称。
- table表示需要映射的表名称。
- user表示MySQL的用户名。
- password表示MySQL的密码。
- replace_query默认为0,对应MySQL的REPLACE INTO语法。如果将它设置为1,则会用
- REPLACEINTO代替INSERT INTO。
- on_duplicate_clause默认为0,对应MySQL的ON DUPLICATE KEY语法。如果需要使用该设置,则必须将replace_query设置成0。
-
操作方式
CREATE TABLE mysql_dept( deptno UInt32, dname String, loc String )ENGINE = MySQL('192.168.88.101:3306', 'scott', 'dept', 'root','123456'); SELECT * FROM mysql_dept INSERT INTO TABLE mysql_dept VALUES (50,'干饭部','207') --目前MySQL表引擎不支持任何UPDATE和DELETE操作这里可以在navicat中查看插入的数据已经更新到了MySQL中
3. JDBC表引擎
- JDBC表引擎不仅可以对接MySQL数据库,还能够与PostgreSQL、SQLite和H2数据库对接。
- JDBC表引擎无法单独完成所有的工作,它需要依赖名为clickhouse-jdbc-bridge的查询代理服务。
- clickhouse-jdbc-bridge是一款基于Java语言实现的SQL代理服务,它的项目地址为https://github.com/ClickHouse/clickhouse-jdbc-bridge 。
- clickhouse-jdbc-bridge可以为ClickHouse代理访问其他的数据库,并自动转换数据类型。
4. Kafka表引擎
目前ClickHouse还不支持恰好一次(Exactly once)的语义,因为这需要应用端与Kafka深度配合才能实现
-
常见参数
ENGINE = Kafka() SETTINGS kafka_broker_list = 'host:port,... ', kafka_topic_list = 'topic1,topic2,...', kafka_group_name = 'group_name', kafka_format = 'data_format'[,] [kafka_row_delimiter = 'delimiter_symbol'] [kafka_schema = ''] [kafka_num_consumers = N] [kafka_skip_broken_messages = N] [kafka_commit_every_batch = N] -
参数详解
- 必填参数:
- kafka_broker_list:表示Broker服务的地址列表,多个地址之间使用逗号分隔。
- kafka_topic_list:表示订阅消息主题的名称列表,多个主题之间使用逗号分隔。
- kafka_group_name:表示消费组的名称,表引擎会依据此名称创建Kafka的消费组。
- kafka_format:表示用于解析消息的数据格式,在消息的发送端,必须按照此格式发送消息。数据格式必须是ClickHouse提供的格式之一
- 例如TSV、JSONEachRow和CSV等。
- 选填参数:
- kafka_row_delimiter:表示判定一行数据的结束符,默认值为’\0’。
- kafka_schema:对应Kafka的schema参数。
- kafka_num_consumers:表示消费者的数量,默认值为1。
- kafka_skip_broken_messages:当表引擎按照预定格式解析数据出现错误时,允许跳过失败的数据行数,默认值为0,即不允许任何格式错误的情形发生。
- kafka_commit_every_batch:表示执行Kafka commit的频率
- 默认值为0,即当一整个Block数据块完全写入数据表后才执行Kafka commit。
- 如果将其设置为1,则每写完一个Batch批次的数据就会执行一次Kafka commit
- 必填参数:
-
操作方式
CREATE TABLE kafka_table( id UInt32, code String, name String ) ENGINE = Kafka() SETTINGS kafka_broker_list = 'node01:9092', kafka_topic_list = 'topic_clickhouse', kafka_group_name = 'clickhouse', kafka_format = 'TabSeparated', kafka_skip_broken_messages = 10;--使用Java代码产生数据 public static void main(String[] args) throws InterruptedException { for (int i = 0; i < 1000; i++) { YjxKafkaUtil.sendMsg("topic_clickhouse", i +"\tcode\tname"); Thread.sleep(1000); } } -
出现的问题
-
再次执行SELECT查询会发现kafka_table数据表空空如也,这是因为Kafka表引擎在执行查询之后就会移动offset,导致数据无法重复读取

-
-
解决方案
- 首先是Kafka数据表A,它充当的角色是一条数据管道,负责拉取Kafka中的数据。
- 接着是另外一张任意引擎的数据表B,它充当的角色是面向终端用户的查询表,在生产环境中通常是MergeTree系列。
- 最后,是一张物化视图C,它负责将表A的数据实时同步到表B
CREATE TABLE kafka_queue( id UInt32, code String, name String ) ENGINE = Kafka() SETTINGS kafka_broker_list = 'node01:9092', kafka_topic_list = 'topic_clickhouse', kafka_group_name = 'clickhouse', kafka_format = 'TabSeparated', kafka_skip_broken_messages = 10; CREATE TABLE kafka_view ( id UInt32, code String, name String ) ENGINE = MergeTree() ORDER BY id; CREATE MATERIALIZED VIEW consumer TO kafka_view AS SELECT id,code,name FROM kafka_queue;
5. File表引擎
-
理解
- File表引擎能够直接读取本地文件的数据,通常被作为一种扩充手段来使用
- File表引擎的定义参数中,并没有包含文件路径这一项。所以,File表引擎的数据文件只能保存在config.xml配置中由path指定的路径下。
- 每张File数据表均由目录和文件组成,其中目录以表的名称命名,而数据文件则固定data.format命名
-
操作方式
--自动创建 CREATE TABLE file_table ( name String, value Int32 ) ENGINE = File("CSV") INSERT INTO file_table VALUES ('one', 1), ('two', 2), ('three', 3) --插入数据 自动创建 # /var/lib/clickhouse/data/yjxxt/file_table///data.CSV --手动创建 //创建表目录 # mkdir /chbase/data/default/file_table1 //创建数据文件 # mv /chbase/data/default/file_table/data.CSV/chbase/data/default/file_table1 ATTACH TABLE file_table1( name String, value UInt32 )ENGINE = File(CSV) INSERT INTO file_table1 VALUES ('four', 4), ('five', 5)
15.7.2 内存类型
- 将数据全量放在内存中,对于表引擎来说是一把双刃剑
- 一方面,拥有较好的查询性能
- 另一方面,如果表内装载的数据量过大,可能会带来极大的内存消耗和负担
1. Memory表引擎
-
理解
- Memory表引擎直接将数据保存在内存中,数据既不会被压缩也不会被格式转换,数据在内存中保存的形态与查询时看到的如出一辙
-
特点
- 当ClickHouse服务重启的时候,Memory表内的数据会全部丢失。
- 当数据被写入之后,磁盘上不会创建任何数据文件
-
操作方式
CREATE TABLE memory_1 ( id UInt64 )ENGINE = Memory()
2. Set表引擎
-
特点
- Set表引擎是拥有物理存储的,数据首先会被写至内存,然后被同步到磁盘文件中
- 所以当服务重启时,它的数据不会丢失,当数据表被重新装载时,文件数据会再次被全量加载至内存
- Set表引擎具有去重的能力,在数据写入的过程中,重复的数据会被自动忽略
-
Set表引擎的存储结构的两个组成部分
- [num].bin数据文件:保存了所有列字段的数据。其中,num是一个自增id,从1开始。伴随着每一批数据的写入(每一次INSERT),都会生成一个新的.bin文件,num也会随之加1。
- tmp临时目录:数据文件首先会被写到这个目录,当一批数据写入完毕之后,数据文件会被移出此目录。
-
操作方式
CREATE TABLE set_1 ( id UInt8 )ENGINE = Set(); INSERT INTO TABLE set_1 SELECT number FROM numbers(10) SELECT arrayJoin([1, 2, 3]) AS a WHERE a IN set_1
3. Join表引擎
-
理解
- Join表引擎可以说是为JOIN查询而生的,它等同于将JOIN查询进行了一层简单封装。在Join表引擎的底层实现中,它与Set表引擎共用了大部分的处理逻辑,所以Join和Set表引擎拥有许多相似之处。
ENGINE = Join(join_strictness, join_type, key1[, key2, ...])- join_strictness:连接精度,它决定了JOIN查询在连接数据时所使用的策略,目前支持ALL、
ANY和ASOF三种类型。 - join_type:连接类型,它决定了JOIN查询组合左右两个数据集合的策略,它们所形成的结果
是交集、并集、笛卡儿积或其他形式,目前支持INNER、OUTER和CROSS三种类型。当join_type被设置为ANY时,在数据写入时,join_key重复的数据会被自动忽略。 - join_key:连接键,它决定了使用哪个列字段进行关联
-
操作方式
CREATE TABLE join_tb1( id UInt8, name String, time Datetime ) ENGINE = Log INSERT INTO TABLE join_tb1 VALUES (1,'ClickHouse','2019-05-01 12:00:00'),(2,'Spark', '2019-05-01 12:30:00') CREATE TABLE id_join_tb1( id UInt8, price UInt32, time Datetime ) ENGINE = Join(ANY, LEFT, id) INSERT INTO TABLE id_join_tb1 VALUES (1,100,'2019-05-01 11:55:00'),(1,105,'2019-05-01 11:10:00')
15.7.3 日志类型
1. TinyLog
- TinyLog是日志家族系列中性能最低的表引擎,它的存储结构由数据文件和元数据两部分组成
- 数据文件是按列独立存储的,也就是说每一个列字段都拥有一个与之对应的.bin文件。
- TinyLog既不支持分区,也没有.mrk标记文件
- 由于没有标记文件,它自然无法支持.bin文件的并行读取操作,所以它只适合在非常简单的场景下使用
2. StripeLog
3. Log
15.7.4 接口类型
1. Merge
15.8 数据查询方式⭐️
在日常运转的过程中,数据查询也是ClickHouse的主要工作之一。ClickHouse完全使用SQL作为查询语言,能够以SELECT查询语句的形式从数据库中选取数据,这也是它具备流行潜质的重要原因。虽然ClickHouse拥有优秀的查询性能,但是我们也不能滥用查询,掌握ClickHouse所支持的各种查询子句,并选择合理的查询形式是很有必要的。使用不恰当的SQL语句进行查询不仅会带来低性能,还可能导致不可预知的系统错误
ClickHouse对于SQL语句的解析是大小写敏感的,这意味着SELECT a和SELECT A表示的语义是不相同的
目前支持的查询字句如下
[WITH expr |(subquery)]
SELECT [DISTINCT] expr
[FROM [db.]table | (subquery) | table_function] [FINAL] [SAMPLE expr]
[[LEFT] ARRAY JOIN]
[GLOBAL] [ALL|ANY|ASOF] [INNER | CROSS | [LEFT|RIGHT|FULL [OUTER]] ]
JOIN (subquery)|table ON|USING columns_list
[PREWHERE expr]
[WHERE expr]
[GROUP BY expr] [WITH ROLLUP|CUBE|TOTALS]
[HAVING expr]
[ORDER BY expr]
[LIMIT [n[,m]]
[UNION ALL]
[INTO OUTFILE filename]
[FORMAT format]
[LIMIT [offset] n BY columns]














 1653
1653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









