







17.6 算子(多文件)⭐️
17.6.1 转换算子
-
转换组
joinjoin后的分区数与父RDD分区数多的那一个相同,我们也可以手动设置新的RDD的分区数
- leftOuterJoin
- 按照Key等值关联,然后显示左面不满足条件的
- rightOuterJoin
- 按照Key等值关联,然后显示右面不满足条件的
- fullOuterJoin
- 按照Key等值关联,然后显示左右所有不满足条件的
- Join
- 按照Key等值关联
- 这些
join都是作用在 K,V 格式的 RDD 上。根据 key 值进行连接,例如: (K,V)join(K,W)返回(K,(V,W)) - 代码实现
object Hello07Join { def main(args: Array[String]): Unit = { //1.配置并创建对象 val sparkContext = new SparkContext((new SparkConf().setMaster("local").setAppName("Join" + System.currentTimeMillis()))) //读取数据 // val array = Array[String]("Hello1 user1", "Hello2 user2", "Hello user", "Hello user", "user1 apple") // val lines: RDD[String] = sparkContext.parallelize(array, 8) // println(lines.getNumPartitions) //读取数据 // val linesPart: RDD[String] = sparkContext.textFile("src/main/resources/part.txt", 4) // println(linesPart.getNumPartitions) //开始关联数据 `(K,V)join(K,W)返回(K,(V,W))` val array1 = Array[String]("Hello1 user1", "Hello2 user1", "Hello user11", "Hello user12", "user1 apple1") val array2 = Array[String]("Hello1 user2", "Hello2 user2", "Hello user21", "Hello user22", "user2 apple2") val lines1 = sparkContext.parallelize(array1, 3) val lines2 = sparkContext.parallelize(array2, 4) val words1 = lines1.map(ele => (ele.split(" ")(0), ele.split(" ")(1))) val words2 = lines2.map(ele => (ele.split(" ")(0), ele.split(" ")(1))) //Join(按照Key等值关联) words1.join(words2).foreach(ele => println("join=>" + ele)) //leftOuterJoin (按照Key等值关联,然后显示左面不满足条件的) words1.leftOuterJoin(words2).foreach(ele => println("leftOuterJoin=>" + ele)) //rightOuterJoin (按照Key等值关联,然后显示右面不满足条件的) words1.rightOuterJoin(words2).foreach(ele => println("rightOuterJoin=>" + ele)) //fullOuterJoin (按照Key等值关联,然后显示左右所有不满足条件的) words1.fullOuterJoin(words2).foreach(ele => println("fullOuterJoin=>" + ele)) //查看分区数 println("合并后的分区数join:" + words1.join(words2, 5).getNumPartitions) println("合并后的分区数leftOuterJoin:" + words1.leftOuterJoin(words2, 7).getNumPartitions) } } - leftOuterJoin
-
Union
- 合并两个数据集。两个数据集的类型要一致。
- 返回新的 RDD 的分区数是合并 RDD 分区数的总和
-
intersection
- 取两个数据集的交集
- 返回新的 RDD 的分区数是RDD分区数最多的那个
-
subtract
- 取两个数据集的差集。
- 返回新的 RDD 的分区数是subtract前面的那个RDD的分区数
-
mapPartitions
- mapPartition与 map 类似,单位是每个 partition 上的数据。
- 分区数不会发生变化
-
distinct(map+reduceByKey+map)
- 对 RDD 内数据去重。
- 对整个对象匹配,完全相同的(K,V)时候才会去重
-
cogroup
- 当调用类型 (K,V) 和 (K,W) 的数据上时,返回一个数据集
(K,(Iterable<V>,Iterable<W>)) - 返回新的 RDD 的分区数是RDD最多的那个分区数,
- 会对所有列都进行拼接,如果没有,迭代器为NIL
- 当调用类型 (K,V) 和 (K,W) 的数据上时,返回一个数据集
17.6.2 行动算子
- foreachPartition
- 遍历的数据是每个 partition 的数据
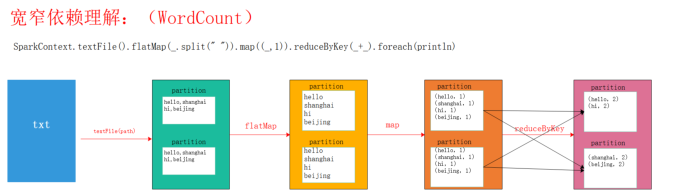
17.7 窄依赖和宽依赖
- 宽窄依赖提出的背景
- 在Spark中,每个任务对应一个分区,通常不会跨分区操作数据。但如果遇到宽依赖的操作,Spark必须从所有分区读取数据,并查找所有键的对应值,然后汇总在一起以计算每个键的最终结果,这称为Shuffle。Shuffle是一项昂贵的操作,因为它通常会跨节点操作数据,这会涉及磁盘 I/O,网络 I/O,和数据序列化。某些Shuffle操作还会消耗大量的堆内存,因为它们使用堆内存来临时存储需要网络传输的数据
- 宽窄依赖的产生
- RDD 之间有一系列的依赖关系,
- 在spark的执行过程中,RDD经过transformation(转换)算子之后,最后由action算子触发操作。逻辑上每经历一次转换,就会将RDD转换为一个新的RDD,新的RDD和旧的RDD之间通过lineage(血统)产生依赖关系,这个关系在容错中有很重要的作用,而依赖也分为宽依赖和窄依赖
- 宽窄依赖的作用?
- 宽窄依赖是为了数据传输更加高效
- 宽窄依赖的划分
- 如果子RDD的一个分区完全依赖父RDD的一个或多个分区,则是窄依赖,否则就是宽依赖
17.7.1 窄依赖
- 概念理解
- 父RDD和子RDD的partition之间的关系式一对一的
- 父 RDD 和子 RDD 的 partition 关系是多对一的
- 特点
- 由于下游数据只有一条,所以不需要对数据进行shuffle操作
- 窄依赖可以组装在一起一次性将数据算出来,然后进行下一步操作,可以减少数据的拉取操作
- 窄依赖由于不需要进行Shuffle,可以将父RDD和子RDD连接到一起,从而减少数据的传输
17.7.2 宽依赖
- 概念理解
- 父 RDD 与子 RDD 的 partition 之间的关系是一对多
- 特点
- 由于下游数据有多条,所以需要对数据进行shuffle操作
17.7.3 宽窄依赖图解
图解一:
图解二:

图解三:
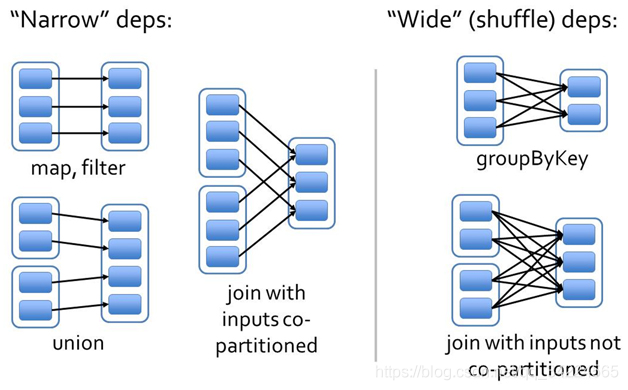
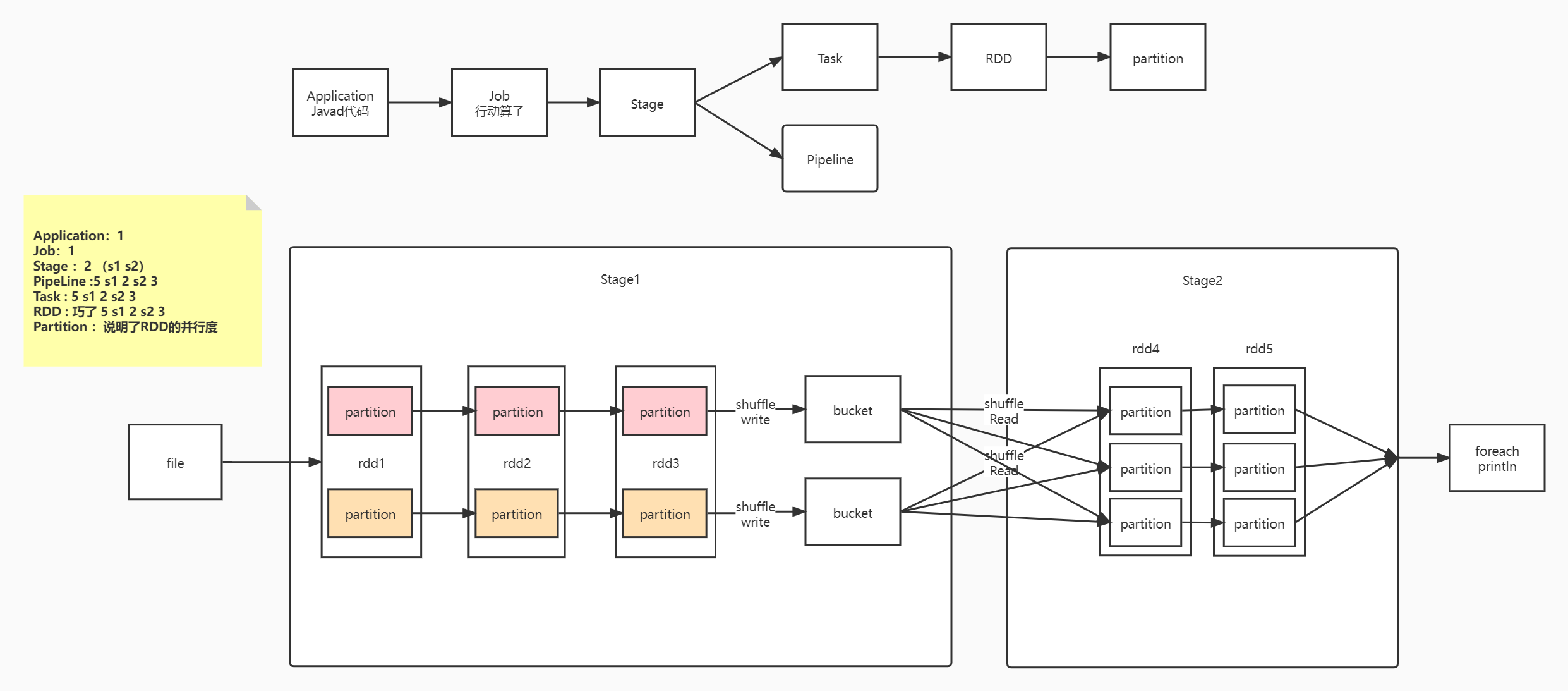
17.8 Stage⭐️
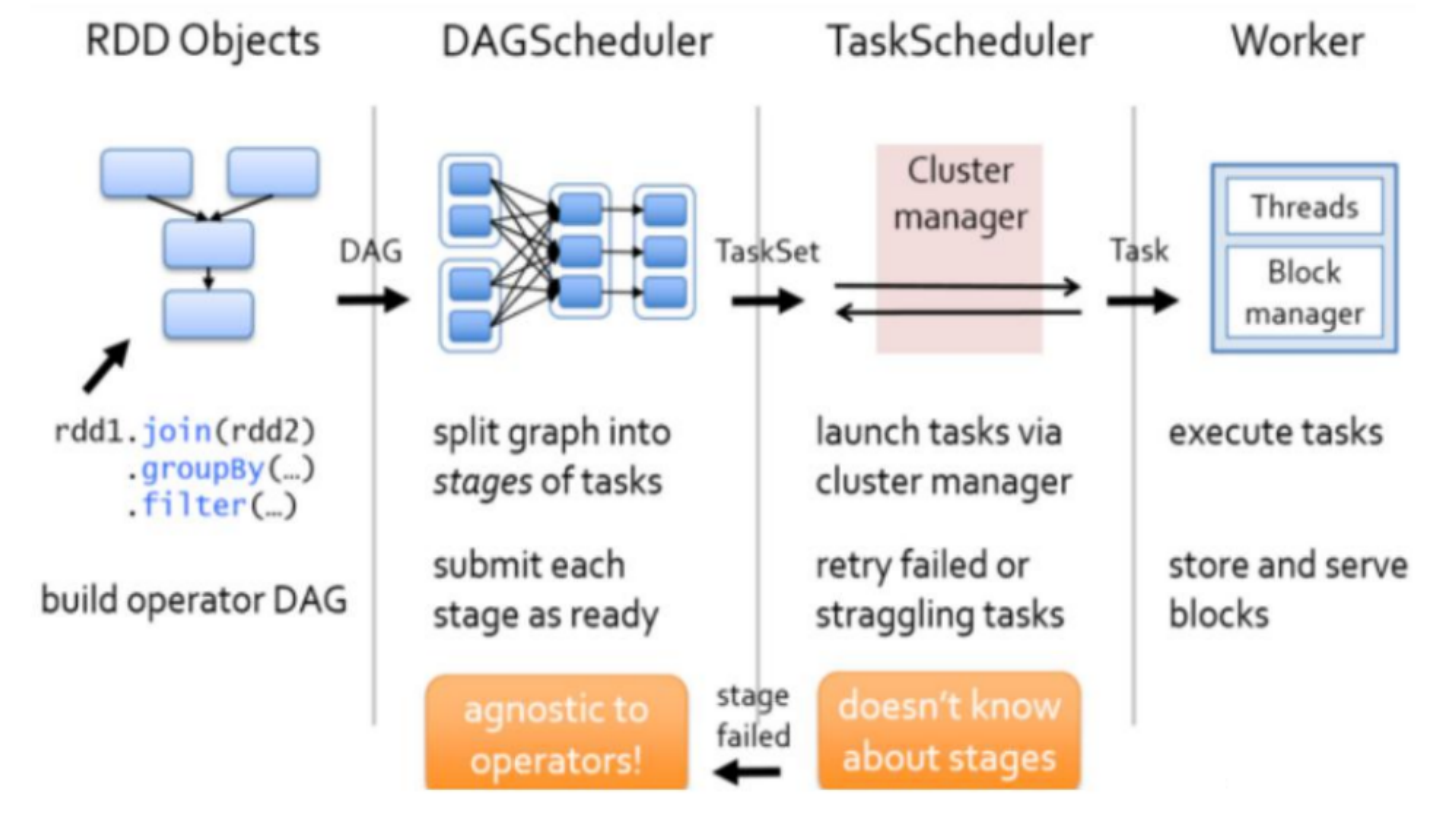
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分成相互依赖的多个Stage,划分Stage的依据就是RDD之间的宽窄依赖,遇到宽依赖就划分stage,每个stage包含一个或者多个task任务,然后将这些task以taskSet的形式提交给TaskScheduler运行
Spark任务–>DAG有向无环图–>DAGScheduler–>n个Stage–>n个task任务–>TaskScheduler
stage是由一组并行的task组成
17.8.1 Stage切割规则
-
切割规则
- 从后往前推RDD算子,如果遇到宽依赖就断开,划分为一个stage;
- 如果遇到窄依赖就将这个RDD加入当前的stage。
- 因为前面的转换算子是懒加载,只有遇到后面的行动算子才会执行,所以只有从行动算子开始才能向前切割stage
-
具体的切割流程
- 从后向前推理,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到Stage中
- 每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition数量决定的
- 最后一个Stage里面的任务的类型是ResultTask,前面所有其他Stage里面的任务类型都是ShuffleMapTask
- 对于窄依赖,由于分区依赖关系的确定性,partition的转换处理可以在同一个线程里完成,称之为ResultTask。
- 而对于宽依赖,只能等父RDD集的shuffle处理完成后,在下一个stage才能开始接下来的计算,称之为shuffleMapTask
- 代表当前Stage的算子一定是这个Stage的最后一个计算步骤
-
总结
- 由于Spark中的stage的划分是根据shuffle来划分的,而宽依赖必然有shuffle过程,因此可以说spark是根据宽窄依赖来划分stage的
-
举例
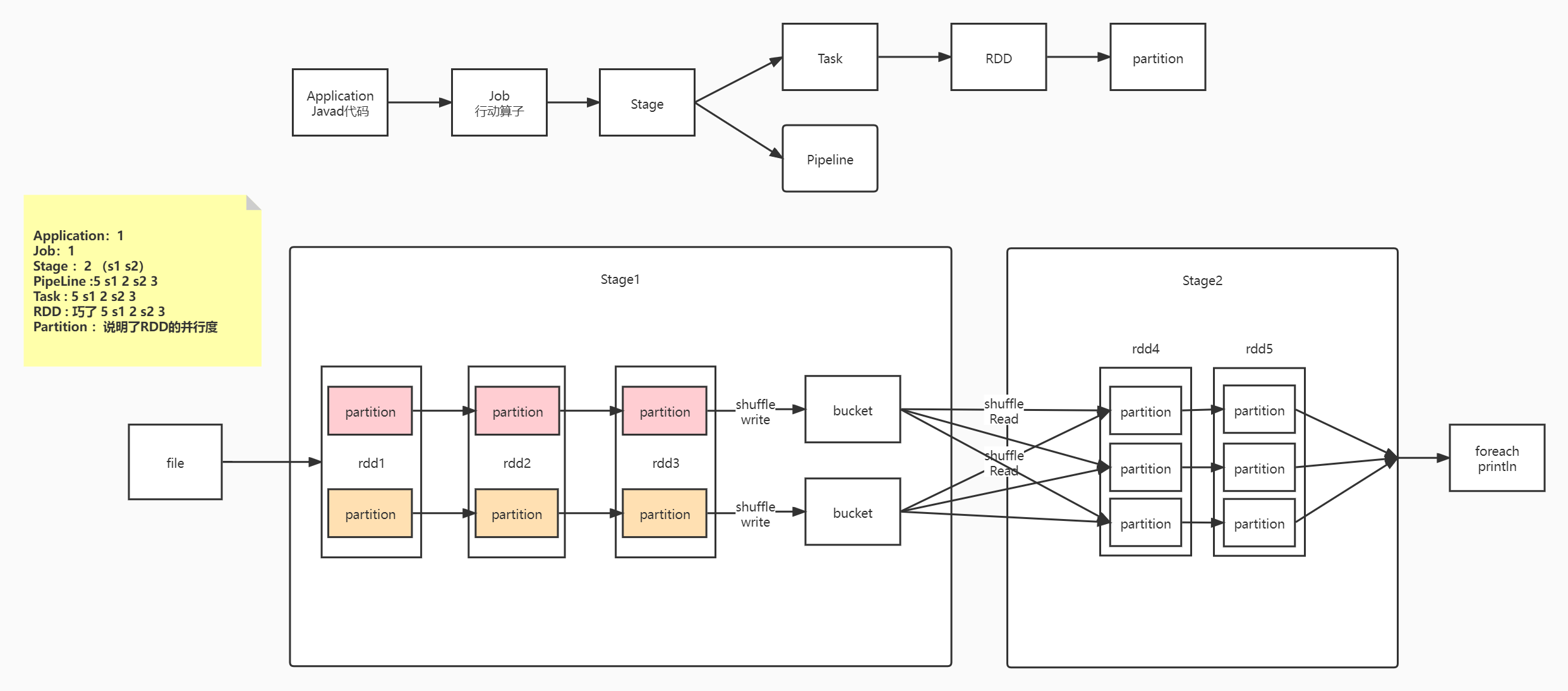
- 如下图的Spark任务应该被划分为2个stage

17.8.2 Stage计算模式
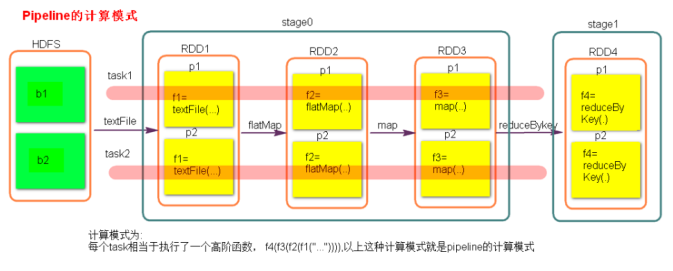
-
pipeline管道计算模式
- pipeline只是一种计算思想、模式
-
pipeline和partition关系
- 在spark中pipeline是一个partition接着对应一个partition(partition关系是一对一),所以在stage内部只有窄依赖
- 可以理解为pipeline是一个流水线(如上图的红色横线代表一个pipeline)
-
数据在管道里面的落地时机
- 对RDD进行持久化( cache , persist )时数据会落地
- shuffle write 的时候
-
task与RDD的partition的关系
- stage的task的并行度是由stage的最后一个RDD的分区数来决定的,有多少个task就有多少个pipeline
-
如何改变RDD的分区数
- reduceByKey(XXX,3)
- GroupByKey(4)
- sc.textFile(path,numpartition)
- 使用算子时传递 分区num参数 就是分区 partition 的数量
-
测试验证 pipeline 计算模式
val conf = new SparkConf() conf.setMaster("local").setAppName("pipeline"); val sc = new SparkContext(conf) val rdd = sc.parallelize(Array(1,2,3,4)) val rdd1 = rdd.map { x => { println("map--------"+x) x }} val rdd2 = rdd1.filter { x => { println("fliter********"+x) true } } rdd2.collect() sc.stop()
17.9 SparkShuffle
-
对Shuffle的理解
- 在Spark中,每个任务对应一个分区,通常不会跨分区操作数据。但如果遇到宽依赖的操作,Spark必须从所有分区读取数据,并查找所有键的对应值,然后汇总在一起以计算每个键的最终结果,这称为Shuffle。Shuffle是一项昂贵的操作,因为它通常会跨节点操作数据,这会涉及磁盘 I/O,网络 I/O,和数据序列化。某些Shuffle操作还会消耗大量的堆内存,因为它们使用堆内存来临时存储需要网络传输的数据
- 通俗的理解,就是2个Stage之间,数据进行传递的过程就叫Shuffle
-
Shuffle的图解
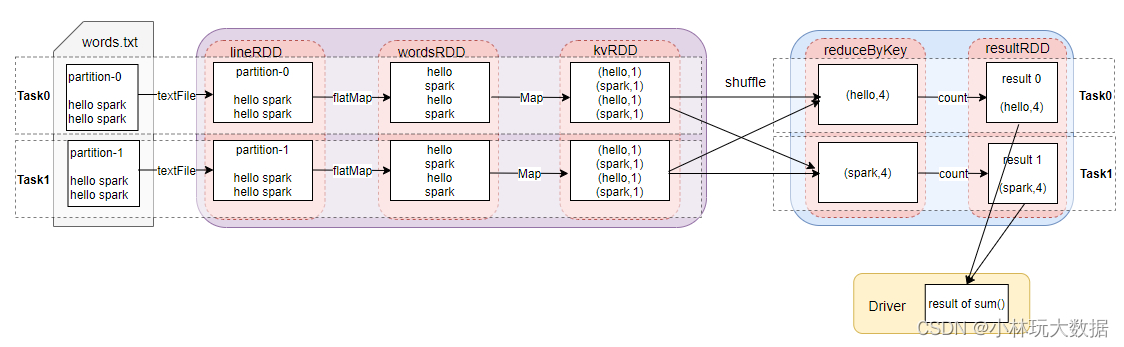
17.9.1 SparkShuffle概念
- ReduceByKey的作用
- reduceByKey会将上一个RDD中的每一个key对应的所有value聚合成一个value,然后生成一个新的RDD,元素类型是<key,value>对的形式,这样每一个key对应一个聚合起来的value
- 对于ReduceByKey出现的问题的提出
- 聚合之前,每一个key对应的value不一定都是在一个partition中,也不太可能在同一个节点上,因为RDD是分布式的弹性数据集,RDD的partition很有可能分布在各个节点上
- 聚合的解决
- Shuffle Write:上一个Stage的每个map task就必须保证将自己处理的当前分区的数据,相同的key写入一个分区文件中,可能会写入多个不同的分区文件中
- Shuffle Read:reduce task就会从上一个stage的所有task所在的机器上寻找属于自己的那些分区文件,这样就可以保证每一个key所对应的value都会汇聚到同一个节点上去处理和聚合。
- Spark的Shuffle类型
- HashShuffle
- SortShuffle
- Spark1.2之前是HashShuffle
- Spark1.2引入SortShuffle
- Spark2.0就只有sortshuffle
17.9.2 HashShuffle
17.9.3 SortShuffle
17.9.4 Shuffle文件寻址
17.9.5 Shuffle调优
17.10 Spark资源调度和任务调度⭐️
17.10.1 调度流程
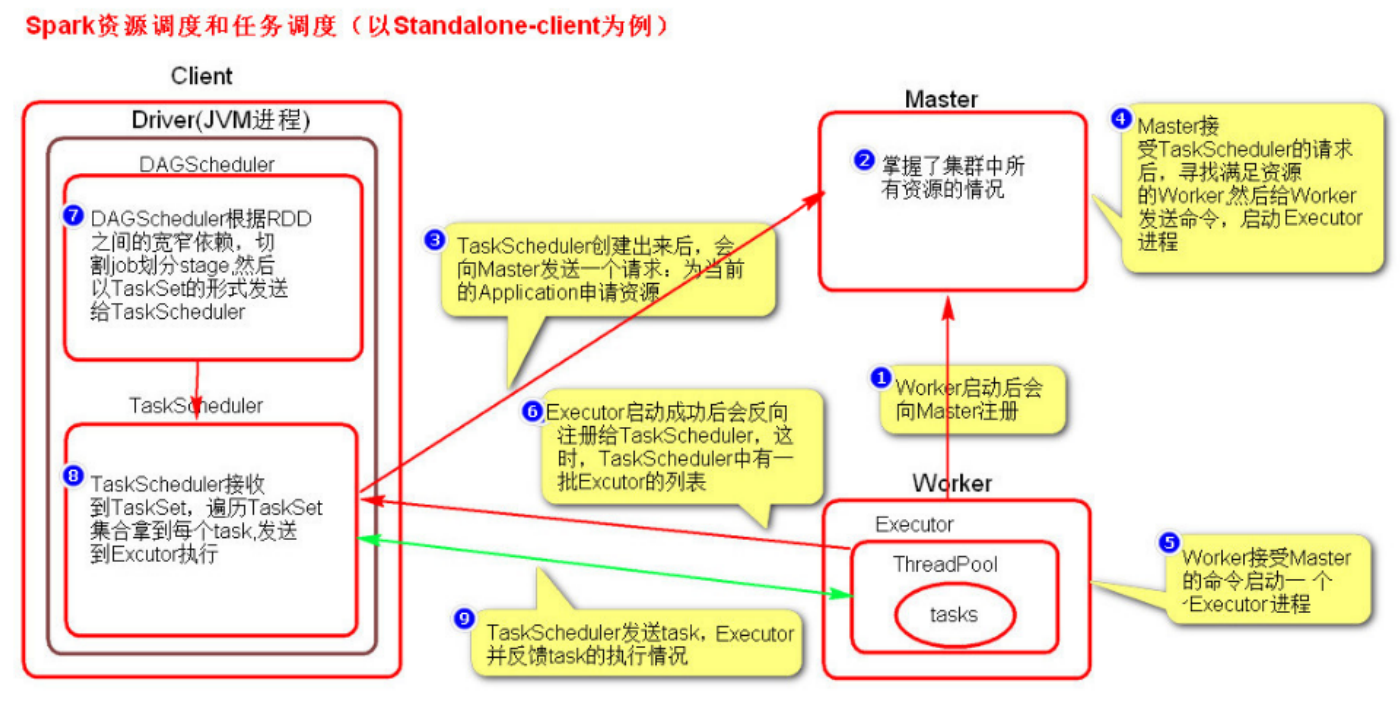
- 启动集群后,worker节点会向Master节点汇报资源情况,Master掌握了集群资源的情况
- 当Spark提交一个Application后,根据RDD之间的依赖关系将Application转换成一个DAG的有向无环图
- 任务提交后,Spark会在Driver端创建两个对象:DAGScheduler和TaskScheduler,(DAGScheduler 是任务调度的高层调度器,TaskScheduler 是任务调度的低层调度器)
- DAGScheduler 的主要作用是将DAG根据RDD之间的宽窄依赖关系划分为一个个的Stage,然后将这些Stage以TaskSet的形式提交给TaskScheduler
- TaskScheduler 是任务调度的低层调度器,这里 TaskSet 其实就是一个集合,里面封装的就是一个个的 task 任务,也就是 stage 中的并行的 task 任务
- TaskScheduler会遍历TaskSet集合,拿到每个task后会将task发送到Executor中去执行(其实就是发送到 Executor 中的线程池 ThreadPool 去执行)
- task在Executor线程池中的运行情况会向TaskScheduler反馈,当task执行失败时,则由TaskScheduler负责重试,将task重新发送给Executor去执行,默认重试3次。如果重试3次依然失败,那么这个task所在的stage就发送失败了
- stage失败了,则由DAGScheduler来负责重试,重新发送TaskSet到TaskScheduler,Stage默认重试4次,如果重试4次以后依然失败,那么这个 job 就失败了。 job 失败了, Application 就失败了
- Spark 的推测执行机制
-
TaskScheduler 不仅能重试失败的 task ,还会重试 straggling (落后,缓慢) task ( 也就是执行速度比其他task慢太多的task )。如果有运行缓慢的 task 那么 TaskScheduler 会启动一个新的task 来与这个运行缓慢的 task 执行相同的处理逻辑。两个 task 哪个先执行完,就以哪个 task的执行结果为准。这就是 Spark 的推测执行机制。在 Spark 中推测执行默认是关闭的。推测执行可以通过spark.speculation 属性来配置
-
注意:
- 对于 ETL 类型要入数据库的业务要关闭推测执行机制,这样就不会有重复的数据入库。
- 如果遇到数据倾斜的情况,开启推测执行则有可能导致一直会有 task 重新启动处理相同的逻辑,任务可能一直处于处理不完的状态
-
对调度流程的总结
-
提交Application
- 根据RDD之间的依赖关系将Application转换成一个DAG
- Driver端创建两个对象来处理Application
-
处理Application
- 正常发送的处理
- DAGScheduler作用:
- TaskScheduler作用:
- 失败发送的处理
- Stage发送失败
- Job发送失败
- 正常发送的处理
-
Spark 的推测执行机制
-
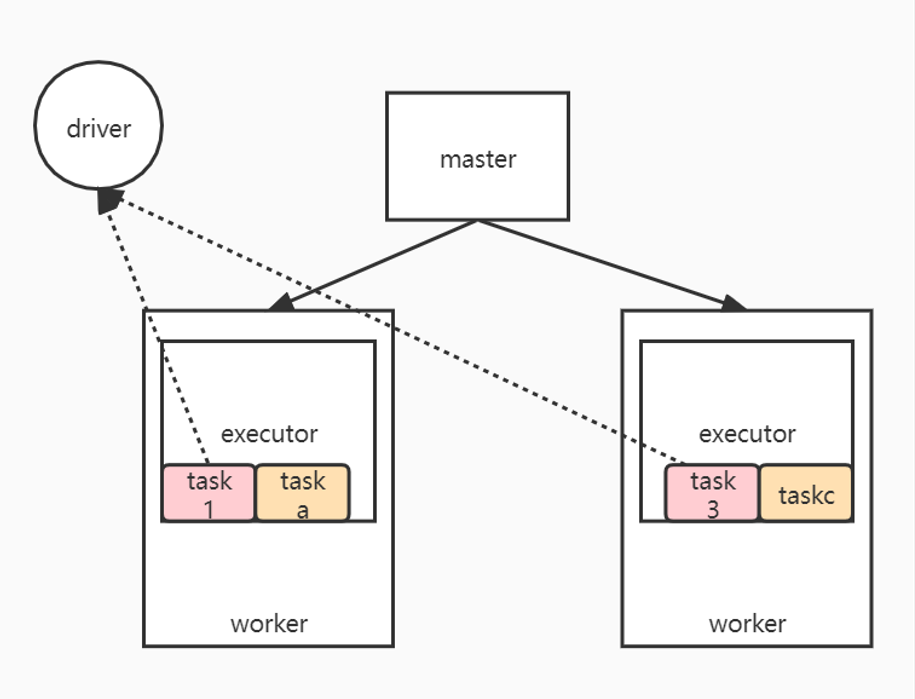
各个节点的作用
- worker节点:向Master节点汇报当前资源情况
- Master节点:收集集群的资源情况
-
各个节点的关系流程
-
17.10.2 流程图解
图解一:
图解二:
17.10.3 粗细粒度资源申请
1. 粗粒度资源申请(Spark)
- 概念理解
- 在Application执行之前,将所有的资源申请完毕,当资源申请成功后,才会进行任务的调度,当所有的task执行完成后,才会释放这部分资源
- 先申请完所有所需的资源,在执行任务,结束后释放所有资源
- 优点
- 在 Application 执行之前,所有的资源都申请完毕,每一个 task 直接使用资源就可以了,不需要 task 在执行前自己去申请资源
- task 启动快了, task 执行快了, stage 执行就快了,job 就快了, application 执行就快了
- 缺点
- 直到最后一个 task 执行完成才会释放资源,集群的资源无法充分利用
- 举例
- Spark
2. 细粒度资源申请(MR)
- 概念理解
- Application执行前不需要先申请资源,而是直接执行,当需要资源时,让job中的每一个task在执行前自己去申请资源,task执行完成后就释放资源
- 优点
- 集群的资源可以充分利用,而不必占用整个资源
- 缺点
- task自己去申请资源,task启动变慢,从而导致Application的运行变慢了
- 举例
- MapReduce















 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









