






最近自己的故障分类论文完成的差不多了,决定抽点时间复现一下引用比较多的WDCNN。之前都是直接用别人的实验数据,没有仔细阅读过相关论文,更没有考虑过复现的问题。仔细阅读这篇论文后,查阅了网上的资料才发现复现的帖子很少,且大部分只对WDCNN复现,有些里还有明显的错误,于是决定自己整一下。
原作者用的是tensorflow,我也是,但其实目前用pytorch复现更容易。
1.首先是WDCNN的模型代码
def WDCNN():
inputs1 = Input(shape=(2048, 1))
x = Conv1D(filters=16, kernel_size=64,strides=16,padding='same')(inputs1)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling1D(pool_size=2, strides=2)(x)
x = Conv1D(filters=32, kernel_size=3, strides=1, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling1D(pool_size=2, strides=2, padding='valid')(x)
x = Conv1D(filters=64, kernel_size=3, strides=1, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling1D(pool_size=2, strides=2)(x)
x = Conv1D(filters=64, kernel_size=3, strides=1, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling1D(pool_size=2, strides=2)(x)
x = Conv1D(filters=64, kernel_size=3, strides=1, padding='valid')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling1D(pool_size=2, strides=2)(x)
x = Flatten()(x)
x = Dense(100)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
outputs = Dense(10, activation='softmax')(x)
model = Model(inputs=inputs1, outputs=outputs)
# model.summary() # 打印模型结构
return model模型比较简单,大家可以根据图里的结构自己查看和调整
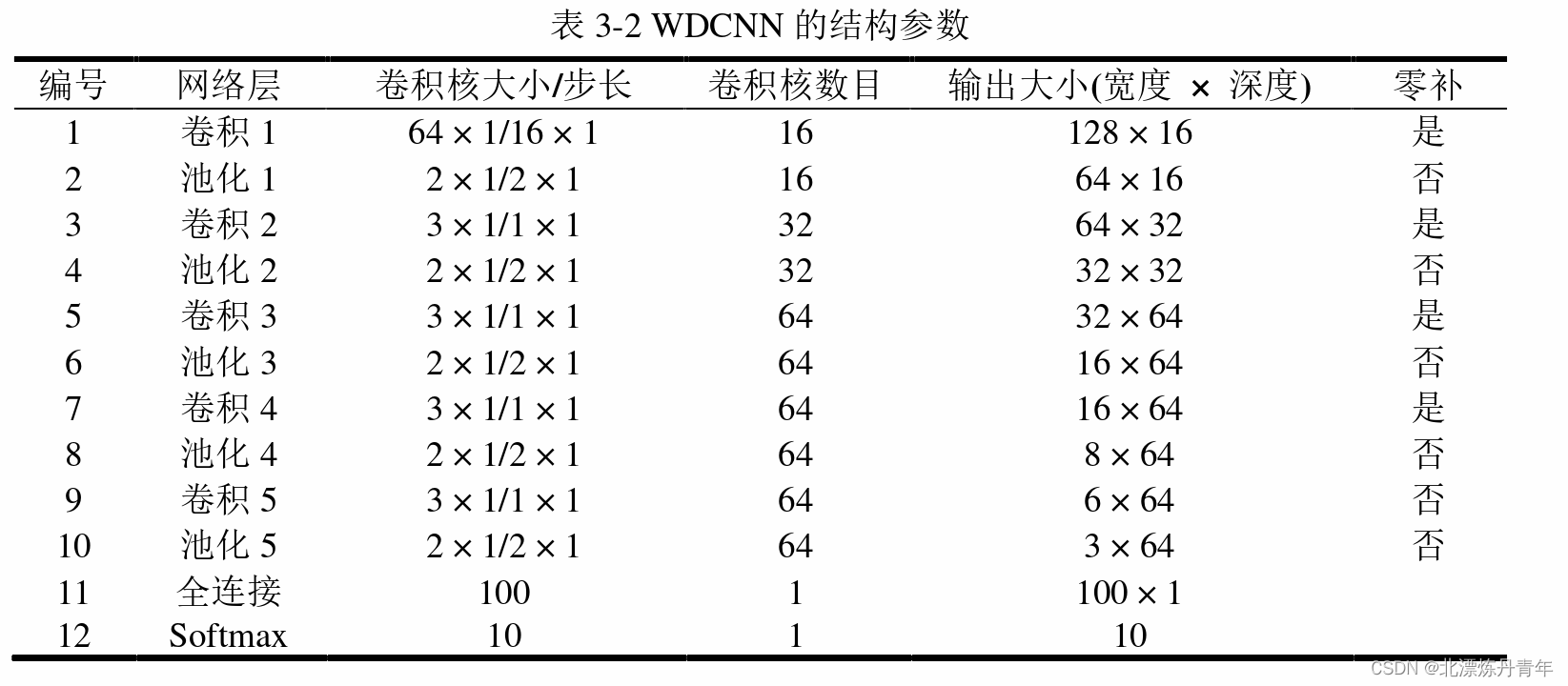
2.AdaBN算法原理及实现
复现WDCNN其实没啥难度,但是AdaBN还是很有说头的。简单来讲,这是BN的一个变种,首先还得对BN的机理多一点了解。我以前只管用,毕竟放到现在已经是一个常规配置项了,不理解一般也不影响使用,但是要用AdaBN的话就不能一知半解了。
大家应该都知道BN实际上就是对隐藏层的参数做批量归一化,而归一化就要用到训练集的数据分布信息,均值和方差。模型中BN模块是个特殊的存在,它不参与反向传播,查看模型时,你会发现它是不可训练的。但不可训练并不意味着不进行变化,在训练阶段它依据每一组batch的相关参数进行调整,之所以不用整个训练集的均值和方差是为了优化模型的适应能力,也可以理解为泛化能力或鲁棒性。
以上过程是model.fit过程中发生的,但是在model.evaluate中就不用了。这时大家一般用测试集来获得准确率,这里的BN用的则是之前fit过程中得到的训练集相关的全局均值和方差。
如果训练集和测试集属于同一工况,或者同分布的数据集,那么这样就很合适。但是当我们做迁移学习时就不一样了,我们当然希望用测试集的均值和方差来进行model.evaluate,毕竟测试集的数据信息是我们已有的信息,这种方法就是AdaBN。
因此,整个AdaBN过程分3步实现。
1.使用训练集进行model.fit。这一步和常规训练一样,但是绝对不能把测试集当验证集进行,这是常识性错误。就像下面这样的,结果肯定准确率能提高,毕竟相当于偷看了答案。
model.fit(X_train, Y_train,validation_data=(X_test, Y_test),epochs=30,batch_size=64)
正确的应该是这样,必须使用验证集。这里我加入了早停机制、模拟褪火和保存最佳模型模块,确保模型能够有效收敛。
model.fit(trainX, trainy, epochs=epochs, batch_size=64, verbose=0, validation_data=(valX, valy),
callbacks=[earlystopper, checkpointer,lr_reducer])2.再次进行model.fit。这一步是最关键的,上一步我们相当于进行了正向传播和反向传播,并且保存了最佳模型的参数。这次fit中我们需要使用训练集进行正向传播,确保BN中的参数更新为训练集相关的。这里如果使用pytorch的话据说非常简单,直接将BN层track_running_stats=True参数,把它改成False,这样在model.eval()时就是用目标域样本的均值和方差。但是tensorflow中我没有找到类似的,也是我个人学的比较浅。这里我使用另外一种方法代替,首先锁定所有模型参数,只允许BN层的参数进行训练,因为BN的机制本身就不参与反向更新,因此训练完成后相当于将目标域测试集的参数保留在了BN中。此时再次保存模型参数,相当于上一步中非BN层的参数+本步骤中BN层的参数组成的一个新的模型参数。
model.load_weights(path) #载入模型参数
model.trainable = False #锁定所有层参数
for i in [2, 6, 10, 14, 16, 20]: #只允许特定层更新
model.layers[i].trainable = True这一步使用model.fit时需要训练集和标签信息,此时训练集就是我们目标域的测试集,标签信息从原理上来讲可以随意设置,因为除了BN所有参数都被锁定了,不会变化,而BN只受此时的训练数据影响。
# np.random.shuffle(valy)
label_te = np.array([1 for i in range(0, 1400)])
label_te = label_te.reshape([1400, 1])
label_te = label_te.reshape(label_te.shape[0], 1)
label_te = label_te.astype(int)
label_te = case10.to_one_hot(label_te)
model.fit(testX, label_te, epochs=epochs, batch_size=64, verbose=0,
callbacks=[lr_reducer, earlystopper2, checkpointer2])为了验证理论的正确,这一步中我用了随机标签和类别都是1的标签,咱们看一下结果如何。进行5次后取平均值
WDCNN Accuracy: 92.764% (+/-1.967)
WDCNN_ada Accuracy: 96.202% (+/-1.447)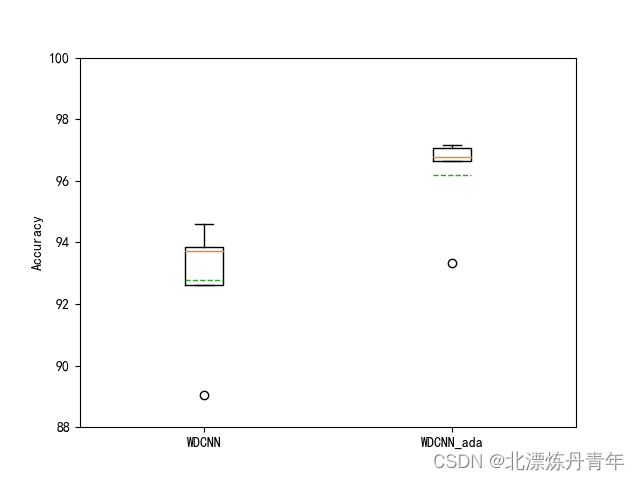
可见效果确实非常不错,提升很明显,和论文中结果接近。
这个方法的好处就是适用性比较强,和很多使用BN的模型都适配,在我的ShuffleNet模型上效果更好,稳定性也更好。
shu Accuracy: 96.148% (+/-0.896)
shu_ada Accuracy: 98.129% (+/-0.445)3.TICNN的复现
我还顺便试了一下TICNN的一部分,实际上这两个模型很接近,TICNN主要就是比WDCNN多了dropout模块,但是我个人测试中发现效果和原作者有出入。这里可能还涉及到原论文中的一点错误,我记录下来供大家参考。首先我们看模型结构
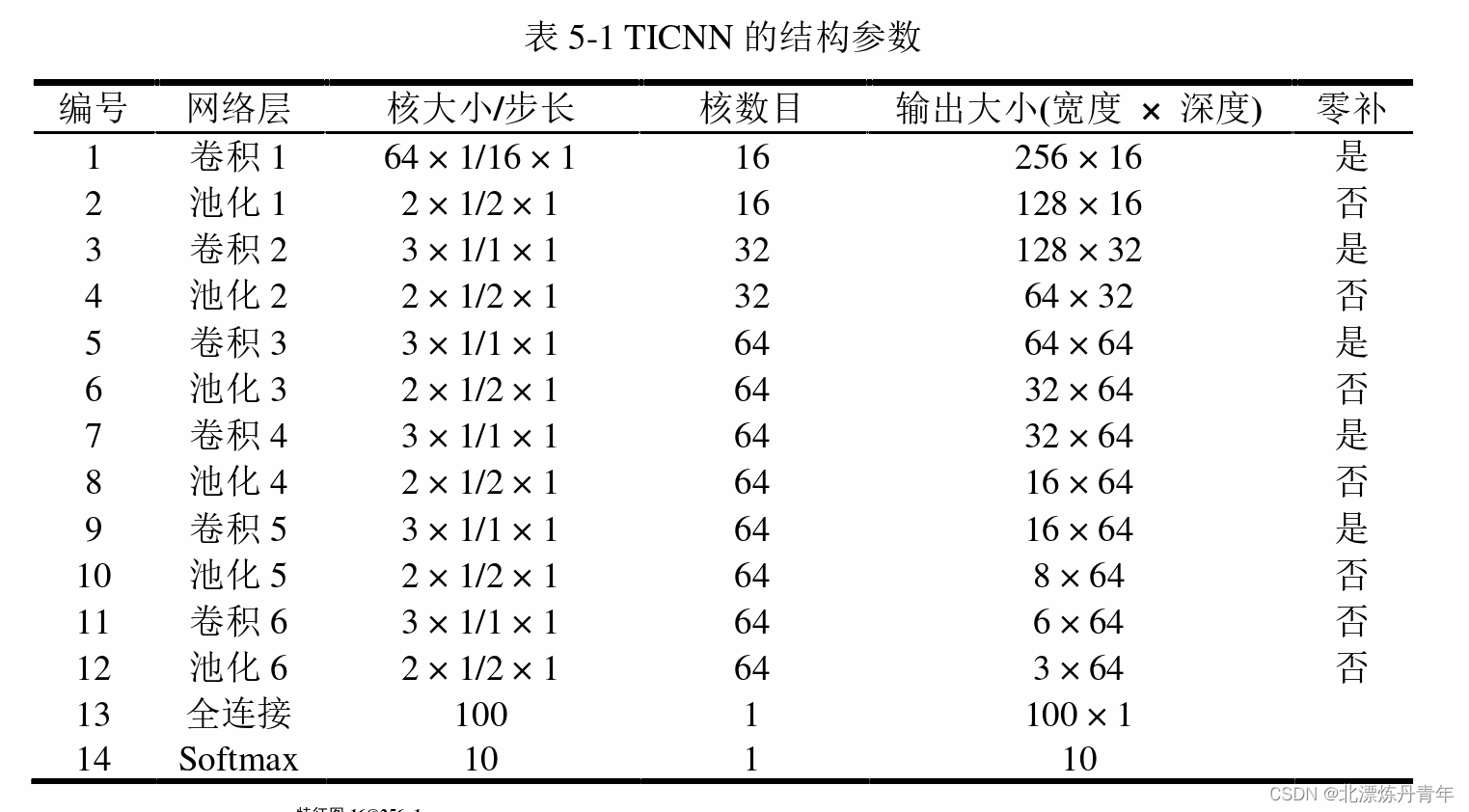
但是作者上文中却有明显提到第一个卷积层的步长改成了8,我估计是作者在做图时的疏忽。下面是原文

但是有意思的是很多人在复现时步长用的还是16,估计是没有好好看论文吧。
TICNN结合AdaBN的效果差一些,只提升1-2%,我个人估计是dropout的原因,因为它会随机丢弃一些参数,导致模型数据的一些不稳定。
就写到这里了,欢迎大家批评指正+点赞收藏!感谢!

















 2496
2496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











