







指令重排序是指编译器或CPU为了优化程序的执行性能而对指令进行重新排序的一种手段,重排序会带来可见性问题,所以在多线程开发中必须要关注并规避重排序。
从源代码到最终运行的指令,会经过如下两个阶段的重排序。
第一阶段,编译器重排序,就是在编译过程中,编译器根据上下文分析对指令进行重排序,目的是减少CPU和内存的交互,重排序之后尽可能保证CPU从寄存器或缓存行中读取数据。
在前面分析JIT优化中提到的循环表达式外提(Loop Expression Hoisting)就是编译器层面的重排序,从CPU层面来说,避免了处理器每次都去内存中加载stop,减少了处理器和内存的交互开销。
第二阶段,处理器重排序,处理器重排序分为两个部分。
并行指令集(CPU)重排序,这是处理器优化的一种,处理器可以改变指令的执行顺序。
内存系统“重排序”,这是处理器引入Store Buffer缓冲区延时写入产生的指令执行顺序不一致的问题;内存系统内不存在真正的重排序,但是内存会带来看上去和重排序一样的效果。
由于内存有缓存的存在,在 JMM 里表现为主存和本地内存,而主存和本地内存的内容可能不一致,所以这也会导致程序表现出乱序的行为。
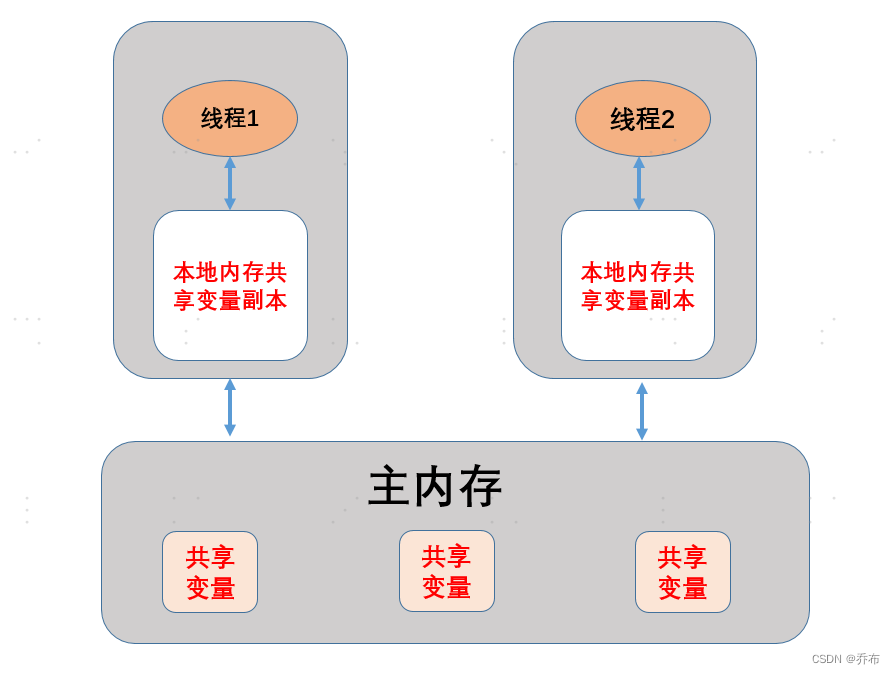
JMM结构:抽象了线程和主内存之间的关系,就比如说线程之间的共享变量必须存储在主内存中
- 主内存 :所有线程创建的实例对象都存放在主内存中,不管该实例对象是成员变量还是方法中的本地变量(也称局部变量)
- 本地内存 :每个线程都有一个私有的本地内存来存储共享变量的副本,并且,每个线程只能访问自己的本地内存,无法访问其他线程的本地内存。本地内存是 JMM 抽象出来的一个概念,存储了主内存中的共享变量副本。
















 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











