







在从Huggingface下载国人做的医学大模型“HuatuoGPT”时,出现了以下报错(已隐去路径信息)
Traceback (most recent call last):
tokenizer = AutoTokenizer.from_pretrained(model_name)
...
return self.sp_model.get_piece_size()
^^^^^^^^^^^^^
AttributeError: 'BaiChuanTokenizer' object has no attribute 'sp_model'可以看到是其内置的Tokenizer找不到相关的参数。关于这个问题,有两种解决方法,都可行。但是笔者因为不想修改很多环境,所以选择了第二种。
第一种 修改环境版本
首先查看Transformer版本
pip show transformers如果你的版本高于4.33.3,那么这个方法是适用的
只需要卸载高版本Transformer,再次下载4.33.3的版本即可。需要注意的是,可能你的torch版本也需要同步到2.0
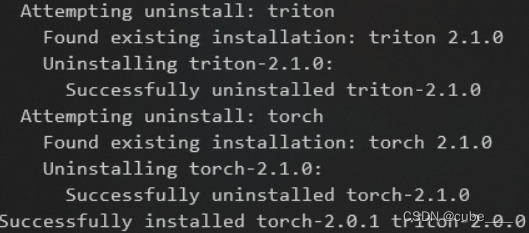
然后就可以正常运行了。
第二种 修改代码
首先进入Huggingface的官网找到模型(https://huggingface.co/FreedomIntelligence/HuatuoGPT-7B/tree/main)
接下来下载tokenization_baichuan.py文件
将其中的super()放在最后,就可以解决报错问题,截图如下:

修改后的顺序为:
self.vocab_file = vocab_file
self.add_bos_token = add_bos_token
self.add_eos_token = add_eos_token
self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
self.sp_model.Load(vocab_file)
super().__init__(
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
pad_token=pad_token,
add_bos_token=add_bos_token,
add_eos_token=add_eos_token,
sp_model_kwargs=self.sp_model_kwargs,
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
**kwargs,
)
# self.vocab_file = vocab_file
# self.add_bos_token = add_bos_token
# self.add_eos_token = add_eos_token
# self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
# self.sp_model.Load(vocab_file)然后就可以正常运行了。
下载模型的代码附下,每次只需要修改“model_name”即可:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 设置模型的名称
model_name = "FreedomIntelligence/HuatuoGPT-7B"
# 创建并保存tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.save_pretrained("./HF_models/HuatuoGPT")
# 创建并保存模型
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
model.save_pretrained("./HF_models/HuatuoGPT")















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









