






目录
下载安装Speech SDK
由于官网相关包已经无法下载,大家可自己寻找TTS.rar和TTSlang.rar两个包的资源
安装好Speech SDK后,语音控制程序将被添加到 “控制面板”->“语音”选项中,
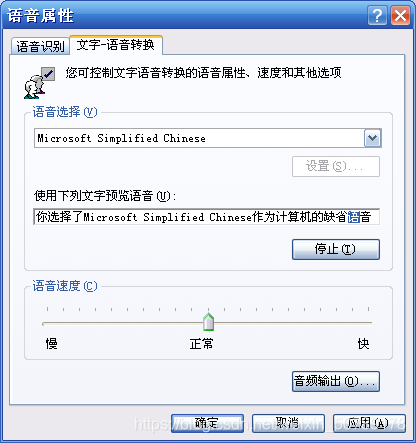
利用下图对话框可以设置语音识别和文字-语音转换的各项属性,包括语言、语调、语速和输入设备等。
配置visual studio 2019项目环境
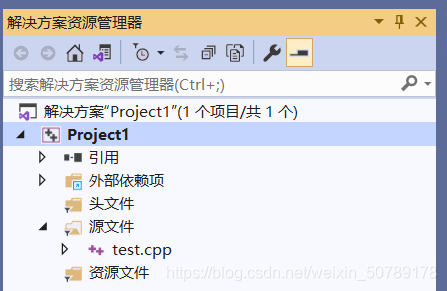
- 先建立一个空项目project1,下添加源文件test.cpp
-
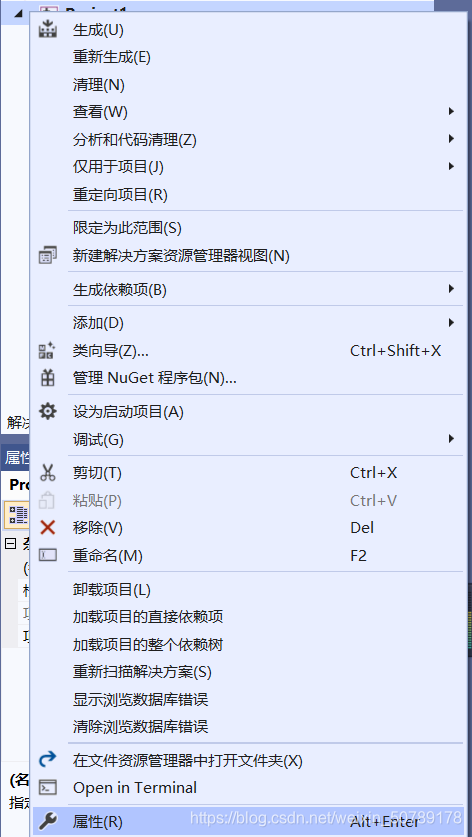
右键点击上图中“Project1”
-
-
点击“属性”-VC++目录
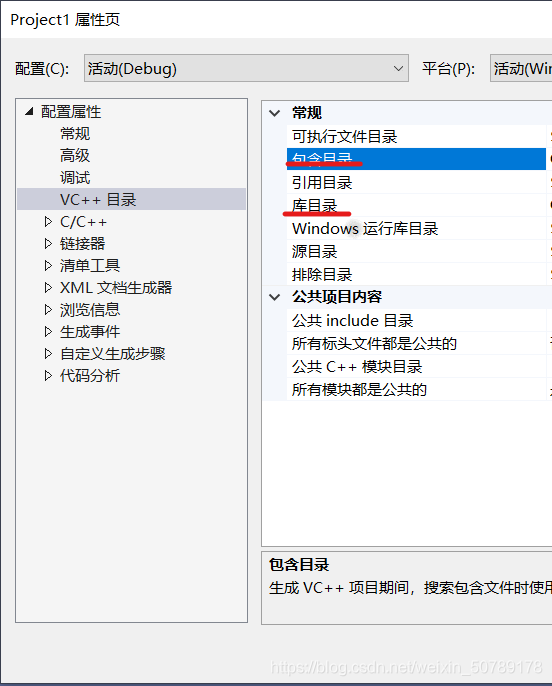
1 1.在“包含目录”后地址框-点击下拉箭头-点击编辑,打开图片2所示“包含目录”-点击图2所圈“新行”图标-下方框中出现一行-点击行后“…”图标-选择\Microsoft Speech SDK 5.1\Include-添加完成

2 2.在“库目录”,同理操作……选择\Microsoft Speech SDK 5.1\Lib\i386-添加完成
-
点击“应用”-“确定”
-
配置完成
测试能否运行
使用测试代码
#include <sphelper.h>//语音头文件
#include <iostream>//C++头文件,用来提示错误信息
int main()
{
::CoInitialize(NULL);//初始化语音环境
ISpVoice* pSpVoice = NULL;//初始化语音变量
if (FAILED(CoCreateInstance(CLSID_SpVoice, NULL, CLSCTX_INPROC_SERVER, IID_ISpVoice, (void**)&pSpVoice)))
//给语音变量创建环境,相当于创建语音变量,FAILED是个宏定义,就是来判断CoCreateInstance这个函数又没有成功创建语音变量,下面是不成功的提示信息。
{
std::cout << "Failed to create instance of ISpVoice!" << std::endl;
return -1;
}
pSpVoice->Speak(L"Hello World!", SPF_DEFAULT, NULL);//执行语音变量的Speek函数,这个函数用来读文字。
pSpVoice->Release(); //释放语音变量
::CoUninitialize();//释放语音环境
return 0;
}
解决运行报错
由于使用Speech SDK安装包版本老,在Visual studio 2019上使用时会出现很多报错,这里记录我运行时解决的报错部分:
-
部分sphelper.h编译错误
这里附上该部分报错解决方案链接(由于转载版本较多,该链接可能不是初始作者发表的博客)https://blog.csdn.net/wangyangtao/article/details/5933734
-
其他部分sphelper.h编译错误解决,都是相似的解决方法,故只按类别提供示例
-
SPDBG_FUNC函数报错:e.g.: SPDBG_FUNC("SpGetTokenFromId"); 改为 SPDBG_FUNC(PCHAR("SpGetTokenFromId"));
-
_tcscpy函数报错:修改为_tcscpy_s函数,在原函数的2个参数之间,增加1个参数:wcslen(第一个参数)
-
wcscpy函数报错:e.g.: wcscpy(szLangCondition, L"Language="); 改为 wcscpy_s(szLangCondition,wcslen(szLangCondition), L"Language=");
-
wcscat函数报错:e.g.: wcscat(szLangCondition, szLang); 改为 wcscat_s(szLangCondition, wcslen(szLangCondition), szLang);
-
GetVersionExW:被声明为已否决:解决办法:项目 > 属性 > C/C++ > SDL 检查 > 关掉
-
sapi.h中报错:wchar_t*转BSTR
例如:BSTR CategoryID = L"" > 修改为:BSTR CategoryID = ::SysAllocString(L"")
可参考博客:
-
若还有其他报错,欢迎大家在评论区补充
修改Speech SDK文件的保存问题
在修改sphelper.h和sapi.h文件后,我遇到了无法保存的问题,即visual studio没有修改该文件的权限,造成“对路径访问被拒绝”
解决方法:
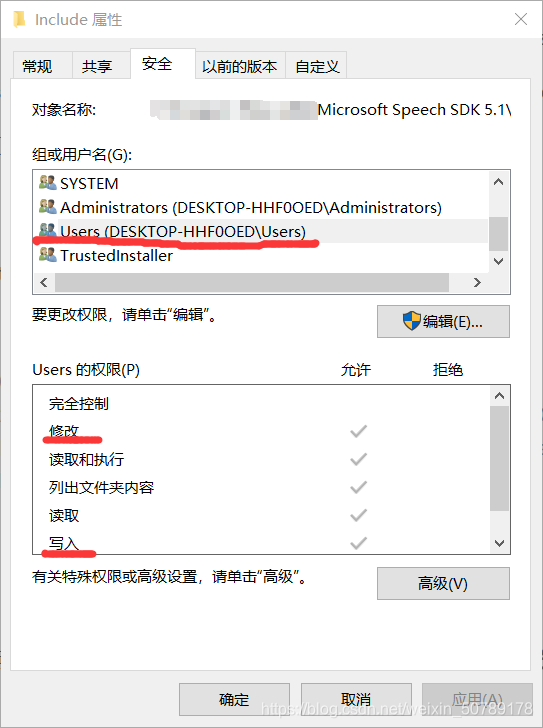
修改include文件属性
右键include文件夹-点击属性-点击“安全”
原本“修改”和“写入”的“允许”权限是没有的,此处点击“编辑”按钮-选择“Users”-勾选“修改”和“写入”的允许权限-应用-确定-可以修改
预祝大家消灭所有报错,取得成功!

















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









