






web自动化测试—Xpath和CSS定位元素
什么是xpath
XPath即为XML路径语言,它是一种用来(标准通用标记语言的子集)在 HTML\XML 文档中查找信息的语言。
什么是XML
XML 指可扩展标记语言(EXtensible Markup Language)
XML 是一种标记语言,很类似 HTML
XML 的设计宗旨是传输数据,而非显示数据
XML与HTML

节点的概念:每个XML/HTML的标签我们都称之为节点


XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非
nodename 选取此节点所有子节点
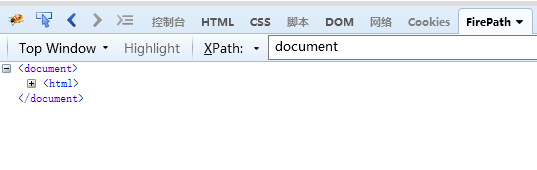
/ 从根节点选取

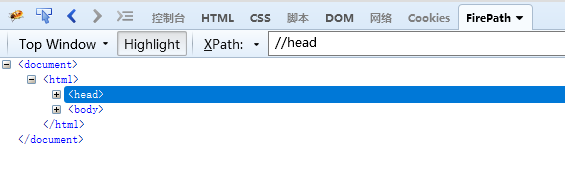
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置
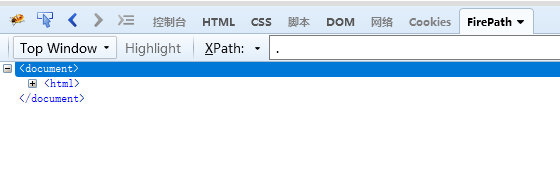
. 选取当前节点
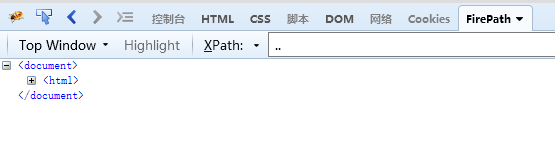
… 选取当前节点的父节点
@ 选取属性

查找某个特定的节点或者包含某个指定的值的节点
/html/head/link[1] 选取head子元素的第一个link元素

/html/head/link[last()] 选取head子元素的最后一个link子元素

/html/head/link[last()-1] 选取head子元素的倒数第二个link子元素

/html/head/link[position()❤️] 选取最前两个属于head子元素的link元素

//html//head//link[@href] 选取所有拥有名为href的属性的link元素

//html//head//link[@href=“img/favicon.ico”] 选取所有link元素,且这些元素拥有值为img/favicon.ico的href属性

- 匹配任何元素节点
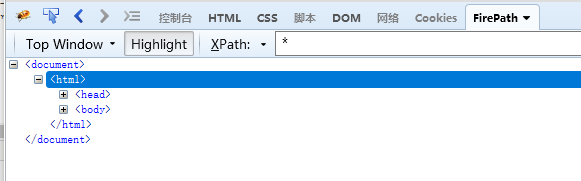
@* 匹配任何属性节点

node 匹配任何类型的节点

/html/* 选取html元素的所有子元素

//* 选取文档中的所有元素

html/node()/link/@* 选择html下面任意节点下的link节点的所有属性

//link[@*] 选取所有带有属性的link元素

//head/link | //head/title 选取head元素的所有link和title元素

//head | //body 选取文档中所有head和body元素
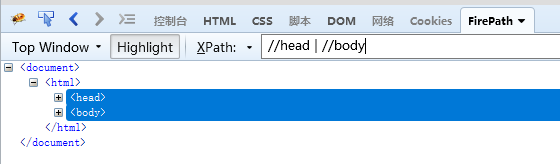
/html/head/title | //body 选取html元素的head元素的所有title元素以及文档中的所有body元素

补充: //*[text()=“x’x’x”] 全部//title/text() 本内容是xxx的元素
//*[starts-with(@attribute,’xxx’)] 属性以xxx开头的元素
//*[contains(@attribute,’xxxxx’)] 属性中含有xxx的元素
//*[@attribute1=value1 and @attribute2=value2] 同时有两个属性值的元素
css选择器



















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









