







原反补
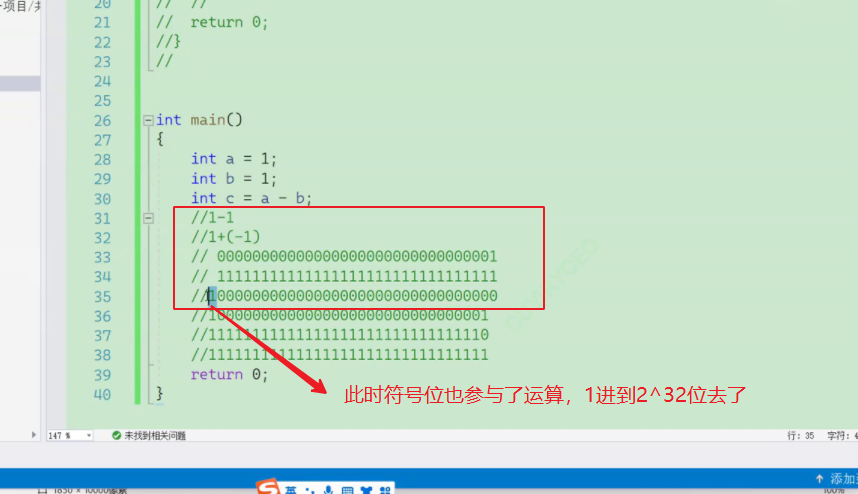
此时符号位也参与了运算
这个列子反应了 数据存储用补码的原因

:使用补码,可以将符号位和数值域统一处理;上述例子正数1负数-1符号位为0和1
同时,加法和减法也可以统一处理(CPU只有加法器);上述例子使用补码相加得到正确结果,如果使用原码计算错误
补码与原码相互转换,其运算过程 是相同的,不需要额外的硬件电路。
:原码到补码 ---取反,+1
补码到原码 ----取反,+1 or -1再取反
例题

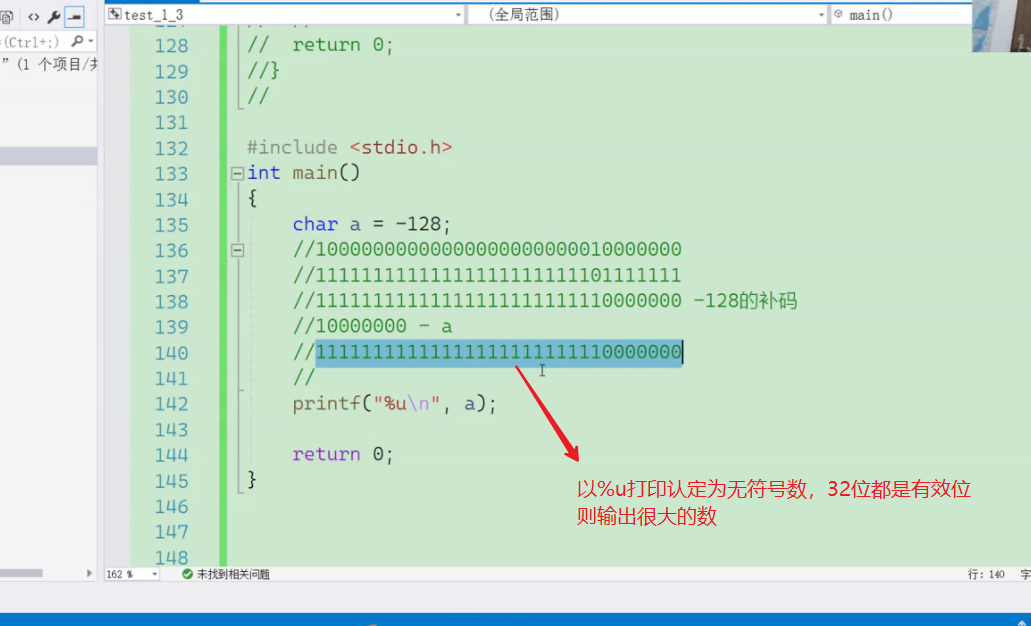
对于char来说 在整型提升时候认定高位为符号位,所以提升时,提升的是char变量如10000000就提升的是1,如果是0就补充0
对于unsigned 整形提升时,不认定高位为符号位,提升补充0
例如char a = -128截断后10000000 的高位为1
char a = 128截断后10000000 的高位也为1
所以提升都
提升1
大小端

为什么有大小端呢?
如果数据超过了1个字节,那么存储时就有一个顺序问题,最后保留了大端和小段这种方式
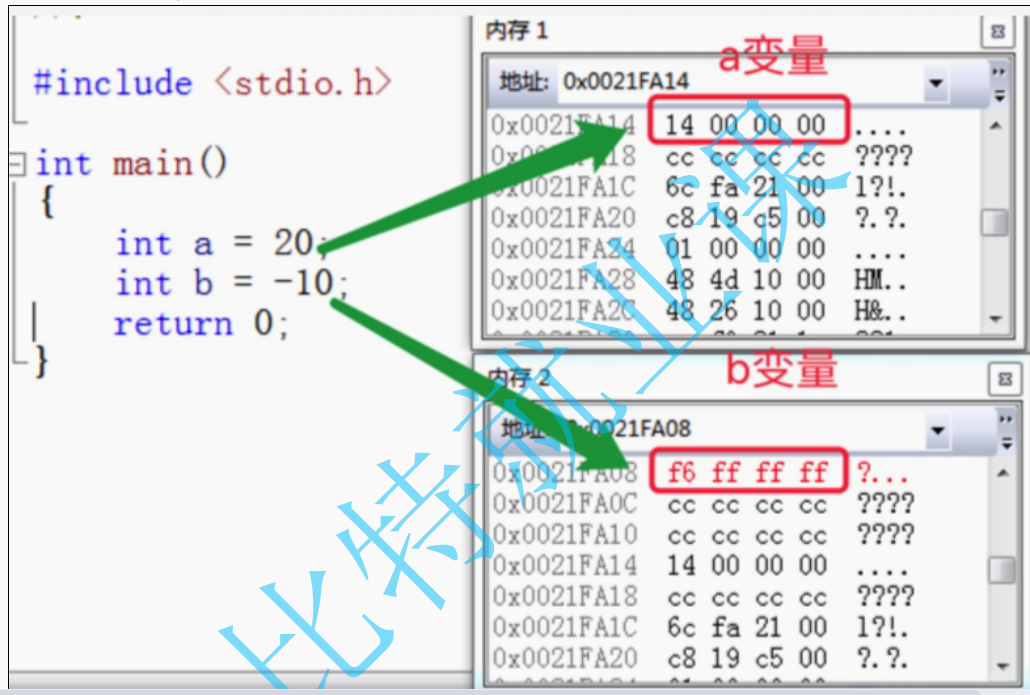
在Debug里面看到的是十六进制
1个十六进制用4个二进制位(也就是bit位)来存储(因为16进制范围0~15,二进制1 1 1 1,8421=15)
2个16进制-----8bit ------1字节
所以上述int为4字节
浮点数在内存中存储
浮点型为float 和 double 一个4字节一个8字节超过了1字节所在在内存中也需要小端存储
3.1415
1E10:表示为:1.0 * 10^10















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









