






在task1中,针对可图AIGC文生图基本跑通了baseline的代码,并对文生图的流程有了一个基本的了解。本章在Task1的基础上继续深入,借助AI工具对baseline的代码有一个更加细致的理解。
task1链接:Datawhale X 魔搭 AI夏令营 第四期魔搭-AIGC文生图方向Task1笔记
通义千问——借助AI工具帮助学习代码
操作指南
官方链接:https://tongyi.aliyun.com/qianwen/
通义千问具有信息查询、语言理解、文本创作等多种能力,其中编程与技术支持能力是它的强项之一。可以通过对话的方式进行提问,从而获取我们想要的信息。
实践操作——精读baseline代码
针对task1中的代码,使用通义千问从代码的主题架构和逐行代码解析两个角度对代码进行理解和分析。首先直观感知下文生图代码的框架结构:
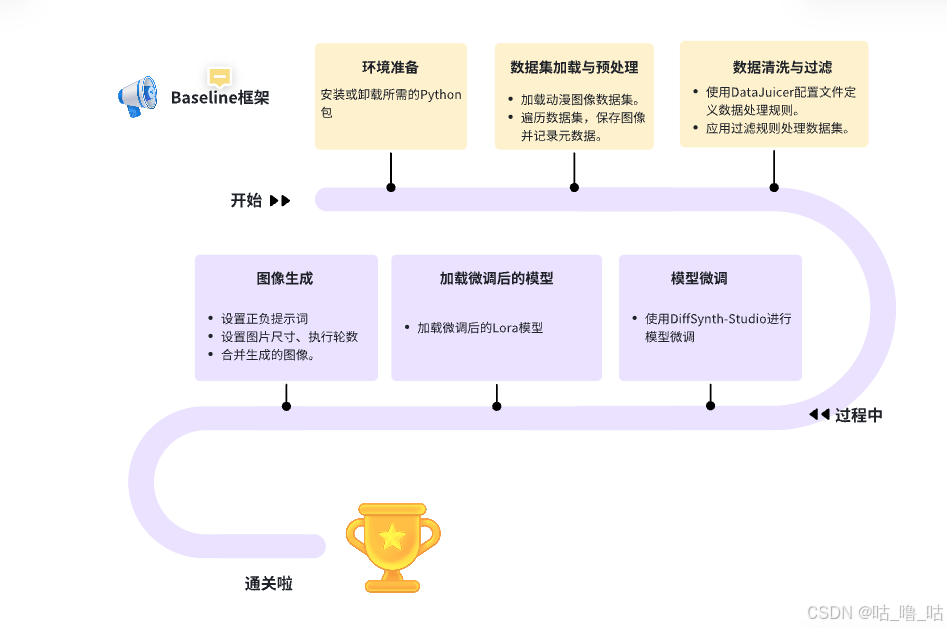
1、分析代码的主体架构
输入的prompt:
你是一个优秀的python开发工程师,现在我们需要你帮我们分析这个代码的主体框架,你需要把代码按
照工作流分成几部分,用中文回答我的问题。{此处替换为baseline的全部代码}返回的答案:
这段代码主要完成了以下几个步骤的工作流程:
1、环境准备与依赖安装
这部分通过`pip`命令安装了所需的Python包,包括`simple-aesthetics-predictor`, `data-juicer`, `peft`, `lightning`, `pandas`, `torchvision`, 和 `DiffSynth-Studio`。同时卸载了`pytorch-lightning`(可能是因为要安装的新版本包含在`lightning`包中)。
2、数据集加载与处理
这里使用了ModelScope的API来加载了一个名为`lowres_anime`的数据集,并将其保存到指定的目录。接着,将数据集中的每一条数据转换成JSONL格式,以便于后续的数据处理。
3、使用Data-Juicer进行数据过滤
创建了一个配置文件`data_juicer_config.yaml`,定义了数据处理的规则(例如图像大小和宽高比)。然后运行`data-juicer`工具来根据这些规则过滤数据。
4、处理过滤后的数据
这部分代码读取了经过Data-Juicer处理后的数据,并将其转换为Pandas DataFrame格式,方便进一步操作。之后,该DataFrame被保存为CSV文件。
5、 图像文本匹配
使用预训练的CLIP模型来计算图像和文本之间的相似性得分。这一步主要是为了评估图像与描述它们的文本之间的关联程度。
6、创建PyTorch数据集与数据加载器
这部分代码创建了一个自定义的PyTorch数据集类`CustomDataset`,用于封装图像和文本数据,并创建了一个数据加载器`DataLoader`来批量加载数据。接着使用CLIP模型对每个批次的数据进行了前向传播。
7、生成图像
最后,使用`StableDiffusionPipeline`根据不同的提示文本生成了一系列二次元风格的图像。这些提示包含了对图像内容的具体描述,以及一些负面提示来避免不希望出现的特征。
8、合并生成的图像
将生成的所有图像合并成一张大图,并调整其尺寸以便展示。
整个过程涉及了从数据集加载、数据清洗与处理、特征提取、数据集构建到最终图像生成的一系列步骤。
可以看到,通义千问基本能够分析出baseline代码的主要步骤和流程
2、逐行分析代码
输入的prompt:
你是一个优秀的python开发工程师,现在我们需要你帮我们逐行分析这个代码,用中文回答我的问题。
{此处替换为baseline的全部代码}返回的答案:逐行代码分析的中文注释
# 安装必要的包
!pip install simple-aesthetics-predictor
# 安装 data-juicer,并设置为可编辑模式
!pip install -v -e data-juicer
# 卸载 pytorch-lightning
!pip uninstall pytorch-lightning -y
# 安装其他所需的包
!pip install peft lightning pandas torchvision
# 安装 DiffSynth-Studio,并设置为可编辑模式
!pip install -e DiffSynth-Studio
# 加载 ModelScope 中的数据集
from modelscope.msdatasets import MsDataset
# 加载数据集
ds = MsDataset.load(
'AI-ModelScope/lowres_anime',
subset_name='default',
split='train',
cache_dir="/mnt/workspace/kolors/data"
)
# 导入必要的库
import json, os
from data_juicer.utils.mm_utils import SpecialTokens
from tqdm import tqdm
# 创建文件夹用于存放训练数据
os.makedirs("./data/lora_dataset/train", exist_ok=True)
# 创建文件夹用于存放 DataJuicer 的输入文件
os.makedirs("./data/data-juicer/input", exist_ok=True)
# 遍历数据集中的每个样本,保存图像,并创建 JSON 文件
with open("./data/data-juicer/input/metadata.jsonl", "w") as f:
for data_id, data in enumerate(tqdm(ds)):
image = data["image"].convert("RGB")
image.save(f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg")
metadata = {"text": "二次元", "image": [f"/mnt/workspace/kolors/data/lora_dataset/train/{data_id}.jpg"]}
f.write(json.dumps(metadata))
f.write("\n")
# 设置 DataJuicer 的配置
data_juicer_config = """
# 全局参数
project_name: 'data-process'
dataset_path: './data/data-juicer/input/metadata.jsonl' # 数据集目录或文件路径
np: 4 # 处理数据的子进程数量
text_keys: 'text'
image_key: 'image'
image_special_token: '<__dj__image>'
export_path: './data/data-juicer/output/result.jsonl'
# 处理计划
# 包含多个处理操作及其参数的列表
process:
- image_shape_filter:
min_width: 1024
min_height: 1024
any_or_all: any
- image_aspect_ratio_filter:
min_ratio: 0.5
max_ratio: 2.0
any_or_all: any
"""
# 写入配置文件
with open("data/data-juicer/data_juicer_config.yaml", "w") as file:
file.write(data_juicer_config.strip())
# 运行 DataJuicer
!dj-process --config data/data-juicer/data_juicer_config.yaml
# 导入库
import pandas as pd
import os, json
from PIL import Image
from tqdm import tqdm
# 创建文件夹用于存放处理后的图像
os.makedirs("./data/data-juicer/output/images", exist_ok=True)
# 从处理后的 JSONL 文件中读取数据,并保存到 CSV 文件
texts, file_names = [], []
with open("./data/data-juicer/output/result.jsonl", "r") as f:
for line in tqdm(f):
metadata = json.loads(line)
texts.append(metadata["text"])
file_names.append(metadata["image"][0])
# 创建 DataFrame
df = pd.DataFrame({"text": texts, "file_name": file_names})
# 保存 DataFrame 到 CSV 文件
df.to_csv("./data/data-juicer/output/result.csv", index=False)
# 显示 DataFrame
df
# 加载 CLIP 模型
from transformers import CLIPProcessor, CLIPModel
import torch
# 加载预训练的 CLIP 模型和处理器
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 加载图像,并使用 CLIP 处理器处理图像和文本
images = [Image.open(img_path) for img_path in df["file_name"]]
inputs = processor(text=df["text"].tolist(), images=images, return_tensors="pt", padding=True)
# 计算图像和文本之间的相似度
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # 图像-文本相似度分数
probs = logits_per_image.softmax(dim=1) # 计算概率
# 显示概率
probs
# 定义自定义数据集类
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
def __init__(self, df, processor):
self.texts = df["text"].tolist()
self.images = [Image.open(img_path) for img_path in df["file_name"]]
self.processor = processor
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
inputs = self.processor(text=self.texts[idx], images=self.images[idx], return_tensors="pt", padding=True)
return inputs
# 创建数据集实例,并使用 DataLoader 进行批处理
dataset = CustomDataset(df, processor)
dataloader = DataLoader(dataset, batch_size=8)
# 遍历 DataLoader,计算每个批次的图像和文本之间的相似度
for batch in dataloader:
outputs = model(**batch)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
print(probs)
# 加载 StableDiffusion 模型
import torch
from diffusers import StableDiffusionPipeline
# 设置随机种子
torch.manual_seed(1)
# 加载预训练模型
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v-1-4", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
# 生成图像
prompt = "二次元,一个紫色长发小女孩穿着粉色吊带漏肩连衣裙,在练习室练习唱歌,手持话筒"
negative_prompt = "丑陋、变形、嘈杂、模糊、低对比度"
guidance_scale = 4
num_inference_steps = 50
# 生成图像
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
height=1024,
width=1024,
).images[0]
# 保存图像
image.save("example_image.png")
# 显示图像
image
# 生成多张图像
from PIL import Image
# 设置随机种子
torch.manual_seed(1)
# 生成图像并保存
image = pipe(
prompt="二次元,日系动漫,演唱会的观众席,人山人海,一个紫色短发小女孩穿着粉色吊带漏肩连衣裙坐在演唱会的观众席,舞台上衣着华丽的歌星们在唱歌",
negative_prompt=negative_prompt,
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("1.jpg")
# 设置随机种子
torch.manual_seed(1)
# 生成图像并保存
image = pipe(
prompt="二次元,一个紫色短发小女孩穿着粉色吊带漏肩连衣裙坐在演唱会的观众席,露出憧憬的神情",
negative_prompt=negative_prompt + ",色情擦边",
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("2.jpg")
# 设置随机种子
torch.manual_seed(2)
# 生成图像并保存
image = pipe(
prompt="二次元,一个紫色短发小女孩穿着粉色吊带漏肩连衣裙坐在演唱会的观众席,露出憧憬的神情",
negative_prompt=negative_prompt + ",色情擦边",
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("3.jpg")
# 设置随机种子
torch.manual_seed(5)
# 生成图像并保存
image = pipe(
prompt="二次元,一个紫色短发小女孩穿着粉色吊带漏肩连衣裙,对着流星许愿,闭着眼睛,十指交叉,侧面",
negative_prompt=negative_prompt + ",扭曲的手指,多余的手指",
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("4.jpg")
# 设置随机种子
torch.manual_seed(0)
# 生成图像并保存
image = pipe(
prompt="二次元,一个紫色中等长度头发小女孩穿着粉色吊带漏肩连衣裙,在练习室练习唱歌",
negative_prompt=negative_prompt,
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("5.jpg")
# 设置随机种子
torch.manual_seed(1)
# 生成图像并保存
image = pipe(
prompt="二次元,一个紫色长发小女孩穿着粉色吊带漏肩连衣裙,在练习室练习唱歌,手持话筒",
negative_prompt=negative_prompt,
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("6.jpg")
# 设置随机种子
torch.manual_seed(7)
# 生成图像并保存
image = pipe(
prompt="二次元,紫色长发少女,穿着黑色连衣裙,试衣间,心情忐忑",
negative_prompt=negative_prompt,
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("7.jpg")
# 设置随机种子
torch.manual_seed(0)
# 生成图像并保存
image = pipe(
prompt="二次元,紫色长发少女,穿着黑色礼服,连衣裙,在台上唱歌",
negative_prompt=negative_prompt,
cfg_scale=4,
num_inference_steps=50, height=1024, width=1024,
)
image.save("8.jpg")
# 导入库
import numpy as np
from PIL import Image
# 加载图像,并合并成一张大图
images = [np.array(Image.open(f"{i}.jpg")) for i in range(1, 9)]
image = np.concatenate([
np.concatenate(images[0:2], axis=1),
np.concatenate(images[2:4], axis=1),
np.concatenate(images[4:6], axis=1),
np.concatenate(images[6:8], axis=1),
], axis=0)
# 转换为 PIL 图像,并调整尺寸
image = Image.fromarray(image).resize((1024, 2048))3、提示词获取
除了代码分析之外,还可以利用通义千问获取生成图片理想的提示词。
输入的prompt:
你是一个文生图专家,我们现在要做一个实战项目,就是要编排一个文生图话剧
话剧由8张场景图片生成,你需要输出每张图片的生图提示词
具体的场景图片
1、女主正在上课
2、开始睡着了
3、进入梦乡,梦到自己站在路旁
4、王子骑马而来
5、两人相谈甚欢
6、一起坐在马背上
7、下课了,梦醒了
8、又回到了学习生活中
生图提示词要求
1、风格为古风
2、根据场景确定是使用全身还是上半身
3、人物描述
4、场景描述
5、做啥事情
例子:
古风,水墨画,一个黑色长发少女,坐在教室里,盯着黑板,深思,上半身,红色长裙返回的答案:
# 场景1
古风,水墨画,一个黑色长发少女,身着淡蓝色长裙,坐在古色古香的教室里,盯着黑板,聚精会神地听讲,上半身
# 场景2
古风,水墨画,一个黑色长发少女,身着淡蓝色长裙,坐在古色古香的教室里,旁边是一本摊开的书,开始打盹,头轻轻垂下,上半身
# 场景3
古风,水墨画,一个黑色长发少女,身着淡蓝色长裙,站在一条蜿蜒的小径旁,周围是青翠的竹林,闭着眼睛,似乎正聆听远处的鸟鸣声,全身
# 场景4
古风,水墨画,一位英俊的年轻男子,身着华贵的紫袍,骑着一匹白马,沿着小径缓缓前行,面带微笑,目光温柔地望向少女,全身
# 场景5
古风,水墨画,一个黑色长发少女,身着淡蓝色长裙,与一位英俊的年轻男子,身着华贵的紫袍,在一片花海中,周围是盛开的牡丹和樱花,谈笑风生,彼此交流,上半身
# 场景6
古风,水墨画,一个黑色长发少女,身着淡蓝色长裙,与一位英俊的年轻男子,身着华贵的紫袍,两人共乘一骑,在一片开阔的田野上,远处是起伏的山峦,欣赏沿途的风景,全身
# 场景7
古风,水墨画,一个黑色长发少女,身着淡蓝色长裙,睁开眼睛,表情有些茫然,坐在古色古香的教室里,周围是同学的身影,上半身
# 场景8
古风,水墨画,一个黑色长发少女,身着淡蓝色长裙,手持毛笔,低头书写,坐在古色古香的教室内,书桌上堆满了书籍,上半身为了获取想要的问题的答案,一个方面是尽可能地打磨询问的prompt,另一个方面则是在上下文的基础之上进行更加深度的提问。对于前一个问题,通过对比代码分析和提示词获取的prompt,可以看到在获取生成提示词的prompt中给出了更多的信息例如:期望要求和提示词案例。关于编写高质量提示词可以查看链接https://github.com/langgptai/wonderful-prompts。对于后一个问题,可以针对不懂的/可以改进的/更加细节的地方进行追问,例如:
我对其中{替换成你的问题}还是不太理解,给我再详细介绍一下结果展示:
在上述提示词下使用baseline可以生成以下结果,为了保证故事尽可能地连续,在生成图片时对生成提示词进行微小调整,使其对特定人物的描写保持一致。

结果分析:
生成图片的细节仍然不够,部分图片略显人物呆滞,且会出现一些事物展现不符合常识的情况。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









