






多元线性回归之预测房价
一、多元线性回归
在回归分析中,如果有两个或两个以上的自变量,就称为多元回归。事实上,一种现象常常是与多个因素相联系的,由多个自变量的最优组合共同来预测或估计因变量,比只用一个自变量进行预测或估计更有效,更符合实际。因此多元线性回归比一元线性回归的实用意义更大。
问题概述:
市场房价的走向受到多种因素的影响,通过对影响市场房价的多种因素进行分析,有助于对未来房价的走势进行较为准确的评估。
多元线性回归适用于对受到多因素影响的数据进行分析的场景。由多个自变量的最优组合共同来预测或估计因变量,比只用一个自变量进行预测或估计更有效,更符合实际。本文基于数学模型,对过去一段时间某一地区的房屋出售价格等相关数据进行整理,利用多元线性回归的方法对数据进行分析,预测该地区未来的房价走势。
二、使用EXCEL
将neighborhood列和style列删除:

选择数据分析中的回归:
设置输入和输出选项:
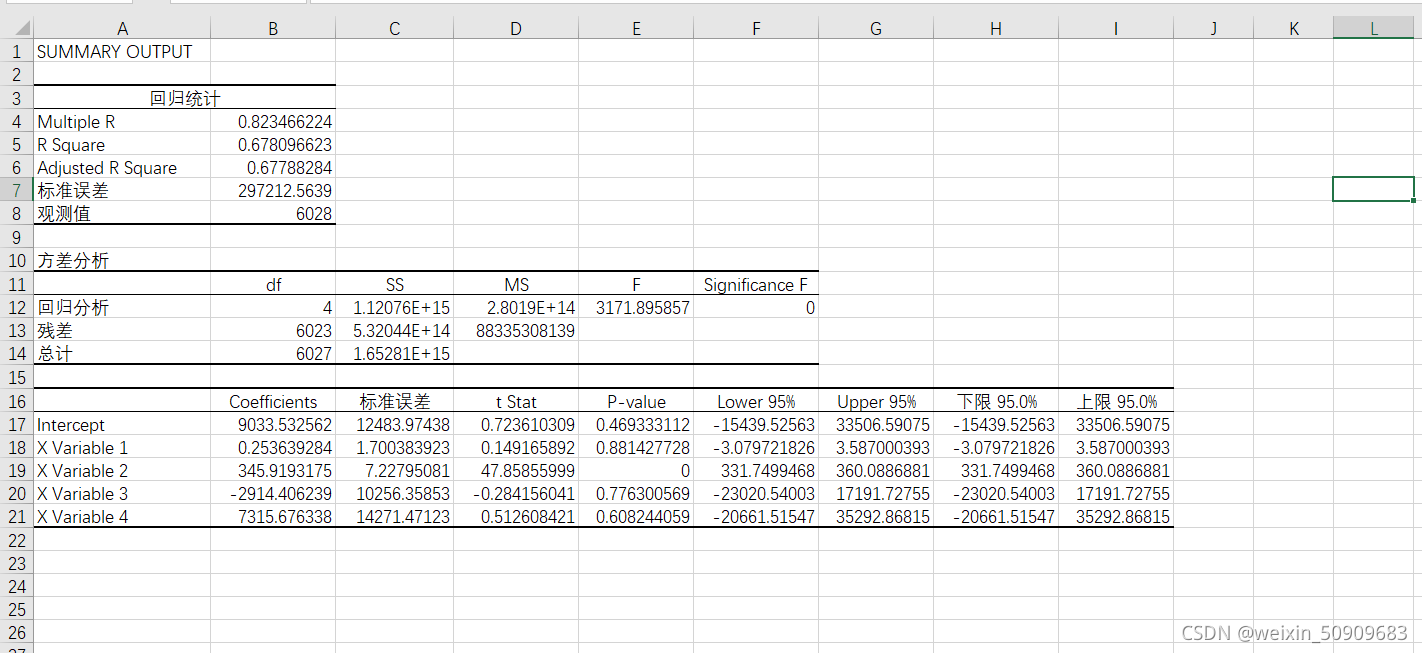
分析结果:
三、Juypter中分析(不使用Sklearn)
导入数据:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('./data/house_prices.csv')
df.info();
df.head();
异常值处理:
# 异常值处理
# ================ 异常值检验函数:iqr & z分数 两种方法 =========================
def outlier_test(data, column, method=None, z=2):
""" 以某列为依据,使用 上下截断点法 检测异常值(索引) """
"""
full_data: 完整数据
column: full_data 中的指定行,格式 'x' 带引号
return 可选; outlier: 异常值数据框
upper: 上截断点; lower: 下截断点
method:检验异常值的方法(可选, 默认的 None 为上下截断点法),
选 Z 方法时,Z 默认为 2
"""
# ================== 上下截断点法检验异常值 ==============================
if method == None:
print(f'以 {column} 列为依据,使用 上下截断点法(iqr) 检测异常值...')
print('=' * 70)
# 四分位点;这里调用函数会存在异常
column_iqr = np.quantile(data[column], 0.75) - np.quantile(data[column], 0.25)
# 1,3 分位数
(q1, q3) = np.quantile(data[column], 0.25), np.quantile(data[column], 0.75)
# 计算上下截断点
upper, lower = (q3 + 1.5 * column_iqr), (q1 - 1.5 * column_iqr)
# 检测异常值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
print(f'第一分位数: {q1}, 第三分位数:{q3}, 四分位极差:{column_iqr}')
print(f"上截断点:{upper}, 下截断点:{lower}")
return outlier, upper, lower
# ===================== Z 分数检验异常值 ==========================
if method == 'z':
""" 以某列为依据,传入数据与希望分段的 z 分数点,返回异常值索引与所在数据框 """
"""
params
data: 完整数据
column: 指定的检测列
z: Z分位数, 默认为2,根据 z分数-正态曲线表,可知取左右两端的 2%,
根据您 z 分数的正负设置。也可以任意更改,知道任意顶端百分比的数据集合
"""
print(f'以 {column} 列为依据,使用 Z 分数法,z 分位数取 {z} 来检测异常值...')
print('=' * 70)
# 计算两个 Z 分数的数值点
mean, std = np.mean(data[column]), np.std(data[column])
upper, lower = (mean + z * std), (mean - z * std)
print(f"取 {z} 个 Z分数:大于 {upper} 或小于 {lower} 的即可被视为异常值。")
print('=' * 70)
# 检测异常值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
return outlier, upper, lower
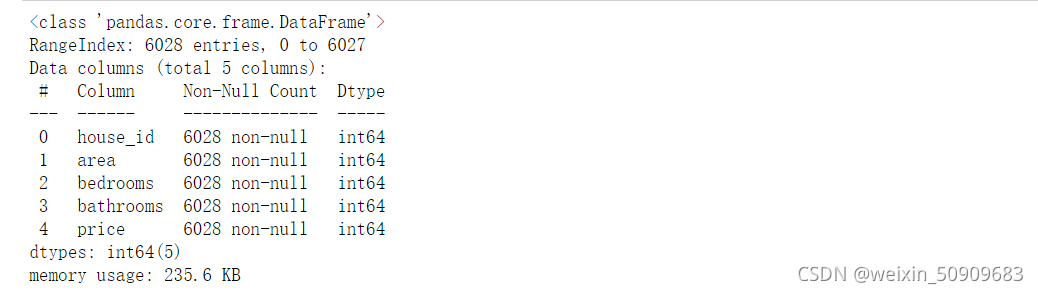
outlier, upper, lower = outlier_test(data=df, column='price', method='z')
outlier.info(); outlier.sample(5)

热力图:
# 热力图
def heatmap(data, method='pearson', camp='RdYlGn', figsize=(10 ,8)):
"""
data: 整份数据
method:默认为 pearson 系数
camp:默认为:RdYlGn-红黄蓝;YlGnBu-黄绿蓝;Blues/Greens 也是不错的选择
figsize: 默认为 10,8
"""
## 消除斜对角颜色重复的色块
# mask = np.zeros_like(df2.corr())
# mask[np.tril_indices_from(mask)] = True
plt.figure(figsize=figsize, dpi= 80)
sns.heatmap(data.corr(method=method), \
xticklabels=data.corr(method=method).columns, \
yticklabels=data.corr(method=method).columns, cmap=camp, \
center=0, annot=True)
# 要想实现只是留下对角线一半的效果,括号内的参数可以加上 mask=mask
heatmap(data=df, figsize=(6,5))
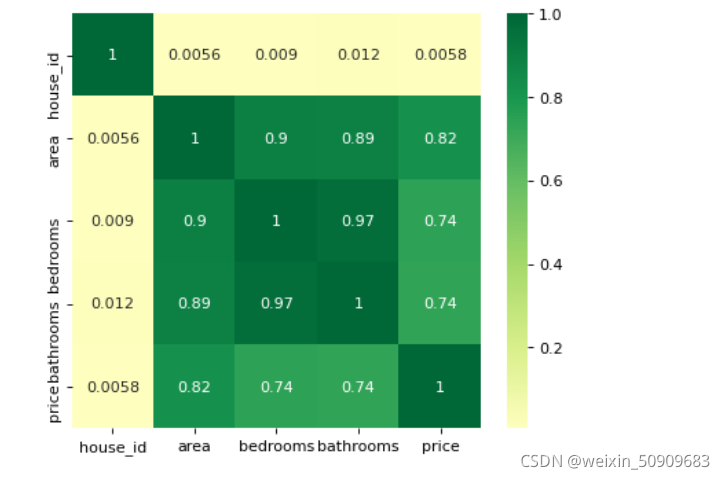
可以看出 area,bedrooms,bathrooms 等变量与房屋价格 price 的关系都还比较强。
多元线性回归建模:
# 随机选择 600 条数据
df = df.copy().sample(600)
from statsmodels.formula.api import ols
lm = ols('price ~ area + bedrooms + bathrooms', data=df).fit()
lm.summary()
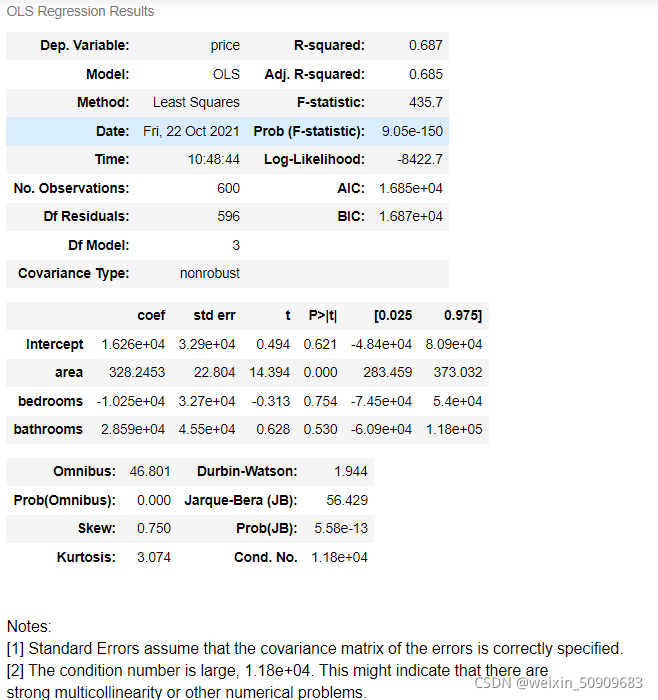
可发现:R^2 =0.687
四、Jupyter中分析(使用Sklearn)
导入数据:
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn import datasets
from sklearn.linear_model import LinearRegression
df = pd.read_csv('data/house_prices.csv')
df.info()#显示列名和数据类型类型
df.head(6)#显示前n行,n默认为5

异常值检测:
# 异常值处理
# ================ 异常值检验函数:iqr & z分数 两种方法 =========================
def outlier_test(data, column, method=None, z=2):
""" 以某列为依据,使用 上下截断点法 检测异常值(索引) """
"""
full_data: 完整数据
column: full_data 中的指定行,格式 'x' 带引号
return 可选; outlier: 异常值数据框
upper: 上截断点; lower: 下截断点
method:检验异常值的方法(可选, 默认的 None 为上下截断点法),
选 Z 方法时,Z 默认为 2
"""
# ================== 上下截断点法检验异常值 ==============================
if method == None:
print(f'以 {column} 列为依据,使用 上下截断点法(iqr) 检测异常值...')
print('=' * 70)
# 四分位点;这里调用函数会存在异常
column_iqr = np.quantile(data[column], 0.75) - np.quantile(data[column], 0.25)
# 1,3 分位数
(q1, q3) = np.quantile(data[column], 0.25), np.quantile(data[column], 0.75)
# 计算上下截断点
upper, lower = (q3 + 1.5 * column_iqr), (q1 - 1.5 * column_iqr)
# 检测异常值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
print(f'第一分位数: {q1}, 第三分位数:{q3}, 四分位极差:{column_iqr}')
print(f"上截断点:{upper}, 下截断点:{lower}")
return outlier, upper, lower
# ===================== Z 分数检验异常值 ==========================
if method == 'z':
""" 以某列为依据,传入数据与希望分段的 z 分数点,返回异常值索引与所在数据框 """
"""
params
data: 完整数据
column: 指定的检测列
z: Z分位数, 默认为2,根据 z分数-正态曲线表,可知取左右两端的 2%,
根据您 z 分数的正负设置。也可以任意更改,知道任意顶端百分比的数据集合
"""
print(f'以 {column} 列为依据,使用 Z 分数法,z 分位数取 {z} 来检测异常值...')
print('=' * 70)
# 计算两个 Z 分数的数值点
mean, std = np.mean(data[column]), np.std(data[column])
upper, lower = (mean + z * std), (mean - z * std)
print(f"取 {z} 个 Z分数:大于 {upper} 或小于 {lower} 的即可被视为异常值。")
print('=' * 70)
# 检测异常值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
return outlier, upper, lower
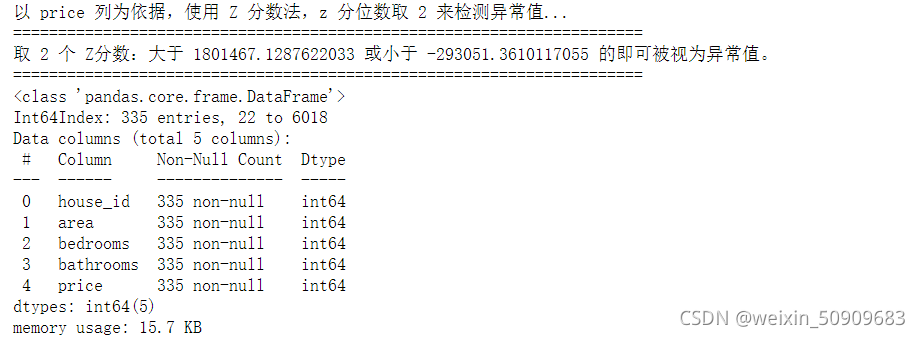
outlier, upper, lower = outlier_test(data=df, column='price', method='z')#获得异常数据
outlier.info(); outlier.sample(5)
df.drop(index=outlier.index, inplace=True)#丢弃异常数据
进行回归:
#取出自变量
data_x=df[['area','bedrooms','bathrooms']]
data_y=df['price']
# 进行多元线性回归
model=LinearRegression()
l_model=model.fit(data_x,data_y)
print('参数权重')
print(model.coef_)
print('模型截距')
print(model.intercept_)
from statsmodels.formula.api import ols
#不使用虚拟变量
lm = ols('price ~ area + bedrooms + bathrooms', data=df).fit()
lm.summary()

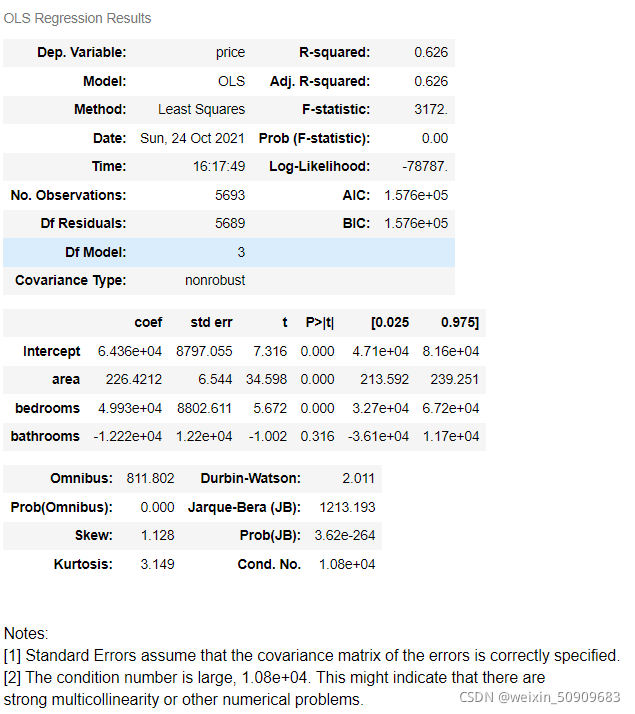
可发现:R^2=0.626
五、总结
多元线性回归的基本原理和基本计算过程与一元线性回归相同,但由于自变量个数多,计算相当麻烦,一般在实际中应用时都要借助统计软件。














 2171
2171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









