







哈希表
哈希表是离散化的一种储存结构:
-
整数:开放寻址法 && 拉链法
-
字符串前缀
模拟散列表
维护一个集合,支持如下几种操作:
1.I x 把x插入集合x;
2.Q x 查询x是否在集合x;
现在要进行 N次操作,对于每个询问操作输出对应的结果。
输入格式
第一行包含整数 N
,表示操作数量。
接下来 N
行,每行包含一个操作指令,操作指令为 I x,Q x 中的一种。
输出格式
对于每个询问指令 Q x,输出一个询问结果,如果 x
在集合中出现过,则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1≤N≤105
−109≤x≤109
输入样例:
5
I 1
I 2
I 3
Q 2
Q 5
输出样例:
Yes
No
冲突:在原区间映射到哈希表的区间可能有些点会重复对应到哈希表中的点h[k]中,因此我们用开放寻址法 || 拉链法两种方法处理这种冲突。
开放寻址法:
- 这种方法要取查询区间的2到3倍,防止不够存储。代码¥¥处解释
- 实际的N尽可能取(N,正无穷)之间的第一个质数,如此处的200003,尽可能减少“冲突”——数学证明。
- memset的用法只能是0和-1,因为memset处理的是字节,此处处理的是0x3f,具体用法百度。
- 映射时 取t=(x%N+N)%N。是因为如果x=-(1e9),x%N之后大概是-(1e4)。我们希望哈希表中的下表是0~N,此时我们把x%N之后再加N让它恒为正数,再对N取模之后下表就一定在0~N的区间之内。
具体见代码注释:
#include<cstring>
#include<iostream>
using namespace std;
const int N=200003,null=0x3f3f3f3f;
int h[N];//仅仅使用一个数组顺序储存
int find(int x)
{
int t=(x%N+N)%N;
while(h[t]!=null&&h[t]!=x)//被占用过且不是之前的x
{
t++;//后移一格
if(t==N) t=0;
//因为¥¥比待求区间大,故不会死循环
}
return t;//如果t这个格子未被占用过——赋值。或者t这个格子仍是x的格子——再次赋值。
}
int main()
{ memset(h,0x3f,sizeof(h));//int四个字节,每个字节0x3f,最终得到的h的结果就是赋值了null
int n;
scanf("%d",&n);
while(n--)
{
char op[2];
int x;
scanf("%s%d",op,&x);
if(op[0]=='I') h[find(x)]=x;
else
{
if(h[find(x)]==null) cout<<"No"<<endl;
else cout<<"Yes"<<endl;
}
}
}
拉链法:
- 实际的N尽可能取(N,正无穷)之间的第一个质数,如此处的100003,尽可能减少“冲突”——数学证明。
- 拉链法是通过h[k]下表处建立一个链表,来存储所有能够映射到哈希下标的x值,由此来解决“冲突”。
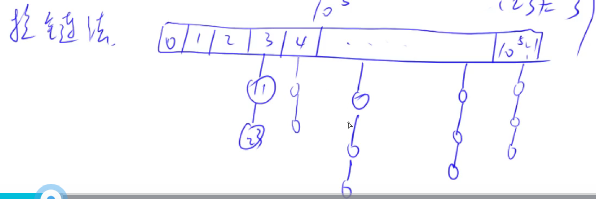
具体见代码:
#include <cstring>
#include <iostream>
using namespace std;
const int N = 100003;
int h[N], e[N], ne[N], idx;
void insert(int x)
{
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx ++ ;
}
bool find(int x)
{
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i])
if (e[i] == x)
return true;
return false;
}
int main()
{
int n;
scanf("%d", &n);
memset(h, -1, sizeof h);
while (n -- )
{
char op[2];
int x;
scanf("%s%d", op, &x);
if (*op == 'I') insert(x);
else
{
if (find(x)) puts("Yes");
else puts("No");
}
}
return 0;
}
字符串前缀:
首先字符串前缀需要把字符串处理成多个字符子串:

把子串中每一个字符从高位到低位对应成一个p进制的数,一般为了避免“冲突”p=131。然后整个数对Q=2^64取模,这样就可以把所有的点映射到0~Q-1的区间。
注意:
- 不能把字母映射成0(因为A——0,AA——0…)
- 哈希字符串需要假定不产生冲突,因为产生的几率可以忽略。
- unsigned long long 溢出范围就相当于对Q取模。
此处可以通过循环i=1~n:
h[i] = h[i - 1] * P + str[i];
分步实现每一个子串的哈希值。

可以通过每个子串对应的p进制数组成的哈希值不同来实现求一个字符串序列中某段子串的哈希值。

此处相当于把h[L-1]扩展到与h[R]同位做差。
因为此处用到了p:
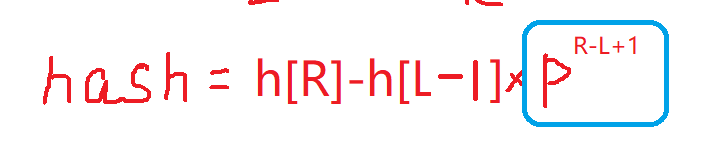
所以我们在枚举h[i]的同时储存p[i],方便此时使用,具体见代码。
题在后边,简单来说就是判断字符串中任意两个子串是否是相等的子串。
#include <iostream>
#include <algorithm>
using namespace std;
typedef unsigned long long ULL;
const int N = 100010, P = 131;
int n, m;
char str[N];
ULL h[N], p[N];
ULL get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
int main()
{
scanf("%d%d", &n, &m);
scanf("%s", str + 1);
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * P + str[i];
p[i] = p[i - 1] * P;
}
while (m -- )
{
int l1, r1, l2, r2;
scanf("%d%d%d%d", &l1, &r1, &l2, &r2);
if (get(l1, r1) == get(l2, r2)) puts("Yes");
else puts("No");
}
return 0;
}
字符串哈希
给定一个长度为 n 的字符串,再给定 m 个询问,每个询问包含四个整数 l1,r1,l2,r2,请你判断 [l1,r1] 和 [l2,r2] 这两个区间所包含的字符串子串是否完全相同。
字符串中只包含大小写英文字母和数字。
输入格式
第一行包含整数 n 和 m,表示字符串长度和询问次数。
第二行包含一个长度为 n 的字符串,字符串中只包含大小写英文字母和数字。
接下来 m 行,每行包含四个整数 l1,r1,l2,r2,表示一次询问所涉及的两个区间。
注意,字符串的位置从 1 开始编号。
输出格式
对于每个询问输出一个结果,如果两个字符串子串完全相同则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1≤n,m≤105
输入样例:
8 3
aabbaabb
1 3 5 7
1 3 6 8
1 2 1 2
输出样例:
Yes
No
Yes















 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









