






分布式爬虫架构
原理
scrapy框架虽然可以实现爬虫的基本功能,在运用到了异步加多线程的加持下,速度得到了提升;但是考虑到只能运行在一台主机上面,爬虫的效率就远远达不到大型任务的开发要求。分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,这将大大提高爬取的效率。
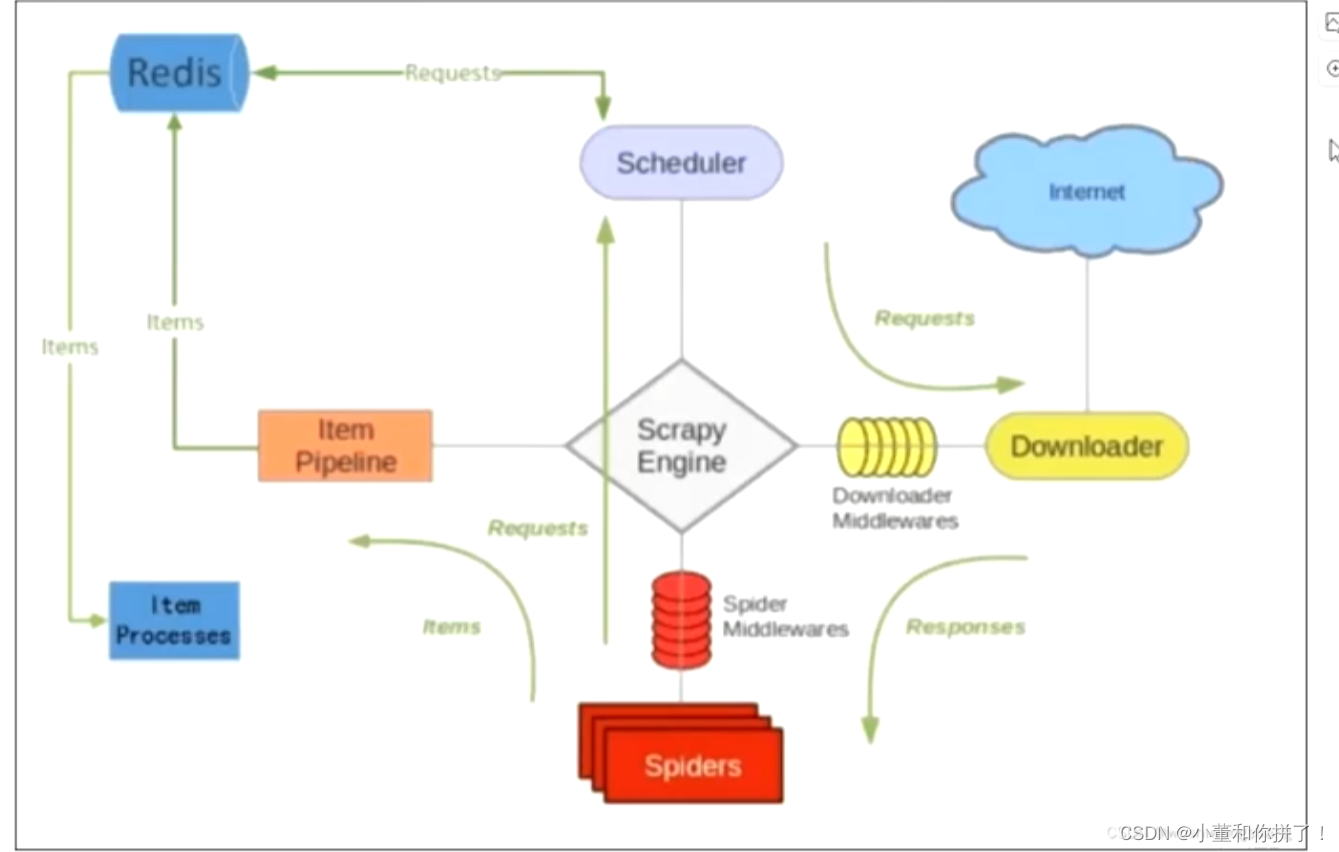
上图和之前的架构图相比,多了redis数据库,而redis数据库在整个框架结构中充当一个调度器的作用,存储了任务队列,这样的优势是在远程服务器上如果已知redis数据库的端口和IP地址,多台主机可以共享redis数据库,共同调度任务队列,提高爬虫工作效率。(redis数据库里面可以存放数据的去重记录做增量爬虫)
怎样去重
Scrapy 有自动去重功能,例如在框架中请求代理IP时,scrapy框架只会反馈给你一个IP地址,不会给你多个IP地址,实际上就是运用了scrapy框架里面的set字段,这就是scrapy框架去重功能的一种表现。它的去重使用了 Python 中的集合。这个集合记录了 Scrapy 中每Request 的指纹,这个指纹实际上就是 Request 的散列值。 (散列值就是转化成一一对应的东西,比如天上的太阳对应“太阳”这两个字,“太阳”这两个字就是) 对应的代码如下:

request_fingerprint 就是计算 Request 指纹的方法,其方法内部使用的是 hashlib 的 sha1 方法(sha1加密,对请求的方法、链接、请求体加密)。计算的字段包括 Request的 Method、URL、Body、Headers 这几部分内容,这里只要有一点不同,那么计算的结果就不同。计算得到的结果是加密后的字符串,也就是指纹。

这段代码是上述代码中的核心序列的部分,可以通过了解序列化的结果去知道去重的方法。
例如:
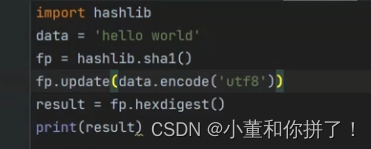
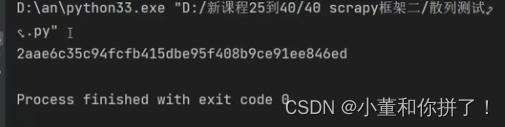
从上面的例子已知字符串‘helloworld’转换成了40位的数字,我们爬虫抓取的相关内容可以打包生成一个新的40位的字符串,利用这个可以进行去重操作,将转换后的4位的sha1字符串存储在数据库中,在下次新的数据进来后可以与原来的数据进行比对,从而达到去重的操作。
.环境准备
pip3 install scrapy-redis
修改配置
修改 Scheduler
在前面的课时中我们讲解了 Scheduler 的概念,它是用来处理 Request、Item 等对象的调度逻辑的,默 认情况下,Request 的队列是在内存中的,为了实现分布式,我们需要将队列迁移到 Redis 中,这时候 我们就需要修改 Scheduler,修改非常简单,只需要在 settings.py 里面添加如下代码即可:
SCHEDULER = "scrapy_redis.scheduler.Scheduler"这里我们将 Scheduler 的类修改为 Scrapy-Redis 提供的 Scheduler 类,这样在我们运行爬虫时, Request 队列就会出现在 Redis 中了。
修改 Redis 连接信息
另外我们还需要修改下 Redis 的连接信息,这样 Scrapy 才能成功连接到 Redis 数据库,修改格式如 下:
REDIS_URL = 'redis://[user:pass]@hostname:9001'在这里我们需要根据如上的格式来修改,由于我的 Redis 是在本地运行的,所以在这里就不需要填写用 户名密码了,直接设置为如下内容即可:
REDIS_URL = 'redis://localhost:6379'修改去重类
既然 Request 队列迁移到了 Redis,那么相应的去重操作我们也需要迁移到 Redis 里面,前一节课我们 讲解了 Dupefilter 的原理,这里我们就修改下去重类来实现基于 Redis 的去重:
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"配置持久化
一般来说开启了 Redis 分布式队列之后,我们不希望爬虫在关闭时将整个队列和去重信息全部删除,因 为很有可能在某个情况下我们会手动关闭爬虫或者爬虫遭遇意外终止,为了解决这个问题,我们可以配 置 Redis 队列的持久化,修改如下:
SCHEDULER_PERSIST = True运行
在scrapy框架里面写一个新的爬虫将里面的相关设置可以按照下上述的方法进行修改,如果是要按照分布式的方法修改的话,要在setting界面将远程服务器的端口进行修改还有修改数据库的密码。修改后按照以下代码即可:

运行后即可得到spider的数据,会将请求的任务信息按照请求链接+请求方法+请求体转运位40位sha1加密的形式存储在redis数据库中如下图:
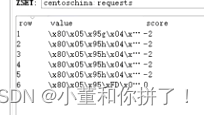
而在另外一个库中存放着已经刷过的请求,即去重的队列,和新来的请求进行比对以达到去重的目的。

scrapy-redis去重
内部相关文件代码解析
在setting中可以看到以下代码:
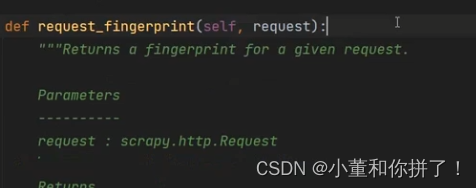
这部分代码讲述的是通过传递过来的result函数生成一个指纹。
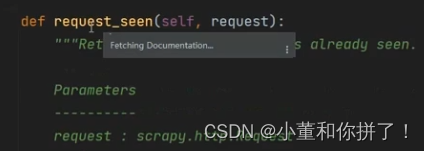
这部分代码是验证之前有没有加过一个指纹,这是框架达到去重功能的一大基础。
在框架内部的request部分可以看到以下代码:

主要就是讲述了三个参数:request请求、include_headers请求头一般为空、keep_fragments一般都是为空。转到内部重要部分
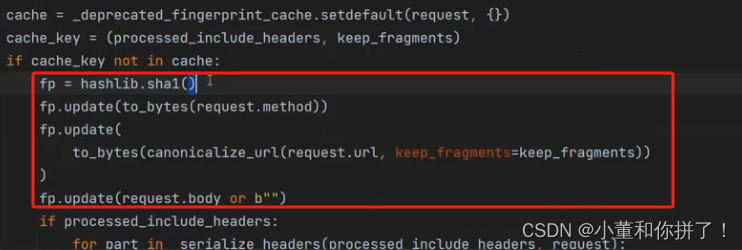
如果cache_key不在cache中即会发生圈出的重要内容,即通过哈希加密的方法可生出一个全新的fp;判断这个请求时post还是get;to_bytes(canonicalize_url(request.url,keep_fragments=keep_fragments))这句话主要是对url的加密,通过序列化url的方法;fp.update(request.body or b"")请求体加密。
scrapy部署
我们不妨设想下面的几个场景:如果采用上传文件的方式部署代码,我们首先需要将代码压缩,然后采用 SFTP或 FTP的方式将文件上传到服务器,之后再连接服务器将文件解压,每个服务器都需要这样配置。如果采用 Git 同步的方式部署代码,我们可以先把代码 Push 到某个 Git 仓库里,然后再远程连接各台主机执行 Pu 操作,同步代码,每个服务器同样需要做一次操作。如果代码突然有更新,那我们必须更新每个服务器,而且万一哪台主机的版本没控制好,还可能会影响整体的分布式爬取状况。所以我们需要一个更方便的工具来部署 Scrapy 项目,如果可以省去一遍遍逐个登录服务器部署的操作,那将会方便很多。 这样就会用到我们的分布式的工具scrapyd。
获取源码
可以把源码克隆下来,执行如下命令: git clone https://github.com/rmax/scrapy-redis.git 核心源码在 scrapy-redis/src/scrapy_redis 目录下。
爬取队列
我们从爬取队列入手,来看看它的具体实现。源码文件为 queue.py,它包含了三个队列的实 现,首先它实现了一个父类 Base,提供一些基本方法和属性,如下所示:
class Base(object): """Per-spider base queue class""" def __init__(self, server, spider, key, serializer=None): if serializer is None: serializer = picklecompat if not hasattr(serializer, 'loads'): raise TypeError("serializer does not implement 'loads' function: % r % serializer) if not hasattr(serializer, 'dumps'): raise TypeError("serializer '% s' does not implement 'dumps' functio % serializer) self.server = server self.spider = spider self.key = key % {'spider': spider.name} self.serializer = serializer def _encode_request(self, request): obj = request_to_dict(request, self.spider) return self.serializer.dumps(obj) def _decode_request(self, encoded_request): obj = self.serializer.loads(encoded_request) return request_from_dict(obj, self.spider) def __len__(self): """Return the length of the queue""" raise NotImplementedError def push(self, request): """Push a request""" raise NotImplementedError def pop(self, timeout=0): """Pop a request""" raise NotImplementedError def clear(self): """Clear queue/stack""" self.server.delete(self.key)首先看一下 _encode_request 和 _decode_request 方法,因为我们需要把一个 Request 对象 存储到数据库中,但数据库无法直接存储对象,所以需要将 Request 序列转化成字符串再存 储。 而这两个方法分别是序列化和反序列化的操作,利用 pickle 库来实现,一般在调用 push 将 Request 存入数据库时会调用 _encode_request 方法进行序列化,在调用 pop 取出 Request 的时候会调用 _decode_request 进行反序列化。 在父类中 len、push 和 pop 方法都是未实现的,会直接抛出 NotImplementedError,因此是 不能直接使用这个类的,必须实现一个子类来重写这三个方法,而不同的子类就会有不同的实 现,也就有着不同的功能。 接下来我们就需要定义一些子类来继承 Base 类,并重写这几个方法,那在源码中就有三个子 类的实现,它们分别是 FifoQueue、PriorityQueue、LifoQueue,我们分别来看下它们的实现 原理。 首先是
FifoQueue: class FifoQueue(Base): """Per-spider FIFO queue""" def __len__(self): """Return the length of the queue""" return self.server.llen(self.key) def push(self, request): """Push a request""" self.server.lpush(self.key, self._encode_request(request)) def pop(self, timeout=0): """Pop a request""" if timeout > 0: data = self.server.brpop(self.key, timeout) if isinstance(data, tuple): data = data[1] else: data = self.server.rpop(self.key) if data: return self._decode_request(data) 可以看到这个类继承了 Base 类,并重写了 len、push、pop 这三个方法,在这三个方法中都 是对 server 对象的操作,而 server 对象就是一个 Redis 连接对象,我们可以直接调用其操作 Redis 的方法对数据库进行操作,可以看到这里的操作方法有 llen、lpush、rpop 等,这就代 表此爬取队列是使用的 Redis 的列表。 序列化后的 Request 会被存入列表中,就是列表的其中一个元素,len 方法是获取列表的长 度,push 方法中调用了 lpush 操作,这代表从列表左侧存入数据,pop 方法中调用了 rpop 操 作,这代表从列表右侧取出数据。 所以 Request 在列表中的存取顺序是左侧进、右侧出,所以这是有序的进出,即先进先出, 英文叫作 First Input First Output,也被简称为 FIFO,而此类的名称就叫作 FifoQueue。 另外还有一个与之相反的实现类,叫作 LifoQueue,实现如下
class LifoQueue(Base): """Per-spider LIFO queue.""" def __len__(self): """Return the length of the stack""" return self.server.llen(self.key) def push(self, request): """Push a request""" self.server.lpush(self.key, self._encode_request(request)) def pop(self, timeout=0): """Pop a request""" if timeout > 0: data = self.server.blpop(self.key, timeout) if isinstance(data, tuple): data = data[1] else: data = self.server.lpop(self.key) if data: return self._decode_request(data)与 FifoQueue 不同的就是它的 pop 方法,在这里使用的是 lpop 操作,也就是从左侧出,而 push 方法依然是使用的 lpush 操作,是从左侧入。 那么这样达到的效果就是先进后出、后进先出,英文叫作 Last In First Out,简称为 LIFO,而 此类名称就叫作 LifoQueue。同时这个存取方式类似栈的操作,所以其实也可以称作 StackQueue。 另外在源码中还有一个子类实现,叫作 PriorityQueue,顾名思义,它叫作优先级队列,实现 如下:
class PriorityQueue(Base): """Per-spider priority queue abstraction using redis' sorted set""" def __len__(self): """Return the length of the queue""" return self.server.zcard(self.key) def push(self, request): """Push a request""" data = self._encode_request(request) score = -request.priority self.server.execute_command('ZADD', self.key, score, data) def pop(self, timeout=0): """ Pop a request timeout not support in this queue class """ pipe = self.server.pipeline() pipe.multi() pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0) results, count = pipe.execute() if results: return self._decode_request(results[0]) 在这里我们可以看到 len、push、pop 方法中使用了 server 对象的 zcard、zadd、zrange 操 作,可以知道这里使用的存储结果是有序集合 Sorted Set,在这个集合中每个元素都可以设置 一个分数,那么这个分数就代表优先级。 在 len 方法里调用了 zcard 操作,返回的就是有序集合的大小,也就是爬取队列的长度,在 push 方法中调用了 zadd 操作,就是向集合中添加元素,这里的分数指定成 Request 的优先 级的相反数,因为分数低的会排在集合的前面,所以这里高优先级的 Request 就会存在集合 的最前面。 pop 方法是首先调用了 zrange 操作取出了集合的第一个元素,因为最高优先级的 Request 会 存在集合最前面,所以第一个元素就是最高优先级的 Request,然后再调用 zremrangebyrank 操作将这个元素删除,这样就完成了取出并删除的操作。 此队列是默认使用的队列,也就是爬取队列默认是使用有序集合来存储的。
去重过滤
前面说过 Scrapy 的去重是利用集合来实现的,而在 Scrapy 分布式中的去重就需要利用共享 的集合,那么这里使用的就是 Redis 中的集合数据结构。我们来看看去重类是怎样实现的, 源码文件是 dupefilter.py,其内实现了一个 RFPDupeFilter 类,如下所示:
class RFPDupeFilter(BaseDupeFilter): """Redis-based request duplicates filter. This class can also be used with default Scrapy's scheduler. """ logger = logger def __init__(self, server, key, debug=False): """Initialize the duplicates filter. Parameters ---------- server : redis.StrictRedis The redis server instance. key : str Redis key Where to store fingerprints. debug : bool, optional Whether to log filtered requests. """ self.server = server self.key = key self.debug = debug self.logdupes = True @classmethod def from_settings(cls, settings): """Returns an instance from given settings. This uses by default the key ``dupefilter:``. When using the ``scrapy_redis.scheduler.Scheduler`` class, this method is not used as it needs to pass the spider name in the key. Parameters ---------- settings : scrapy.settings.Settings Returns ------- RFPDupeFilter A RFPDupeFilter instance. """ server = get_redis_from_settings(settings) key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())} debug = settings.getbool('DUPEFILTER_DEBUG') return cls(server, key=key, debug=debug) @classmethod def from_crawler(cls, crawler): """Returns instance from crawler. Parameters ---------- crawler : scrapy.crawler.Crawler Returns ------- RFPDupeFilter Instance of RFPDupeFilter. """ return cls.from_settings(crawler.settings) def request_seen(self, request): """Returns True if request was already seen. Parameters ---------- request : scrapy.http.Request Returns ------- bool """ fp = self.request_fingerprint(request) added = self.server.sadd(self.key, fp) return added == 0 def request_fingerprint(self, request): """Returns a fingerprint for a given request. Parameters ---------- request : scrapy.http.Request Returns ------- str """ return request_fingerprint(request) def close(self, reason=''): """Delete data on close. Called by Scrapy's scheduler. Parameters ---------- reason : str, optional """ self.clear() def clear(self): """Clears fingerprints data.""" self.server.delete(self.key) def log(self, request, spider): """Logs given request. Parameters ---------- request : scrapy.http.Request spider : scrapy.spiders.Spider """ if self.debug: msg = "Filtered duplicate request: %(request) s" self.logger.debug(msg, {'request': request}, extra={'spider': spider elif self.logdupes: msg = ("Filtered duplicate request %(request) s" "- no more duplicates will be shown" "(see DUPEFILTER_DEBUG to show all duplicates)") self.logger.debug(msg, {'request': request}, extra={'spider': spider self.logdupes = False这里同样实现了一个 request_seen 方法,和 Scrapy 中的 request_seen 方法实现极其类似。 不过这里集合使用的是 server 对象的 sadd 操作,也就是集合不再是一个简单数据结构了,而 是直接换成了数据库的存储方式。 鉴别重复的方式还是使用指纹,指纹同样是依靠 request_fingerprint 方法来获取的。获取指纹 之后就直接向集合添加指纹,如果添加成功,说明这个指纹原本不存在于集合中,返回值 1。 代码中最后的返回结果是判定添加结果是否为 0,如果刚才的返回值为 1,那这个判定结果就 是 False,也就是不重复,否则判定为重复。 这样我们就成功利用 Redis 的集合完成了指纹的记录和重复的验证。
调度器
Scrapy-Redis 还帮我们实现了配合 Queue、DupeFilter 使用的调度器 Scheduler,源文件名 称是 scheduler.py。我们可以指定一些配置,如 SCHEDULER_FLUSH_ON_START 即是否 在爬取开始的时候清空爬取队列,SCHEDULER_PERSIST 即是否在爬取结束后保持爬取队 列不清除。我们可以在 settings.py 里自由配置,而此调度器很好地实现了对接。 接下来我们看看两个核心的存取方法,实现如下所示:
def enqueue_request(self, request): if not request.dont_filter and self.df.request_seen(request): self.df.log(request, self.spider) return False if self.stats: self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider) self.queue.push(request) return True def next_request(self): block_pop_timeout = self.idle_before_close request = self.queue.pop(block_pop_timeout) if request and self.stats: self.stats.inc_value('scheduler/dequeued/redis', spider=self.spider) return request enqueue_request可以向队列中添加 Request,核心操作就是调用 Queue 的 push 操作,还 有一些统计和日志操作。next_request 就是从队列中取 Request,核心操作就是调用 Queue 的 pop 操作,此时如果队列中还有 Request,则 Request 会直接取出来,爬取继续,否则如 果队列为空,爬取则会重新开始。
Gerapy使用流程总结
使用gerapy之前要保证scrapyd 是可用的
直接在cmd里输入scrapyd,挂着别关之后的步骤如下
1.gerapy init 初始化,会在文件夹下创建一个gerapy文件夹2.cd gerapy
3.gerapy migrate
4.gerapy runserver 默认是127.0.0.1:80005.gerapy createsuperuser 创建账号密码,默认情况下都是没有的
Bloom Filter
了解Bloom Filter
当爬取达到亿级别规模时,Scrapy-Redis提供的集合去重已经不能满足我们的要求。所以我们需要使用一个更加节省内存的去重算法Bloom Filter,Bloom Filter,中文名称叫作布隆过滤器,可以被用来检测一个元素是否在一个集合中。Bloom Filter的空间利用效率很高,使用它可以大大节省存储空间。Bloom Filter使用位数组表示一个待检测集合,并可以快速地通过概率算法判断一个元素是否 存在于这个集合中。利用这个算法我们可以实现去重效果。
Bloom Filter的算法
在Bloom Filter中使用位数组来辅助实现检测判断。在初始状态下,我们声明一个包含m位的 位数组,它的所有位都是0,如下图所示。

现在我们有了一个待检测集合,其表示为S={x1, x2, …, xn}。接下来需要做的就是检测一个x是 否已经存在于集合S中。在Bloom Filter算法中,首先使用k个相互独立、随机的散列函数来将 集合S中的每个元素x1, x2, …, xn映射到长度为m的位数组上,散列函数得到的结果记作位置索 引,然后将位数组该位置索引的位置1。例如,我们取k为3,表示有三个散列函数,x1经过三 个散列函数映射得到的结果分别为1、4、8,x2经过三个散列函数映射得到的结果分别为4、 6、10,那么位数组的1、4、6、8、10这五位就会置为1,如下图所示。

如果有一个新的元素x,我们要判断x是否属于S集合,我们仍然用k个散列函数对x求映射结 果。如果所有结果对应的位数组位置均为1,那么x属于S这个集合;如果有一个不为1,则x不 属于S集合。 例如,新元素x经过三个散列函数映射的结果为4、6、8,对应的位置均为1,则x属于S集合。 如果结果为4、6、7,而7对应的位置为0,则x不属于S集合。 注意,这里m、n、k满足的关系是m>nk,也就是说位数组的长度m要比集合元素n和散列函数 k的乘积还要大。 这样的判定方法很高效,但是也是有代价的,它可能把不属于这个集合的元素误认为属于这个 集合。我们来估计一下这种方法的错误率。当集合S={x1, x2,…, xn} 的所有元素都被k个散列函 数映射到m位的位数组中时,这个位数组中某一位还是0的概率是:
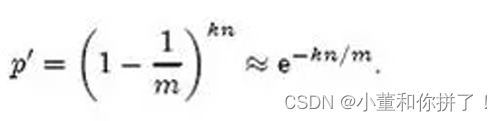
散列函数是随机的,则任意一个散列函数选中这一位的概率为1/m,那么1-1/m就代表散列函 数从未没有选中这一位的概率,要把S完全映射到m位数组中,需要做kn次散列运算,最后的 概率就是1-1/m的kn次方。 一个不属于S的元素x如果误判定为在S中,那么这个概率就是k次散列运算得到的结果对应的 位数组位置都为1,则误判概率为:
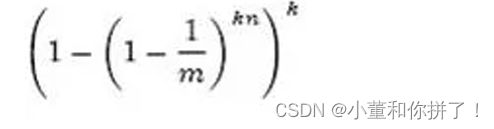
在给定m、n时,可以求出使得f最小化的k值为:
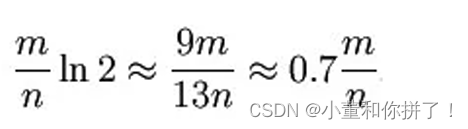
这里将误判概率归纳如下:
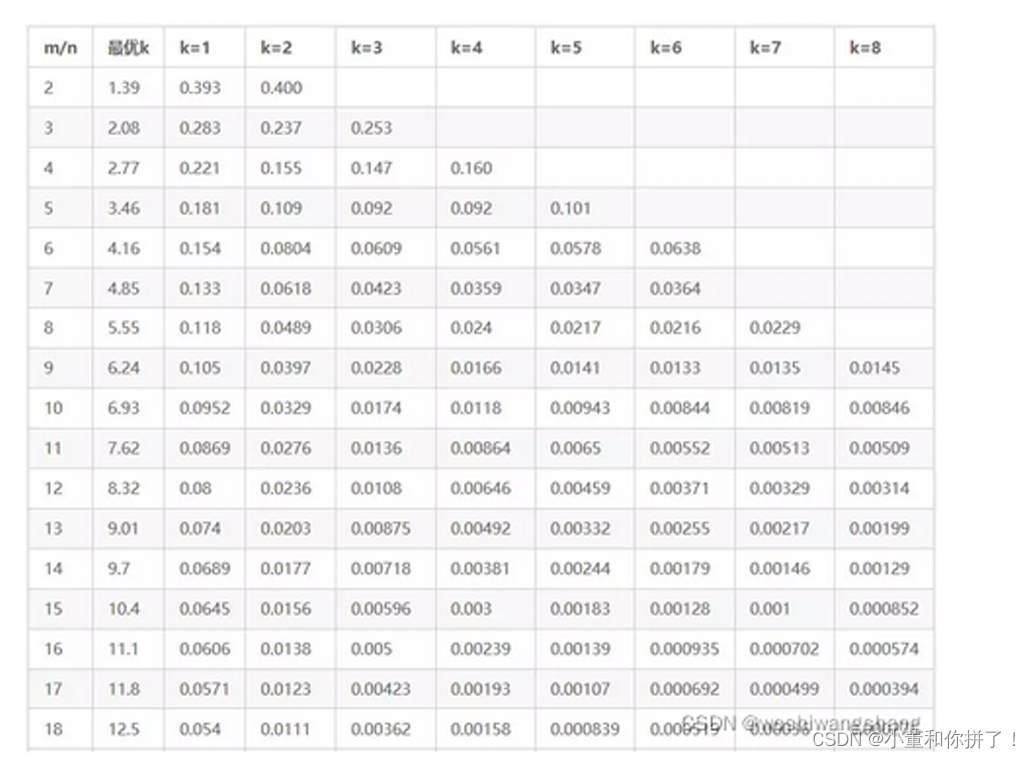
表中第一列为m/n的值,第二列为最优k值,其后列为不同k值的误判概率。当k值确定时,随 着m/n的增大,误判概率逐渐变小。当m/n的值确定时,当k越靠近最优K值,误判概率越小。 误判概率总体来看都是极小的,在容忍此误判概率的情况下,大幅减小存储空间和判定速度是 完全值得的。 接下来,我们将Bloom Filter算法应用到Scrapy-Redis分布式爬虫的去重过程中,以解决Redis 内存不足的问题。
对接Scrapy-Redis
实现Bloom Filter时,首先要保证不能破坏Scrapy-Redis分布式爬取的运行架构。我们需要修改 Scrapy-Redis的源码,将它的去重类替换掉。同时,Bloom Filter的实现需要借助于一个位数 组,既然当前架构还是依赖于Redis,那么位数组的维护直接使用Redis就好了。 首先实现一个基本的散列算法,将一个值经过散列运算后映射到一个m位数组的某一位上,代 码如下: class HashMap(object): def __init__(self, m, seed): self.m = m self.seed = seed def hash(self, value): """ Hash Algorithm :param value: Value :return: Hash Value """ ret = 0 for i in range(len(value)): ret += self.seed * ret + ord(value[i]) return (self.m 这里新建了一个HashMap类。构造函数传入两个值,一个是m位数组的位数,另一个是种子值 seed。不同的散列函数需要有不同的seed,这样可以保证不同的散列函数的结果不会碰撞。 在hash()方法的实现中,value是要被处理的内容。这里遍历了value的每一位,并利用ord()方 法取到每一位的ASCII码值,然后混淆seed进行迭代求和运算,最终得到一个数值。这个数值 的结果就由value和seed唯一确定。我们再将这个数值和m进行按位与运算,即可获取到m位数 组的映射结果,这样就实现了一个由字符串和seed来确定的散列函数。当m固定时,只要seed 值相同,散列函数就是相同的,相同的value必然会映射到相同的位置。所以如果想要构造几 个不同的散列函数,只需要改变其seed就好了。以上内容便是一个简易的散列函数的实现。 接下来我们再实现Bloom Filter。Bloom Filter里面需要用到k个散列函数,这里要对这几个散 列函数指定相同的m值和不同的seed值,构造如下: BLOOMFILTER_HASH_NUMBER = 6BLOOMFILTER_BIT = 30class BloomFilter(object): def __init__(self, server, key, bit=BLOOMFILTER_BIT, hash_number=BLOOMFILTER """ Initialize BloomFilter :param server: Redis Server :param key: BloomFilter Key :param bit: m = 2 ^ bit :param hash_number: the number of hash function """ # default to 1 kn,这里m值大约保底在10亿,由于这个数值比较大,所以这里用 移位操作来实现,传入位数bit,将其定义为30,然后做一个移位操作1<<30,相当于2的30次 方,等于1073741824,量级也是恰好在10亿左右,由于是位数组,所以这个位数组占用的大 小就是2^30 b=128 MB。开头我们计算过Scrapy-Redis集合去重的占用空间大约在2 GB左 右,可见Bloom Filter的空间利用效率极高。 随后我们再传入散列函数的个数,用它来生成几个不同的seed。用不同的seed来定义不同的 散列函数,这样我们就可以构造一个散列函数列表。遍历seed,构造带有不同seed值的 HashMap对象,然后将HashMap对象保存成变量maps供后续使用。 另外,server就是Redis连接对象,key就是这个m位数组的名称。 接下来,我们要实现比较关键的两个方法:一个是判定元素是否重复的方法exists(),另一个是 添加元素到集合中的方法insert(),实现如下: def exists(self, value): """ if value exists :param value: :return: """ if not value: return False exist = 1 for map in self.maps: offset = map.hash(value) exist = exist & self.server.getbit(self.key, offset) return exist """ add value to bloom :param value: :return: """ for f in self.maps: offset = f.hash(value) self.server.setbit(self.key, offset, 1) 首先看下insert()方法。Bloom Filter算法会逐个调用散列函数对放入集合中的元素进行运算, 得到在m位位数组中的映射位置,然后将位数组对应的位置置1。这里代码中我们遍历了初始 化好的散列函数,然后调用其hash()方法算出映射位置offset,再利用Redis的setbit()方法将该 位置1。 在exists()方法中,我们要实现判定是否重复的逻辑,方法参数value为待判断的元素。我们首 先定义一个变量exist,遍历所有散列函数对value进行散列运算,得到映射位置,用getbit()方 法取得该映射位置的结果,循环进行与运算。这样只有每次getbit()得到的结果都为1时,最后 的exist才为True,即代表value属于这个集合。如果其中只要有一次getbit()得到的结果为0,即 m位数组中有对应的0位,那么最终的结果exist就为False,即代表value不属于这个集合。 Bloom Filter的实现就已经完成了,我们可以用一个实例来测试一下,代码如下: conn = StrictRedis(host='localhost', port=6379, password='foobared') bf = BloomFilter(conn, 'testbf', 5, 6) bf.insert('Hello') bf.insert('World') result = bf.exists('Hello') print(bool(result)) result = bf.exists('Python') print(bool(result)) 这里首先定义了一个Redis连接对象,然后传递给Bloom Filter。为了避免内存占用过大,这里 传的位数bit比较小,设置为5,散列函数的个数设置为6。 调用insert()方法插入Hello和World两个字符串,随后判断Hello和Python这两个字符串是否存 在,最后输出它的结果,运行结果如下: TrueFalse 很明显,结果完全没有问题。这样我们就借助Redis成功实现了Bloom Filter的算法。 接下来继续修改Scrapy-Redis的源码,将它的dupefilter逻辑替换为Bloom Filter的逻辑。这里 主要是修改RFPDupeFilter类的request_seen()方法,实现如下: def request_seen(self, request): fp = self.request_fingerprint(request) self.bf.insert(fp) return False if self.bf.exists(fp): 利用request_fingerprint()方法获取Request的指纹,调用Bloom Filter的exists()方法判定该指纹 是否存在。如果存在,则说明该Request是重复的,返回True,否则调用Bloom Filter的insert() 方法将该指纹添加并返回False。这样就成功利用Bloom Filter替换了Scrapy-Redis的集合去 重。 对于Bloom Filter的初始化定义,我们可以将__init__()方法修改为如下内容: def __init__(self, server, key, debug, bit, hash_number): self.server = server self.key = key self.debug = debug self.bit = bit self.hash_number = hash_number self.logdupes = True self.bf = BloomFilter(server, self.key, bit, hash_number) 其中bit和hash_number需要使用from_se ngs()方法传递,修改如下: @classmethoddef from_settings(cls, settings): server = get_redis_from_settings(settings) key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())} debug = settings.getbool('DUPEFILTER_DEBUG', DUPEFILTER_DEBUG) bit = settings.getint('BLOOMFILTER_BIT', BLOOMFILTER_BIT) hash_number = settings.getint('BLOOMFILTER_HASH_NUMBER', BLOOMFILTER_HASH_NU 其中,常量DUPEFILTER_DEBUG和BLOOMFILTER_BIT统一定义在defaults.py中,默认如 下: BLOOMFILTER_HASH_NUMBER = 6BLOOMFILTER_BIT = 30 现在,我们成功实现了Bloom Filter和Scrapy-Redis的对接。 为了方便使用,本节的代码已经打包成一个Python包并发布到PyPi,链接为 h ps://pypi.python.org/pypi/scrapy-redis-bloomfilter,可以直接使用 ScrapyRedisBloomFilter,不需要自己实现一遍。 我们可以直接使用pip来安装,命令如下: pip3 install scrapy-redis-bloomfilter 使用的方法和Scrapy-Redis基本相似,在这里说明几个关键配置。 # 去重类,要使用Bloom Filter请替换DUPEFILTER_CLASSDUPEFILTER_CLASS = "scrapy_redis_ DUPEFILTER_CLASS是去重类,如果要使用Bloom Filter,则DUPEFILTER_CLASS需要 修改为该包的去重类。 BLOOMFILTER_HASH_NUMBER是Bloom Filter使用的散列函数的个数,默认为6,可 以根据去重量级自行修改。 BLOOMFILTER_BIT即前文所介绍的BloomFilter类的bit参数,它决定了位数组的位数。 如果BLOOMFILTER_BIT为30,那么位数组位数为2的30次方,这将占用Redis 128 MB 的存储空间,去重量级在1亿左右,即对应爬取量级1亿左右。如果爬取量级在10亿、20 亿甚至100亿,请务必将此参数对应调高。 源代码附有一个测试项目,放在tests文件夹,该项目使用了ScrapyRedisBloomFilter来去重, Spider的实现如下 from scrapy import Request, Spiderclass TestSpider(Spider): name = 'test' base_url = 'https://www.baidu.com/s?wd=' def start_requests(self): for i in range(10): url = self.base_url + str(i) yield Request(ur for i in range(100): url = self.base_url + str(i) yield Request(ur self.logger.debug('Response of ' + response.url) start_requests()方法首先循环10次,构造参数为0 99的 URL。那么这里就会包含10个重复的Request,我们运行项目测试一下: scrapy crawl test {'bloomfilter/filtered': 10, 'downloader/request_bytes': 34021, 'downloader/requ 最后统计的第一行的结果: 'bloomfilter/filtered': 10, 这就是Bloom Filter过滤后的统计结果,它的过滤个数为10个,也就是它成功将重复的10个 Reqeust识别出来了,测试通过。 以上内容便是Bloom Filter的原理及对接实现,Bloom Filter的使用可以大大节省Redis内存。 在数据量大的情况下推荐此方案。
exists()方法和insert()方法
接下来,我们要实现比较关键的两个方法:一个是判定元素是否重复的方法exists() ,另一个是添加元素到集合中的方法insert() ,实现如下:
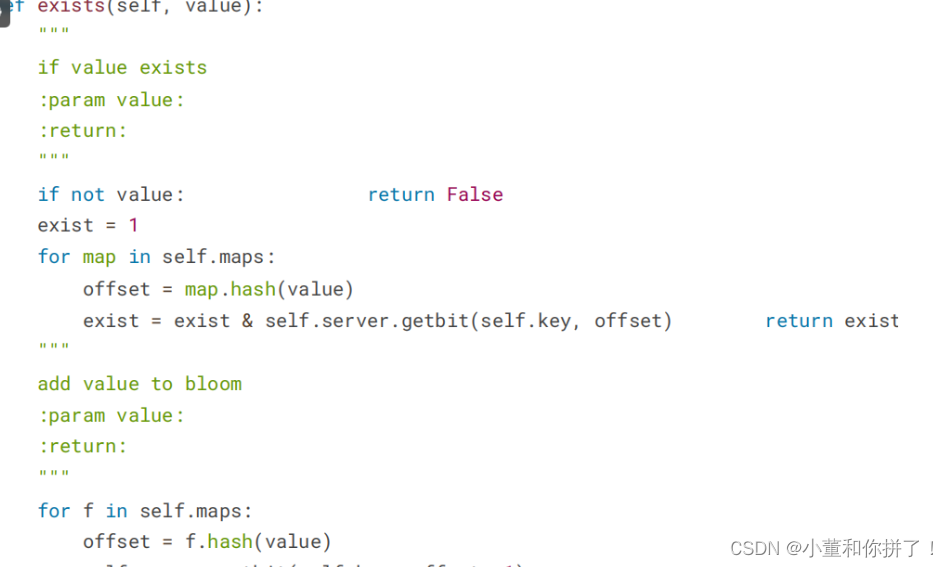
首先看下insert() 方法。 Bloom Filter 算法会逐个调用散列函数对放入集合中的元素进行运算,得到在m 位位数组中的映射位置,然后将位数组对应的位置置 1 。这里代码中我们遍历了初始化好的散列函数,然后调用其hash() 方法算出映射位置 offset ,再利用 Redis 的 setbit() 方法将该位置 。
在exists() 方法中,我们要实现判定是否重复的逻辑,方法参数 value 为待判断的元素。我们首先定义一个变量exist ,遍历所有散列函数对 value 进行散列运算,得到映射位置,用 getbit() 方法取得该映射位置的结果,循环进行与运算。这样只有每次getbit() 得到的结果都为 1 时,最后的exist 才为 True ,即代表 value 属于这个集合。如果其中只要有一次 getbit() 得到的结果为 0 ,即m位数组中有对应的 0 位,那么最终的结果 exist 就为 False ,即代表 value 不属于这个集合。
例如:
conn = StrictRedis(host='localhost', port=6379, password='foobared')
bf = BloomFilter(conn, 'testbf', 5, 6)
bf.insert('Hello')
bf.insert('World')
result = bf.exists('Hello')
print(bool(result))
result = bf.exists('Python')
print(bool(result))首先定义了一个Redis连接对象,然后传递给Bloom Filter。为了避免内存占用过大,这里传的位数bit比较小,设置为5,散列函数的个数设置为6。调用insert()方法插入Hello和World两个字符串,随后判断Hello和Python这两个字符串是否存在,最后输出它的结果。
接下来继续修改Scrapy-Redis 的源码,将它的 dupefilter 逻辑替换为 Bloom Filter 的逻辑。这里主要是修改RFPDupeFilter 类的 request_seen() 方法,实现如下:
def request_seen(self, request):
fp = self.request_fingerprint(request)
if self.bf.exists(fp):
self.bf.insert(fp)
return False利用request_fingerprint() 方法获取 Request 的指纹,调用 Bloom Filter 的 exists() 方法判定该指纹是否存在。如果存在,则说明该Request 是重复的,返回 True ,否则调用 Bloom Filter 的 insert()方法将该指纹添加并返回False 。这样就成功利用 Bloom Filter 替换了 Scrapy-Redis 的集合去重。
对于Bloom Filter的初始化定义,我们可以将__init__()方法修改为如下内容:
def __init__(self, server, key, debug, bit, hash_number):
self.server = server
self.key = key
self.debug = debug
self.bit = bit
self.hash_number = hash_number
self.logdupes = True
self.bf = BloomFilter(server, self.key, bit, hash_number)其中bit 和 hash_number 需要使用 from_setti ngs() 方法传递,修改如下:

其中,常量 DUPEFILTER_DEBUG 和 BLOOMFILTER_BIT 统一定义在 defaults.py 中,默认如下
BLOOMFILTER_HASH_NUMBER = 6BLOOMFILTER_BIT = 30我们可以直接使用 pip 来安装,命令如下:
pip install scrapy - redis - bloomfilter
使用的方法和 Scrapy-Redis 基本相似,在这里说明几个关键配置。
DUPEFILTER_CLASS 是去重类,如果要使用 Bloom Filter ,则 DUPEFILTER_CLASS 需要修改为该包的去重类。
BLOOMFILTER_HASH_NUMBER 是 Bloom Filter 使用的散列函数的个数,默认为 6 ,可以根据去重量级自行修改。
BLOOMFILTER_BIT 即前文所介绍的 BloomFilter 类的 bit 参数,它决定了位数组的位数。如果BLOOMFILTER_BIT 为 30 ,那么位数组位数为 2 的 30 次方,这将占用 Redis 128 MB的存储空间,去重量级在1 亿左右,即对应爬取量级 1 亿左右。如果爬取量级在 10 亿、 20亿甚至100 亿,请务必将此参数对应调高。
网站登录验证主要有两种实现,一种是基于 Session + Cookies 的登录验证,另一种是基于 JWT 的登录验证,那么本课时我们就通过两个实例来分别讲解这两种登录验证的分析和模拟登录流程。
模拟登录
准备工作
在本课时开始之前,请你确保已经做好了如下准备工作:
-
安装好了 Python (最好 3.6 及以上版本)并能成功运行 Python 程序;
-
安装好了 requests 请求库并学会了其基本用法;
-
安装好了 Selenium 库并学会了其基本用法。
案例介绍
这里有两个需要登录才能抓取的网站,链接为Scrape | Movie和Scrape | Book,前者是基于 Session + Cookies 认证的网站,后者是基于 JWT 认证的网站。
首先看下第一个网站,打开后会看到如图所示的页面。  它直接跳转到了登录页面,这里用户名和密码都是 admin,我们输入之后登录。
它直接跳转到了登录页面,这里用户名和密码都是 admin,我们输入之后登录。
登录成功之后,我们便看到了熟悉的电影网站的展示页面,如图所示。  这个网站是基于传统的 MVC 模式开发的,因此也比较适合 Session + Cookies 的认证。
这个网站是基于传统的 MVC 模式开发的,因此也比较适合 Session + Cookies 的认证。
第二个网站打开后同样会跳到登录页面,如图所示。  用户名和密码是一样的,都输入 admin 即可登录。
用户名和密码是一样的,都输入 admin 即可登录。
登录之后会跳转到首页,展示了一些书籍信息,如图所示。  这个页面是前后端分离式的页面,数据的加载都是通过 Ajax 请求后端 API 接口获取,登录的校验是基于 JWT 的,同时后端每个 API 都会校验 JWT 是否是有效的,如果无效则不会返回数据。
这个页面是前后端分离式的页面,数据的加载都是通过 Ajax 请求后端 API 接口获取,登录的校验是基于 JWT 的,同时后端每个 API 都会校验 JWT 是否是有效的,如果无效则不会返回数据。
案例一
接下来我们就分析这两个案例并实现模拟登录吧。
对于案例一,我们如果要模拟登录,就需要先分析下登录过程究竟发生了什么,首先我们打开Scrape | Movie,然后执行登录操作,查看其登录过程中发生的请求,如图所示。  这里我们可以看到其登录的瞬间是发起了一个 POST 请求,目标 URL 为 https://login2.scrape.cuiqingcai.com/login,通过表单提交的方式提交了登录数据,包括 username 和 password 两个字段,返回的状态码是 302,Response Headers 的 location 字段是根页面,同时 Response Headers 还包含了 set-cookie 信息,设置了 Session ID。
这里我们可以看到其登录的瞬间是发起了一个 POST 请求,目标 URL 为 https://login2.scrape.cuiqingcai.com/login,通过表单提交的方式提交了登录数据,包括 username 和 password 两个字段,返回的状态码是 302,Response Headers 的 location 字段是根页面,同时 Response Headers 还包含了 set-cookie 信息,设置了 Session ID。
由此我们可以发现,要实现模拟登录,我们只需要模拟这个请求就好了,登录完成之后获取 Response 设置的 Cookies,将 Cookies 保存好,以后后续的请求带上 Cookies 就可以正常访问了。
好,那么我们接下来用代码实现一下吧。
requests 默认情况下每次请求都是独立互不干扰的,比如我们第一次先调用了 post 方法模拟登录,然后紧接着再调用 get 方法请求下主页面,其实这是两个完全独立的请求,第一次请求获取的 Cookies 并不能传给第二次请求,因此说,常规的顺序调用是不能起到模拟登录的效果的。
我们先来看一个无效的代码: import requests from urllib.parse import urljoin
BASE_URL = 'https://login2.scrape.cuiqingcai.com/' LOGIN_URL = urljoin(BASE_URL, '/login') INDEX_URL = urljoin(BASE_URL, '/page/1') USERNAME = 'admin' PASSWORD = 'admin'
response_login = requests.post(LOGIN_URL, data={ 'username': USERNAME, 'password': PASSWORD })
response_index = requests.get(INDEX_URL) print('Response Status', response_index.status_code) print('Response URL', response_index.url) 这里我们先定义了几个基本的 URL 和用户名、密码,接下来分别用 requests 请求了登录的 URL 进行模拟登录,然后紧接着请求了首页来获取页面内容,但是能正常获取数据吗?
由于 requests 可以自动处理重定向,我们最后把 Response 的 URL 打印出来,如果它的结果是 INDEX_URL,那么就证明模拟登录成功并成功爬取到了首页的内容。如果它跳回到了登录页面,那就说明模拟登录失败。
我们通过结果来验证一下,运行结果如下:
Response Status 200 Response URL https://login2.scrape.cuiqingcai.com/login?next=/page/1
这里可以看到,其最终的页面 URL 是登录页面的 URL,另外这里也可以通过 response 的 text 属性来验证页面源码,其源码内容就是登录页面的源码内容,由于内容较多,这里就不再输出比对了。
总之,这个现象说明我们并没有成功完成模拟登录,这是因为 requests 直接调用 post、get 等方法,每次请求都是一个独立的请求,都相当于是新开了一个浏览器打开这些链接,这两次请求对应的 Session 并不是同一个,因此这里我们模拟了第一个 Session 登录,而这并不能影响第二个 Session 的状态,因此模拟登录也就无效了。 那么怎样才能实现正确的模拟登录呢?
我们知道 Cookies 里面是保存了 Session ID 信息的,刚才也观察到了登录成功后 Response Headers 里面是有 set-cookie 字段,实际上这就是让浏览器生成了 Cookies。
Cookies 里面包含了 Session ID 的信息,所以只要后续的请求携带这些 Cookies,服务器便能通过 Cookies 里的 Session ID 信息找到对应的 Session,因此服务端对于这两次请求就会使用同一个 Session 了。而因为第一次我们已经完成了模拟登录,所以第一次模拟登录成功后,Session 里面就记录了用户的登录信息,第二次访问的时候,由于是同一个 Session,服务器就能知道用户当前是登录状态,就可以返回正确的结果而不再是跳转到登录页面了。
所以,这里的关键就在于两次请求的 Cookies 的传递。所以这里我们可以把第一次模拟登录后的 Cookies 保存下来,在第二次请求的时候加上这个 Cookies 就好了,所以代码可以改写如下:
import requests
from urllib.parse import urljoin
BASE_URL = 'https://login2.scrape.cuiqingcai.com/'
LOGIN_URL = urljoin(BASE_URL, '/login')
INDEX_URL = urljoin(BASE_URL, '/page/1')
USERNAME = 'admin'
PASSWORD = 'admin'
response_login = requests.post(LOGIN_URL, data={
'username': USERNAME,
'password': PASSWORD
}, allow_redirects=False)
cookies = response_login.cookies
print('Cookies', cookies)
response_index = requests.get(INDEX_URL, cookies=cookies)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)
由于 requests 可以自动处理重定向,所以模拟登录的过程我们要加上 allow_redirects 参数并设置为 False,使其不自动处理重定向,这里登录之后返回的 Response 我们赋值为 response_login,这样通过调用 response_login 的 cookies 就可以获取到网站的 Cookies 信息了,这里 requests 自动帮我们解析了 Response Headers 的 set-cookie 字段并设置了 Cookies,所以我们不需要手动解析 Response Headers 的内容了,直接使用 response_login 对象的 cookies 属性即可获取 Cookies。
好,接下来我们再次用 requests 的 get 方法来请求网站的 INDEX_URL,不过这里和之前不同,get 方法多加了一个参数 cookies,这就是第一次模拟登录完之后获取的 Cookies,这样第二次请求就能携带第一次模拟登录获取的 Cookies 信息了,此时网站会根据 Cookies 里面的 Session ID 信息查找到同一个 Session,校验其已经是登录状态,然后返回正确的结果。
这里我们还是输出了最终的 URL,如果其是 INDEX_URL,那就代表模拟登录成功并获取到了有效数据,否则就代表模拟登录失败。
我们看下运行结果:
Cookies <RequestsCookieJar[<Cookie sessionid=psnu8ij69f0ltecd5wasccyzc6ud41tc for login2.scrape.cuiqingcai.com/>]> Response Status 200 Response URL https://login2.scrape.cuiqingcai.com/page/1
这下就没有问题了,这次我们发现其 URL 就是 INDEX_URL,模拟登录成功了!同时还可以进一步输出 response_index 的 text 属性看下是否获取成功。
接下来后续的爬取用同样的方式爬取即可。
但是我们发现其实这种实现方式比较烦琐,每次还需要处理 Cookies 并进行一次传递,有没有更简便的方法呢?
有的,我们可以直接借助于 requests 内置的 Session 对象来帮我们自动处理 Cookies,使用了 Session 对象之后,requests 会将每次请求后需要设置的 Cookies 自动保存好,并在下次请求时自动携带上去,就相当于帮我们维持了一个 Session 对象,这样就更方便了。
所以,刚才的代码可以简化如下:
import requests
from urllib.parse import urljoin
BASE_URL = 'https://login2.scrape.cuiqingcai.com/'
LOGIN_URL = urljoin(BASE_URL, '/login')
INDEX_URL = urljoin(BASE_URL, '/page/1')
USERNAME = 'admin'
PASSWORD = 'admin'
session = requests.Session()
response_login = session.post(LOGIN_URL, data={
'username': USERNAME,
'password': PASSWORD
})
cookies = session.cookies
print('Cookies', cookies)
response_index = session.get(INDEX_URL)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)
可以看到,这里我们无需再关心 Cookies 的处理和传递问题,我们声明了一个 Session 对象,然后每次调用请求的时候都直接使用 Session 对象的 post 或 get 方法就好了。
运行效果是完全一样的,结果如下:
Cookies <RequestsCookieJar[<Cookie sessionid=ssngkl4i7en9vm73bb36hxif05k10k13 for login2.scrape.cuiqingcai.com/>]> Response Status 200 Response URL https://login2.scrape.cuiqingcai.com/page/1
因此,为了简化写法,这里建议直接使用 Session 对象来进行请求,这样我们就无需关心 Cookies 的操作了,实现起来会更加方便。
这个案例整体来说比较简单,但是如果碰上复杂一点的网站,如带有验证码,带有加密参数等等,直接用 requests 并不好处理模拟登录,如果登录不了,那岂不是整个页面都没法爬了吗?那么有没有其他的方式来解决这个问题呢?当然是有的,比如说,我们可以使用 Selenium 来通过模拟浏览器的方式实现模拟登录,然后获取模拟登录成功后的 Cookies,再把获取的 Cookies 交由 requests 等来爬取就好了。
这里我们还是以刚才的页面为例,我们可以把模拟登录这块交由 Selenium 来实现,后续的爬取交由 requests 来实现,代码实现如下:
from urllib.parse import urljoin
from selenium import webdriver
import requests
import time
BASE_URL = 'https://login2.scrape.cuiqingcai.com/'
LOGIN_URL = urljoin(BASE_URL, '/login')
INDEX_URL = urljoin(BASE_URL, '/page/1')
USERNAME = 'admin'
PASSWORD = 'admin'
browser = webdriver.Chrome()
browser.get(BASE_URL)
browser.find_element_by_css_selector('input[name="username"]').send_keys(USERNAME)
browser.find_element_by_css_selector('input[name="password"]').send_keys(PASSWORD)
browser.find_element_by_css_selector('input[type="submit"]').click()
time.sleep(10)
# get cookies from selenium
cookies = browser.get_cookies()
print('Cookies', cookies)
browser.close()
# set cookies to requests
session = requests.Session()
for cookie in cookies:
session.cookies.set(cookie['name'], cookie['value'])
response_index = session.get(INDEX_URL)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)
这里我们使用 Selenium 先打开了 Chrome 浏览器,然后跳转到了登录页面,随后模拟输入了用户名和密码,接着点击了登录按钮,这时候我们可以发现浏览器里面就提示登录成功,然后成功跳转到了主页面。
这时候,我们通过调用 get_cookies 方法便能获取到当前浏览器所有的 Cookies,这就是模拟登录成功之后的 Cookies,用这些 Cookies 我们就能访问其他的数据了。
接下来,我们声明了 requests 的 Session 对象,然后遍历了刚才的 Cookies 并设置到 Session 对象的 cookies 上面去,接着再拿着这个 Session 对象去请求 INDEX_URL,也就能够获取到对应的信息而不会跳转到登录页面了。
运行结果如下:
Cookies [{'domain': 'login2.scrape.cuiqingcai.com', 'expiry': 1589043753.553155, 'httpOnly': True, 'name': 'sessionid', 'path': '/', 'sameSite': 'Lax', 'secure': False, 'value': 'rdag7ttjqhvazavpxjz31y0tmze81zur'}]
Response Status 200
Response URL https://login2.scrape.cuiqingcai.com/page/1
可以看到这里的模拟登录和后续的爬取也成功了。所以说,如果碰到难以模拟登录的过程,我们也可以使用 Selenium 或 Pyppeteer 等模拟浏览器操作的方式来实现,其目的就是取到登录后的 Cookies,有了 Cookies 之后,我们再用这些 Cookies 爬取其他页面就好了。
所以这里我们也可以发现,对于基于 Session + Cookies 验证的网站,模拟登录的核心要点就是获取 Cookies,这个 Cookies 可以被保存下来或传递给其他的程序继续使用。甚至说可以将 Cookies 持久化存储或传输给其他终端来使用。另外,为了提高 Cookies 利用率或降低封号几率,可以搭建一个 Cookies 池实现 Cookies 的随机取用。
案例二
对于案例二这种基于 JWT 的网站,其通常都是采用前后端分离式的,前后端的数据传输依赖于 Ajax,登录验证依赖于 JWT 本身这个 token 的值,如果 JWT 这个 token 是有效的,那么服务器就能返回想要的数据。
下面我们先来在浏览器里面操作登录,观察下其网络请求过程,如图所示。  这里我们发现登录时其请求的 URL 为Scrape | Book,是通过 Ajax 请求的,同时其 Request Body 是 JSON 格式的数据,而不是 Form Data,返回状态码为 200。
这里我们发现登录时其请求的 URL 为Scrape | Book,是通过 Ajax 请求的,同时其 Request Body 是 JSON 格式的数据,而不是 Form Data,返回状态码为 200。
然后再看下返回结果,如图所示。 可以看到返回结果是一个 JSON 格式的数据,包含一个 token 字段,其结果为:
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNTg3ODc3OTQ2LCJlbWFpbCI6ImFkbWluQGFkbWluLmNvbSIsIm9yaWdfaWF0IjoxNTg3ODM0NzQ2fQ.ujEXXAZcCDyIfRLs44i_jdfA3LIp5Jc74n-Wq2udCR8
这就是我们上一课时所讲的 JWT 的内容,格式是三段式的,通过“.”来分隔。
那么有了这个 JWT 之后,后续的数据怎么获取呢?下面我们再来观察下后续的请求内容,如图所示。  这里我们可以发现,后续获取数据的 Ajax 请求中的 Request Headers 里面就多了一个 Authorization 字段,其结果为 jwt 然后加上刚才的 JWT 的内容,返回结果就是 JSON 格式的数据。
这里我们可以发现,后续获取数据的 Ajax 请求中的 Request Headers 里面就多了一个 Authorization 字段,其结果为 jwt 然后加上刚才的 JWT 的内容,返回结果就是 JSON 格式的数据。  没有问题,那模拟登录的整个思路就简单了: 模拟请求登录结果,带上必要的登录信息,获取 JWT 的结果。
没有问题,那模拟登录的整个思路就简单了: 模拟请求登录结果,带上必要的登录信息,获取 JWT 的结果。
后续的请求在 Request Headers 里面加上 Authorization 字段,值就是 JWT 对应的内容。 好,接下来我们用代码实现如下:
import requests
from urllib.parse import urljoin
BASE_URL = 'https://login3.scrape.cuiqingcai.com/'
LOGIN_URL = urljoin(BASE_URL, '/api/login')
INDEX_URL = urljoin(BASE_URL, '/api/book')
USERNAME = 'admin'
PASSWORD = 'admin'
response_login = requests.post(LOGIN_URL, json={
'username': USERNAME,
'password': PASSWORD
})
data = response_login.json()
print('Response JSON', data)
jwt = data.get('token')
print('JWT', jwt)
headers = {
'Authorization': f'jwt {jwt}'
}
response_index = requests.get(INDEX_URL, params={
'limit': 18,
'offset': 0
}, headers=headers)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)
print('Response Data', response_index.json())
这里我们同样是定义了登录接口和获取数据的接口,分别为 LOGIN_URL 和 INDEX_URL,接着通过 post 请求进行了模拟登录,这里提交的数据由于是 JSON 格式,所以这里使用 json 参数来传递。接着获取了返回结果中包含的 JWT 的结果。第二步就可以构造 Request Headers,然后设置 Authorization 字段并传入 JWT 即可,这样就能成功获取数据了。
运行结果如下:
Response JSON {'token': 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNTg3ODc4NzkxLCJlbWFpbCI6ImFkbWluQGFkbWluLmNvbSIsIm9yaWdfaWF0IjoxNTg3ODM1NTkxfQ.iUnu3Yhdi_a-Bupb2BLgCTUd5yHL6jgPhkBPorCPvm4'}
JWT eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNTg3ODc4NzkxLCJlbWFpbCI6ImFkbWluQGFkbWluLmNvbSIsIm9yaWdfaWF0IjoxNTg3ODM1NTkxfQ.iUnu3Yhdi_a-Bupb2BLgCTUd5yHL6jgPhkBPorCPvm4
Response Status 200
Response URL https://login3.scrape.cuiqingcai.com/api/book/?limit=18&offset=0
Response Data {'count': 9200, 'results': [{'id': '27135877', 'name': '校园市场:布局未来消费群,决战年轻人市场', 'authors': ['单兴华', '李烨'], 'cover': 'https://img9.doubanio.com/view/subject/l/public/s29539805.jpg', 'score': '5.5'},
...
{'id': '30289316', 'name': '就算這樣,還是喜歡你,笠原先生', 'authors': ['おまる'], 'cover': 'https://img3.doubanio.com/view/subject/l/public/s29875002.jpg', 'score': '7.5'}]}
可以看到,这里成功输出了 JWT 的内容,同时最终也获取到了对应的数据,模拟登录成功!
类似的思路,如果我们遇到 JWT 认证的网站,也可以通过类似的方式来实现模拟登录。当然可能某些页面比较复杂,需要具体情况具体分析。
反屏蔽
注意一下以下所有练习网站可能有已经失效的参考Python爬虫案例 | Scrape Center即可
现在很多网站都加上了对 Selenium 的检测,来防止一些爬虫的恶意爬取。即如果检测到有人在使用 Selenium 打开浏览器,那就直接屏蔽。
其大多数情况下,检测基本原理是检测当前浏览器窗口下的 window.navigator 对象是否包含 webdriver 这个属性。因为在正常使用浏览器的情况下,这个属性是 undefined,然而一旦我们使用了 Selenium,Selenium 会给 window.navigator 设置 webdriver 属性。很多网站就通过 JavaScript 判断如果 webdriver 属性存在,那就直接屏蔽。
这边有一个典型的案例网站:https://antispider1.scrape.cuiqingcai.com/,这个网站就是使用了上述原理实现了 WebDriver 的检测,如果使用 Selenium 直接爬取的话,那就会返回如下页面:  这时候我们可能想到直接使用 JavaScript 直接把这个 webdriver 属性置空,比如通过调用 execute_script 方法来执行如下代码:
这时候我们可能想到直接使用 JavaScript 直接把这个 webdriver 属性置空,比如通过调用 execute_script 方法来执行如下代码:
Object.defineProperty(navigator, "webdriver", {get: () => undefined})
这行 JavaScript 的确是可以把 webdriver 属性置空,但是 execute_script 调用这行 JavaScript 语句实际上是在页面加载完毕之后才执行的,执行太晚了,网站早在最初页面渲染之前就已经对 webdriver 属性进行了检测,所以用上述方法并不能达到效果。
在 Selenium 中,我们可以使用 CDP(即 Chrome Devtools-Protocol,Chrome 开发工具协议)来解决这个问题,通过 CDP 我们可以实现在每个页面刚加载的时候执行 JavaScript 代码,执行的 CDP 方法叫作 Page.addScriptToEvaluateOnNewDocument,然后传入上文的 JavaScript 代码即可,这样我们就可以在每次页面加载之前将 webdriver 属性置空了。另外我们还可以加入几个选项来隐藏 WebDriver 提示条和自动化扩展信息,代码实现如下:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(options=option)
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'
})
browser.get('https://antispider1.scrape.cuiqingcai.com/')
这样整个页面就能被加载出来了:  对于大多数的情况,以上的方法均可以实现 Selenium 反屏蔽。但对于一些特殊的网站,如果其有更多的 WebDriver 特征检测,可能需要具体排查。 上面的案例在运行的时候,我们可以观察到其总会弹出一个浏览器窗口,虽然有助于观察页面爬取状况,但在有些时候窗口弹来弹去也会形成一些干扰。
对于大多数的情况,以上的方法均可以实现 Selenium 反屏蔽。但对于一些特殊的网站,如果其有更多的 WebDriver 特征检测,可能需要具体排查。 上面的案例在运行的时候,我们可以观察到其总会弹出一个浏览器窗口,虽然有助于观察页面爬取状况,但在有些时候窗口弹来弹去也会形成一些干扰。
Chrome 浏览器从 60 版本已经支持了无头模式,即 Headless。无头模式在运行的时候不会再弹出浏览器窗口,减少了干扰,而且它减少了一些资源的加载,如图片等资源,所以也在一定程度上节省了资源加载时间和网络带宽。
我们可以借助于 ChromeOptions 来开启 Chrome Headless 模式,代码实现如下:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_argument('--headless')
browser = webdriver.Chrome(options=option)
browser.set_window_size(1366, 768)
browser.get('https://www.baidu.com')
browser.get_screenshot_as_file('preview.png')
这里我们通过 ChromeOptions 的 add_argument 方法添加了一个参数 --headless,开启了无头模式。在无头模式下,我们最好需要设置下窗口的大小,接着打开页面,最后我们调用 get_screenshot_as_file 方法输出了页面的截图。
运行代码之后,我们发现 Chrome 窗口就不会再弹出来了,代码依然正常运行,最后输出了页面截图如图所示。  这样我们就在无头模式下完成了页面的抓取和截图操作。
这样我们就在无头模式下完成了页面的抓取和截图操作。
现在,我们基本对 Selenium 的常规用法有了大体的了解。使用 Selenium,处理 JavaScript 渲染的页面不再是难事。 但是把实际上还是很容易暴毙,如何真的想比较完美的消除指纹需要使用一些黑科技 stealth.min.js 它的本质是一段js脚本,可以帮我们消除指纹
option.add_argument(
'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36')
option.add_argument('--disable-blink-features=AutomationControlled')
driver_path = r'C:\\Python39\\chromedriver.exe' # 定义好路径
driver = webdriver.Chrome(executable_path=driver_path, options=option) # 初始化路径+规避检测
with open('stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
这里还有一个检测网站
'https://bot.sannysoft.com/'
可以自行对比浏览器环境,注意js软件包需要随浏览器的版本更迭调整
Pyppeteer 介绍
在前面我们学习了 Selenium 的基本用法,它功能的确非常强大,但很多时候我们会发现 Selenium 有一些不太方便的地方,比如环境的配置,得安装好相关浏览器,比如 Chrome、Firefox 等等,然后还要到官方网站去下载对应的驱动,最重要的还需要安装对应的 Python Selenium 库,而且版本也得好好看看是否对应,确实不是很方便,另外如果要做大规模部署的话,环境配置的一些问题也是个头疼的事情。
那么本课时我们就介绍另一个类似的替代品,叫作 Pyppeteer。注意,是叫作 Pyppeteer,而不是 Puppeteer。
Puppeteer 是 Google 基于 Node.js 开发的一个工具,有了它我们可以通过 JavaScript 来控制 Chrome 浏览器的一些操作,当然也可以用作网络爬虫上,其 API 极其完善,功能非常强大,Selenium 当然同样可以做到。
而 Pyppeteer 又是什么呢?它实际上是 Puppeteer 的 Python 版本的实现,但它不是 Google 开发的,是一位来自于日本的工程师依据 Puppeteer 的一些功能开发出来的非官方版本。
在 Pyppetter 中,实际上它背后也是有一个类似 Chrome 浏览器的 Chromium 浏览器在执行一些动作进行网页渲染,首先说下 Chrome 浏览器和 Chromium 浏览器的渊源。
Chromium 是谷歌为了研发 Chrome 而启动的项目,是完全开源的。二者基于相同的源代码构建,Chrome 所有的新功能都会先在 Chromium 上实现,待验证稳定后才会移植,因此 Chromium 的版本更新频率更stealth高,也会包含很多新的功能,但作为一款独立的浏览器,Chromium 的用户群体要小众得多。两款浏览器“同根同源”,它们有着同样的 Logo,但配色不同,Chrome 由蓝红绿黄四种颜色组成,而 Chromium 由不同深度的蓝色构成。
 Pyppeteer 就是依赖于 Chromium 这个浏览器来运行的。那么有了 Pyppeteer 之后,我们就可以免去那些烦琐的环境配置等问题。如果第一次运行的时候,Chromium 浏览器没有安装,那么程序会帮我们自动安装和配置,就免去了烦琐的环境配置等工作。另外 Pyppeteer 是基于 Python 的新特性 async 实现的,所以它的一些执行也支持异步操作,效率相对于 Selenium 来说也提高了。
Pyppeteer 就是依赖于 Chromium 这个浏览器来运行的。那么有了 Pyppeteer 之后,我们就可以免去那些烦琐的环境配置等问题。如果第一次运行的时候,Chromium 浏览器没有安装,那么程序会帮我们自动安装和配置,就免去了烦琐的环境配置等工作。另外 Pyppeteer 是基于 Python 的新特性 async 实现的,所以它的一些执行也支持异步操作,效率相对于 Selenium 来说也提高了。
安装
首先就是安装问题了,由于 Pyppeteer 采用了 Python 的 async 机制,所以其运行要求的 Python 版本为 3.5 及以上。
安装方式非常简单:
pip3 install pyppeteer
好了,安装完成之后我们在命令行下测试:
import pyppeteer
如果没有报错,那么就证明安装成功了。
接下来我们测试基本的页面渲染操作,这里我们选用的网址为:https://dynamic2.scrape.cuiqingcai.com/,如图所示。 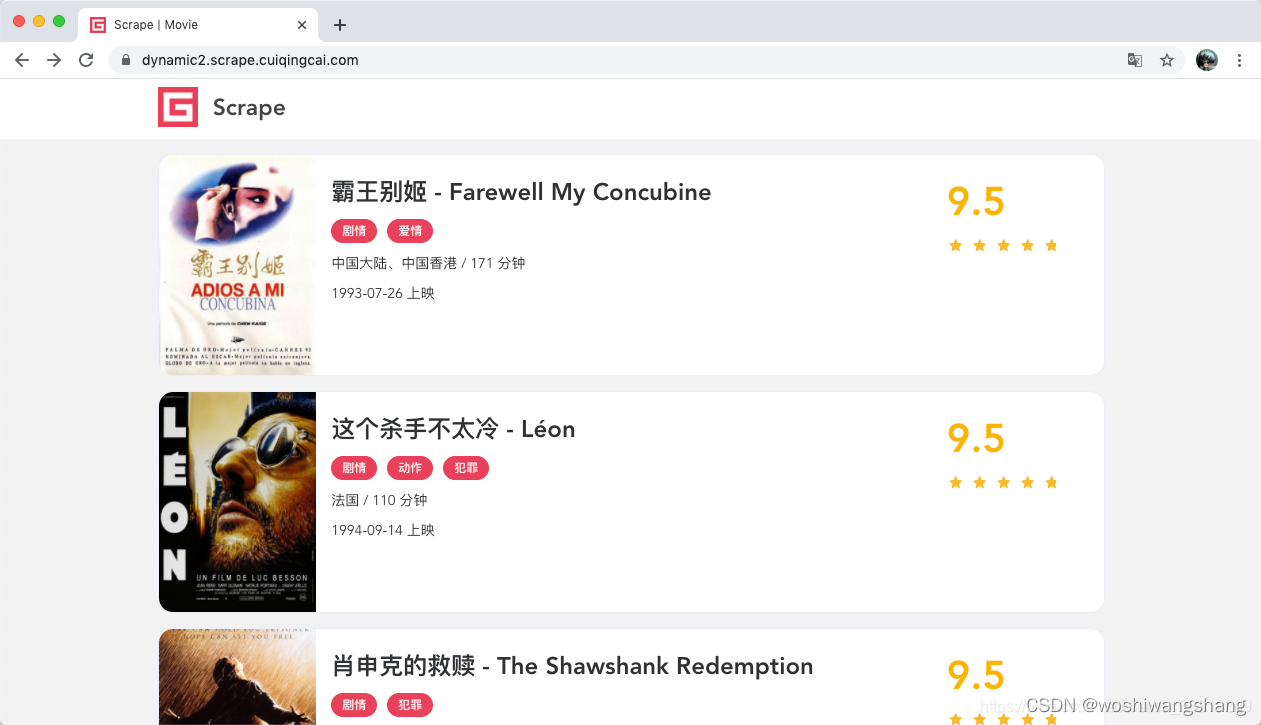 这个网站我们在之前的 Selenium 爬取实战课时中已经分析过了,整个页面是用 JavaScript 渲染出来的,同时一些 Ajax 接口还带有加密参数,所以这个网站的页面我们无法直接使用 requests 来抓取看到的数据,同时我们也不太好直接模拟 Ajax 来获取数据。
这个网站我们在之前的 Selenium 爬取实战课时中已经分析过了,整个页面是用 JavaScript 渲染出来的,同时一些 Ajax 接口还带有加密参数,所以这个网站的页面我们无法直接使用 requests 来抓取看到的数据,同时我们也不太好直接模拟 Ajax 来获取数据。
所以前面一课时我们介绍了使用 Selenium 爬取的方式,其原理就是模拟浏览器的操作,直接用浏览器把页面渲染出来,然后再直接获取渲染后的结果。同样的原理,用 Pyppeteer 也可以做到。
下面我们用 Pyppeteer 来试试,代码就可以写为如下形式:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await page.waitForSelector('.item .name')
doc = pq(await page.content())
names = [item.text() for item in doc('.item .name').items()]
print('Names:', names)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
运行结果:
Names: ['霸王别姬 - Farewell My Concubine', '这个杀手不太冷 - Léon', '肖申克的救赎 - The Shawshank Redemption', '泰坦尼克号 - Titanic', '罗马假日 - Roman Holiday', '唐伯虎点秋香 - Flirting Scholar', '乱世佳人 - Gone with the Wind', '喜剧之王 - The King of Comedy', '楚门的世界 - The Truman Show', '狮子王 - The Lion King']
先初步看下代码,大体意思是访问了这个网站,然后等待 .item .name 的节点加载出来,随后通过 pyquery 从网页源码中提取了电影的名称并输出,最后关闭 Pyppeteer。
看运行结果,和之前的 Selenium 一样,我们成功模拟加载出来了页面,然后提取到了首页所有电影的名称。
那么这里面的具体过程发生了什么?我们来逐行看下。
-
launch 方法会新建一个 Browser 对象,其执行后最终会得到一个 Browser 对象,然后赋值给 browser。这一步就相当于启动了浏览器。
-
然后 browser 调用 newPage 方法相当于浏览器中新建了一个选项卡,同时新建了一个 Page 对象,这时候新启动了一个选项卡,但是还未访问任何页面,浏览器依然是空白。
-
随后 Page 对象调用了 goto 方法就相当于在浏览器中输入了这个 URL,浏览器跳转到了对应的页面进行加载。
-
Page 对象调用 waitForSelector 方法,传入选择器,那么页面就会等待选择器所-对应的节点信息加载出来,如果加载出来了,立即返回,否则会持续等待直到超时。此时如果顺利的话,页面会成功加载出来。
-
页面加载完成之后再调用 content 方法,可以获得当前浏览器页面的源代码,这就是 JavaScript 渲染后的结果。
-
然后进一步的,我们用 pyquery 进行解析并提取页面的电影名称,就得到最终结果了。 另外其他的一些方法如调用 asyncio 的 get_event_loop 等方法的相关操作则属于 Python 异步 async 相关的内容了,你如果不熟悉可以了解下前面所讲的异步相关知识。
好,通过上面的代码,我们同样也可以完成 JavaScript 渲染页面的爬取了。怎么样?代码相比 Selenium 是不是更简洁易读,而且环境配置更加方便。在这个过程中,我们没有配置 Chrome 浏览器,也没有配置浏览器驱动,免去了一些烦琐的步骤,同样达到了 Selenium 的效果,还实现了异步抓取。 接下来我们再看看另外一个例子,这个例子设定了浏览器窗口大小,然后模拟了网页截图,另外还可以执行自定义的 JavaScript 获得特定的内容,代码如下:
import asyncio
from pyppeteer import launch
width, height = 1366, 768
async def main():
browser = await launch()
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await page.waitForSelector('.item .name')
await asyncio.sleep(2)
await page.screenshot(path='example.png')
dimensions = await page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}''')
print(dimensions)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
这里我们又用到了几个新的 API,完成了页面窗口大小设置、网页截图保存、执行 JavaScript 并返回对应数据。
首先 screenshot 方法可以传入保存的图片路径,另外还可以指定保存格式 type、清晰度 quality、是否全屏 fullPage、裁切 clip 等各个参数实现截图。 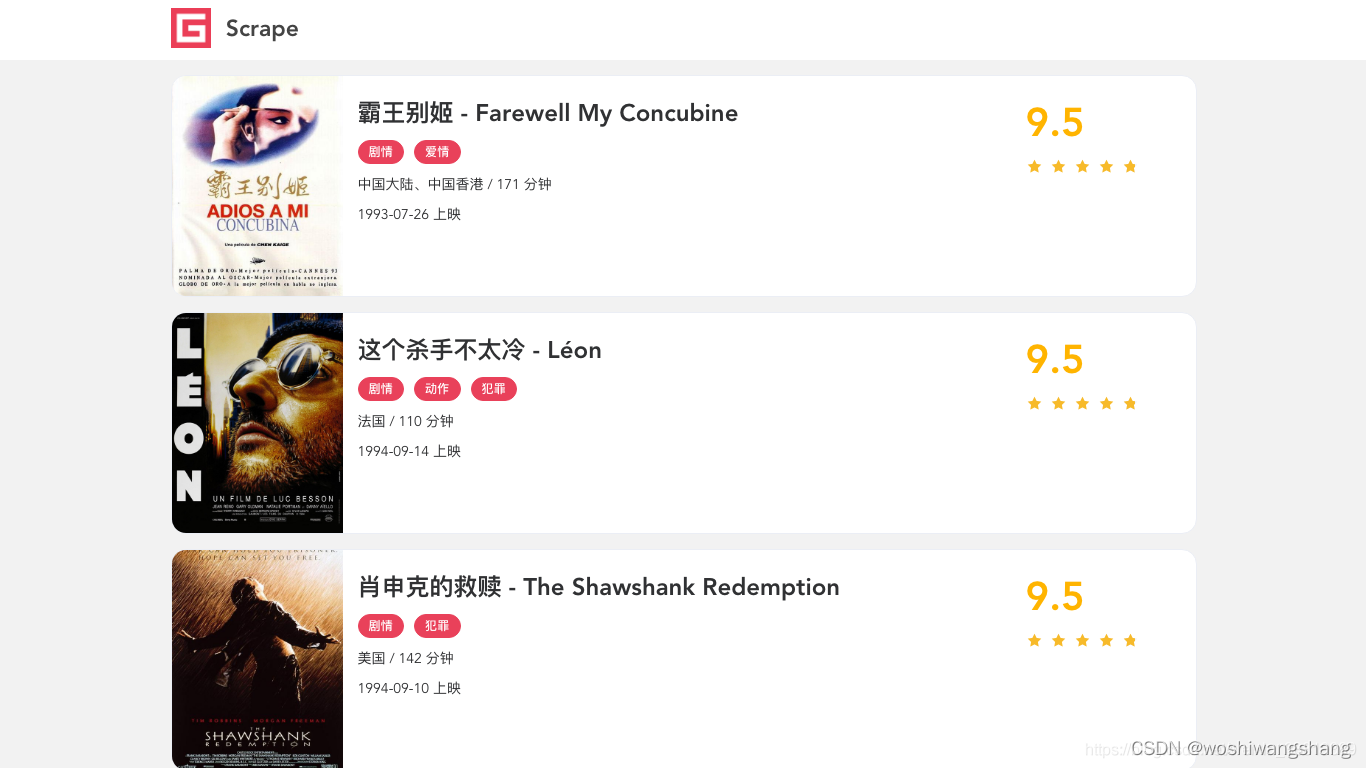 可以看到它返回的就是 JavaScript 渲染后的页面,和我们在浏览器中看到的结果是一模一样的。
可以看到它返回的就是 JavaScript 渲染后的页面,和我们在浏览器中看到的结果是一模一样的。
最后我们又调用了 evaluate 方法执行了一些 JavaScript,JavaScript 传入的是一个函数,使用 return 方法返回了网页的宽高、像素大小比率三个值,最后得到的是一个 JSON 格式的对象,内容如下:
{'width': 1366, 'height': 768, 'deviceScaleFactor': 1}
OK,实例就先感受到这里,还有太多太多的功能还没提及。
总之利用 Pyppeteer 我们可以控制浏览器执行几乎所有动作,想要的操作和功能基本都可以实现,用它来自由地控制爬虫当然就不在话下了。
详细用法
了解了基本的实例之后,我们再来梳理一下 Pyppeteer 的一些基本和常用操作。Pyppeteer 的几乎所有功能都能在其官方文档的 API Reference 里面找到,链接为:API Reference — Pyppeteer 0.0.25 documentation,用到哪个方法就来这里查询就好了,参数不必死记硬背,即用即查就好。
launch
使用 Pyppeteer 的第一步便是启动浏览器,首先我们看下怎样启动一个浏览器,其实就相当于我们点击桌面上的浏览器图标一样,把它运行起来。用 Pyppeteer 完成同样的操作,只需要调用 launch 方法即可。
我们先看下 launch 方法的 API,链接为:API Reference — Pyppeteer 0.0.25 documentation,其方法定义如下:
pyppeteer.launcher.launch(options: dict = None, **kwargs) → pyppeteer.browser.Browser
可以看到它处于 launcher 模块中,参数没有在声明中特别指定,返回类型是 browser 模块中的 Browser 对象,另外观察源码发现这是一个 async 修饰的方法,所以调用它的时候需要使用 await。
接下来看看它的参数:
-
ignoreHTTPSErrors (bool):是否要忽略 HTTPS 的错误,默认是 False。
-
headless (bool):是否启用 Headless 模式,即无界面模式,如果 devtools 这个参数是 True 的话,那么该参数就会被设置为 False,否则为 True,即默认是开启无界面模式的。
-
executablePath (str):可执行文件的路径,如果指定之后就不需要使用默认的 Chromium 了,可以指定为已有的 Chrome 或 Chromium。
-
slowMo (int|float):通过传入指定的时间,可以减缓 Pyppeteer 的一些模拟操作。 args (List[str]):在执行过程中可以传入的额外参数。
-
ignoreDefaultArgs (bool):不使用 Pyppeteer 的默认参数,如果使用了这个参数,那么最好通过 args 参数来设定一些参数,否则可能会出现一些意想不到的问题。这个参数相对比较危险,慎用。
-
handleSIGINT (bool):是否响应 SIGINT 信号,也就是可以使用 Ctrl + C 来终止浏览器程序,默认是 True。
-
handleSIGTERM (bool):是否响应 SIGTERM 信号,一般是 kill 命令,默认是 True。
-
handleSIGHUP (bool):是否响应 SIGHUP 信号,即挂起信号,比如终端退出操作,默认是 True。
-
dumpio (bool):是否将 Pyppeteer 的输出内容传给 process.stdout 和 process.stderr 对象,默认是 False。
-
userDataDir (str):即用户数据文件夹,即可以保留一些个性化配置和操作记录。 env (dict):环境变量,可以通过字典形式传入。
-
devtools (bool):是否为每一个页面自动开启调试工具,默认是 False。如果这个参数设置为 True,那么 headless 参数就会无效,会被强制设置为 False。
-
logLevel (int|str):日志级别,默认和 root logger 对象的级别相同。
-
autoClose (bool):当一些命令执行完之后,是否自动关闭浏览器,默认是 True。
-
loop (asyncio.AbstractEventLoop):事件循环对象。
好了,知道这些参数之后,我们可以先试试看。
无头模式
首先可以试用下最常用的参数 headless,如果我们将它设置为 True 或者默认不设置它,在启动的时候我们是看不到任何界面的,如果把它设置为 False,那么在启动的时候就可以看到界面了,一般我们在调试的时候会把它设置为 False,在生产环境上就可以设置为 True,我们先尝试一下关闭 headless 模式:
import asyncio from pyppeteer import launch async def main(): await launch(headless=False) await asyncio.sleep(100) asyncio.get_event_loop().run_until_complete(main())
运行之后看不到任何控制台输出,但是这时候就会出现一个空白的 Chromium 界面了:  但是可以看到这就是一个光秃秃的浏览器而已,看一下相关信息:
但是可以看到这就是一个光秃秃的浏览器而已,看一下相关信息:
 看到了,这就是 Chromium,上面还写了开发者内部版本,你可以认为是开发版的 Chrome 浏览器就好。
看到了,这就是 Chromium,上面还写了开发者内部版本,你可以认为是开发版的 Chrome 浏览器就好。
调试模式
另外我们还可以开启调试模式,比如在写爬虫的时候会经常需要分析网页结构还有网络请求,所以开启调试工具还是很有必要的,我们可以将 devtools 参数设置为 True,这样每开启一个界面就会弹出一个调试窗口,非常方便,示例如下:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(devtools=True)
page = await browser.newPage()
await page.goto('https://www.baidu.com')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
刚才说过 devtools 这个参数如果设置为了 True,那么 headless 就会被关闭了,界面始终会显现出来。在这里我们新建了一个页面,打开了百度,界面运行效果如下: 
禁用提示条
这时候我们可以看到上面的一条提示:“Chrome 正受到自动测试软件的控制”,这个提示条有点烦,那该怎样关闭呢?这时候就需要用到 args 参数了,禁用操作如下:
browser = await launch(headless=False, args=['--disable-infobars'])
这里就不再写完整代码了,就是在 launch 方法中,args 参数通过 list 形式传入即可,这里使用的是 --disable-infobars 的参数。
防止检测
你可能会说,如果你只是把提示关闭了,有些网站还是会检测到是 WebDriver 吧,比如拿之前的检测 WebDriver 的案例 https://antispider1.scrape.cuiqingcai.com/ 来验证下,我们可以试试:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.goto('https://antispider1.scrape.cuiqingcai.com/')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
果然还是被检测到了,页面如下: 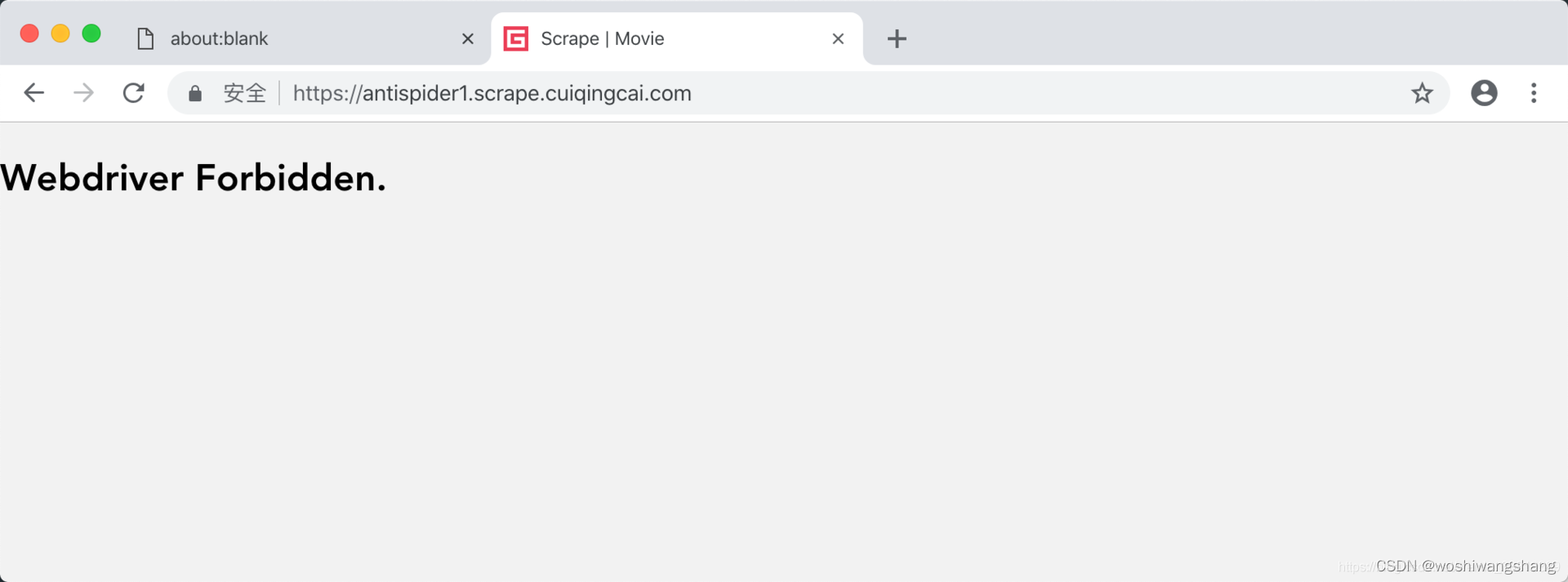 这说明 Pyppeteer 开启 Chromium 照样还是能被检测到 WebDriver 的存在。
这说明 Pyppeteer 开启 Chromium 照样还是能被检测到 WebDriver 的存在。
那么此时如何规避呢?Pyppeteer 的 Page 对象有一个方法叫作 evaluateOnNewDocument,意思就是在每次加载网页的时候执行某个语句,所以这里我们可以执行一下将 WebDriver 隐藏的命令,改写如下:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.evaluateOnNewDocument('Object.defineProperty(navigator, "webdriver", {get: () => undefined})')
await page.goto('https://antispider1.scrape.cuiqingcai.com/')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
这里我们可以看到整个页面就可以成功加载出来了,如图所示。 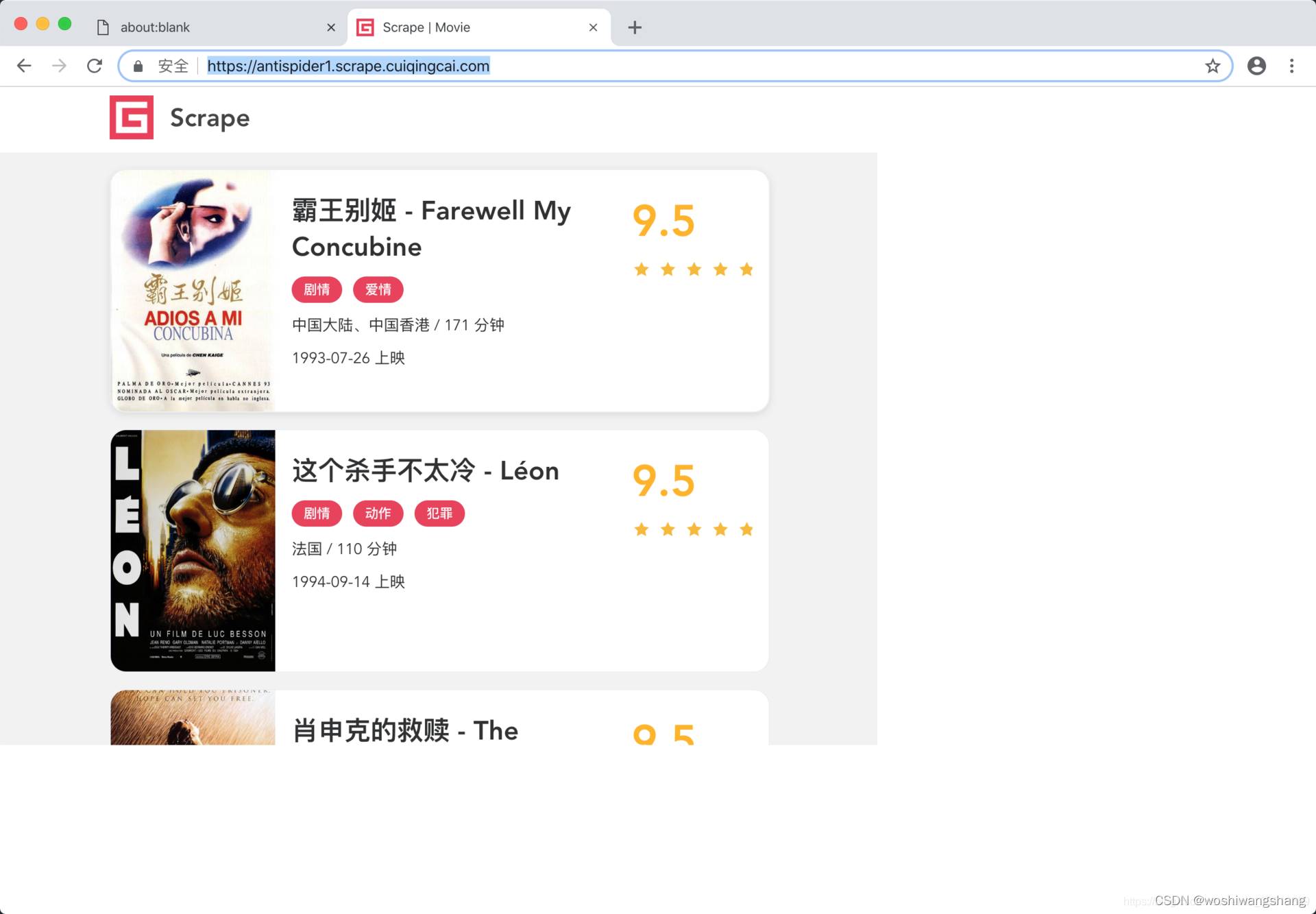 我们发现页面就成功加载出来了,绕过了 WebDriver 的检测。
我们发现页面就成功加载出来了,绕过了 WebDriver 的检测。
页面大小设置
在上面的例子中,我们还发现了页面的显示 bug,整个浏览器窗口比显示的内容窗口要大,这个是某些页面会出现的情况。
对于这种情况,我们通过设置窗口大小就可以解决,可以通过 Page 的 setViewport 方法设置,代码如下:
import asyncio
from pyppeteer import launch
width, height = 1366, 768
async def main():
browser = await launch(headless=False, args=['--disable-infobars', f'--window-size={width},{height}'])
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.evaluateOnNewDocument('Object.defineProperty(navigator, "webdriver", {get: () => undefined})')
await page.goto('https://antispider1.scrape.cuiqingcai.com/')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
这里我们同时设置了浏览器窗口的宽高以及显示区域的宽高,使得二者一致,最后发现显示就正常了,如图所示。 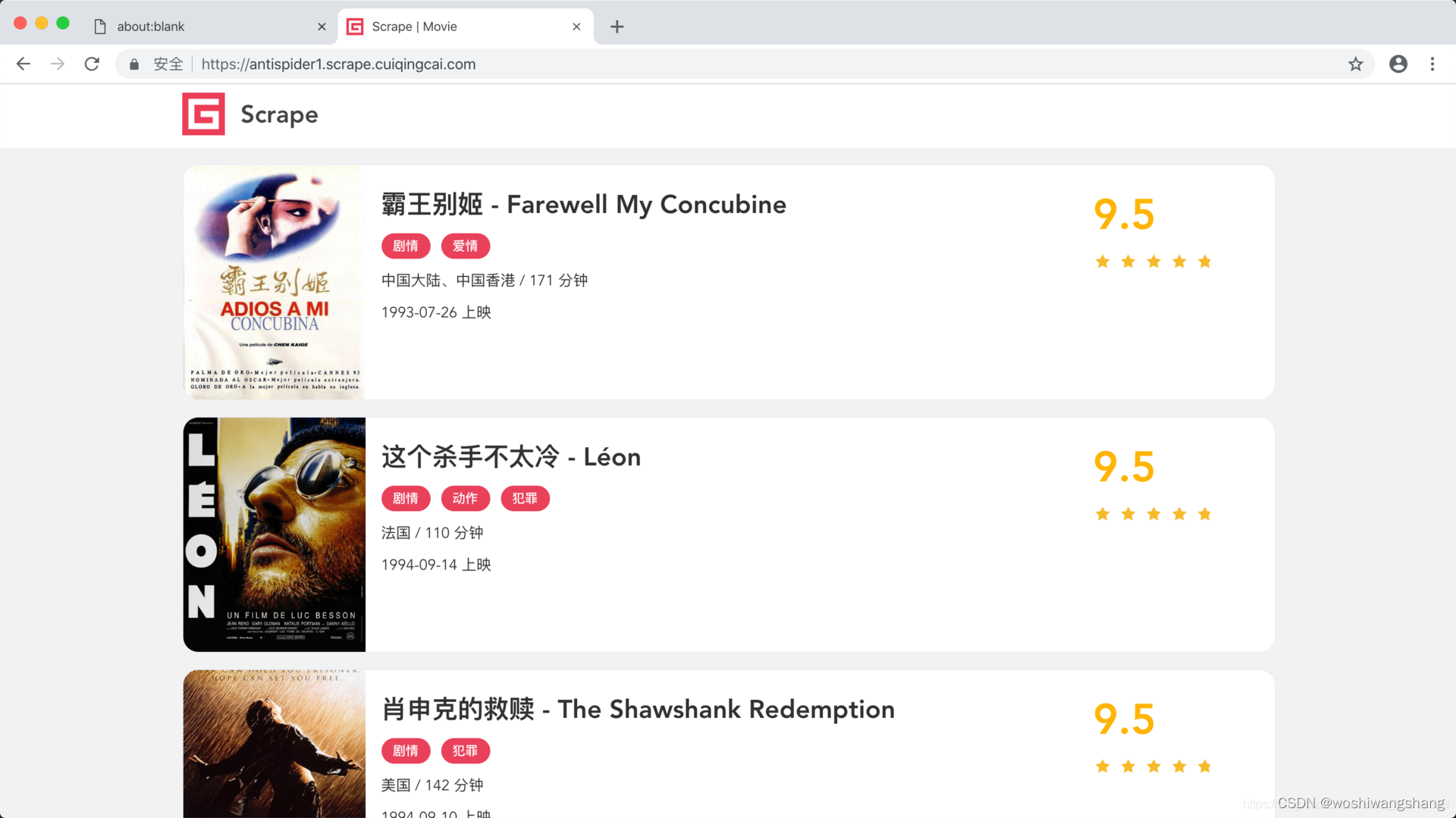
用户数据持久化
刚才我们可以看到,每次我们打开 Pyppeteer 的时候都是一个新的空白的浏览器。而且如果遇到了需要登录的网页之后,如果我们这次登录上了,下一次再启动又是空白了,又得登录一次,这的确是一个问题。
比如以淘宝举例,平时我们逛淘宝的时候,在很多情况下关闭了浏览器再打开,淘宝依然还是登录状态。这是因为淘宝的一些关键 Cookies 已经保存到本地了,下次登录的时候可以直接读取并保持登录状态。
那么这些信息保存在哪里了呢?其实就是保存在用户目录下了,里面不仅包含了浏览器的基本配置信息,还有一些 Cache、Cookies 等各种信息都在里面,如果我们能在浏览器启动的时候读取这些信息,那么启动的时候就可以恢复一些历史记录甚至一些登录状态信息了。
这也就解决了一个问题:很多时候你在每次启动 Selenium 或 Pyppeteer 的时候总是一个全新的浏览器,那这究其原因就是没有设置用户目录,如果设置了它,每次打开就不再是一个全新的浏览器了,它可以恢复之前的历史记录,也可以恢复很多网站的登录信息。
那么这个怎么来做呢?很简单,在启动的时候设置 userDataDir 就好了,示例如下:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, userDataDir='./userdata', args=['--disable-infobars'])
page = await browser.newPage()
await page.goto('https://www.taobao.com')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
好,这里就是加了一个 userDataDir 的属性,值为 userdata,即当前目录的 userdata 文件夹。我们可以首先运行一下,然后登录一次淘宝,这时候我们同时可以观察到在当前运行目录下又多了一个 userdata 的文件夹,里面的结构是这样子的:  具体的介绍可以看官方的一些说明,如: https://chromium.googlesource.com/chromium/src/+/master/docs/user_data_dir.md,这里面介绍了 userdatadir 的相关内容。
具体的介绍可以看官方的一些说明,如: https://chromium.googlesource.com/chromium/src/+/master/docs/user_data_dir.md,这里面介绍了 userdatadir 的相关内容。
再次运行上面的代码,这时候可以发现现在就已经是登录状态了,不需要再次登录了,这样就成功跳过了登录的流程。当然可能时间太久了,Cookies 都过期了,那还是需要登录的。
以上便是 launch 方法及其对应的参数的配置
Browser
上面我们了解了 launch 方法,其返回的就是一个 Browser 对象,即浏览器对象,我们会通常将其赋值给 browser 变量,其实它就是 Browser 类的一个实例。
下面我们来看看 Browser 类的定义:
class pyppeteer.browser.Browser(connection: pyppeteer.connection.Connection, contextIds: List[str], ignoreHTTPSErrors: bool, setDefaultViewport: bool, process: Optional[subprocess.Popen] = None, closeCallback: Callable[[], Awaitable[None]] = None, **kwargs)
这里我们可以看到其构造方法有很多参数,但其实多数情况下我们直接使用 launch 方法或 connect 方法创建即可。
browser 作为一个对象,其自然有很多用于操作浏览器本身的方法,下面我们来选取一些比较有用的介绍下。
开启无痕模式
我们知道 Chrome 浏览器是有一个无痕模式的,它的好处就是环境比较干净,不与其他的浏览器示例共享 Cache、Cookies 等内容,其开启方式可以通过 createIncognitoBrowserContext 方法,示例如下:
import asyncio
from pyppeteer import launch
width, height = 1200, 768
async def main():
browser = await launch(headless=False,
args=['--disable-infobars', f'--window-size={width},{height}'])
context = await browser.createIncognitoBrowserContext()
page = await context.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://www.baidu.com')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
这里关键的调用就是 createIncognitoBrowserContext 方法,其返回一个 context 对象,然后利用 context 对象我们可以新建选项卡。 
关闭
怎样关闭自不用多说了,就是 close 方法,但很多时候我们可能忘记了关闭而造成额外开销,所以要记得在使用完毕之后调用一下 close 方法,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
Page
Page 即页面,就对应一个网页,一个选项卡。在前面我们已经演示了几个 Page 方法的操作了,这里我们再详细看下它的一些常用用法。
选择器
Page 对象内置了一些用于选取节点的选择器方法,如 J 方法传入一个选择器 Selector,则能返回对应匹配的第一个节点,等价于 querySelector。如 JJ 方法则是返回符合 Selector 的列表,类似于 querySelectorAll。
下面我们来看下其用法和运行结果,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await page.waitForSelector('.item .name')
j_result1 = await page.J('.item .name')
j_result2 = await page.querySelector('.item .name')
jj_result1 = await page.JJ('.item .name')
jj_result2 = await page.querySelectorAll('.item .name')
print('J Result1:', j_result1)
print('J Result2:', j_result2)
print('JJ Result1:', jj_result1)
print('JJ Result2:', jj_result2)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
在这里我们分别调用了 J、querySelector、JJ、querySelectorAll 四个方法,观察下其运行效果和返回结果的类型,运行结果:
J Result1: <pyppeteer.element_handle.ElementHandle object at 0x1166f7dd0> J Result2: <pyppeteer.element_handle.ElementHandle object at 0x1166f07d0> JJ Result1: [<pyppeteer.element_handle.ElementHandle object at 0x11677df50>, <pyppeteer.element_handle.ElementHandle object at 0x1167857d0>, <pyppeteer.element_handle.ElementHandle object at 0x116785110>, ... <pyppeteer.element_handle.ElementHandle object at 0x11679db10>, <pyppeteer.element_handle.ElementHandle object at 0x11679dbd0>] JJ Result2: [<pyppeteer.element_handle.ElementHandle object at 0x116794f10>, <pyppeteer.element_handle.ElementHandle object at 0x116794d10>, <pyppeteer.element_handle.ElementHandle object at 0x116794f50>, ... <pyppeteer.element_handle.ElementHandle object at 0x11679f690>, <pyppeteer.element_handle.ElementHandle object at 0x11679f750>]
在这里我们可以看到,J、querySelector 一样,返回了单个匹配到的节点,返回类型为 ElementHandle 对象。JJ、querySelectorAll 则返回了节点列表,是 ElementHandle 的列表。
项卡操作
前面我们已经演示了多次新建选项卡的操作了,也就是 newPage 方法,那新建了之后怎样获取和切换呢,下面我们来看一个例子:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.baidu.com')
page = await browser.newPage()
await page.goto('https://www.bing.com')
pages = await browser.pages()
print('Pages:', pages)
page1 = pages[1]
await page1.bringToFront()
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
在这里我们启动了 Pyppeteer,然后调用了 newPage 方法新建了两个选项卡并访问了两个网站。那么如果我们要切换选项卡的话,只需要调用 pages 方法即可获取所有的页面,然后选一个页面调用其 bringToFront 方法即可切换到该页面对应的选项卡。
常见操作
作为一个页面,我们一定要有对应的方法来控制,如加载、前进、后退、关闭、保存等,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://dynamic1.scrape.cuiqingcai.com/')
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
# 后退
await page.goBack()
# 前进
await page.goForward()
# 刷新
await page.reload()
# 保存 PDF
await page.pdf()
# 截图
await page.screenshot()
# 设置页面 HTML
await page.setContent('<h2>Hello World</h2>')
# 设置 User-Agent
await page.setUserAgent('Python')
# 设置 Headers
await page.setExtraHTTPHeaders(headers={})
# 关闭
await page.close()
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
这里我们介绍了一些常用方法,除了一些常用的操作,这里还介绍了设置 User-Agent、Headers 等功能。
点击
Pyppeteer 同样可以模拟点击,调用其 click 方法即可。比如我们这里以 https://dynamic2.scrape.cuiqingcai.com/ 为例,等待节点加载出来之后,模拟右键点击一下,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await page.waitForSelector('.item .name')
await page.click('.item .name', options={
'button': 'right',
'clickCount': 1, # 1 or 2
'delay': 3000, # 毫秒
})
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
这里 click 方法第一个参数就是选择器,即在哪里操作。第二个参数是几项配置:
-
button:鼠标按钮,分为 left、middle、right。
-
clickCount:点击次数,如双击、单击等。
-
delay:延迟点击。
-
输入文本
对于文本的输入,Pyppeteer 也不在话下,使用 type 方法即可,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.taobao.com')
# 后退
await page.type('#q', 'iPad')
# 关闭
await asyncio.sleep(10)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
这里我们打开淘宝网,使用 type 方法第一个参数传入选择器,第二个参数传入输入的内容,Pyppeteer 便可以帮我们完成输入了。
获取信息
Page 获取源代码用 content 方法即可,Cookies 则可以用 cookies 方法获取,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
print('HTML:', await page.content())
print('Cookies:', await page.cookies())
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
执行
Pyppeteer 可以支持 JavaScript 执行,使用 evaluate 方法即可,看之前的例子:
import asyncio
from pyppeteer import launch
width, height = 1366, 768
async def main():
browser = await launch()
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await page.waitForSelector('.item .name')
await asyncio.sleep(2)
await page.screenshot(path='example.png')
dimensions = await page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}''')
print(dimensions)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
这里我们通过 evaluate 方法执行了 JavaScript,并获取到了对应的结果。另外其还有 exposeFunction、evaluateOnNewDocument、evaluateHandle 方法可以做了解。
延时等待
在本课时最开头的地方我们演示了 waitForSelector 的用法,它可以让页面等待某些符合条件的节点加载出来再返回。
在这里 waitForSelector 就是传入一个 CSS 选择器,如果找到了,立马返回结果,否则等待直到超时。
除了 waitForSelector 方法,还有很多其他的等待方法,介绍如下。
-
waitForFunction:等待某个 JavaScript 方法执行完毕或返回结果。zh
-
waitForNavigation:等待页面跳转,如果没加载出来就会报错。
-
waitForRequest:等待某个特定的请求被发出。
-
waitForResponse:等待某个特定的请求收到了回应。
-
waitFor:通用的等待方法。
-
waitForSelector:等待符合选择器的节点加载出来。
-
waitForXPath:等待符合 XPath 的节点加载出来。
-
通过等待条件,我们就可以控制页面加载的情况了。
消除指纹
pip install pyppeteer-stealth
from pyppeteer_stealth import stealth
振坤行案例
import asyncio
from pyppeteer import launch
from pyppeteer_stealth import stealth
import os
from openpyxl import load_workbook
import random
width, height = 1920, 1080
import re
import openpyxl
import pymysql
db = pymysql.connect(user='root',password='123456',db='test')
cursor = db.cursor()
async def run(url):
d = re.compile('https://www\.zkh\.com/list/c-(\d+)\.html')
num = d.findall(url)[0]
current_page = 1
# dicts = {}
# dicts[num]=[]
browser = await launch(headless=False, args=['--disable-infobars'])
# 开启一个页面对象
page = await browser.newPage()
# 消除指纹
await stealth(page) # <-- Here
# 设置浏览器宽高
await page.setViewport({'width': width, 'height': height})
await page.goto(url)
# await asyncio.sleep(1000)
while True:
# await asyncio.sleep(2)
# 等待id=key的这个元素出现,等9秒,超过不出现报超时错误
await page.waitForXPath('//*[@class="goods-item-wrap-new clearfix common-item-wrap"]', {'timeout': 9000})
await page.evaluate('window.scrollBy(10000, document.body.scrollHeight)')
await asyncio.sleep(1)
await page.evaluate('window.scrollBy(10000, document.body.scrollHeight)')
await asyncio.sleep(1)
await page.evaluate('window.scrollBy(10000, document.body.scrollHeight)')
await asyncio.sleep(1)
li_list = await page.xpath('//div[@class="goods-item-wrap-new clearfix common-item-wrap"]/a[1]')
for content_url in li_list:
the_url = await (await content_url.getProperty("href")).jsonValue()
# dicts[num].append(the_url)
sql = 'insert into task(code,urls,status) values ("{}","{}","{}")'.format(num,the_url,1)
cursor.execute(sql)
db.commit()
# await (await a[0].getProperty("textContent")).jsonValue()
a = await page.xpath('//b[@class="pagination-page-total"]')
if len(a) == 0:
break
all_page = await (await a[0].getProperty("textContent")).jsonValue()
print('当前页数为', current_page)
if current_page == int(all_page):
break
else:
current_page += 1
await page.click('.nextbtn')
async def main():
# 设置启动时是否开启浏览器可视,消除控制条信息
# 访问某个页面
task_url = ['https://www.zkh.com/list/c-10290173.html','https://www.zkh.com/list/c-10290175.html']
await asyncio.gather(*[run(_) for _ in task_url])
asyncio.get_event_loop().run_until_complete(main())
阳光高考案例
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from multiprocessing import Pool
from selenium.webdriver import ChromeOptions # 这个包用来规避被检测的风险
import time
import asyncio
from pyppeteer import launch
from pyppeteer_stealth import stealth
from lxml import etree
width, height = 1366, 768
#
async def main():
# 设置启动时是否开启浏览器可视,消除控制条信息
browser = await launch(headless=False, args=['--disable-infobars'])
# 开启一个页面对象
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
# 消除指纹
await stealth(page) # <-- Here
# 设置浏览器宽高
# await page.setViewport({'width': width, 'height': height})
# await page.evaluateOnNewDocument('Object.defineProperty(navigator, "webdriver", {get: () => undefined})')
# 访问某个页面
await page.goto('https://gaokao.chsi.com.cn/')
await page.waitForXPath('//ul[@class="clearfix margin-b4"]/li[1]/a')
await page.click('ul.nav-index-list li:nth-child(2) ul:nth-child(1) li:nth-child(1) a', options={
'button': 'left',
'clickCount': 1, # 1 or 2
'delay': 3000, # 毫秒
})
# 等待元素出现
await page.waitForSelector('div.sch-list-container')
# 拉滚动条
await page.evaluate('window.scrollBy(200, document.body.scrollHeight)')
# divs = etree.HTML(await page.content()).xpath('//div[@class="sch-item"]')
# for div in divs:
# title = div.xpath('div[1]/div[1]/a/text()')[0].strip()
# print(title)
li_list = await page.xpath('//div[@class="sch-item"]')
for i in li_list:
a = await i.xpath('div[1]/div[1]/a')
b = await i.xpath('div[1]/a[1]')
# 取商品标题
title = await (await a[0].getProperty("textContent")).jsonValue()
bb = await (await b[0].getProperty("textContent")).jsonValue()
print(title,bb)
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
# selenium过检测代码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import requests
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver import ChromeOptions # 这个包用来规避被检测的风险
import time # 延迟
from selenium.webdriver import ActionChains # 动作链
option = webdriver.ChromeOptions()
option.add_argument(
'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36')
option.add_argument('--disable-blink-features=AutomationControlled')
driver_path = r'C:\\Python39\\chromedriver.exe' # 定义好路径
driver = webdriver.Chrome(executable_path=driver_path, options=option) # 初始化路径+规避检测
with open('stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
url1 = 'https://bot.sannysoft.com/'
driver.maximize_window()
time.sleep(3)
driver.get(url1)
安装node.js环境
下载 Node.js — Run JavaScript Everywhere  下载前面那个就行 之后就是安装,一直下一步就行,记得配好环境变量,安装好之后要重新启动,然后用程序检测nodejs是否可用 以下都需要成功 第一:打开命令框输入node可以看到版本号
下载前面那个就行 之后就是安装,一直下一步就行,记得配好环境变量,安装好之后要重新启动,然后用程序检测nodejs是否可用 以下都需要成功 第一:打开命令框输入node可以看到版本号  第二新建一个python文件,然后输入如下代码
第二新建一个python文件,然后输入如下代码
import execjs # pip install PyExecJS print(execjs.get().name)
 看到如上显示证明成功,其他显示一律视为不成功,重启电脑再试一下
看到如上显示证明成功,其他显示一律视为不成功,重启电脑再试一下
nodejs环境中常用包安装介绍
//npm install crypto-js
const CryptoJS = require('crypto-js')
//npm install pako
const pako = require('pako')
//npm install fs
const fs = require('fs')
//npm install jsdom
const jsdom = require("jsdom");
const { JSDOM } = jsdom;
const dom = new JSDOM('<!DOCTYPE html><p>Hello world</p>');
const {document} = (new JSDOM('<!doctype html><html><body></body></html>')).window;
global.document = document;
const window = document.defaultView;
//npm install jquery
const $ = require('jquery')(window);
CryptoJS用于加密解密
例如base64转码,md5加密 sha aes等加密 pako 主要作用是压缩 fs是读取文件例子:
//npm install crypto-js
const CryptoJS = require('crypto-js')
//npm install pako
const pako = require('pako')
//npm install fs
const fs = require('fs')
//npm install jsdom
const jsdom = require("jsdom");
const { JSDOM } = jsdom;
const dom = new JSDOM('<!DOCTYPE html><p>Hello world</p>');
const {document} = (new JSDOM('<!doctype html><html><body></body></html>')).window;
global.document = document;
const window = document.defaultView;
//npm install jquery
const $ = require('jquery')(window);
function test(path) {
//Uint8Array 数组类型表示一个8位无符号整型数组,
//创建时内容被初始化为0。创建完后,可以以对象的
//方式或使用数组下标索引的方式引用数组中的元素
//let s = new Uint8Array(fs.readFileSync(path,'utf8'))
let s = fs.readFileSync(path,'utf8')
console.log(s.length,s)
let st = +new Date()
let compressed = pako.deflate(s)
let ed = +new Date()
console.log(compressed.length, compressed.length / s.length, ed - st)
st = +new Date()
let raw = pako.inflate(compressed)
ed = +new Date()
const decoder = new TextDecoder('utf-8');
const text = decoder.decode(raw);
console.log(text,raw,raw.length, ed - st)
}
test('./测试文件.txt')
jsdom 主要用来模拟window和document两个公共变量
安装如上方法安装会在你命令框所在的目录位置装包,比如  那么这个包就装再82目录下,也只在82目录下能用 安装成功当前位置会出现几个文件
那么这个包就装再82目录下,也只在82目录下能用 安装成功当前位置会出现几个文件 
ps:这里如果提示找不到package.json 这个文件,那就需要自己建一个文件夹名字不能有中文,进到这个文件夹里输入 npm init -y 这样就可以先创造package.json这个文件,其他按上面命令装就行了
接着创建js文件,文件里写各种引包代码:
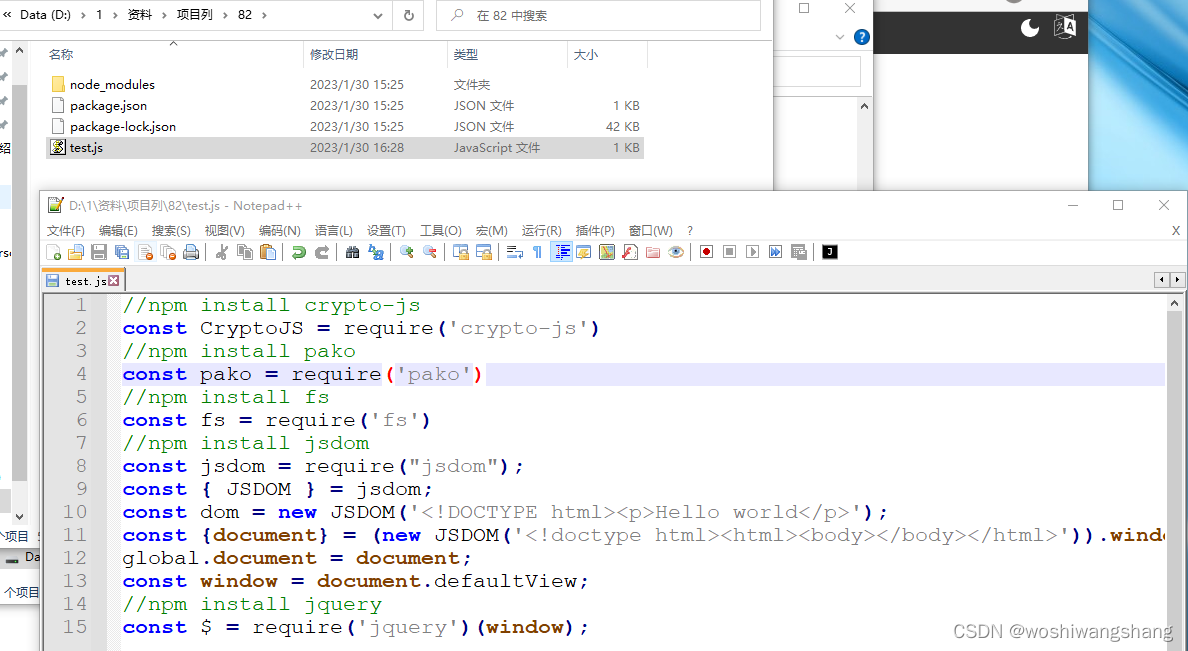 执行如下代码,如果没报错证明包都装的没问题
执行如下代码,如果没报错证明包都装的没问题  到这一步,我们就可以开始探索网易云了。
到这一步,我们就可以开始探索网易云了。
网易云音乐 我们的目标暂定爬这个链接专辑里的歌曲
 先说下,这个网站有缓存机制,如果一首歌被播放过,再次播放不会再请求接口,我们如果要请求相同的歌曲需要先删除缓存才可以。
先说下,这个网站有缓存机制,如果一首歌被播放过,再次播放不会再请求接口,我们如果要请求相同的歌曲需要先删除缓存才可以。  选设置,然后
选设置,然后 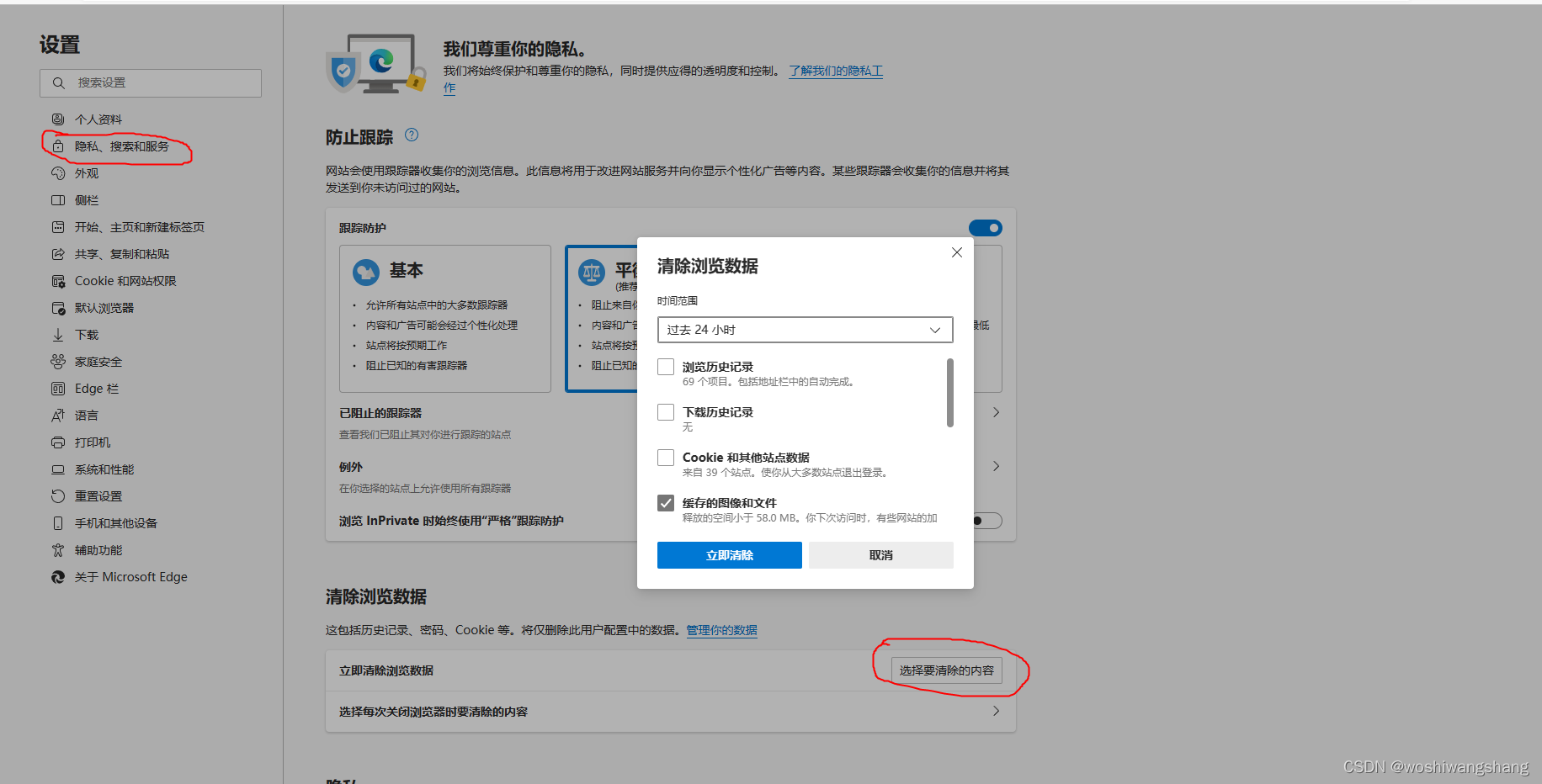 然后点立即清除就行了。
然后点立即清除就行了。
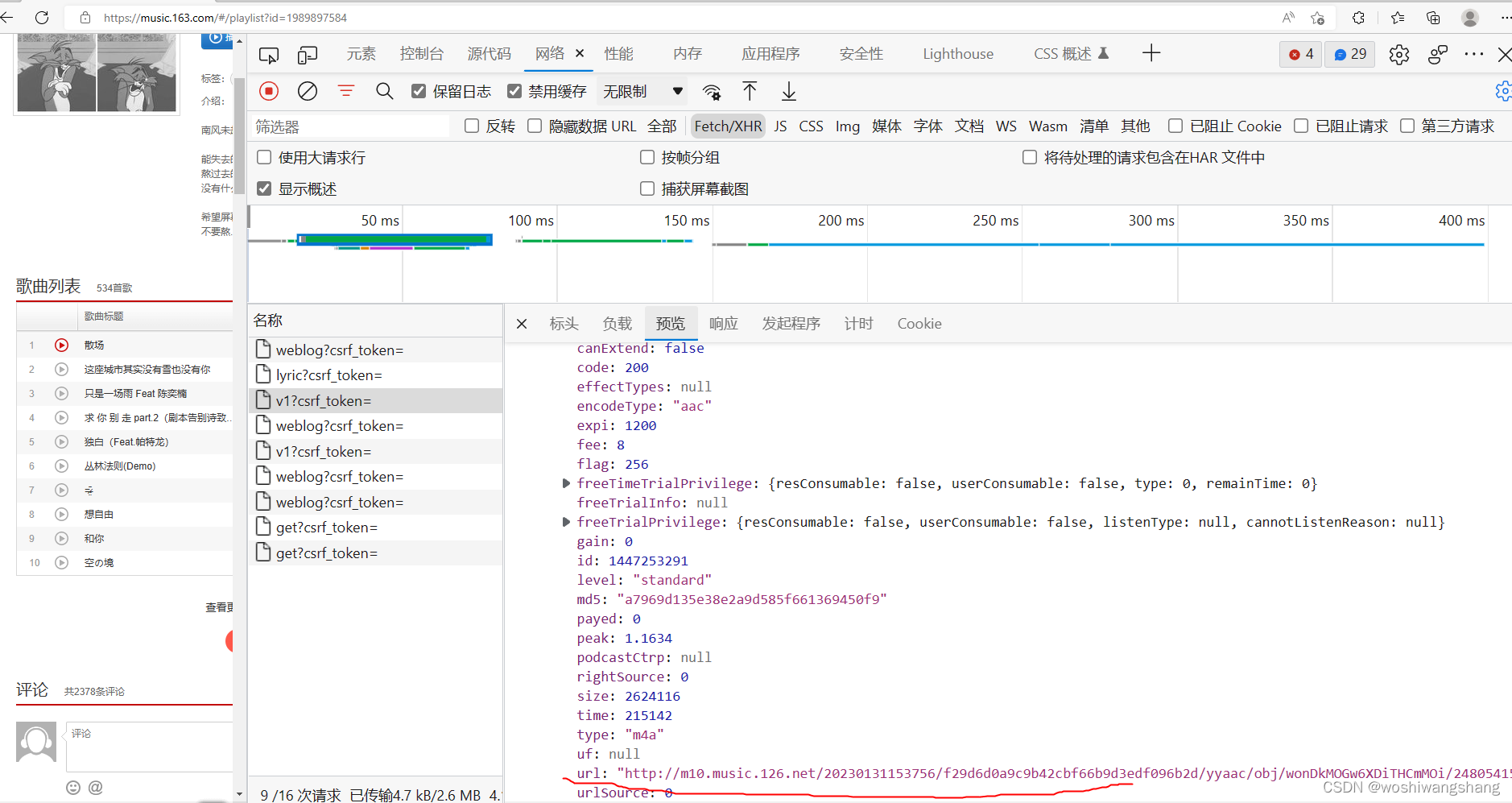 然后我们就找到了我们要的链接,这个链接就是这首歌的资源链接,按照存图片的方法即可请求获取到音频资源,关键是请求这个链接的时候需要提供2个参数
然后我们就找到了我们要的链接,这个链接就是这首歌的资源链接,按照存图片的方法即可请求获取到音频资源,关键是请求这个链接的时候需要提供2个参数
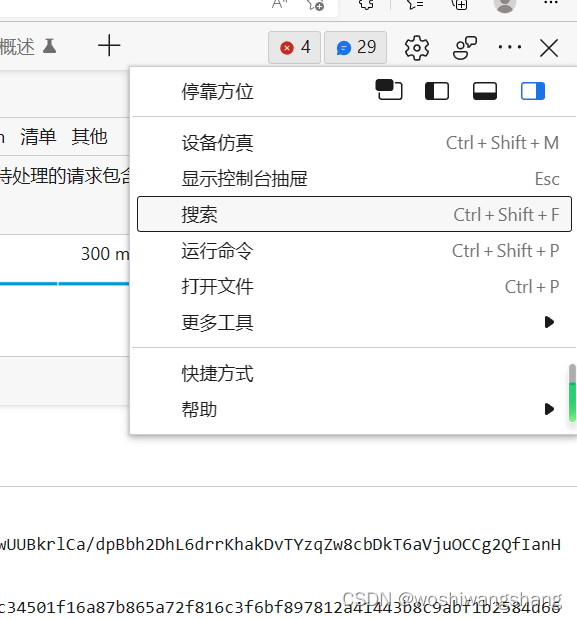 点击右上角三个点然后点搜索,即可打开全局搜索,然后输入参数进行查找,这种方法更加依赖运气,如果代码进行过混淆,这种方法就很难奏效,但是这里没有混淆,我们可以试试:
点击右上角三个点然后点搜索,即可打开全局搜索,然后输入参数进行查找,这种方法更加依赖运气,如果代码进行过混淆,这种方法就很难奏效,但是这里没有混淆,我们可以试试: 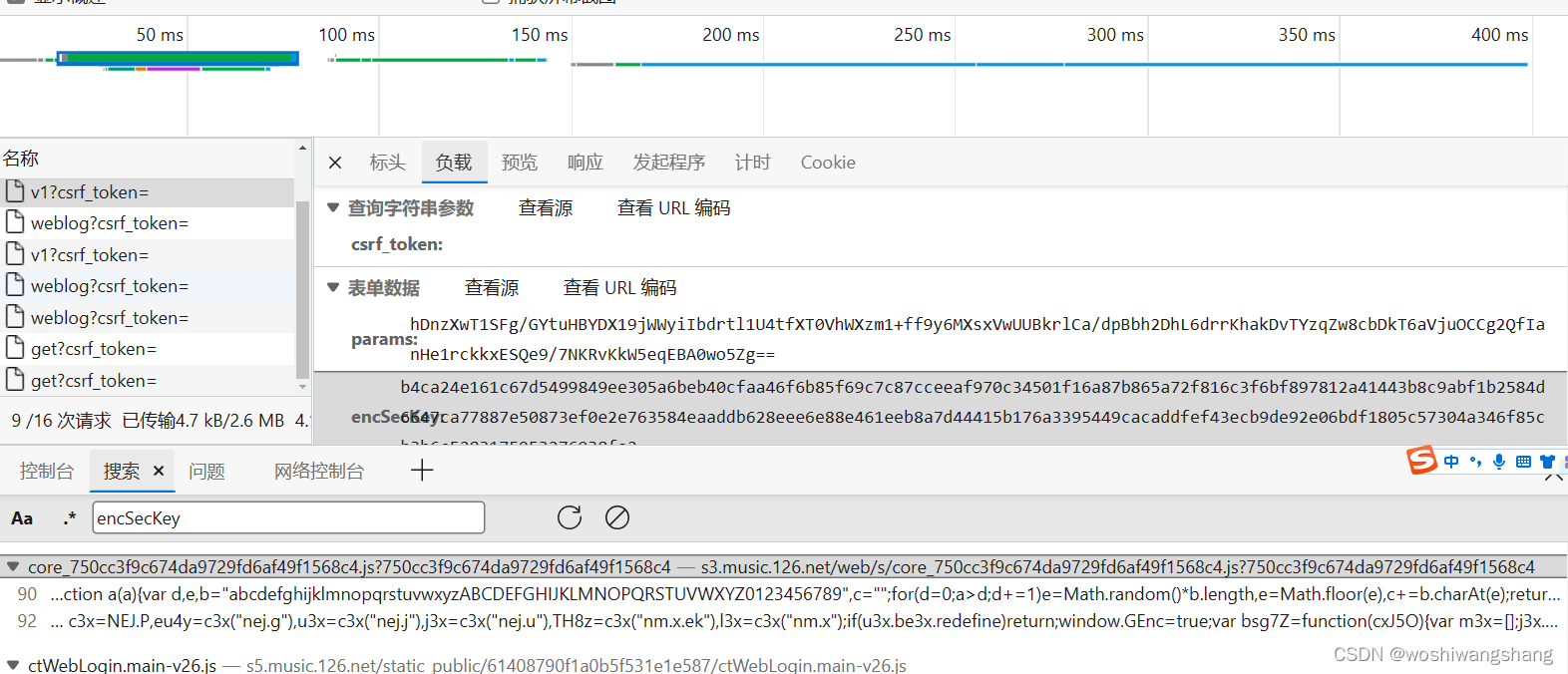 直接点击搜索到的内容,
直接点击搜索到的内容, 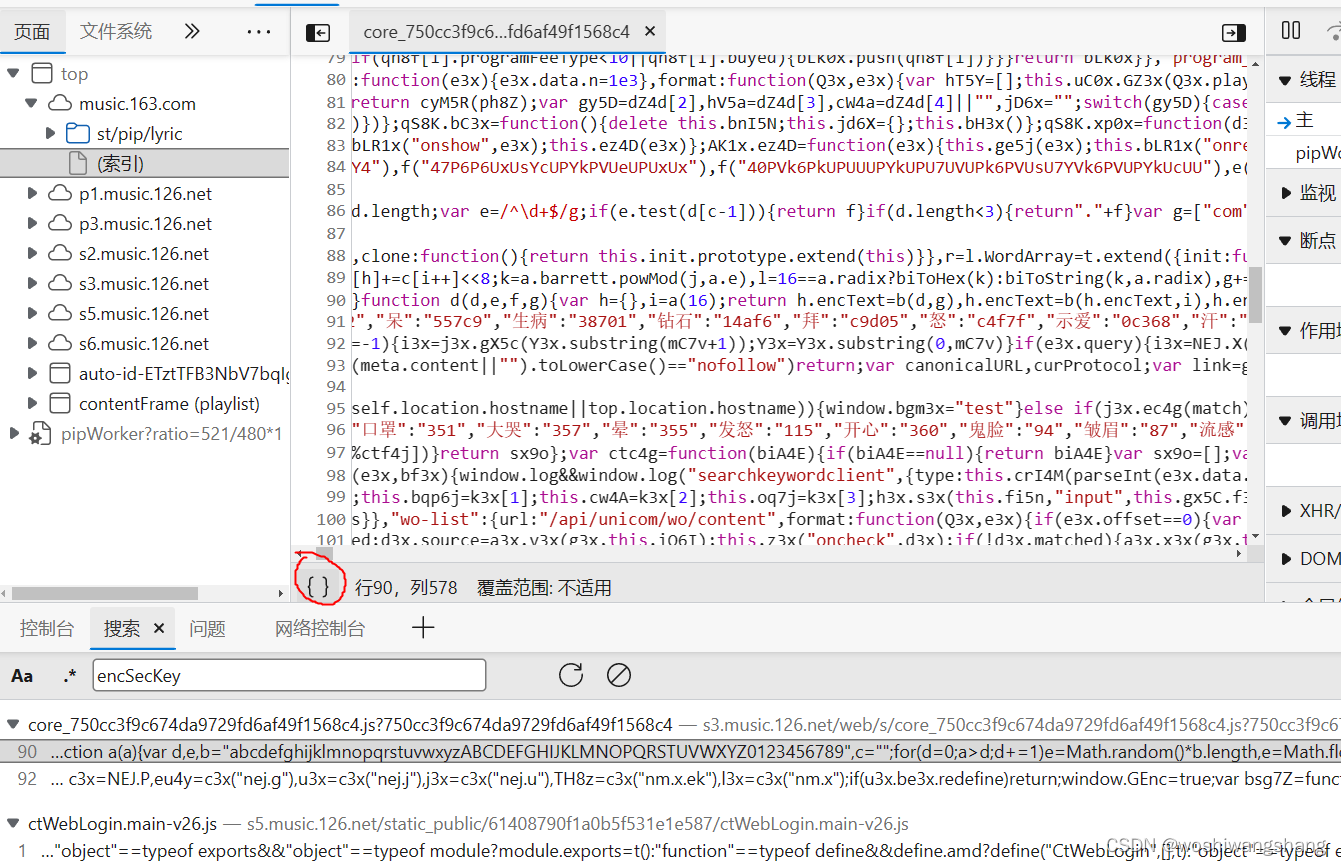 点击红圈位置美化代码
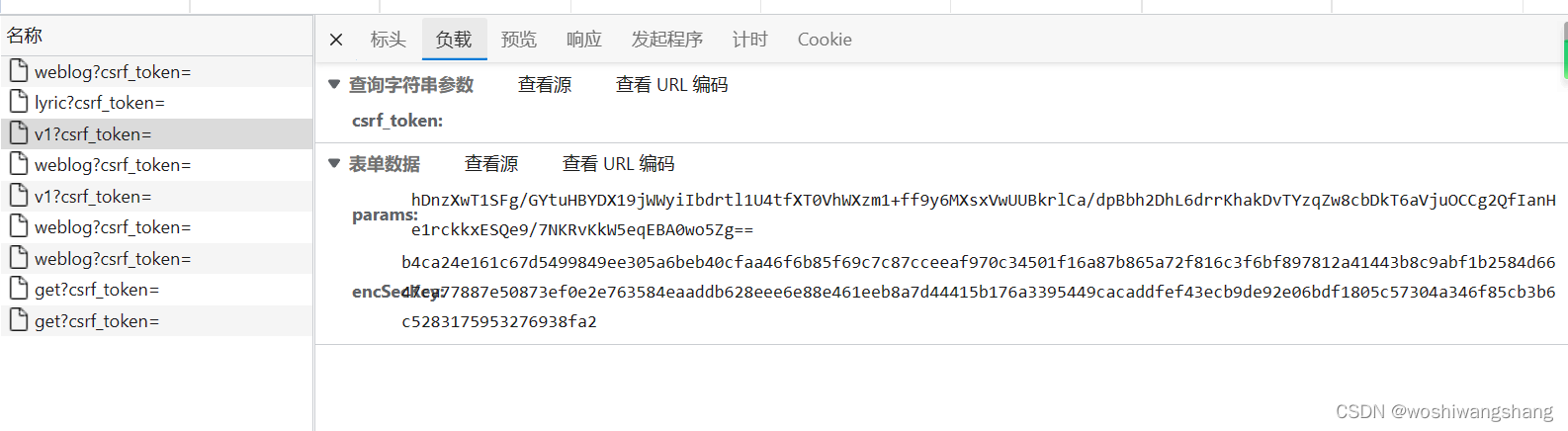
点击红圈位置美化代码 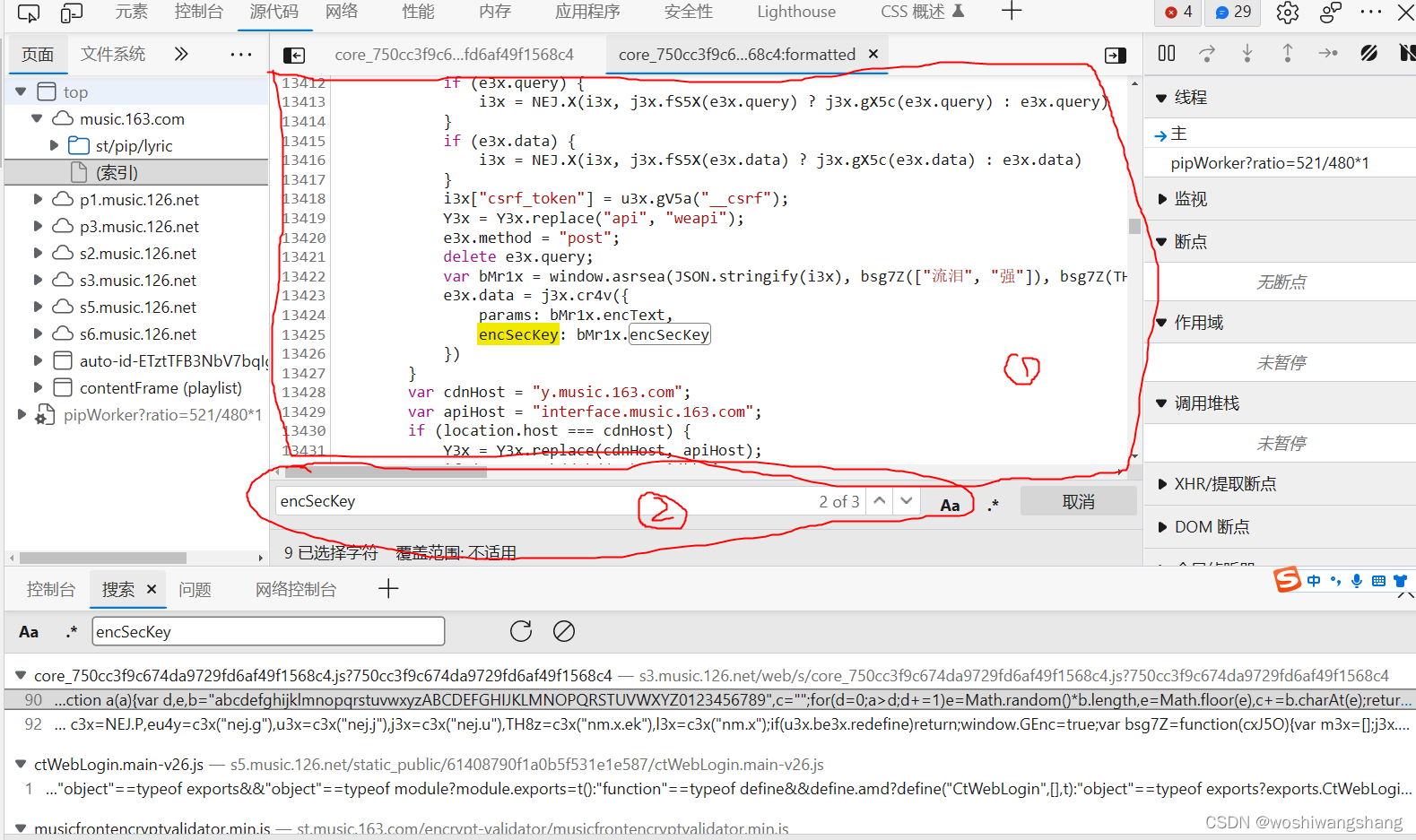 点击一下1 这个位置,然后ctrl+f 打开搜索框,如2,这地方可以直接填入关键单词在这个文件里进行搜索,找到当前位置,可以看到两个参数,一个params 和 encSeckey,这里很像我们发请求的位置,打断点进行实验
点击一下1 这个位置,然后ctrl+f 打开搜索框,如2,这地方可以直接填入关键单词在这个文件里进行搜索,找到当前位置,可以看到两个参数,一个params 和 encSeckey,这里很像我们发请求的位置,打断点进行实验
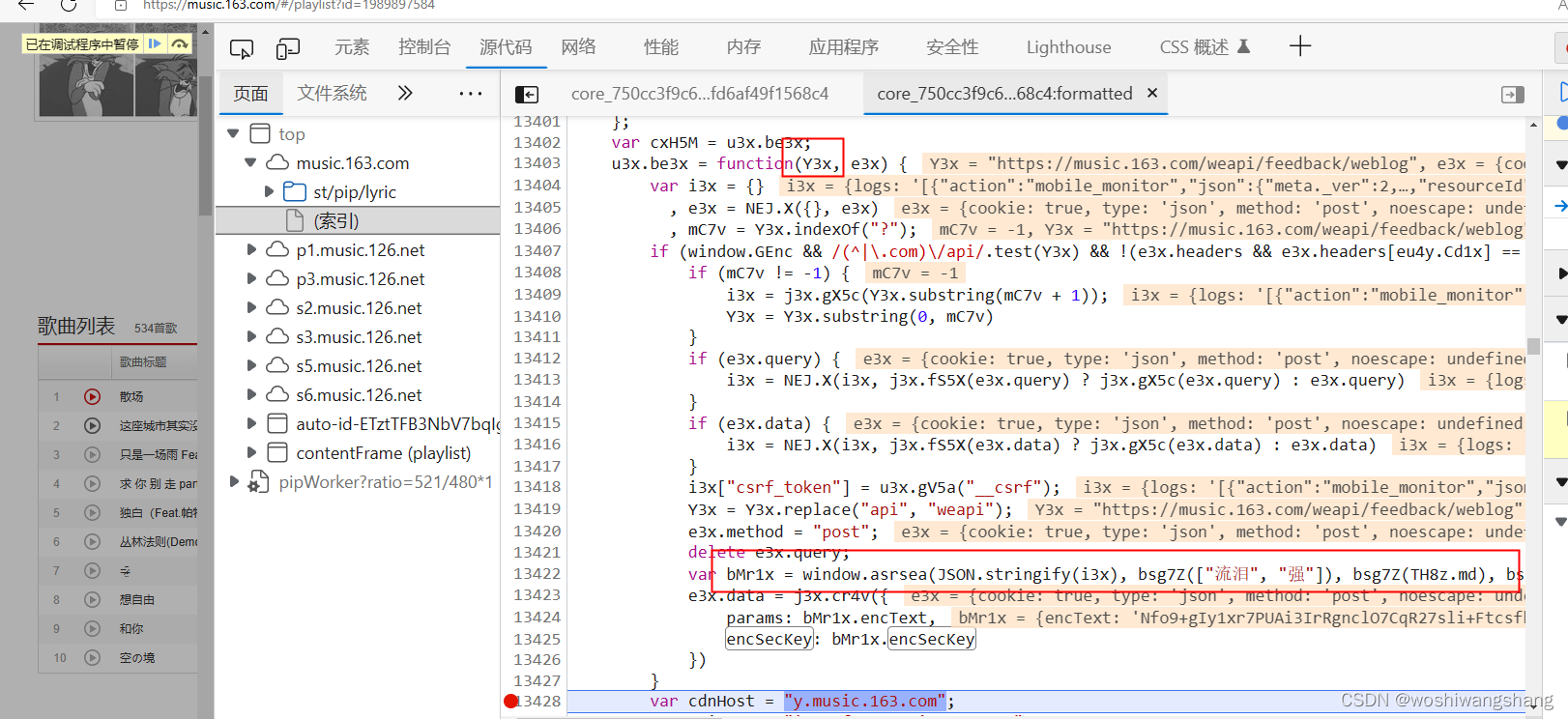 这里我们可以看到Y3x,它是当前请求的链接,但是我们现在看到这个东西明显和之前我们要的请求那不一样,那就放过继续看看, 多点几下就找到了
这里我们可以看到Y3x,它是当前请求的链接,但是我们现在看到这个东西明显和之前我们要的请求那不一样,那就放过继续看看, 多点几下就找到了 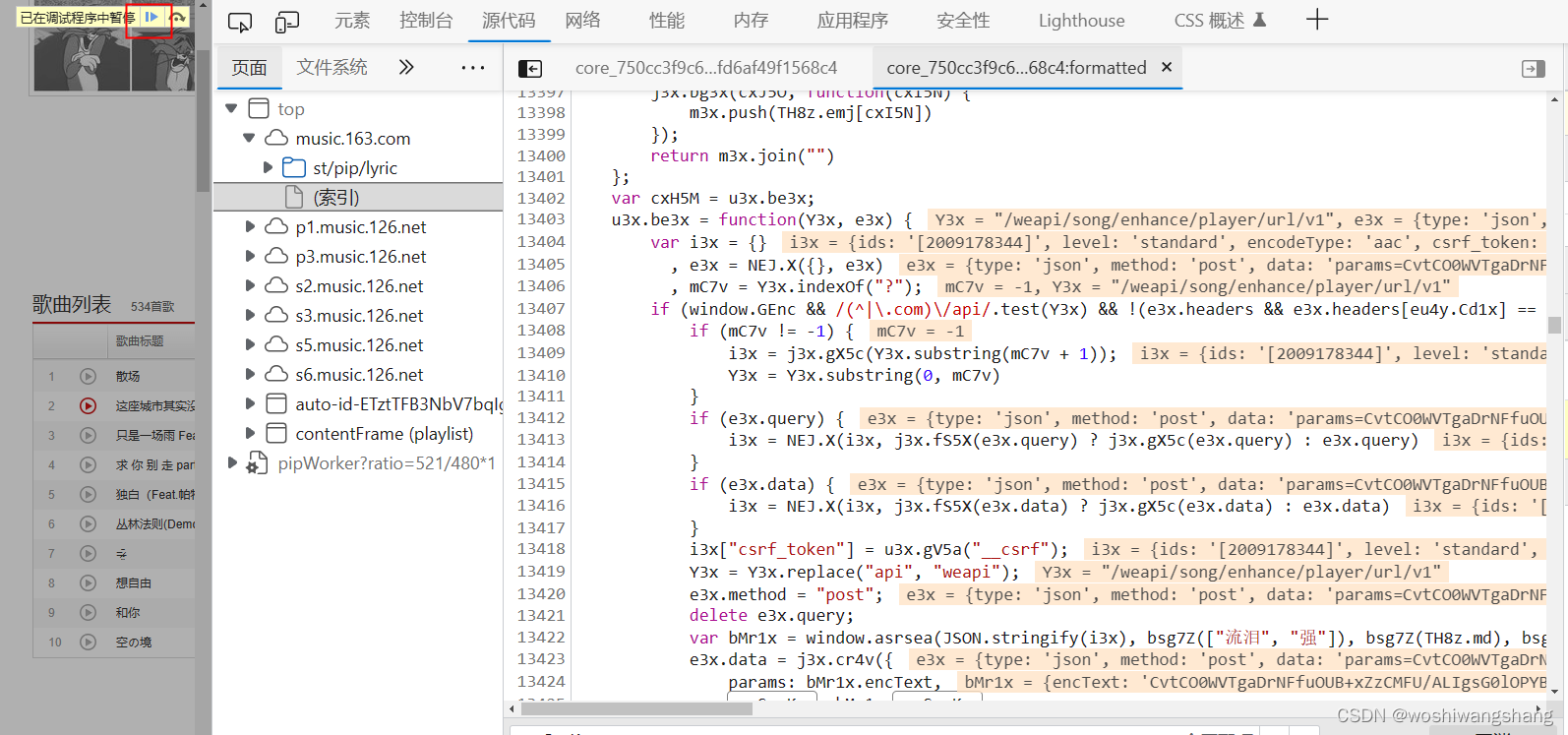 接下来就研究一下这个关键对象
接下来就研究一下这个关键对象  bMr1x这个变量是一个函数的返回值,这个函数有四个参数,我们需要先确定这个四个参数到底是不是会变 第一个参数 JSON.stringify(i3x) 的值: "{"ids":"[2009178344]","level":"standard","encodeType":"aac","csrf_token":""}" 第二个参数bsg7Z(["流泪", "强"])的值: "010001" 第三个参数为: bsg7Z(TH8z.md) 的值为: 00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7 第四个参数为: bsg7Z(["爱心", "女孩", "惊恐", "大笑"]) 值为: "0CoJUm6Qyw8W8jud"
bMr1x这个变量是一个函数的返回值,这个函数有四个参数,我们需要先确定这个四个参数到底是不是会变 第一个参数 JSON.stringify(i3x) 的值: "{"ids":"[2009178344]","level":"standard","encodeType":"aac","csrf_token":""}" 第二个参数bsg7Z(["流泪", "强"])的值: "010001" 第三个参数为: bsg7Z(TH8z.md) 的值为: 00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7 第四个参数为: bsg7Z(["爱心", "女孩", "惊恐", "大笑"]) 值为: "0CoJUm6Qyw8W8jud"
然后你再点开一首歌做同样的操作,可以发现只有第一个参数会变,也就是id对应的值会变,通过观察可以确定,这个会变化的id应该是这个歌曲的ID 参数都已经确定了,那么就得研究一下函数了
通过函数追踪,可以看到,该函数追踪到的位置在这 
也就是说实际上window.asrsea这个函数就是d函数 跟它一起的还有其他的函数,比如a函数,b 函数 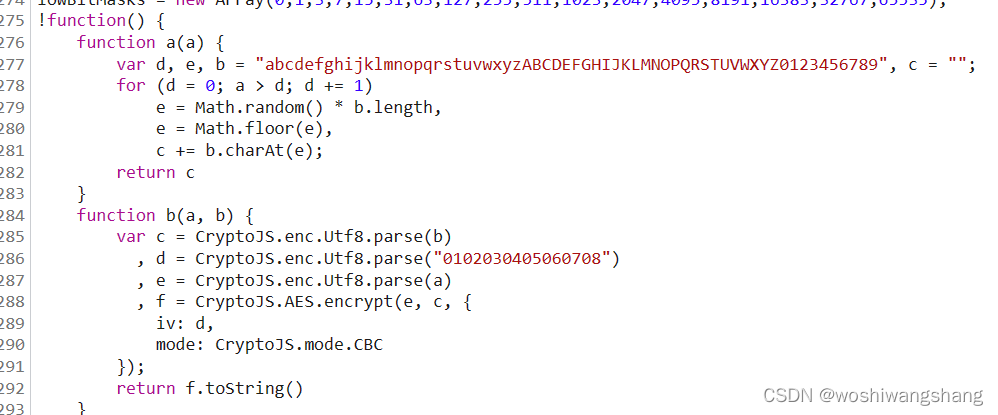 a函数主要作用是生成一个随机字符串,d函数中的a(16)就是这个,b函数则是一个加密方法,
a函数主要作用是生成一个随机字符串,d函数中的a(16)就是这个,b函数则是一个加密方法, 
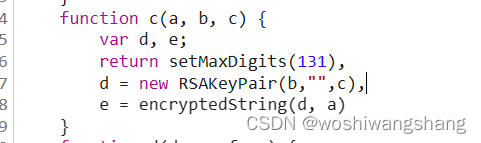
这里有很明显的AES特征,这里加密的模式是CBC加密,c方法也是一个加密函数,这里面是RSA加密方法,这里的RSA据说是魔改过的,我们采用最通用的方法来解决,就是扣代码,把核心加密逻辑扣下来,然后使用python催动js代码得到加密结果 python部分的代码如下:
import zlib
# pip install PyExecJS
import execjs
import requests
import time
import hashlib
import base64
import os
import json
def get_js():
f = open("wyy.js", 'r',encoding='utf8')
line = f.readline()
htmlstr = ''
while line:
htmlstr = htmlstr+line
line = f.readline()
return htmlstr
def get_des_psswd(e):
js_str = get_js()
ctx = execjs.compile(js_str)
#这里hello为js文件里的函数,e为向hello这个函数里传递的参数
#这里我们的e这个形参主要用来传递歌曲的id,这样我们只需要向该函数传递不同的歌曲Id,即可返回不同的下载链接
return (ctx.call('hello',e))
token = get_des_psswd('404459664')
js文件wyy.js的代码如下:
var CryptoJS = require('crypto-js')
var maxDigits, ZERO_ARRAY, bigZero, bigOne, dpl10, lr10, hexatrigesimalToChar, hexToChar, highBitMasks, lowBitMasks, biRadixBase = 2, biRadixBits = 16, bitsPerDigit = biRadixBits, biRadix = 65536, biHalfRadix = biRadix >>> 1, biRadixSquared = biRadix * biRadix, maxDigitVal = biRadix - 1, maxInteger = 9999999999999998;
setMaxDigits(20),
dpl10 = 15,
lr10 = biFromNumber(1e15),
hexatrigesimalToChar = new Array("0","1","2","3","4","5","6","7","8","9","a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z"),
hexToChar = new Array("0","1","2","3","4","5","6","7","8","9","a","b","c","d","e","f"),
highBitMasks = new Array(0,32768,49152,57344,61440,63488,64512,65024,65280,65408,65472,65504,65520,65528,65532,65534,65535),
lowBitMasks = new Array(0,1,3,7,15,31,63,127,255,511,1023,2047,4095,8191,16383,32767,65535);
function reverseStr(a) {
var c, b = "";
for (c = a.length - 1; c > -1; --c)
b += a.charAt(c);
return b
}
function digitToHex(a) {
var b = 15
, c = "";
for (i = 0; 4 > i; ++i)
c += hexToChar[a & b],
a >>>= 4;
return reverseStr(c)
}
function biToHex(a) {
var d, b = "";
for (biHighIndex(a),
d = biHighIndex(a); d > -1; --d)
b += digitToHex(a.digits[d]);
return b
}
function biModuloByRadixPower(a, b) {
var c = new BigInt;
return arrayCopy(a.digits, 0, c.digits, 0, b),
c
}
function biDivideByRadixPower(a, b) {
var c = new BigInt;
return arrayCopy(a.digits, b, c.digits, 0, c.digits.length - b),
c
}
function biMultiply(a, b) {
var d, h, i, k, c = new BigInt, e = biHighIndex(a), f = biHighIndex(b);
for (k = 0; f >= k; ++k) {
for (d = 0,
i = k,
j = 0; e >= j; ++j,
++i)
h = c.digits[i] + a.digits[j] * b.digits[k] + d,
c.digits[i] = h & maxDigitVal,
d = h >>> biRadixBits;
c.digits[k + e + 1] = d
}
return c.isNeg = a.isNeg != b.isNeg,
c
}
function encryptedString(a, b) {
for (var f, g, h, i, j, k, l, c = new Array, d = b.length, e = 0; d > e; )
c[e] = b.charCodeAt(e),
e++;
for (; 0 != c.length % a.chunkSize; )
c[e++] = 0;
for (f = c.length,
g = "",
e = 0; f > e; e += a.chunkSize) {
for (j = new BigInt,
h = 0,
i = e; i < e + a.chunkSize; ++h)
j.digits[h] = c[i++],
j.digits[h] += c[i++] << 8;
k = a.barrett.powMod(j, a.e),
l = 16 == a.radix ? biToHex(k) : biToString(k, a.radix),
g += l + " "
}
return g.substring(0, g.length - 1)
}
function BarrettMu_powMod(a, b) {
var d, e, c = new BigInt;
for (c.digits[0] = 1,
d = a,
e = b; ; ) {
if (0 != (1 & e.digits[0]) && (c = this.multiplyMod(c, d)),
e = biShiftRight(e, 1),
0 == e.digits[0] && 0 == biHighIndex(e))
break;
d = this.multiplyMod(d, d)
}
return c
}
function BarrettMu_multiplyMod(a, b) {
var c = biMultiply(a, b);
return this.modulo(c)
}
function BarrettMu_modulo(a) {
var i, b = biDivideByRadixPower(a, this.k - 1), c = biMultiply(b, this.mu), d = biDivideByRadixPower(c, this.k + 1), e = biModuloByRadixPower(a, this.k + 1), f = biMultiply(d, this.modulus), g = biModuloByRadixPower(f, this.k + 1), h = biSubtract(e, g);
for (h.isNeg && (h = biAdd(h, this.bkplus1)),
i = biCompare(h, this.modulus) >= 0; i; )
h = biSubtract(h, this.modulus),
i = biCompare(h, this.modulus) >= 0;
return h
}
function biShiftRight(a, b) {
var e, f, g, h, c = Math.floor(b / bitsPerDigit), d = new BigInt;
for (arrayCopy(a.digits, c, d.digits, 0, a.digits.length - c),
e = b % bitsPerDigit,
f = bitsPerDigit - e,
g = 0,
h = g + 1; g < d.digits.length - 1; ++g,
++h)
d.digits[g] = d.digits[g] >>> e | (d.digits[h] & lowBitMasks[e]) << f;
return d.digits[d.digits.length - 1] >>>= e,
d.isNeg = a.isNeg,
d
}
function biMultiplyDigit(a, b) {
var c, d, e, f;
for (result = new BigInt,
c = biHighIndex(a),
d = 0,
f = 0; c >= f; ++f)
e = result.digits[f] + a.digits[f] * b + d,
result.digits[f] = e & maxDigitVal,
d = e >>> biRadixBits;
return result.digits[1 + c] = d,
result
}
function biSubtract(a, b) {
var c, d, e, f;
if (a.isNeg != b.isNeg)
b.isNeg = !b.isNeg,
c = biAdd(a, b),
b.isNeg = !b.isNeg;
else {
for (c = new BigInt,
e = 0,
f = 0; f < a.digits.length; ++f)
d = a.digits[f] - b.digits[f] + e,
c.digits[f] = 65535 & d,
c.digits[f] < 0 && (c.digits[f] += biRadix),
e = 0 - Number(0 > d);
if (-1 == e) {
for (e = 0,
f = 0; f < a.digits.length; ++f)
d = 0 - c.digits[f] + e,
c.digits[f] = 65535 & d,
c.digits[f] < 0 && (c.digits[f] += biRadix),
e = 0 - Number(0 > d);
c.isNeg = !a.isNeg
} else
c.isNeg = a.isNeg
}
return c
}
function biCompare(a, b) {
if (a.isNeg != b.isNeg)
return 1 - 2 * Number(a.isNeg);
for (var c = a.digits.length - 1; c >= 0; --c)
if (a.digits[c] != b.digits[c])
return a.isNeg ? 1 - 2 * Number(a.digits[c] > b.digits[c]) : 1 - 2 * Number(a.digits[c] < b.digits[c]);
return 0
}
function biMultiplyByRadixPower(a, b) {
var c = new BigInt;
return arrayCopy(a.digits, 0, c.digits, b, c.digits.length - b),
c
}
function arrayCopy(a, b, c, d, e) {
var g, h, f = Math.min(b + e, a.length);
for (g = b,
h = d; f > g; ++g,
++h)
c[h] = a[g]
}
function biShiftLeft(a, b) {
var e, f, g, h, c = Math.floor(b / bitsPerDigit), d = new BigInt;
for (arrayCopy(a.digits, 0, d.digits, c, d.digits.length - c),
e = b % bitsPerDigit,
f = bitsPerDigit - e,
g = d.digits.length - 1,
h = g - 1; g > 0; --g,
--h)
d.digits[g] = d.digits[g] << e & maxDigitVal | (d.digits[h] & highBitMasks[e]) >>> f;
return d.digits[0] = d.digits[g] << e & maxDigitVal,
d.isNeg = a.isNeg,
d
}
function biFromNumber(a) {
var c, b = new BigInt;
for (b.isNeg = 0 > a,
a = Math.abs(a),
c = 0; a > 0; )
b.digits[c++] = a & maxDigitVal,
a >>= biRadixBits;
return b
}
function biNumBits(a) {
var e, b = biHighIndex(a), c = a.digits[b], d = (b + 1) * bitsPerDigit;
for (e = d; e > d - bitsPerDigit && 0 == (32768 & c); --e)
c <<= 1;
return e
}
function biDivideModulo(a, b) {
var f, g, h, i, j, k, l, m, n, o, p, q, r, s, c = biNumBits(a), d = biNumBits(b), e = b.isNeg;
if (d > c)
return a.isNeg ? (f = biCopy(bigOne),
f.isNeg = !b.isNeg,
a.isNeg = !1,
b.isNeg = !1,
g = biSubtract(b, a),
a.isNeg = !0,
b.isNeg = e) : (f = new BigInt,
g = biCopy(a)),
new Array(f,g);
for (f = new BigInt,
g = a,
h = Math.ceil(d / bitsPerDigit) - 1,
i = 0; b.digits[h] < biHalfRadix; )
b = biShiftLeft(b, 1),
++i,
++d,
h = Math.ceil(d / bitsPerDigit) - 1;
for (g = biShiftLeft(g, i),
c += i,
j = Math.ceil(c / bitsPerDigit) - 1,
k = biMultiplyByRadixPower(b, j - h); -1 != biCompare(g, k); )
++f.digits[j - h],
g = biSubtract(g, k);
for (l = j; l > h; --l) {
for (m = l >= g.digits.length ? 0 : g.digits[l],
n = l - 1 >= g.digits.length ? 0 : g.digits[l - 1],
o = l - 2 >= g.digits.length ? 0 : g.digits[l - 2],
p = h >= b.digits.length ? 0 : b.digits[h],
q = h - 1 >= b.digits.length ? 0 : b.digits[h - 1],
f.digits[l - h - 1] = m == p ? maxDigitVal : Math.floor((m * biRadix + n) / p),
r = f.digits[l - h - 1] * (p * biRadix + q),
s = m * biRadixSquared + (n * biRadix + o); r > s; )
--f.digits[l - h - 1],
r = f.digits[l - h - 1] * (p * biRadix | q),
s = m * biRadix * biRadix + (n * biRadix + o);
k = biMultiplyByRadixPower(b, l - h - 1),
g = biSubtract(g, biMultiplyDigit(k, f.digits[l - h - 1])),
g.isNeg && (g = biAdd(g, k),
--f.digits[l - h - 1])
}
return g = biShiftRight(g, i),
f.isNeg = a.isNeg != e,
a.isNeg && (f = e ? biAdd(f, bigOne) : biSubtract(f, bigOne),
b = biShiftRight(b, i),
g = biSubtract(b, g)),
0 == g.digits[0] && 0 == biHighIndex(g) && (g.isNeg = !1),
new Array(f,g)
}
function biDivide(a, b) {
return biDivideModulo(a, b)[0]
}
function biModulo(a, b) {
return biDivideModulo(a, b)[1]
}
function biMultiplyMod(a, b, c) {
return biModulo(biMultiply(a, b), c)
}
function biPow(a, b) {
for (var c = bigOne, d = a; ; ) {
if (0 != (1 & b) && (c = biMultiply(c, d)),
b >>= 1,
0 == b)
break;
d = biMultiply(d, d)
}
return c
}
function biPowMod(a, b, c) {
for (var d = bigOne, e = a, f = b; ; ) {
if (0 != (1 & f.digits[0]) && (d = biMultiplyMod(d, e, c)),
f = biShiftRight(f, 1),
0 == f.digits[0] && 0 == biHighIndex(f))
break;
e = biMultiplyMod(e, e, c)
}
return d
}
function biCopy(a) {
var b = new BigInt(!0);
return b.digits = a.digits.slice(0),
b.isNeg = a.isNeg,
b
}
function BarrettMu(a) {
this.modulus = biCopy(a),
this.k = biHighIndex(this.modulus) + 1;
var b = new BigInt;
b.digits[2 * this.k] = 1,
this.mu = biDivide(b, this.modulus),
this.bkplus1 = new BigInt,
this.bkplus1.digits[this.k + 1] = 1,
this.modulo = BarrettMu_modulo,
this.multiplyMod = BarrettMu_multiplyMod,
this.powMod = BarrettMu_powMod
}
function biHighIndex(a) {
for (var b = a.digits.length - 1; b > 0 && 0 == a.digits[b]; )
--b;
return b
}
function charToHex(a) {
var h, b = 48, c = b + 9, d = 97, e = d + 25, f = 65, g = 90;
return h = a >= b && c >= a ? a - b : a >= f && g >= a ? 10 + a - f : a >= d && e >= a ? 10 + a - d : 0
}
function hexToDigit(a) {
var d, b = 0, c = Math.min(a.length, 4);
for (d = 0; c > d; ++d)
b <<= 4,
b |= charToHex(a.charCodeAt(d));
return b
}
function biFromHex(a) {
var d, e, b = new BigInt, c = a.length;
for (d = c,
e = 0; d > 0; d -= 4,
++e)
b.digits[e] = hexToDigit(a.substr(Math.max(d - 4, 0), Math.min(d, 4)));
return b
}
function BigInt(a) {
this.digits = "boolean" == typeof a && 1 == a ? null : ZERO_ARRAY.slice(0),
this.isNeg = !1
}
function RSAKeyPair(a, b, c) {
this.e = biFromHex(a),
this.d = biFromHex(b),
this.m = biFromHex(c),
this.chunkSize = 2 * biHighIndex(this.m),
this.radix = 16,
this.barrett = new BarrettMu(this.m)
}
function setMaxDigits(a) {
maxDigits = a,
ZERO_ARRAY = new Array(maxDigits);
for (var b = 0; b < ZERO_ARRAY.length; b++)
ZERO_ARRAY[b] = 0;
bigZero = new BigInt,
bigOne = new BigInt,
bigOne.digits[0] = 1
}
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
function hello(song_id){
var p1 = '{"ids":"['+song_id+']","level":"standard","encodeType":"aac","csrf_token":""}'
var p2 = "010001"
var p3 = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
var p4 = "0CoJUm6Qyw8W8jud"
var bKB4F = d(p1,p2,p3,p4)
return [bKB4F.encText,bKB4F.encSecKey]
}
console.info(hello())
我们先写好hello这个函数,这个函数用到d方法,我们就把d方法也沾过来,d方法里面又调用了a方法,就把a方法也沾过来,依次类推,缺什么就沾什么,直到这个程序不报错为止,补全后代码如上
这个时候运行python文件去调用js则可以得到2个参数的值
再之后就是使用这两个参数,发起请求,得到最终的资源链接  python部分完整代码如下
python部分完整代码如下
```python
import requests
import zlib
# pip install PyExecJS
import execjs
import requests
import time
import hashlib
import base64
import os
import json
print(execjs.get().name)
header = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"content-length": "438",
"content-type": "application/x-www-form-urlencoded",
"cookie": "_ntes_nnid=e53e2bb3edf3a15f9aeb5119f9037b24,1622028956643; _ntes_nuid=e53e2bb3edf3a15f9aeb5119f9037b24; NMTID=00O-PRytPFgJgo7DEDBt3a60f_BqJwAAAF5qHTQWA; WEVNSM=1.0.0; WNMCID=ypoezq.1636510586524.01.0; __root_domain_v=.163.com; _qddaz=QD.804240328821791; wyy_uid=6cb211a8-34fb-434d-a723-c21145cd54c9; locale=zh_CN; _ga=GA1.2.1484811175.1640328827; timing_user_id=time_blsw3JLE53; _iuqxldmzr_=32; WM_TID=ezjNSGAXpPBEFRRBBEZqqqmQ71ya6m5e; WM_NI=wFlWe5gbcS4Vj%2Bm0R4OXW537Wy%2Fnn%2FneFKdiaXzGGnbwyAMiLBlQOVO0XJhI2bGF0T9fF5nJ6zXbsPqmQnN2HOyH4xs%2Fk39FlKcWh7aZOrzSILi%2FqFRQrPDmtWw8tIJteUw%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6ee97d872ab98a0a4c1479cbc8ab2c14b929b9e86d85e829a8597e27eac948cb8aa2af0fea7c3b92ab59aa4b8e83fa5beadb4b75eaaf5a3d1d1408d8899d6b23d95a7e18fed25aebb8aace763a388b6a8c666a2a9b7a2d063909ea4b2ce5e8df098abeb43f2be89a7b360fbba8ad6ed42f6a69883f25cb3b39f8fcd3a8c91b7a9b774b1f1a5d4bc4eb095adb8eb3da3868193f9598b94a7d0f44e928fbeb1c767b889b9d9f7438aacabb6f637e2a3; playerid=19061068; JSESSIONID-WYYY=SCixoBwmYrjsIEwIPFdMrV5axo%5COxPO6uIpfoVSY9yAZGSMEuoC2Tk7Eh8zoWYGl5a2w3vFm74a0N8nFz%2Fe6%2FFoPnk%5C9WnBEHit6UAGAdgQ0GFqBN1Pn0G%2FZDjtQ8ObfChMceoqzVaCR5zGA2bDj6fZ1i6V%2BovMJ7IfpXDJB0X0rBXJc%3A1649383646481",
"origin": "https://music.163.com",
"pragma": "no-cache",
"referer": "https://music.163.com/",
"sec-ch-ua": "\" Not A;Brand\";v=\"99\", \"Chromium\";v=\"99\", \"Google Chrome\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36"
}
def get_js():
# f = open("./../js/my.js", 'r', encoding='utf-8')
f = open("wyy.js", 'r',encoding='utf8')
line = f.readline()
htmlstr = ''
while line:
htmlstr = htmlstr+line
line = f.readline()
return htmlstr
def get_des_psswd(e):
js_str = get_js()
ctx = execjs.compile(js_str)
return (ctx.call('hello',e))
token = get_des_psswd('404459664')
data = {'params':token[0],'encSecKey':token[1]}
source = requests.post('https://music.163.com/weapi/song/enhance/player/url/v1?csrf_token=',headers=header,data=data).text
print(source)
ps: 个别同学请求回来是乱码
删除header头中
"accept-encoding": "gzip, deflate, br", 即可
js 的条件语句
if else结构
if结构先判断一个表达式的布尔值,然后根据布尔值的真伪,执行不同的语句。所谓布尔值,指的是 JavaScript 的两个特殊值,true表示“真”,false表示“伪”。
if (布尔值) 语句; // 或者 if (布尔值) 语句;
例如
if (m === 3) m = m + 1;
上面代码表示,只有在m等于3时,才会将其值加上1。
这种写法要求条件表达式后面只能有一个语句。如果想执行多个语句,必须在if的条件判断之后,加上大括号,表示代码块(多个语句合并成一个语句)。
完整版本写法
if (m !== 1) {
if (n === 2) {
console.log('hello');
}
} else {
console.log('world');
}
// world
switch 结构
switch (x) {
case 1:
console.log('x 等于1');
break;
case 2:
console.log('x 等于2');
break;
default:
console.log('x 等于其他值');
}
三元运算符
JavaScript 还有一个三元运算符(即该运算符需要三个运算子)?:,也可以用于逻辑判断。
(条件) ? 表达式1 : 表达式2
上面代码中,如果“条件”为true,则返回“表达式1”的值,否则返回“表达式2”的值。
var even = (n % 2 === 0) ? true : false;
下面有2个例子
//例子一 var myVar; console.log( myVar ? 'myVar has a value' : 'myVar does not have a value' ) // myVar does not have a value //例子二 var msg = '数字' + n + '是' + (n % 2 === 0 ? '偶数' : '奇数');
循环语句
while循环
var i = 0;
while (i < 100) {
console.log('i 当前为:' + i);
i = i + 1;
}
上面的代码将循环100次,直到i等于100为止。
下面的例子是一个无限循环,因为循环条件总是为真。
while (true) {
console.log('Hello, world');
}
for 循环
for (初始化表达式; 条件; 递增表达式)
语句
// 或者
for (初始化表达式; 条件; 递增表达式) {
语句
}
例子一:
var x = 3;
for (var i = 0; i < x; i++) {
console.log(i);
}
// 0
// 1
// 2
例子二:
var x = 3;
var i = 0;
while (i < x) {
console.log(i);
i++;
}
例子三:
for ( ; ; ){
console.log('Hello World');
}
do...while 循环
do...while循环与while循环类似,唯一的区别就是先运行一次循环体,然后判断循环条件。
do
do
语句
while (条件);
// 或者
do {
语句
} while (条件);
不管条件是否为真,do...while循环至少运行一次,这是这种结构最大的特点。另外,while语句后面的分号注意不要省略。
下面是一个例子。
var x = 3;
var i = 0;
do {
console.log(i);
i++;
} while(i < x);
break 语句和 continue 语句
break语句和continue语句都具有跳转作用,可以让代码不按既有的顺序执行。
break语句用于跳出代码块或循环。
var i = 0;
while(i < 100) {
console.log('i 当前为:' + i);
i++;
if (i === 10) break;
}
上面代码只会执行10次循环,一旦i等于10,就会跳出循环。
for循环也可以使用break语句跳出循环。
var i = 0;
while (i < 100){
i++;
if (i % 2 === 0) continue;
console.log('i 当前为:' + i);
}
上面代码只有在i为奇数时,才会输出i的值。如果i为偶数,则直接进入下一轮循环。
数据类型
字符串与数组
var s = 'hello'; s[0] // "h" s[1] // "e" s[4] // "o" // 直接对字符串使用方括号运算符 'hello'[1] // "e"
如果方括号中的数字超过字符串的长度,或者方括号中根本不是数字,则返回undefined。
'abc'[3] // undefined 'abc'[-1] // undefined 'abc'['x'] // undefined
但是,字符串与数组的相似性仅此而已。实际上,无法改变字符串之中的单个字符。
var s = 'hello'; delete s[0]; s // "hello" s[1] = 'a'; s // "hello" s[5] = '!'; s // "hello"
上面代码表示,字符串内部的单个字符无法改变和增删,这些操作会默默地失败。
length 属性
length属性返回字符串的长度,该属性也是无法改变的。
var s = 'hello'; s.length // 5 s.length = 3; s.length // 5 s.length = 7; s.length // 5
上面代码表示字符串的length属性无法改变,但是不会报错。
Base64 转码 (该知识点比较重要)
有时,文本里面包含一些不可打印的符号,比如 ASCII 码0到31的符号都无法打印出来,这时可以使用 Base64 编码,将它们转成可以打印的字符。另一个场景是,有时需要以文本格式传递二进制数据,那么也可以使用 Base64 编码。
所谓 Base64 就是一种编码方法,可以将任意值转成 0~9、A~Z、a-z、+和/这64个字符组成的可打印字符。使用它的主要目的,不是为了加密,而是为了不出现特殊字符,简化程序的处理。
JavaScript 原生提供两个 Base64 相关的方法。
-
btoa():任意值转为 Base64 编码 -
atob():Base64 编码转为原来的值
var string = 'Hello World!';
btoa(string) // "SGVsbG8gV29ybGQh"
atob('SGVsbG8gV29ybGQh') // "Hello World!"
注意,这两个方法不适合非 ASCII 码的字符,会报错。
btoa('你好') // 报错
要将非 ASCII 码字符转为 Base64 编码,必须中间插入一个转码环节,再使用这两个方法。
function b64Encode(str) {
return btoa(encodeURIComponent(str));
}
function b64Decode(str) {
return decodeURIComponent(atob(str));
}
b64Encode('你好') // "JUU0JUJEJUEwJUU1JUE1JUJE"
b64Decode('JUU0JUJEJUEwJUU1JUE1JUJE') // "你好"
对象
你其实完全可以理解为python里的字典
var obj = {
foo: 'Hello',
bar: 'World'
};
如果键名是数值,会被自动转为字符串。如果键名不符合标识名的条件(比如第一个字符为数字,或者含有空格或运算符),且也不是数字,则必须加上引号,否则会报错,记不住就一律加引号得了。
// 报错
var obj = {
1p: 'Hello World'
};
// 不报错
var obj = {
'1p': 'Hello World',
'h w': 'Hello World',
'p+q': 'Hello World'
};
对象的每一个键名又称为“属性”(property),它的“键值”可以是任何数据类型。如果一个属性的值为函数,通常把这个属性称为“方法”,它可以像函数那样调用。
var obj = {
p: function (x) {
return 2 * x;
}
};
obj.p(1) // 2
是对象还是代码块的问题
{ console.log(123) } // 123
({ foo: 123 }) // 正确
({ console.log(123) }) // 报错
这种差异在eval语句(作用是对字符串求值)中反映得最明显。
eval('{foo: 123}') // 123
eval('({foo: 123})') // {foo: 123}
对象的读值与赋值
var obj = {};
obj.foo = 'Hello';
obj['bar'] = 'World';
属性的查看
var obj = {
key1: 1,
key2: 2
};
Object.keys(obj);
// ['key1', 'key2']
属性的删除:delete 命令
delete命令用于删除对象的属性,删除成功后返回true。
var obj = { p: 1 };
Object.keys(obj) // ["p"]
delete obj.p // true
obj.p // undefined
Object.keys(obj) // []
注意,删除一个不存在的属性,delete不报错,而且返回true。
var obj = {};
delete obj.p // true
上面代码中,对象obj并没有p属性,但是delete命令照样返回true。因此,不能根据delete命令的结果,认定某个属性是存在的。
只有一种情况,delete命令会返回false,那就是该属性存在,且不得删除。
var obj = Object.defineProperty({}, 'p', {
value: 123,
configurable: false
});
obj.p // 123
delete obj.p // false
属性是否存在:in 运算符
in运算符用于检查对象是否包含某个属性(注意,检查的是键名,不是键值),如果包含就返回true,否则返回false。它的左边是一个字符串,表示属性名,右边是一个对象。
var obj = { p: 1 };
'p' in obj // true
'toString' in obj // true
in运算符的一个问题是,它不能识别哪些属性是对象自身的,哪些属性是继承的。就像上面代码中,对象obj本身并没有toString属性,但是in运算符会返回true,因为这个属性是继承的。
这时,可以使用对象的hasOwnProperty方法判断一下,是否为对象自身的属性。
var obj = {};
if ('toString' in obj) {
console.log(obj.hasOwnProperty('toString')) // false
}
属性的遍历:for...in 循环
var obj = {a: 1, b: 2, c: 3};
for (var i in obj) {
console.log('键名:', i);
console.log('键值:', obj[i]);
}
// 键名: a
// 键值: 1
// 键名: b
// 键值: 2
// 键名: c
// 键值: 3
for...in循环有两个使用注意点。
-
它遍历的是对象所有可遍历(enumerable)的属性,会跳过不可遍历的属性。
-
它不仅遍历对象自身的属性,还遍历继承的属性。
举例来说,对象都继承了toString属性,但是for...in循环不会遍历到这个属性。
var obj = {};
// toString 属性是存在的
obj.toString // toString() { [native code] }
for (var p in obj) {
console.log(p);
} // 没有任何输出
上面代码中,对象obj继承了toString属性,该属性不会被for...in循环遍历到,因为它默认是“不可遍历”的。
如果继承的属性是可遍历的,那么就会被for...in循环遍历到。但是,一般情况下,都是只想遍历对象自身的属性,所以使用for...in的时候,应该结合使用hasOwnProperty方法,在循环内部判断一下,某个属性是否为对象自身的属性。
var person = { name: '老张' };
for (var key in person) {
if (person.hasOwnProperty(key)) {
console.log(key);
}
}
// name
函数
js三种声明函数的方式
方法一
function print(s) {
console.log(s);
}
方法二
var print = function(s) {
console.log(s);
};
方法三 (这种没人用)
var add = new Function(
'x',
'y',
'return x + y'
);
// 等同于
function add(x, y) {
return x + y;
}
第一等公民
JavaScript 语言将函数看作一种值,与其它值(数值、字符串、布尔值等等)地位相同。凡是可以使用值的地方,就能使用函数。比如,可以把函数赋值给变量和对象的属性,也可以当作参数传入其他函数,或者作为函数的结果返回。函数只是一个可以执行的值,此外并无特殊之处。
由于函数与其他数据类型地位平等,所以在 JavaScript 语言中又称函数为第一等公民。
function add(x, y) {
return x + y;
}
// 将函数赋值给一个变量
var operator = add;
// 将函数作为参数和返回值
function a(op){
return op;
}
a(add)(1, 1)
// 2
函数名的提升
JavaScript 引擎将函数名视同变量名,所以采用function命令声明函数时,整个函数会像变量声明一样,被提升到代码头部。所以,下面的代码不会报错。
f();
function f() {}
表面上,上面代码好像在声明之前就调用了函数f。但是实际上,由于“变量提升”,函数f被提升到了代码头部,也就是在调用之前已经声明了。但是,如果采用赋值语句定义函数,JavaScript 就会报错。
f();
var f = function (){};
// TypeError: undefined is not a function
上面的代码等同于下面的形式。
var f;
f();
f = function () {};
上面代码第二行,调用f的时候,f只是被声明了,还没有被赋值,等于undefined,所以会报错。
注意,如果像下面例子那样,采用function命令和var赋值语句声明同一个函数,由于存在函数提升,最后会采用var赋值语句的定义。
var f = function () {
console.log('1');
}
function f() {
console.log('2');
}
f() // 1
上面例子中,表面上后面声明的函数f,应该覆盖前面的var赋值语句,但是由于存在函数提升,实际上正好反过来。
函数作用域
定义
作用域(scope)指的是变量存在的范围。在 ES5 的规范中,JavaScript 只有两种作用域:一种是全局作用域,变量在整个程序中一直存在,所有地方都可以读取;另一种是函数作用域,变量只在函数内部存在。
函数内部定义的变量,会在该作用域内覆盖同名全局变量。
var v = 1;
function f(){
var v = 2;
console.log(v);
}
f() // 2
v // 1
上面代码中,变量v同时在函数的外部和内部有定义。结果,在函数内部定义,局部变量v覆盖了全局变量v。
注意,对于var命令来说,局部变量只能在函数内部声明,在其他区块中声明,一律都是全局变量。
if (true) {
var x = 5;
}
console.log(x); // 5
上面代码中,变量x在条件判断区块之中声明,结果就是一个全局变量,可以在区块之外读取。
函数本身也是一个值,也有自己的作用域。它的作用域与变量一样,就是其声明时所在的作用域,与其运行时所在的作用域无关。
var a = 1;
var x = function () {
console.log(a);
};
function f() {
var a = 2;
x();
}
f() // 1
上面代码中,函数x是在函数f的外部声明的,所以它的作用域绑定外层,内部变量a不会到函数f体内取值,所以输出1,而不是2。
总之,函数执行时所在的作用域,是定义时的作用域,而不是调用时所在的作用域。
参数
js里的函数的参数,不用跟实际传过来的值一一对应
arguments 对象
由于 JavaScript 允许函数有不定数目的参数,所以需要一种机制,可以在函数体内部读取所有参数。这就是arguments对象的由来。
arguments对象包含了函数运行时的所有参数,arguments[0]就是第一个参数,arguments[1]就是第二个参数,以此类推。这个对象只有在函数体内部,才可以使用
var f = function (one) {
console.log(arguments[0]);
console.log(arguments[1]);
console.log(arguments[2]);
}
f(1, 2, 3)
需要注意的是,虽然arguments很像数组,但它是一个对象。数组专有的方法(比如slice和forEach),不能在arguments对象上直接使用。
如果要让arguments对象使用数组方法,真正的解决方法是将arguments转为真正的数组。下面是两种常用的转换方法:slice方法和逐一填入新数组。
var args = Array.prototype.slice.call(arguments);
// 或者
var args = [];
for (var i = 0; i < arguments.length; i++) {
args.push(arguments[i]);
}
关于slice函数的语法
let fruits = ['apple', 'banana', 'cherry', 'date', 'fig']; // 提取从索引1开始到索引3的元素 let slicedFruits = fruits.slice(1, 3); // 返回 ["banana", "cherry"] // 如果不指定end参数,则提取从start到数组末尾的元素 let slicedFruitsToEnd = fruits.slice(1); // 返回 ["banana", "cherry", "date", "fig"] // 如果start参数是负数,则表示从数组末尾开始计算的位置 let slicedFruitsFromEnd = fruits.slice(-3); // 返回 ["date", "fig"] // 如果省略start和end参数,则返回数组的一个完整副本 let fruitsCopy = fruits.slice(); // 返回 ["apple", "banana", "cherry", "date", "fig"]
闭包
闭包(closure)是 JavaScript 语言的一个难点,也是它的特色,很多高级应用都要依靠闭包实现。
理解闭包,首先必须理解变量作用域。前面提到,JavaScript 有两种作用域:全局作用域和函数作用域。函数内部可以直接读取全局变量。
var n = 999;
function f1() {
console.log(n);
}
f1() // 999
上面代码中,函数f1可以读取全局变量n。
但是,正常情况下,函数外部无法读取函数内部声明的变量。
function f1() {
var n = 999;
}
console.log(n)
// Uncaught ReferenceError: n is not defined(
上面代码中,函数f1内部声明的变量n,函数外是无法读取的。
如果出于种种原因,需要得到函数内的局部变量。正常情况下,这是办不到的,只有通过变通方法才能实现。那就是在函数的内部,再定义一个函数。
function f1() {
var n = 999;
function f2() {
console.log(n); // 999
}
}
上面代码中,函数f2就在函数f1内部,这时f1内部的所有局部变量,对f2都是可见的。但是反过来就不行,f2内部的局部变量,对f1就是不可见的。这就是 JavaScript 语言特有的"链式作用域"结构(chain scope),子对象会一级一级地向上寻找所有父对象的变量。所以,父对象的所有变量,对子对象都是可见的,反之则不成立。
既然f2可以读取f1的局部变量,那么只要把f2作为返回值,我们不就可以在f1外部读取它的内部变量了吗!
function f1() {
var n = 999;
function f2() {
console.log(n);
}
return f2;
}
var result = f1();
result(); // 999
上面代码中,函数f1的返回值就是函数f2,由于f2可以读取f1的内部变量,所以就可以在外部获得f1的内部变量了。
闭包就是函数f2,即能够读取其他函数内部变量的函数。由于在 JavaScript 语言中,只有函数内部的子函数才能读取内部变量,因此可以把闭包简单理解成“定义在一个函数内部的函数”。闭包最大的特点,就是它可以“记住”诞生的环境,比如f2记住了它诞生的环境f1,所以从f2可以得到f1的内部变量。在本质上,闭包就是将函数内部和函数外部连接起来的一座桥梁。
闭包的最大用处有两个,一个是可以读取外层函数内部的变量,另一个就是让这些变量始终保持在内存中,即闭包可以使得它诞生环境一直存在。请看下面的例子,闭包使得内部变量记住上一次调用时的运算结果。
function createIncrementor(start) {
return function () {
return start++;
};
}
var inc = createIncrementor(5);
inc() // 5
inc() // 6
inc() // 7
上面代码中,start是函数createIncrementor的内部变量。通过闭包,start的状态被保留了,每一次调用都是在上一次调用的基础上进行计算。从中可以看到,闭包inc使得函数createIncrementor的内部环境,一直存在。所以,闭包可以看作是函数内部作用域的一个接口。
为什么闭包能够返回外层函数的内部变量?原因是闭包(上例的inc)用到了外层变量(start),导致外层函数(createIncrementor)不能从内存释放。只要闭包没有被垃圾回收机制清除,外层函数提供的运行环境也不会被清除,它的内部变量就始终保存着当前值,供闭包读取。
闭包的另一个用处,是封装对象的私有属性和私有方法。
function Person(name) {
var _age;
function setAge(n) {
_age = n;
}
function getAge() {
return _age;
}
return {
name: name,
getAge: getAge,
setAge: setAge
};
}
var p1 = Person('张三');
p1.setAge(25);
p1.getAge() // 25
上面代码中,函数Person的内部变量_age,通过闭包getAge和setAge,变成了返回对象p1的私有变量。
注意,外层函数每次运行,都会生成一个新的闭包,而这个闭包又会保留外层函数的内部变量,所以内存消耗很大。因此不能滥用闭包,否则会造成网页的性能问题。
语句与表达式的区别
语句(Statement)
语句是执行动作的指令。它告诉JavaScript执行某些操作,通常会有副作用(即改变程序的状态或环境)。语句的结束通常需要一个分号(;),但这不是强制性的,因为在JavaScript中,分号是语句的可选结束符。例如:
// 赋值语句
let x = 10;
// 函数调用语句
doSomething();
// 控制流语句
if (condition) {
// ...
}
// 循环语句
for (let i = 0; i < 10; i++) {
// ...
}
表达式(Expression)
表达式是一个计算并返回值的代码片段。它可以是一个变量、一个函数调用、一个算术运算或者任何能够产生值的组合。表达式可以是语句的一部分,但单独的表达式不能作为语句存在(除非它是返回值的函数或语句末尾有分号)。 例如:
// 变量名是一个表达式 let y = 20; // 算术运算是一个表达式 let sum = 10 + 5; // 这里的 10 + 5 是一个表达式 // 函数调用也是一个表达式,特别是当它返回一个值时 let result = doSomething(); // doSomething() 是一个返回值的表达式
立即调用的函数表达式(IIFE)
根据 JavaScript 的语法,圆括号()跟在函数名之后,表示调用该函数。比如,print()就表示调用print函数。
有时,我们需要在定义函数之后,立即调用该函数。这时,你不能在函数的定义之后加上圆括号,这会产生语法错误。
function(){ /* code */ }();
// SyntaxError: Unexpected token (
产生这个错误的原因是,function这个关键字既可以当作语句,也可以当作表达式。
// 语句
function f() {}
// 表达式
var f = function f() {}
当作表达式时,函数可以定义后直接加圆括号调用。
var f = function f(){ return 1}();
f // 1
上面的代码中,函数定义后直接加圆括号调用,没有报错。原因就是function作为表达式,引擎就把函数定义当作一个值。这种情况下,就不会报错。
为了避免解析的歧义,JavaScript 规定,如果function关键字出现在行首,一律解释成语句。因此,引擎看到行首是function关键字之后,认为这一段都是函数的定义,不应该以圆括号结尾,所以就报错了。
函数定义后立即调用的解决方法,就是不要让function出现在行首,让引擎将其理解成一个表达式。最简单的处理,就是将其放在一个圆括号里面。
(function(){ /* code */ }());
// 或者
(function(){ /* code */ })();
上面两种写法都是以圆括号开头,引擎就会认为后面跟的是一个表达式,而不是函数定义语句,所以就避免了错误。这就叫做“立即调用的函数表达式”(Immediately-Invoked Function Expression),简称 IIFE。
注意,上面两种写法最后的分号都是必须的。如果省略分号,遇到连着两个 IIFE,可能就会报错。
// 报错
(function(){ /* code */ }())
(function(){ /* code */ }())
上面代码的两行之间没有分号,JavaScript 会将它们连在一起解释,将第二行解释为第一行的参数。
推而广之,任何让解释器以表达式来处理函数定义的方法,都能产生同样的效果,比如下面三种写法。
var i = function(){ return 10; }();
true && function(){ /* code */ }();
0, function(){ /* code */ }();
甚至像下面这样写,也是可以的。
!function () { /* code */ }();
~function () { /* code */ }();
-function () { /* code */ }();
+function () { /* code */ }();
(function () {
var tmp = newData;
processData(tmp);
storeData(tmp);
}());
eval 命令
基本用法
eval命令接受一个字符串作为参数,并将这个字符串当作语句执行。
eval('var a = 1;');
a // 1
数组的本质
本质上,数组属于一种特殊的对象。typeof运算符会返回数组的类型是object。
typeof [1, 2, 3] // "object"
但是,对于数值的键名,不能使用点结构
var arr = [1, 2, 3]; arr.0 // SyntaxError
上面代码中,arr.0的写法不合法,因为单独的数值不能作为标识符(identifier)。所以,数组成员只能用方括号arr[0]表示(方括号是运算符,可以接受数值)。
length 属性
数组的length属性,返回数组的成员数量。
['a', 'b', 'c'].length // 3
JavaScript 使用一个32位整数,保存数组的元素个数。这意味着,数组成员最多只有 4294967295 个(232 - 1)个,也就是说length属性的最大值就是 4294967295。
只要是数组,就一定有length属性。该属性是一个动态的值,等于键名中的最大整数加上1。
var arr = ['a', 'b']; arr.length // 2 arr[2] = 'c'; arr.length // 3 arr[9] = 'd'; arr.length // 10 arr[1000] = 'e'; arr.length // 1001
上面代码表示,数组的数字键不需要连续,length属性的值总是比最大的那个整数键大1。另外,这也表明数组是一种动态的数据结构,可以随时增减数组的成员。
length属性是可写的。如果人为设置一个小于当前成员个数的值,该数组的成员数量会自动减少到length设置的值。
in 运算符
检查某个键名是否存在的运算符in,适用于对象,也适用于数组。
var arr = [ 'a', 'b', 'c' ]; 2 in arr // true '2' in arr // true 4 in arr // false
上面代码表明,数组存在键名为2的键。由于键名都是字符串,所以数值2会自动转成字符串。
注意,如果数组的某个位置是空位,in运算符返回false。
var arr = []; arr[100] = 'a'; 100 in arr // true 1 in arr // false
上面代码中,数组arr只有一个成员arr[100],其他位置的键名都会返回false。
数组遍历
var a = [1, 2, 3];
// for循环
for(var i = 0; i < a.length; i++) {
console.log(a[i]);
}
// while循环
var i = 0;
while (i < a.length) {
console.log(a[i]);
i++;
}
var l = a.length;
while (l--) {
console.log(a[l]);
}
上面代码是三种遍历数组的写法。最后一种写法是逆向遍历,即从最后一个元素向第一个元素遍历。
数组的forEach方法,也可以用来遍历数组
var colors = ['red', 'green', 'blue'];
colors.forEach(function (color) {
console.log(color);
});
// red
// green
// blue
强制转换
强制转换主要指使用Number()、String()和Boolean()三个函数,手动将各种类型的值,分别转换成数字、字符串或者布尔值。
Number()
// 数值:转换后还是原来的值
Number(324) // 324
// 字符串:如果可以被解析为数值,则转换为相应的数值
Number('324') // 324
// 字符串:如果不可以被解析为数值,返回 NaN
Number('324abc') // NaN
// 空字符串转为0
Number('') // 0
// 布尔值:true 转成 1,false 转成 0
Number(true) // 1
Number(false) // 0
// undefined:转成 NaN
Number(undefined) // NaN
// null:转成0
Number(null) // 0
类似函数parseInt函数的使用
parseInt('42 cats') // 42
Number('42 cats') // NaN
String()
String(123) // "123"
String('abc') // "abc"
String(true) // "true"
String(undefined) // "undefined"
String(null) // "null"
String({a: 1}) // "[object Object]"
String([1, 2, 3]) // "1,2,3"
Boolean()
Boolean()函数可以将任意类型的值转为布尔值。
它的转换规则相对简单:除了以下五个值的转换结果为false,其他的值全部为true。
-
undefined -
null -
0(包含-0和+0) -
NaN -
''(空字符串)
Boolean(undefined) // false
Boolean(null) // false
Boolean(0) // false
Boolean(NaN) // false
Boolean('') // false
Boolean(true) // true
Boolean(false) // false
Boolean({}) // true
Boolean([]) // true
Boolean(new Boolean(false)) // true
自动转换
遇到以下三种情况时,JavaScript 会自动转换数据类型,即转换是自动完成的,用户不可见。
第一种情况,不同类型的数据互相运算。
123 + 'abc' // "123abc"
第二种情况,对非布尔值类型的数据求布尔值。
if ('abc') {
console.log('hello')
} // "hello"
第三种情况,对非数值类型的值使用一元运算符(即+和-)。
+ {foo: 'bar'} // NaN
- [1, 2, 3] // NaN
自动转换的规则是这样的:预期什么类型的值,就调用该类型的转换函数。比如,某个位置预期为字符串,就调用String()函数进行转换。如果该位置既可以是字符串,也可能是数值,那么默认转为数值。
由于自动转换具有不确定性,而且不易除错,建议在预期为布尔值、数值、字符串的地方,全部使用Boolean()、Number()和String()函数进行显式转换。
object对象
这里看下js函数说明里的内容
Object实例对象的方法
Object实例对象的方法,主要有以下六个。
-
Object.prototype.valueOf():返回当前对象对应的值。 -
Object.prototype.toString():返回当前对象对应的字符串形式。 -
Object.prototype.toLocaleString():返回当前对象对应的本地字符串形式。 -
Object.prototype.hasOwnProperty():判断某个属性是否为当前对象自身的属性,还是继承自原型对象的属性。 -
Object.prototype.isPrototypeOf():判断当前对象是否为另一个对象的原型。 -
Object.prototype.propertyIsEnumerable():判断某个属性是否可枚举。
//这里用来toString来判断数据类型
var o1 = new Object();
o1.toString() // "[object Object]"
var o2 = {a:1};
o2.toString() // "[object Object]"
var obj = {
p: 123
};
//Object.prototype.hasOwnProperty方法接受一个字符串作为参数,返回一个布尔值,表示该实例对象自身是否具有该属性。
obj.hasOwnProperty('p') // true
obj.hasOwnProperty('toString') // false
Object.getOwnPropertyDescriptor
Object.getOwnPropertyDescriptor 方法在 JavaScript 中用于获取指定对象上给定属性的描述信息。描述信息是一个包含属性的各种元数据的对象,例如属性是否可枚举、是否可写、默认值以及 getter 和 setter 函数等。
这个方法对于深入了解对象属性的具体行为和特征非常有用,尤其是在调试或者需要精确控制对象属性时。
下面是一个使用 Object.getOwnPropertyDescriptor 方法的例子:
// 创建一个对象,并定义一个属性
const myObject = {
myProperty: 'Hello, World!'
};
// 定义一个 getter 和一个 setter 函数
const getter = function () {
return this.myProperty + ' (accessed via getter)';
};
const setter = function (newValue) {
this.myProperty = newValue + ' (updated via setter)';
};
// 使用 Object.defineProperty 为对象添加一个带有 getter 和 setter 的属性
Object.defineProperty(myObject, 'accessorProperty', {
get: getter,
set: setter,
enumerable: true,
configurable: true
});
// 使用 Object.getOwnPropertyDescriptor 获取属性描述信息
const descriptor = Object.getOwnPropertyDescriptor(myObject, 'accessorProperty');
// 打印属性描述信息
console.log(descriptor);
// 输出:
// {
// value: 'Hello, World! (accessed via getter)',
// writable: false,
// enumerable: true,
// configurable: true,
// get: [Function: getter],
// set: [Function: setter]
// }
// 直接访问属性值
console.log(myObject.accessorProperty); // 输出: 'Hello, World! (accessed via getter)'
// 修改属性值
myObject.accessorProperty = 'Goodbye, World!';
console.log(myObject.accessorProperty); // 输出: 'Goodbye, World! (updated via setter)'
在这个例子中,我们首先创建了一个对象 myObject 并给它定义了一个普通的属性 myProperty。接着,我们定义了一个 getter 函数和一个 setter 函数,并将它们与 Object.defineProperty 方法一起使用,为 myObject 添加了一个带有访问器(accessor)的属性 accessorProperty。
使用 Object.getOwnPropertyDescriptor 方法,我们获取了 accessorProperty 的描述信息,并打印出来。描述信息对象包含了属性的值、是否可写、是否可枚举、是否可配置以及 getter 和 setter 函数的引用。
然后,我们通过直接访问 accessorProperty 来触发 getter 函数,并打印出它的返回值。之后,我们尝试修改 accessorProperty 的值,这将触发 setter 函数,并将修改后的值打印出来。
通过这个例子,我们可以看到 Object.getOwnPropertyDescriptor 方法如何帮助我们获取和理解对象属性的详细信息。
eval 命令
基本用法
eval命令接受一个字符串作为参数,并将这个字符串当作语句执行。
闭包
闭包(closure)是 JavaScript 语言的一个难点,也是它的特色,很多高级应用都要依靠闭包实现。
理解闭包,首先必须理解变量作用域。前面提到,JavaScript 有两种作用域:全局作用域和函数作用域。函数内部可以直接读取全局变量。
var n = 999;
function f1() {
console.log(n);
}
f1() // 999
上面代码中,函数f1可以读取全局变量n。
但是,正常情况下,函数外部无法读取函数内部声明的变量。
function f1() {
var n = 999;
}
console.log(n)
// Uncaught ReferenceError: n is not defined(
上面代码中,函数f1内部声明的变量n,函数外是无法读取的。
如果出于种种原因,需要得到函数内的局部变量。正常情况下,这是办不到的,只有通过变通方法才能实现。那就是在函数的内部,再定义一个函数。
function f1() {
var n = 999;
function f2() {
console.log(n); // 999
}
}
上面代码中,函数f2就在函数f1内部,这时f1内部的所有局部变量,对f2都是可见的。但是反过来就不行,f2内部的局部变量,对f1就是不可见的。这就是 JavaScript 语言特有的"链式作用域"结构(chain scope),子对象会一级一级地向上寻找所有父对象的变量。所以,父对象的所有变量,对子对象都是可见的,反之则不成立。
既然f2可以读取f1的局部变量,那么只要把f2作为返回值,我们不就可以在f1外部读取它的内部变量了吗!
function f1() {
var n = 999;
function f2() {
console.log(n);
}
return f2;
}
var result = f1();
result(); // 999
上面代码中,函数f1的返回值就是函数f2,由于f2可以读取f1的内部变量,所以就可以在外部获得f1的内部变量了。
闭包就是函数f2,即能够读取其他函数内部变量的函数。由于在 JavaScript 语言中,只有函数内部的子函数才能读取内部变量,因此可以把闭包简单理解成“定义在一个函数内部的函数”。闭包最大的特点,就是它可以“记住”诞生的环境,比如f2记住了它诞生的环境f1,所以从f2可以得到f1的内部变量。在本质上,闭包就是将函数内部和函数外部连接起来的一座桥梁。
闭包的最大用处有两个,一个是可以读取外层函数内部的变量,另一个就是让这些变量始终保持在内存中,即闭包可以使得它诞生环境一直存在。请看下面的例子,闭包使得内部变量记住上一次调用时的运算结果。
function createIncrementor(start) {
return function () {
return start++;
};
}
var inc = createIncrementor(5);
inc() // 5
inc() // 6
inc() // 7
上面代码中,start是函数createIncrementor的内部变量。通过闭包,start的状态被保留了,每一次调用都是在上一次调用的基础上进行计算。从中可以看到,闭包inc使得函数createIncrementor的内部环境,一直存在。所以,闭包可以看作是函数内部作用域的一个接口。
为什么闭包能够返回外层函数的内部变量?原因是闭包(上例的inc)用到了外层变量(start),导致外层函数(createIncrementor)不能从内存释放。只要闭包没有被垃圾回收机制清除,外层函数提供的运行环境也不会被清除,它的内部变量就始终保存着当前值,供闭包读取。
闭包的另一个用处,是封装对象的私有属性和私有方法。
function Person(name) {
var _age;
function setAge(n) {
_age = n;
}
function getAge() {
return _age;
}
return {
name: name,
getAge: getAge,
setAge: setAge
};
}
var p1 = Person('张三');
p1.setAge(25);
p1.getAge() // 25
上面代码中,函数Person的内部变量_age,通过闭包getAge和setAge,变成了返回对象p1的私有变量。
注意,外层函数每次运行,都会生成一个新的闭包,而这个闭包又会保留外层函数的内部变量,所以内存消耗很大。因此不能滥用闭包,否则会造成网页的性能问题。
语句与表达式的区别
语句(Statement)
语句是执行动作的指令。它告诉JavaScript执行某些操作,通常会有副作用(即改变程序的状态或环境)。语句的结束通常需要一个分号(;),但这不是强制性的,因为在JavaScript中,分号是语句的可选结束符。例如:
// 赋值语句
let x = 10;
// 函数调用语句
doSomething();
// 控制流语句
if (condition) {
// ...
}
// 循环语句
for (let i = 0; i < 10; i++) {
// ...
}
表达式(Expression)
表达式是一个计算并返回值的代码片段。它可以是一个变量、一个函数调用、一个算术运算或者任何能够产生值的组合。表达式可以是语句的一部分,但单独的表达式不能作为语句存在(除非它是返回值的函数或语句末尾有分号)。 例如:
// 变量名是一个表达式
let y = 20;
// 算术运算是一个表达式
let sum = 10 + 5; // 这里的 10 + 5 是一个表达式
// 函数调用也是一个表达式,特别是当它返回一个值时
let result = doSomething(); // doSomething() 是一个返回值的表达式
立即调用的函数表达式(IIFE)


















 1934
1934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











