







1、自增
赋值 = 最后计算
= 右边的从左往右加载值依次压入操作数栈
实际先算哪个,看运算符的优先级
自增、自减操作都是直接修改量的值,不经过操作数栈
最后的赋值之前,临时结果也是存储在操作数栈中
2、单例设计模式
一是某个类只能有一个实例—— 构造器私有化
二是它必须自行创建这个实例—— 用静态变量来保存这个唯一的实例
三是它必须自行向整个系统提供这个实例—— (1)直接暴露(2)用静态方法的get方法获取
饿汉式:不管需不需要都会new出对象。直接实例化,枚举式,静态代码块
懒汉式:延迟创建对象,静态内部类get,或者加锁
3、类初始化和实例初始化等
(1)、类初始化过程
1、一个类要创建实例需要先加载并初始化该类(main方法所在的类需要先加载和初始化)
2、一个子类要初始化需要先初始化父类
3、一个类初始化就是执行<clinit>() 方法,静态赋值,静态代码块,从上到下执行,只执行一次
(2)、实例初始化过程
1、实例初始化就是执行<init>() 方法
(1)、可以重载多个,有多少个构造器就有多少个
(2)、由非静态实例变量赋值,非静态代码块,从上到下执行,对应构造器(最后执行)构成
子类的实例化方法:
super()最前
(3)、方法重写Override
1、哪些方法不会被重写
(1)、final方法
(2)、静态方法
(3)、private等子类中不可见的方法
4、方法的参数传递机制
由方法区,栈,常量池,堆组成
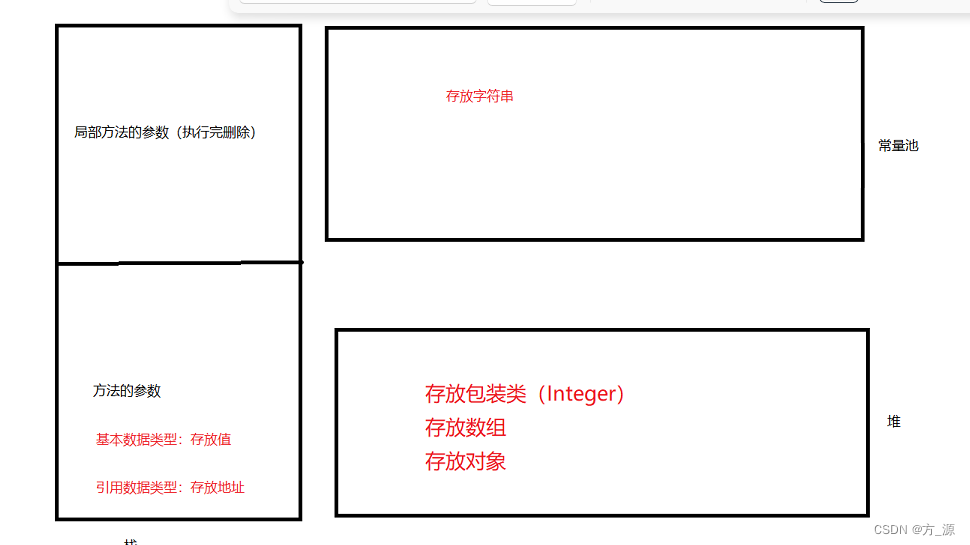
(1)、方法的参数传递机制
1、形参是基本数据类型:传递数据值
2、实参是引用数据类型:传递地址值
(2)、String、包装类(Integer)等对象的不可变性
字符串对象,包装类,不会改变,只会添加多一个值
5、递归与迭代
1、递归:方法自身调用自己
2、迭代:利用变量的原值推出新值
6、成员变量与局部变量
1、就近原则
2、变量的分类
局部变量与成员变量的区别:声明位置,修饰符,值存储的位置(局部变量:栈 / 实例变量(没有static修饰):堆 / 类变量(有static修饰,共享的):方法区)
3、非静态代码块的执行
4、方法的调用规则
项目中经验面试
1、Redis在项目中的使用场景
数据类型 使用场景
String 比如说,我想知道什么时候封锁一个IP地址。 Incrby 命令
Hash 存储用户信息【id,name,age】
Hset(key , field, value)
List 实际最新消息的排行,还可以利用List的push命令,将任务存在list
电商系统的秒杀活动
Set 可以自动排重,好友的集合
ZSet 以某一个条件为权重进行排序
2、Elasticsearch 和 solr 的区别
他们都是基于Lucene搜索服务器基础上开发的一款优秀的高性能的企业级搜索服务器。基于分词技术构建的倒排索引的方式进行查询
区别:
1、当实时建立索引时,solr会发生io阻塞,es性能高于solr
2、当不断动态添加数据时,solr会检索效率低下,es不会
3、solr需要借助zookeeper进行分布式管理,es自身带有分布式系统管理功能,Solr(动态web项目)需要部署到web服务器上面(tomcat)
4、Solr支持多种格式数据xml,json,csv等,es仅支持json
5、solr是传统的,es是新兴的,对已有数据进行查询solr更快
6、solr提供更多功能,es需要借助第三方工具
3、单点登录实现过程
4、购物车实现过程
购物车跟用户的关系:一个用户必须对应一个购物车,单点登录一定在购物车之前
跟购物车有关的操作有哪些:
添加购物车:
1、用户未登录状态:添加到上面地方?未登录的数据保存到什么地方?
a:Redis
b:Cookie
2、用户登录状态:
a:Redis缓存中:使用Hash
b:存在数据库中(两个都需要存放)
展示购物车:
1、用户未登录状态:
直接从Cookie中获取数据展示即可
2、用户登录状态:
用户一旦登录,必须显示数据库/redis+Cookie中的购物车的数据
5、消息队列在项目中的使用
背景:在分布式系统中是如何处理高并发的
由于在高并发的环境下,来不及同步处理用户发送的请求,则会导致请求发生阻塞。比如说:大量的insert,update之类的请求同时到达数据库MYSQL,直接导致无数的行锁表锁,甚至会导致请求堆积很多,从而触发too many connections错误。使用消息队列的异步通信可以解决
第一次面试
1、bean的自动装配方式详细说明
(1)、根据类型自动装配(byType):Spring容器会自动查找与要注入的属性类型匹配的Bean。如果存在多个匹配的Bean,会抛出异常。可以使用 @Autowired 注解或者 XML 配置中的 <bean> 元素的 autowire 属性来实现。
(2)、根据名称自动装配(byName):Spring容器会自动查找与要注入的属性名称匹配的Bean。可以使用 @Autowired 注解或者 XML 配置中的 <bean> 元素的 autowire 属性来实现。
(3)、构造函数自动装配(constructor):Spring容器会自动查找与要注入的构造函数参数类型匹配的Bean。可以使用 @Autowired 注解或者 XML 配置中的 <bean> 元素的 autowire 属性来实现
(4)、注解自动装配:Spring提供了一些注解来实现自动装配,包括@Autowired、@Resource等。这些注解可以用于字段、方法、构造函数等位置,通过注解来指定要注入的Bean
(5)、自定义装配规则:还可以通过实现BeanPostProcessor接口或者使用@Conditional注解等方式来自定义装配规则。这样可以根据特定的条件或者逻辑来确定要注入的Bean。
2、bean的生命周期详细说明
(1)、实例化:在实例化阶段,Spring容器根据配置信息或者注解创建Bean的实例。通常通过调用构造函数来完成。
(2)、属性赋值:在属性赋值阶段,Spring容器将配置的属性值或者引用注入到Bean的属性中。通常通过@Autowried、@Value注解或者XML配置中的<property>元素来实现
(3)、初始化:在初始化阶段,Spring容器会调用Bean的初始化方法。可以通过实现InitializingBean接口或者使用@PostConstruct注解来指定初始化方法。
(4)、销毁:在销毁阶段,Spring容器会调用Bean的销毁方法。可以通过实现DisposableBean接口或者使用注解@PreDestroy注解来指定销毁方法。
3、mybatis的一级缓存和二级缓存详细说明
(1)、一级缓存是mybatis默认开启的缓存机制,它是指在同一个SqlSession中,对于相同的查询语句,第一次查询数据库后,将查询结果缓存起来,并在后续的查询中直接返回缓存的结果,而不再访问数据。
a:一级缓存的作用范围是SqlSession级别的,同一个SqlSession中的缓存是共享的
b:一级缓存是自动开启的,不需要进行额外的配置。
c:一级缓存的生命周期是与SqlSession相关联的,当SqlSession被关闭、提交或回滚时,壹一级缓存也会被清空。
(2)、二级缓存是在多个SqlSession之间共享的缓存,它可以跨越多个SqlSession的边界,提供了更广泛的缓存范围。
a:二级缓存的作用范围是Mapper级别的,同一个Mapper接口中的缓存是共享的。
b:二级缓存需要进行额外的配置,通过在Mapper接口对应的XML文件中添加<cache>元素配置
c:二级缓存的实现是通过将查询结果序列化后存储在内存中,因此要确保查询结果是可序列化的。
d:二级缓存的生命周期与整个应用程序相关联,随之关闭而被清空
需要注意的是,一级缓存和二级缓存的使用是互斥的,即开启了二级缓存的情况下,一级缓存是不生效的。可以通过在 Mapper 接口对应的 XML 文件中的 <select> 元素上加 useCache="false" 属性来禁用二级缓存。
4、redis对与性能方面的详细说明
(1)、内存存储:Redis将数据存储在内存中,因此读写速度非常快。
(2)、单线程模型:Redis使用单线程模型来处理客户端请求,这样可以避免多线程间的竞争和锁的开销。使得redis在处理请求时非常高效。
(3)、非阻塞I/O:Redis使用非阻塞I/O模型来处理网络请求,通过使用事件循环机制,可以在单线程中同时处理多个连接。大大提高Redis的并发能力,使其能够处理大量的并发请求。
(4)、数据结构简单:提供了多种数据结构,如字符串、列表、哈希、集合和有序集合等,实现简单执行效率高
(5)、持久化支持:提供两种持久化方式,即RDB(快照)和AOF(日志),可以将内存中的数据持久化到磁盘上。重启或者崩溃都可以加载持久化文件来恢复数据,确保数据的可靠性。
(6)、高级性能支持:提供了一些高级功能。如发布订阅、事务、Lua脚本等,这些功能实现非常高效。
5、假如同时有百万级别的请求访问怎么处理详细说明
(1)、横向扩展:采用集群化部署,将系统划分为多个节点,每个节点处理部分请求。可以使用负载均衡器(nginx)将请求分发到不同的节点上。
(2)、缓存:使用缓存技术(redis)来缓存频繁访问的数据,减少对后端数据库的请求压力。缓存可以存储经常访问的数据,提高读取速度和系统的响应能力。
(3)、异步处理:将一部分请求转换为异步处理,通过消息队列(RabbitMQ)将请求发送到后台进行处理,提高系统的并发处理能力。
(4)、数据分片:将数据分散存储在多个节点上,通过哈希算法或一致性哈希算法将请求的负载均衡到不同的节点上,提高整个系统的处理能力。
(5)、弹性伸缩:根据实际请求量的变化动态调整系统的资源配置。可以使用自动化的扩展方案,根据监控指标(如CPU、内存、网络等)的变化,自动增加或减少节点数量,保证系统的稳定性和性能。
(6)、数据库优化:对数据库进行优化,包括索引优化、查询优化、分库分表等通过合理的数据库设计和优化,提高数据库的读写性能和并发能力。
(7)、CDN加速:使用内容分发网络(CDN)来分发静态资源,减少服务器的负载和网络延迟。CDN可以将静态文件缓存在离用户较近的边缘节点上,提高用户的访问速度和系统的并发处理能力。
(8)、异地多活:在不同的地理位置部署多个节点,实现异地多活的架构。通过数据同步和负载均衡,提高系统的可用性和容灾能力。
(9)、高速缓存:使用高速缓存技术(如Redis、Memcached)来缓存计算结果,减少计算的时间和资源消耗。可以将复杂的计算过程缓存起
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









