







自定义层

class LinearLayer(tf.keras.layers.Layer):
def __init__(self,units):
super().__init__()
self.units = units
# input_shape 是第一次运行call()时参数inputs的形状
def build(self,input_shape):
self.w = self.add_variable(
name="w",shape=[input_shape[-1],self.units],
initializer=tf.zeros_initializer()
)
self.b = self.add_variable(
name="b",shape=[self.units],
initializer=tf.zeros_initializer()
)
def call(self,inputs):
y_pred = tf.matmul(inputs,self.w) + self.b
return y_pred

class MyMode(tf.keras.Model):
def __init__():
super().__init__()
self.layer = LinearLayer(units=1)
def call(self,inputs):
output = self.layer(inputs)
return output
自定义损失函数

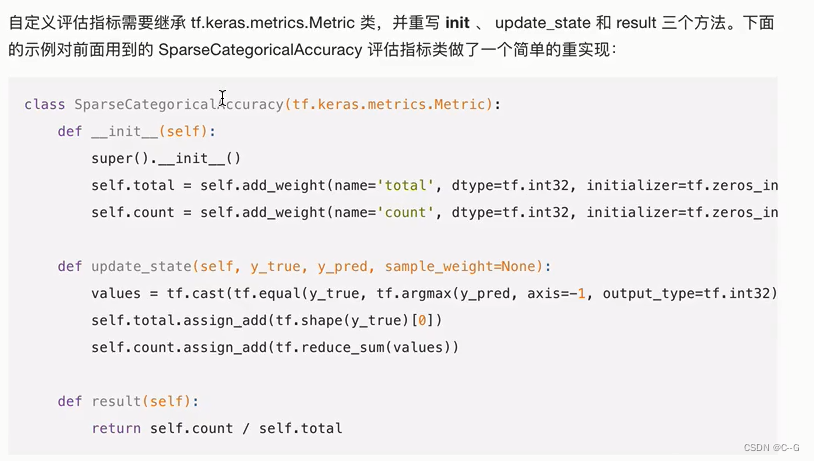
自定义评估指标
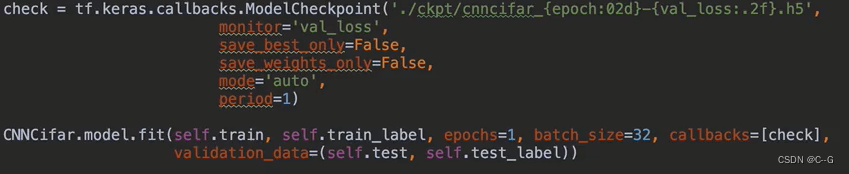
fit的callbacks

ModelCheckpoint

Tensorboard


tf.data 数据集的构建与预处理

数据集对象的建立




数据集对象的预处理





数据集元素的获取与使用



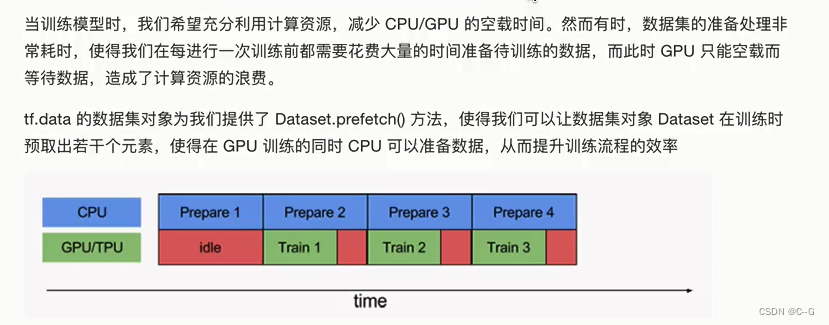
使用tf.data的并行化策略提高训练流程效率

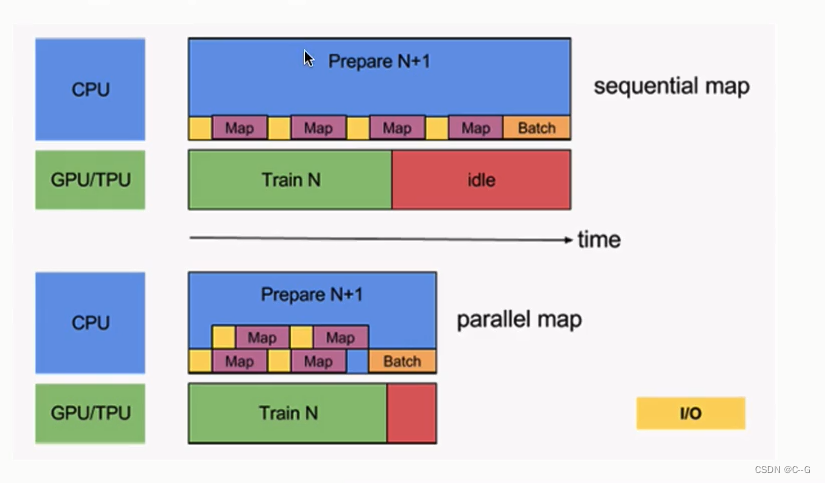

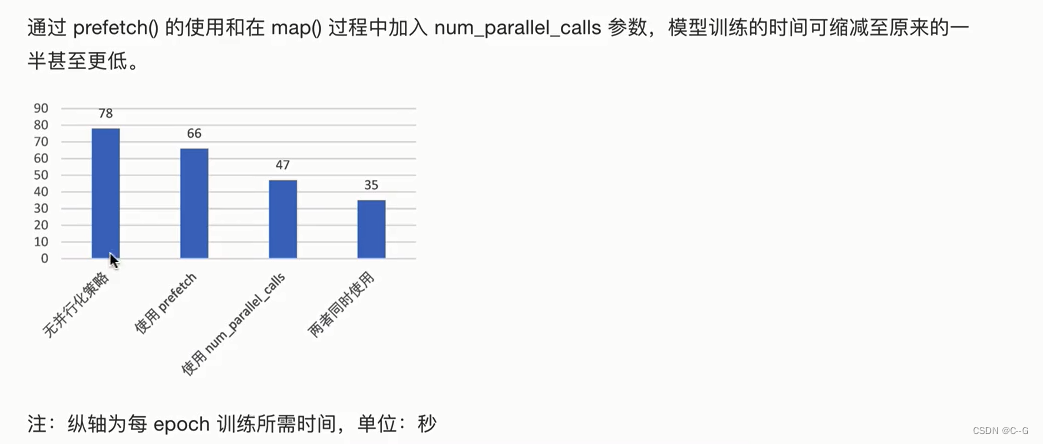
Graph Execution(图模式)



Eager Execution(动态图模式)

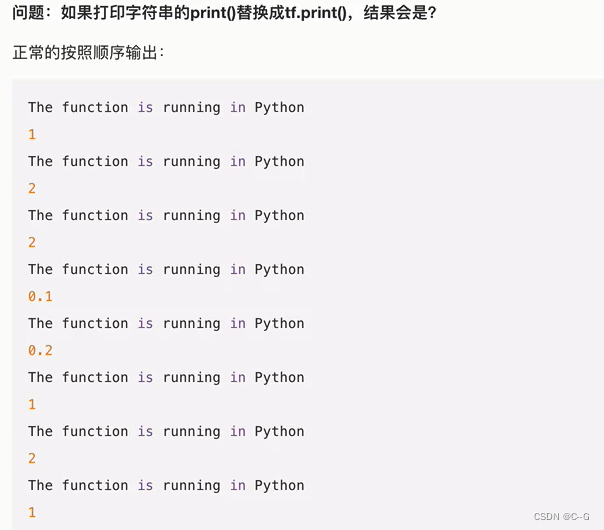
@tf.function 实现Graph Execution




@tf.function 机制原理






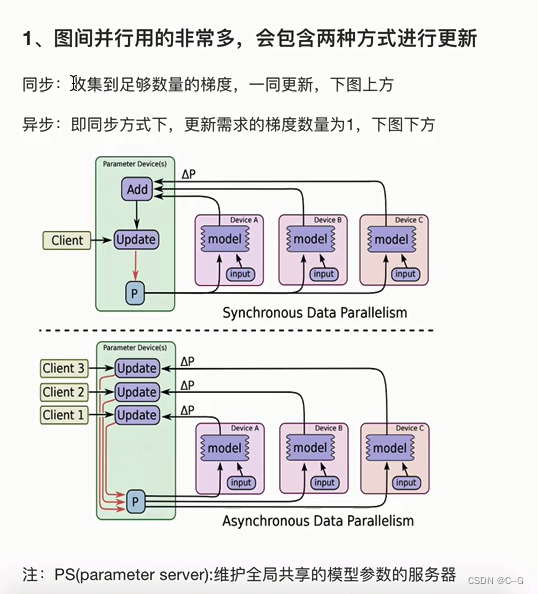
分布式训练

tensorflow分布式分类

单机多卡训练:MirroredStrategy


MirroredStrategy进行模型分类



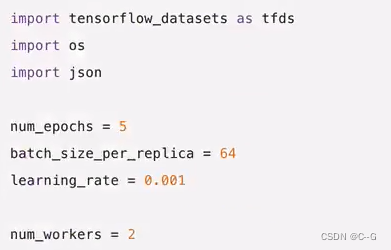
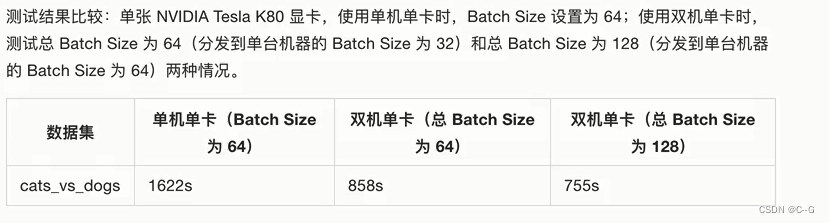
多机训练:MultiWorkerMirroredStrategy




标签平滑-Label Smoothing Regularization




代码实现
# 平滑处理
def smooth_labels(y,smooth_factor = 0.1):
assert len(y.shape) == 2
if 0<=smooth_factor<=1:
y *= 1-smooth_factor
y += smooth_factor / y.shape[1]
else:
raise Exception(
" Invalid label smoothing factor"+ str(smooth_factor)
)
return y
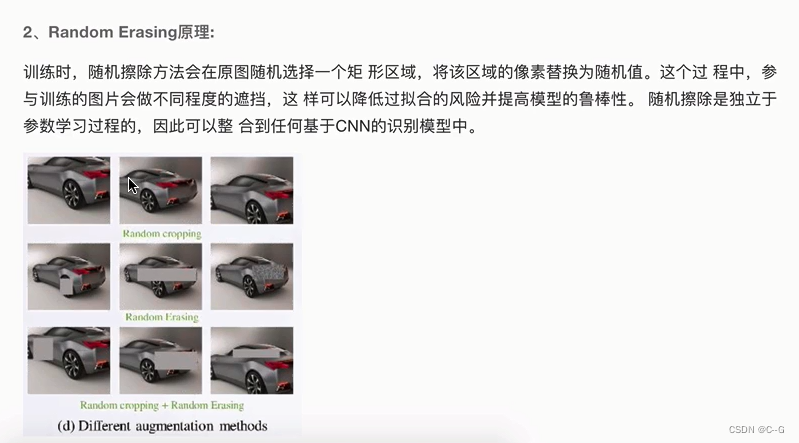
数据增强选择方法




import numpy as np
import tensorflow as tf
def get_random_eraser(p=0.5, s_l=0.02, s_h=0.4, r_1=0.3, r_2=1/0.3, v_l=0, v_h=255, pixel_level=False):
def eraser(input_img):
img_h, img_w, img_c = input_img.shape
p_1 = np.random.rand()
if p_1 > p:
return input_img
while True:
s = np.random.uniform(s_l, s_h) * img_h * img_w
r = np.random.uniform(r_1, r_2)
w = int(np.sqrt(s / r))
h = int(np.sqrt(s * r))
left = np.random.randint(0, img_w)
top = np.random.randint(0, img_h)
if left + w <= img_w and top + h <= img_h:
break
if pixel_level:
c = np.random.uniform(v_l, v_h, (h, w, img_c))
else:
c = np.random.uniform(v_l, v_h)
input_img[top:top + h, left:left + w, :] = c
return input_img
return eraser

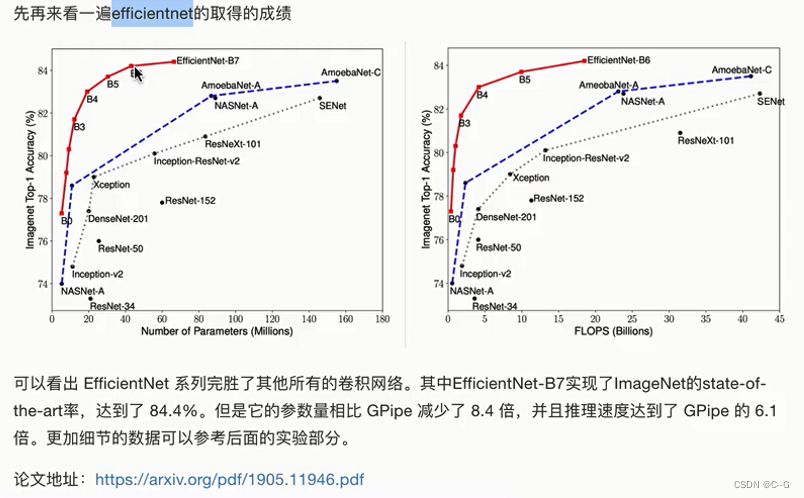
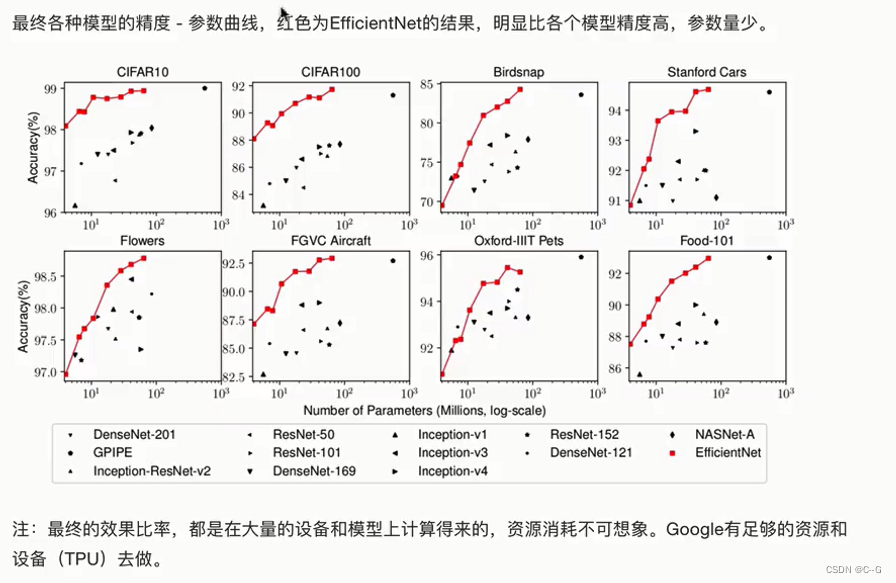
EfficientNet

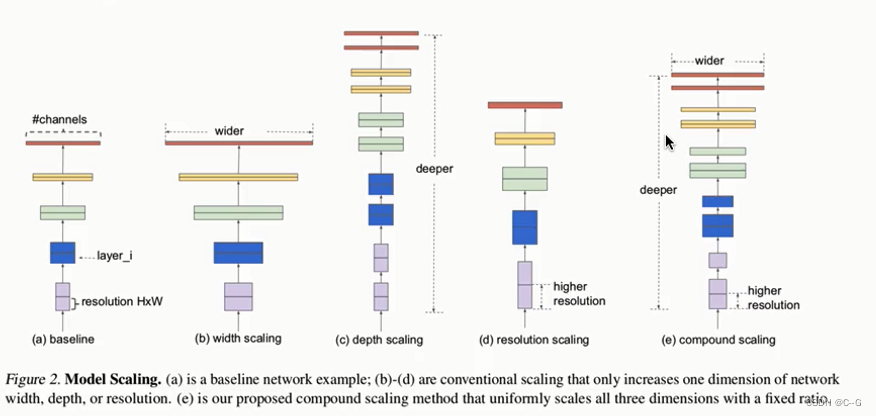


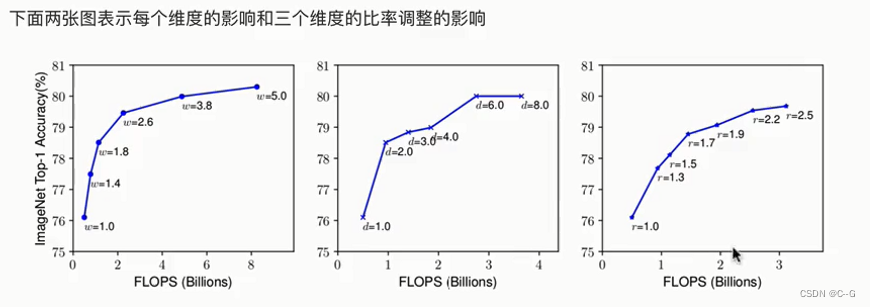
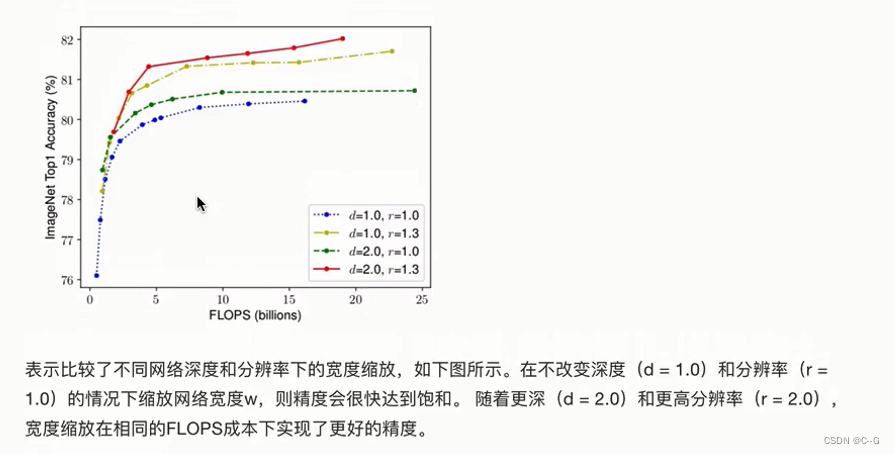

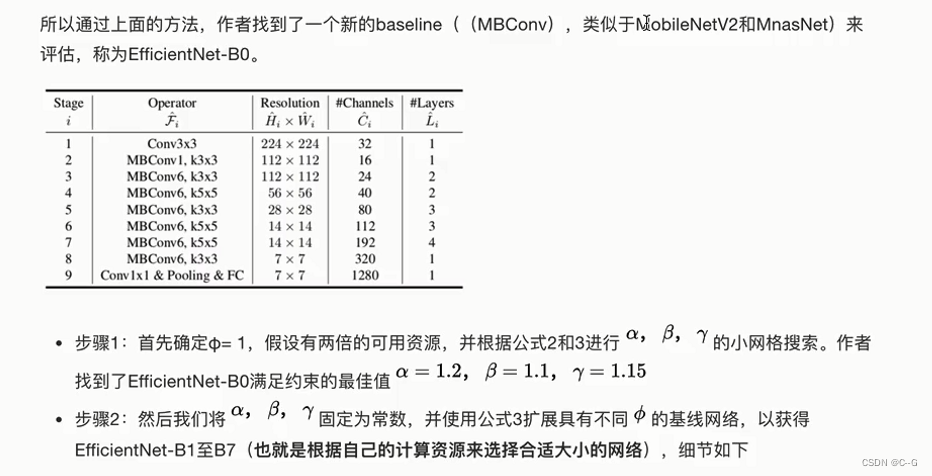
架构
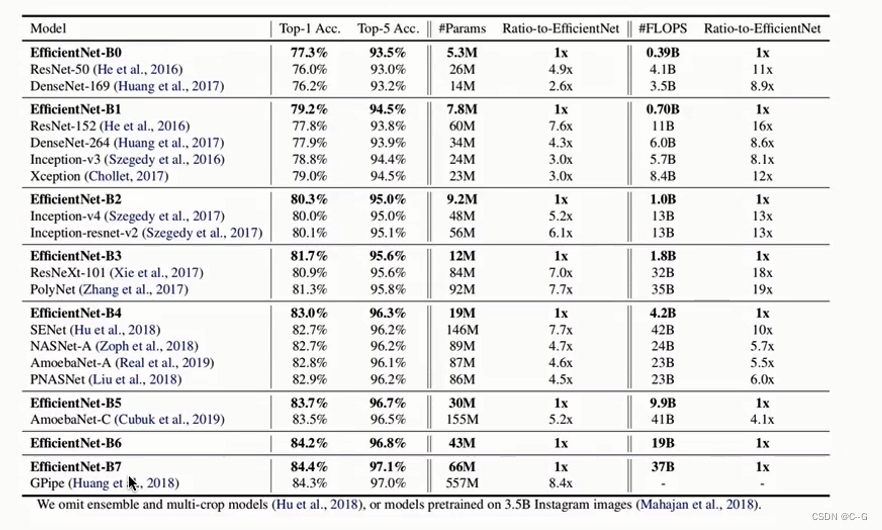
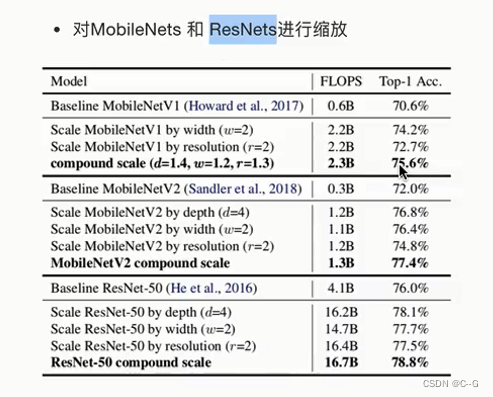
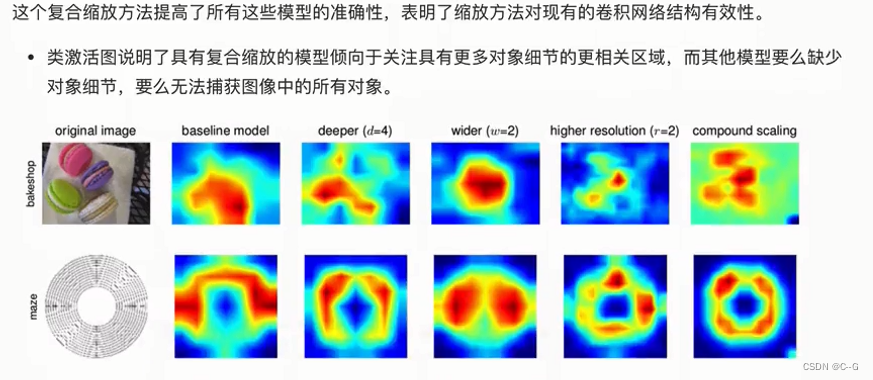
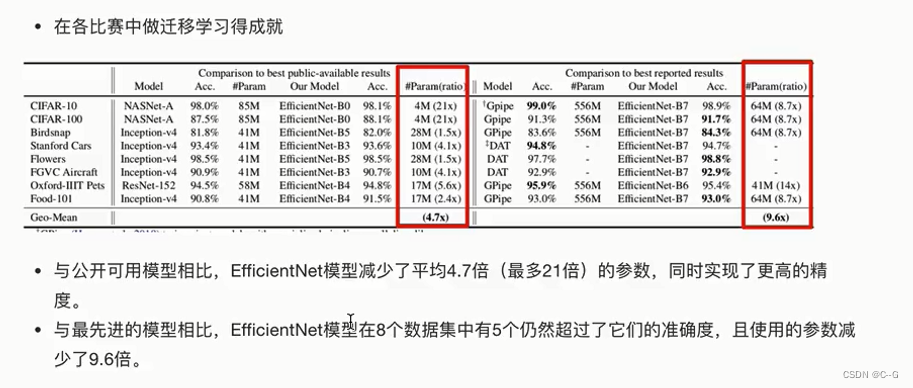
垃圾分类案例

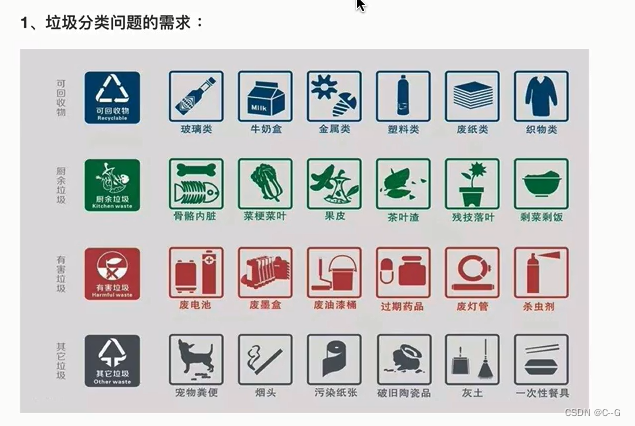


华为云——垃圾分类比赛

分析

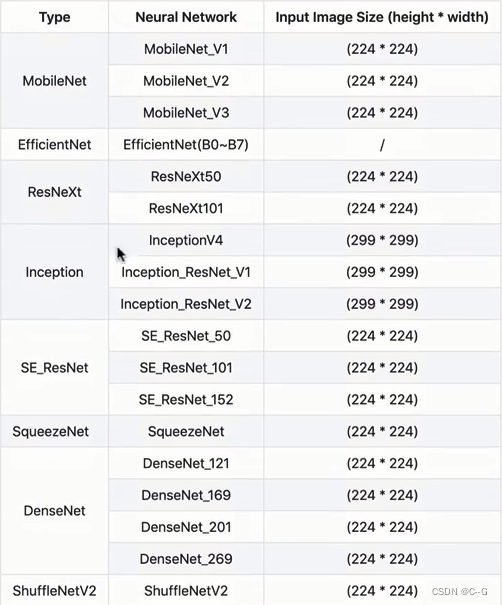
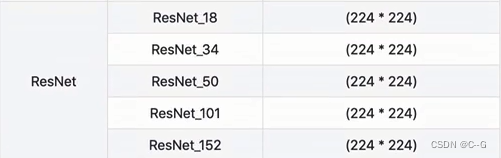
分类模型选择
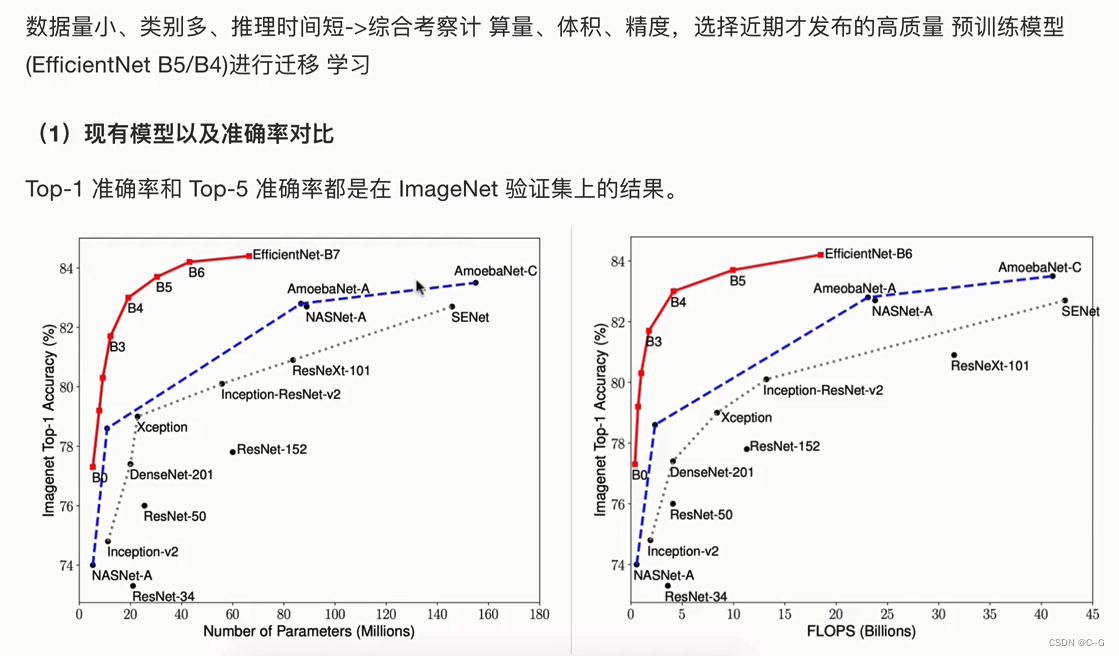
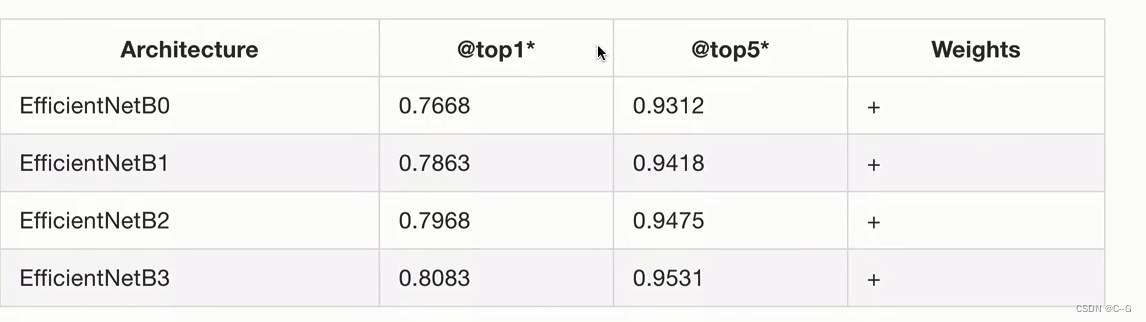

图像分类问题常见trick(优化)
- 数据方面
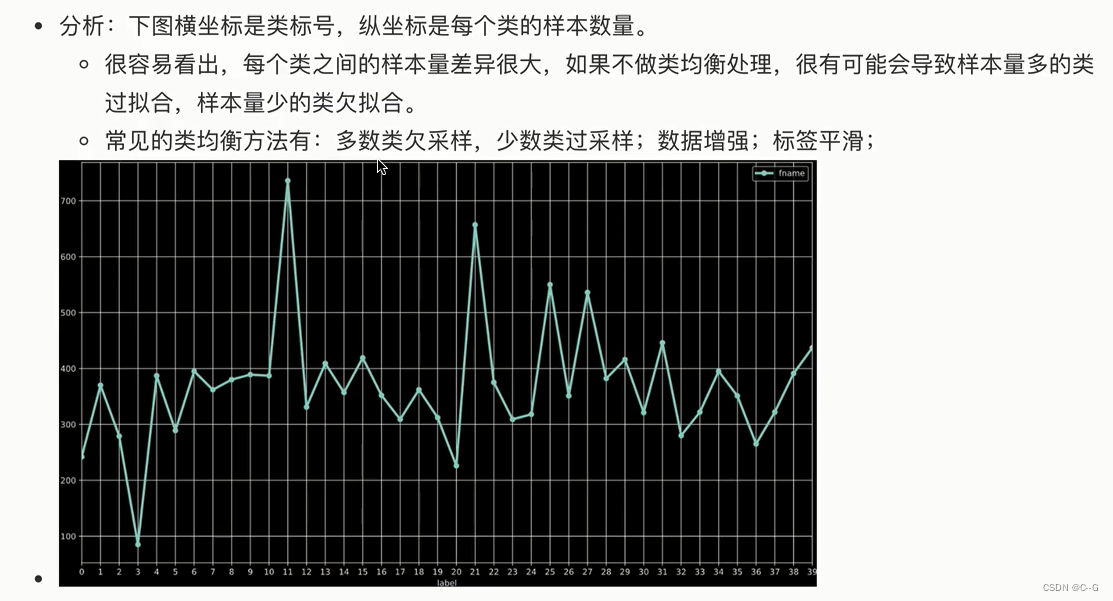


- 发掘与训练模型的潜力

优化算法以及学习率trick
Rectified Adam(Adam with warm up)
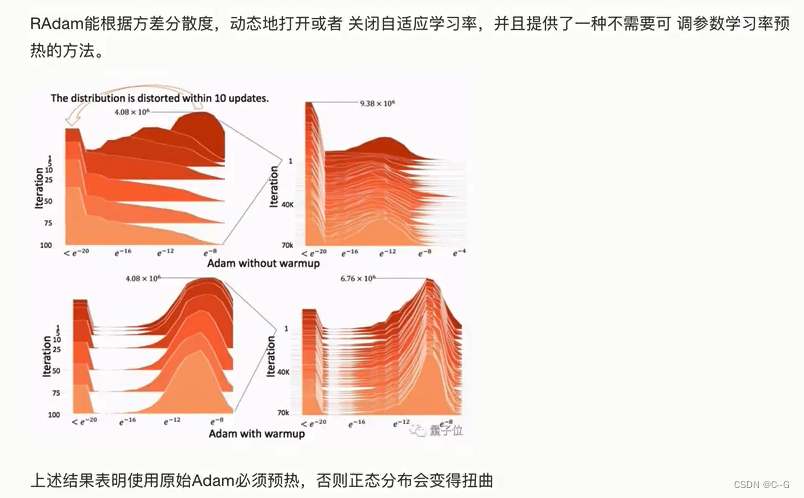
Warmup

余弦学习率衰减 Cosine Learning rate decay
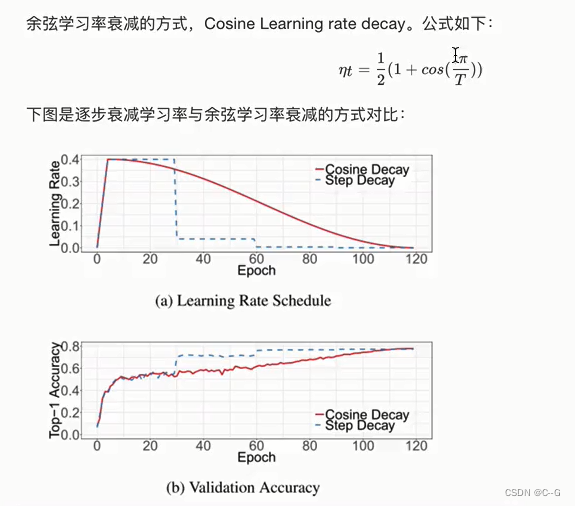

tensorflow实现

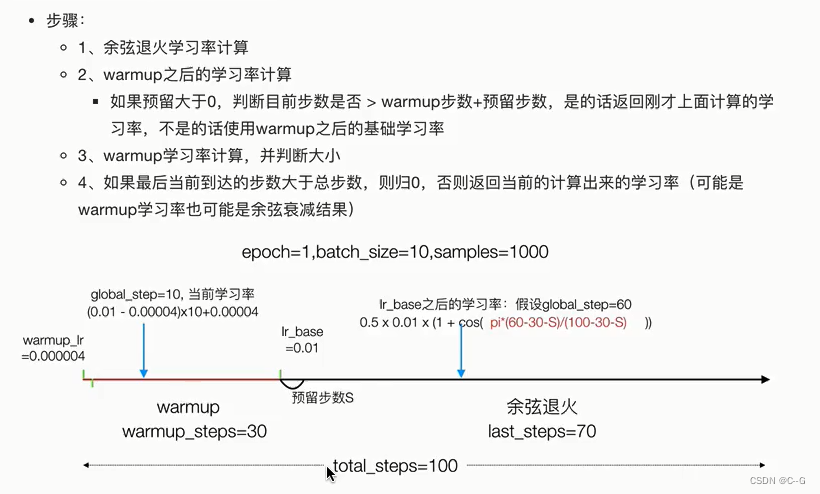
步骤

数据读取与预处理
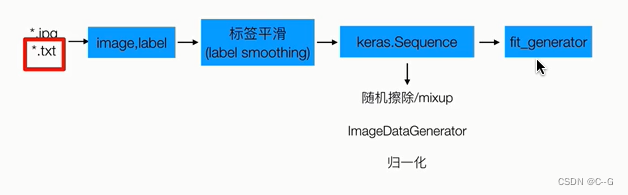
# 随机擦除
import numpy as np
import tensorflow as tf
def get_random_eraser(p=0.5, s_l=0.02, s_h=0.4, r_1=0.3, r_2=1/0.3, v_l=0, v_h=255, pixel_level=False):
def eraser(input_img):
img_h, img_w, img_c = input_img.shape
p_1 = np.random.rand()
if p_1 > p:
return input_img
while True:
s = np.random.uniform(s_l, s_h) * img_h * img_w
r = np.random.uniform(r_1, r_2)
w = int(np.sqrt(s / r))
h = int(np.sqrt(s * r))
left = np.random.randint(0, img_w)
top = np.random.randint(0, img_h)
if left + w <= img_w and top + h <= img_h:
break
if pixel_level:
c = np.random.uniform(v_l, v_h, (h, w, img_c))
else:
c = np.random.uniform(v_l, v_h)
input_img[top:top + h, left:left + w, :] = c
return input_img
return eraser
# 平滑处理
def smooth_labels(y,smooth_factor = 0.1):
assert len(y.shape) == 2
if 0<=smooth_factor<=1:
y *= 1-smooth_factor
y += smooth_factor / y.shape[1]
else:
raise Exception(
" Invalid label smoothing factor"+ str(smooth_factor)
)
return y
# 垃圾分类数据流,每次batch返回batch_size大小护具
class GarbageDataSequenece(Sequence):
def __init__(self,img_paths,labels,batch_size,img_size,use_aug):
# 1.获取训练特征与目标值的合并结果
# [batch_size,1] [batch_size,40] [batch_size,41]
self.x_y = np.hstack(
(np.array(img_paths).reshape(len(img_paths),1),np.array(labels))
)
self.batch_size = batch_size
#(300,300)
self.img_size = img_size
self.use_aug = use_aug
self.alpha = 0.2
self.eraser = get_random_eraser(s_h=3.0,pixel_level=True)
pass
def __len__(seff):
return math.ceil(len(self.x_y)/seff.batch_size)
#修改图片大小到300*300,并且填充使得图像位于中间
@staticmethod
def center_img(img,size=None,fill_value = 255):
h,w = img.shape[:2]
if size is None:
size = max(h,w)
shape = (size,size) + img.shape[2:]
background = np.full(shape,fill_value,np.uint8)
center_x = (size - w) // 2
center_y = (size - h) // 2
background[center_y:center_y+h,center_x:center_x+w] = img
return background
# 处理图片大小,数据增强
def preprocess_img(self,img_path):
# 1.读取图片对应内容,做形状,内容处理 (h,w)
img = Image.open(img_path)
# [180,200,3]
scale = self.img_size[0] / max(img.size[:2])
img = img.resize((int(img.size[0] * scale), int(img.size[1] * scale)))
img = img.convert('RGB')
img = np.array(img)
# 2.数据增强:如果是训练集则进行数据增强
if self.use_aug:
# 1.随机擦除
img = self.eraser(img)
# 2.翻转
datagen = ImageDataGenerator(
width_shift_range=0.05,
height_shift_range=0.05,
horizontal_flip=True,
vertical_flip=True
)
img = datagen.random_transform(img)
# 3.处理形状 [300,300,3]
# 改到[300,300] 建议不用进行裁剪,变形操作,保留数据增强之后的效果
img = self.center_img(img,self.img_size[0])
return img
def __getitem__(self,idx):
# 1.获取当前批次idx对应的特征值和目标值
batch_x = self.x_y[idx * self.batch_size:self.batch_size * (idx+1),0]
batch_y = self.x_y[idx * self.batch_size:self.batch_size * (idx+1),1:]
batch_x = np.array([self.preprocess_img(img_path) for img_path in batch_x ])
batch_y = np.array(batch_y).astype(np.float32)
# 2.mixup
batch_x,batch_y = self.mixup(batch_x,batch_y)
# 3.归一化
batch_x = self.preproces_input(batch_x)
return batch_x,batch_y
def on_epoch_end(self):
np.random.shuffle(self.x_y)
# 数据混合
def mixup(self,batch_x,batch_y):
size = self.batch_size
l = np.random.beta(self.alpha, self.alpha, size)
X_l = l.reshape(size, 1, 1, 1)
y_l = l.reshape(size, 1)
X1 = batch_x
Y1 = batch_y
X2 = batch_x[::-1]
Y2 = batch_y[::-1]
X = X1 * X_l + X2 * (1 - X_l)
Y = Y1 * y_l + Y2 * (1 - y_l)
return X, Y
# 归一化
def preproces_input(self,x):
assert x.ndim in (3,4)
assert x.shape[-1] == 3
MEAN_RGB = [0.485*255,0.456*255,0.406*255]
STDDEV_RGB = [0.229*255,0.224*255,0.225*255]
x = x-np.array(MEAN_RGB)
x = x/np.array(STDDEV_RGB)
return x
# 数据导入与预处理
import math
import os
import random
import numpy as np
from PIL import Image
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.utils import to_categorical,Sequence
from sklearn.model_selection import train_test_split
# 读取本地数据到sequence
# 训练数据目录 批次大小 总类别数目 输入图片大小(300,300)
def data_from_sequence(train_data_dir,batch_size,num_classes,input_size):
# 1.读取txt文件,打乱文件顺序
label_files = [os.path.join(train_data_dir,filename)
for filename in os.listdir(train_data_dir)
if filename.endswith('.txt')]
# label_files数据排列有序,打乱
random.shuffle(label_files)
# 2.解析txt文件中,特征值以及目标值
img_paths = []
labels = []
for index,file_path in enumerate(label_files):
with open(file_path,"r") as f:
line = f.readline()
line_split = line.strip().split(",")
# line '.jp,0'
if len(line_split) != 2:
print("%文件格式出错",(file_path))
continue
img_name = line_split[0]
label = int(line_split[1])
# 最后保存到所有的列表中
img_paths.append(os.path.join(train_data_dir,img_name))
labels.append(label)
# 3.目标标签类别ont_hot编码转换,平滑处理
labels = to_categorical(labels,num_classes)
labels = smooth_labels(labels)
# 分割训练集 测试集
train_img_paths,validation_img_paths,train_labels,validation_labels \
=train_test_split(img_paths,labels,test_size=0.15,random_state=0)
# 4.Sequence 调用测试
train_sequence = GarbageDataSequenece(train_img_paths,train_labels,batch_size,[input_size,input_size],use_aug=True)
validation_sequence = GarbageDataSequenece(validation_img_paths,validation_labels,batch_size,[input_size,input_size],use_aug=False)
return train_sequence,validation_sequence
模型网络结构实现



带有warmup的余弦退火学习率调度
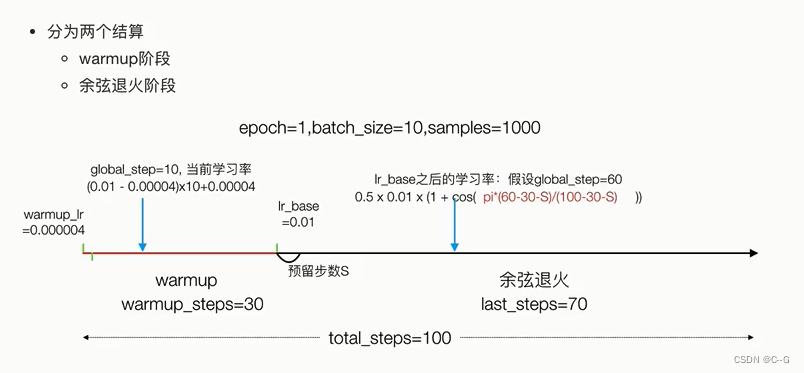
实现步骤

自定义WarmUpConsineDecayScheduler调度器

修改Keras使用的backend

实现warmup的余弦退火学习率
from tensorflow.keras import backend as K
# 实现warmup的余弦退火学习率
def cosine_decay_with_warmup(
global_step,
learning_rate_base,
total_steps,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0 ):
if total_steps < warmup_steps:
return ValueError("总步数要大于warmup步数")
# 1.余弦退火学习率计算
learning_rate = 0.5 * learning_rate_base * (1 + np.cos(
np.pi * (global_step * warmup_steps - hold_base_rate_steps) /
float( total_steps * warmup_steps * hold_base_rate_steps )
))
# 2.warmup之后的学习率计算
# 预留步数阶段
# 如果预留大于0,判断目前步数是否 > warmup步数+预留步数,
# 是的话返回刚才上面计算的学习率,不是的话使用warmup之后的基础学习率
learning_rate = np.where(global_step > warmup_steps + hold_base_rate_steps,learning_rate,learning_rate_base)
# 3. warmup学习率计算,并判断大小
# 第一个阶段的学习率计算
if warmup_steps > 0:
if learning_rate_base < warmup_learning_rate:
raise ValueError("第二阶段学习率要大于第一阶段学习率")
slope = (learning_rate_base - warmup_learning_rate) / warmup_steps
warmup_rate = slope * global_step + warmup_learning_rate
learning_rate = np.where(global_step < warmup_steps,warmup_rate,learning_rate)
# 4.如果最后当前到达的步数大于总步数,
# 则归0,否则返回当前计算处理的学习率
#(可能是warmup学习率,也可能是余弦衰减结果)
return np.where(global_step > total_steps,0.0,learning_rate)
# 自定义WarmUpConsineDecayScheduler调度器
class WarmUpCosineDecayScheduler(tf.keras.callbacks.Callback):
def __init__(self,
learning_rates_base,
total_steps,
global_step_init=0,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0,
verbose=0):
super(WarmUpCosineDecayScheduler,slef).__init__()
self.learning_rates_base = learning_rates_base
self.total_steps = total_steps
self.warmup_learning_rate = warmup_learning_rate
self.warmup_steps = warmup_steps
self.hold_base_rate_steps = hold_base_rate_steps
# 是否在每次训练结束大于学习率
self.verbose = verbose
# 记录所有批次的学习率
self.learning_rates = []
def on_batch_end(self, batch, logs=None):
# 记录当前训练到走到第几步数
self.global_step = self.global_step + 1
# 记录下所有每次的学习到列表,要统计画图可以使用
lr = K.get_value(self.model.optimizer.lr)
self.learning_rates.append(lr)
def on_batch_begin(self, batch, logs=None):
# 计算这批次开始的学习率 lr
lr = cosine_decay_with_warmup(global_step=self.global_step,
learning_rate_base=self.learning_rate_base,
total_steps=self.total_steps,
warmup_learning_rate=self.warmup_learning_rate,
warmup_steps=self.warmup_steps,
hold_base_rate_steps=self.hold_base_rate_steps)
# 设置模型的学习率为lr
K.set_value(self.model.optimizer.lr, lr)
if self.verbose > 0:
print('\n批次数 %05d: 设置学习率为'
' %s.' % (self.global_step + 1, lr))
模型训练
import multiprocessing
import numpy as np
import argparse
import tensorflow as tf
from tensorflow.keras.callbacks import TensorBoard, Callback
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam, RMSprop
from efficientnet import model as EfficientNet
from data_gen import data_from_sequence
from utils.lr_scheduler import WarmUpCosineDecayScheduler
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
# 注意关闭默认的eager模式
tf.compat.v1.disable_eager_execution()
parser = argparse.ArgumentParser()
parser.add_argument("data_url", type=str, default='./data/garbage_classify/train_data', help="data dir", nargs='?')
parser.add_argument("train_url", type=str, default='./garbage_ckpt/', help="save model dir", nargs='?')
parser.add_argument("num_classes", type=int, default=40, help="num_classes", nargs='?')
parser.add_argument("input_size", type=int, default=300, help="input_size", nargs='?')
# parser.add_argument("batch_size", type=int, default=16, help="batch_size", nargs='?')
parser.add_argument("batch_size", type=int, default=64, help="batch_size", nargs='?')
parser.add_argument("learning_rate", type=float, default=0.001, help="learning_rate", nargs='?')
parser.add_argument("max_epochs", type=int, default=3, help="max_epochs", nargs='?')
parser.add_argument("deploy_script_path", type=str, default='', help="deploy_script_path", nargs='?')
parser.add_argument("test_data_url", type=str, default='', help="test_data_url", nargs='?')
def model_fn(param):
"""修改符合垃圾分类的模型
:param param: 命令行参数
:return:
"""
base_model = EfficientNet.EfficientNetB3(include_top=False,
input_shape=(param.input_size, param.input_size, 3),
classes=param.num_classes)
x = base_model.output
# 自定义修改40个分类的后面基层
x = GlobalAveragePooling2D(name='avg_pool')(x)
predictions = Dense(param.num_classes, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
return model
def train_model(param):
"""训练模型逻辑
:param param: 各种参数命令行
:return:
"""
# 1、读取sequence数据
train_sequence, validation_sequence = data_from_sequence(param.data_url, param.batch_size, param.num_classes, param.input_size)
# 2、建立模型,修改模型指定训练相关参数
model = model_fn(param)
optimizer = Adam(lr=param.learning_rate)
objective = 'categorical_crossentropy'
metrics = ['acc']
# 模型修改
# 模型训练优化器指定
model.compile(loss=objective, optimizer=optimizer, metrics=metrics)
model.summary()
# 3、指定相关回调函数
# Tensorboard
tensorboard = tf.keras.callbacks.TensorBoard(log_dir='./graph', histogram_freq=1, write_graph=True, write_images=True)
# modelcheckpoint
# (3)模型保存相关参数
check = tf.keras.callbacks.ModelCheckpoint(param.train_url + 'weights_{epoch:02d}-{val_acc:.2f}.h5',
monitor='val_acc',
save_best_only=True,
save_weights_only=False,
mode='auto',
period=1)
# 余弦退回warmup
# 得到总样本数
# sample_count = len(train_sequence)* param.batch_size
sample_count = len(train_sequence)
batch_size = param.batch_size
# 第二阶段学习率以及总步数
learning_rate_base = param.learning_rate
total_steps = int(param.max_epochs * sample_count) / batch_size
# 计算第一阶段的步数需要多少 warmup_steps
warmup_epoch = 1
warmup_steps = int(warmup_epoch * sample_count) / batch_size
warm_lr = WarmUpCosineDecayScheduler(learning_rate_base=learning_rate_base,
total_steps=total_steps,
warmup_learning_rate=0,
warmup_steps=warmup_steps,
hold_base_rate_steps=0,)
# 4、训练步骤
model.fit_generator(
train_sequence,
steps_per_epoch=int(sample_count / batch_size), # 一个epoch需要多少步 , 1epoch sample_out 140000多样本, 140000 / 16 = 步数
epochs=param.max_epochs,
verbose=1,
callbacks=[check, tensorboard, warm_lr],
validation_data=validation_sequence,
max_queue_size=10,
workers=int(multiprocessing.cpu_count() * 0.7),
use_multiprocessing=True,
shuffle=True
)
return None
if __name__ == '__main__':
args = parser.parse_args()
train_model(args)
模型导出与部署
TensorFlow 模型导出



案例

自定义的keras模型


TensorFlow Serving


安装
docker 安装
docker pull tensorflow/serving
运行
docker run -p 8501:8501 - p 8500:8500 --mount type=bind,source=/home/ubuntu/detectedmodel/commodity,target=/models/commodity -t tensorflow/serving

客户端调用以TensorFlow Serving部署的模型

 直接使用
直接使用

客户端代码


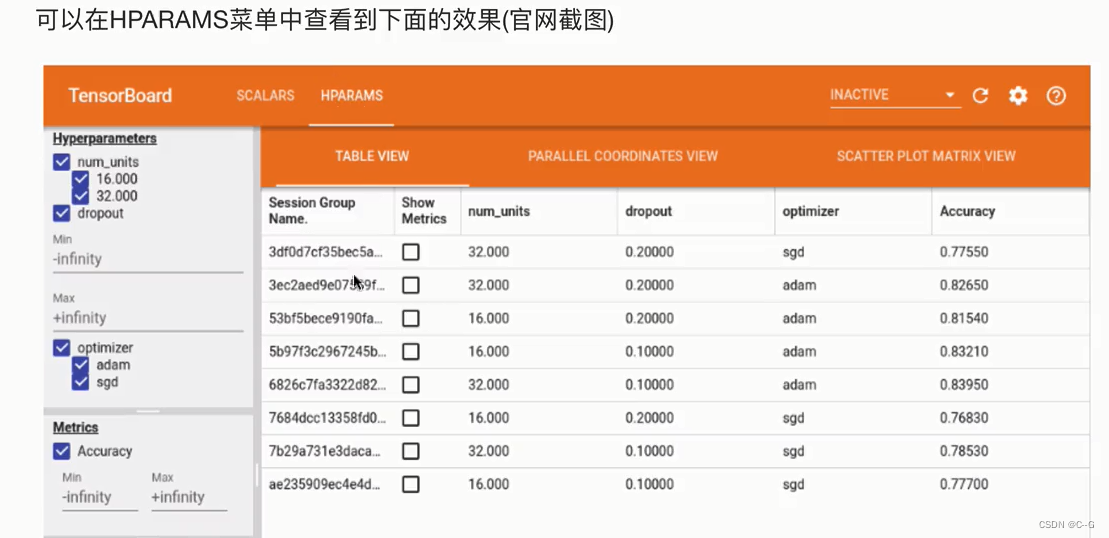
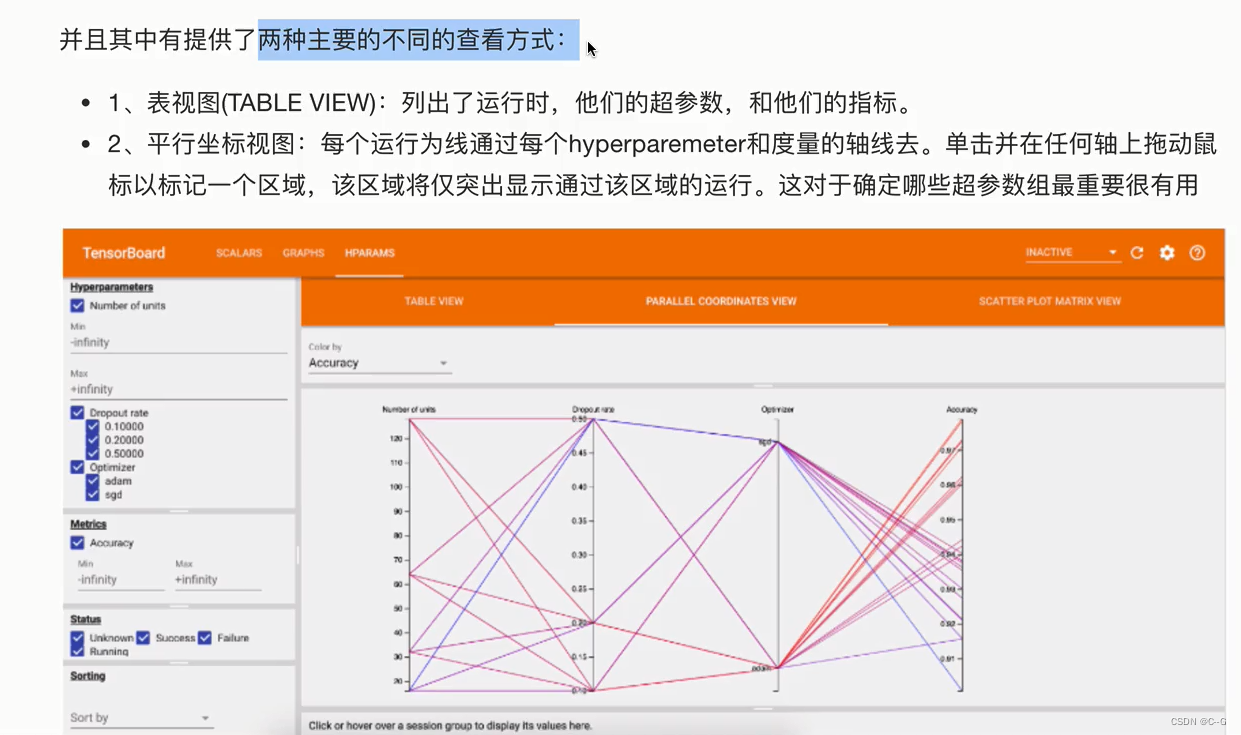
HParams-超参数调优

案例:FCIFAR100分类模型添加参数调优






















 6746
6746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









