







简介

自然语言入门
文本预处理
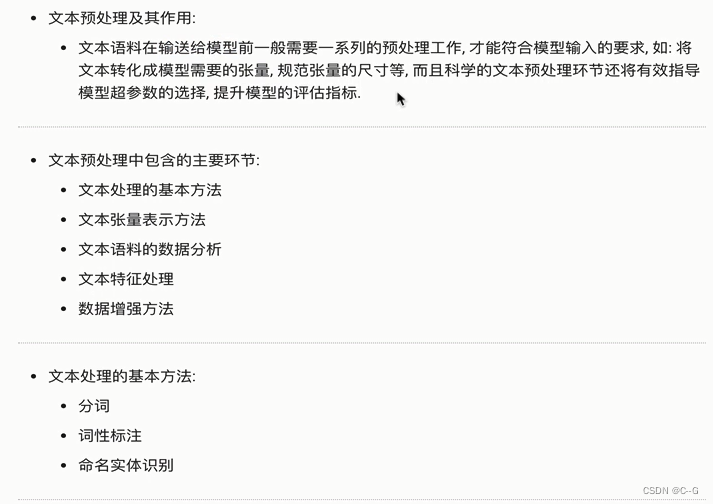


文本处理的基本方法
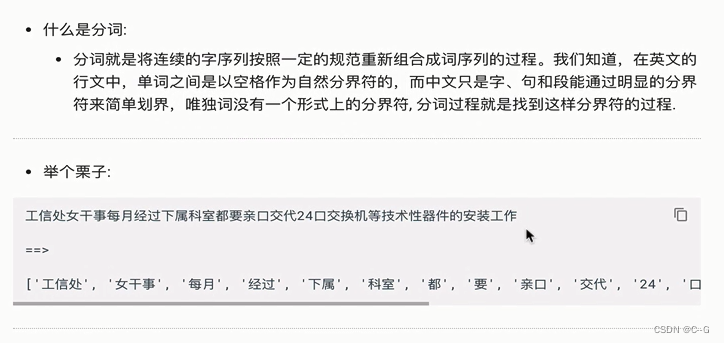


jieba分词
安装
pip install jieba
使用
- 精确模式分词
视图将句子最精确地切开,适合文本分析
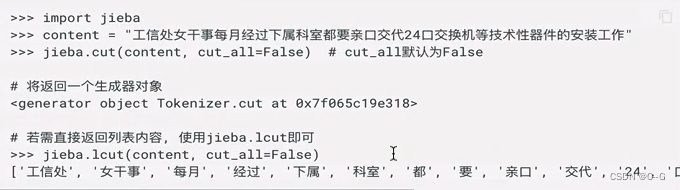
- 全模式分词
把句子中所有的可以成词的词语读扫描出来,速度非常快,但是不能消除歧义

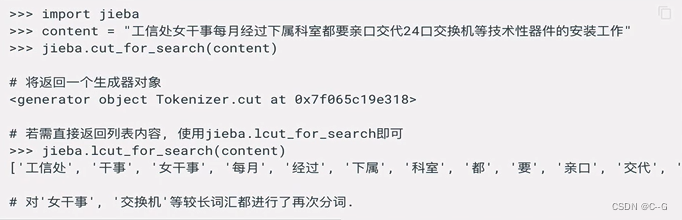
- 搜索引擎模式
在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
- 中文繁体分词
针对中国香港,台湾地区的繁体文本进行分词

- 使用用户自定义词典


流行中英文分词工具hanlp
中英文NLP处理工具包,基于tensorflow2.0,使用在学术界和行业中推广最先进的深度学习技术
安装
pip install hanlp
-
中文分词

-
英文分词


-
hanlp进行中文命名实体识别

-
hanlp进行英文命名实体识别

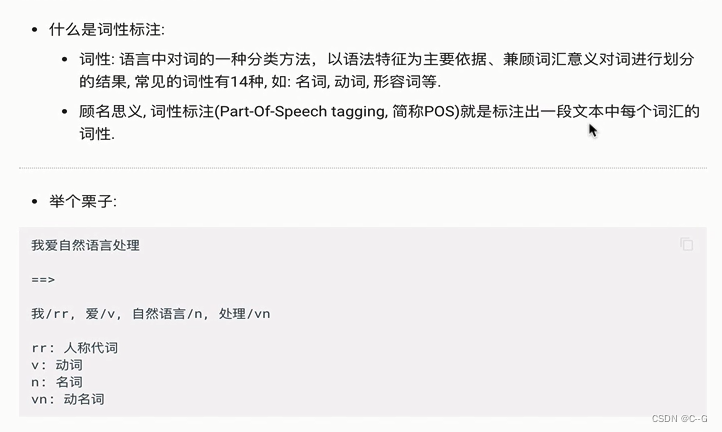

-
使用jieba进行中文词性标注

-
使用hanlp进行中文词性标注

-
使用hanlp进行英文词性标注

文本张量表示方法
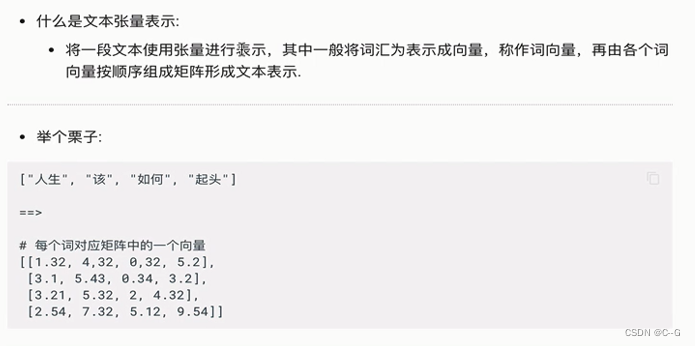

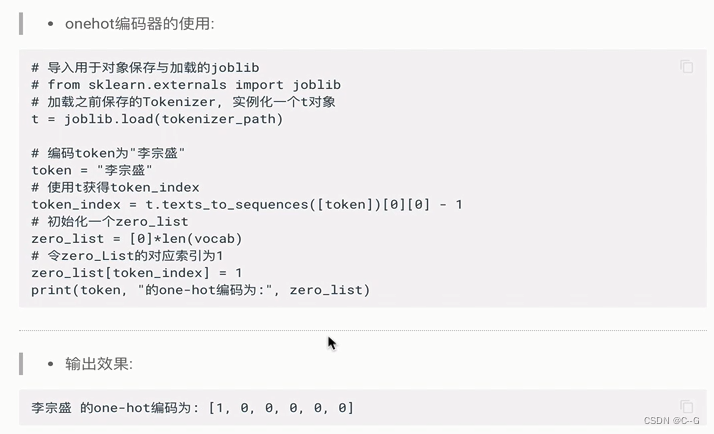
one-hot





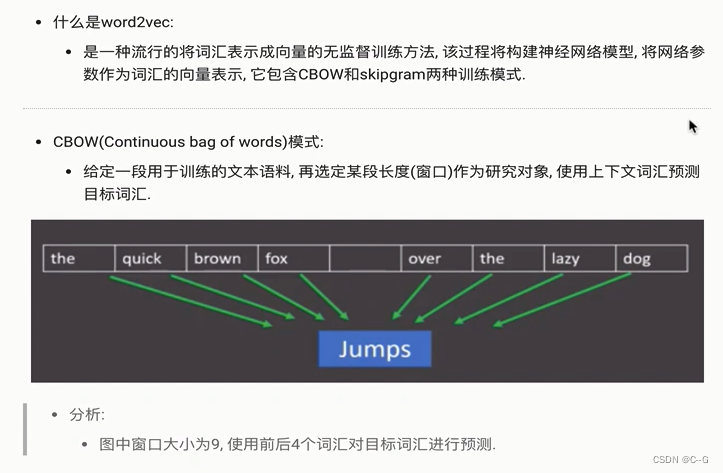
word2vec
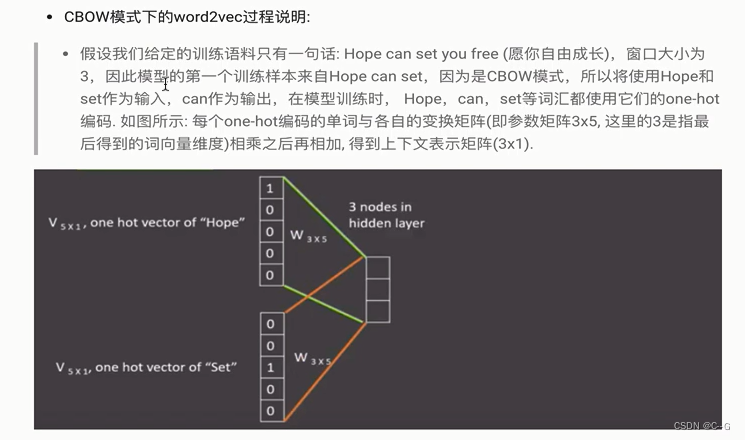
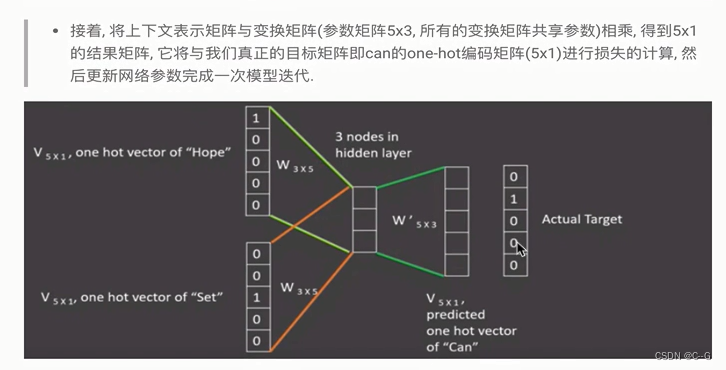

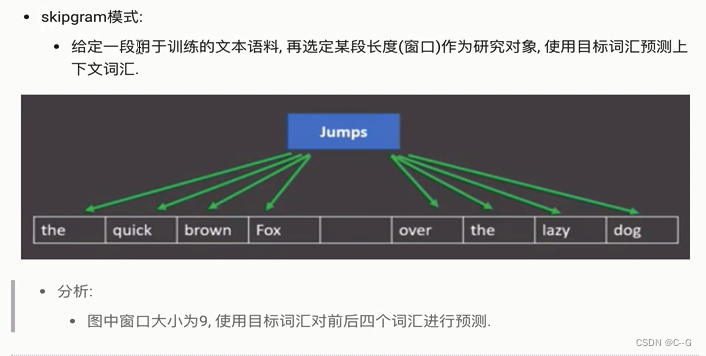
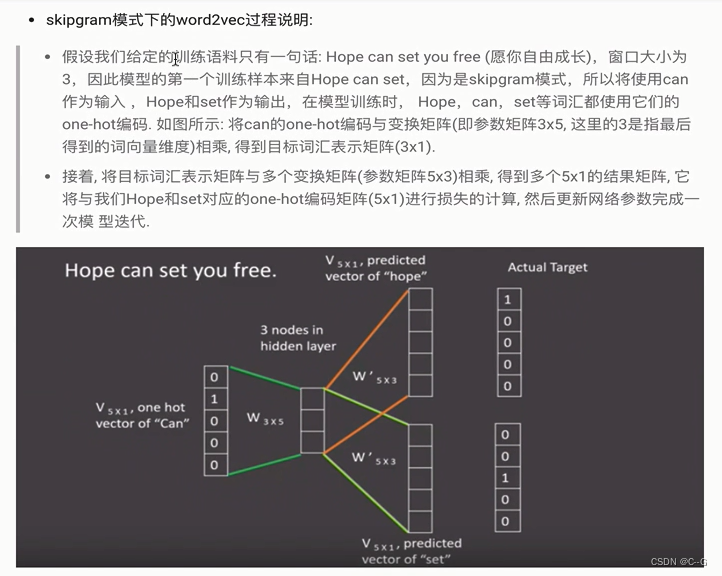
使用fasttext工具实习word2vec的训练和使用
- 数据准备
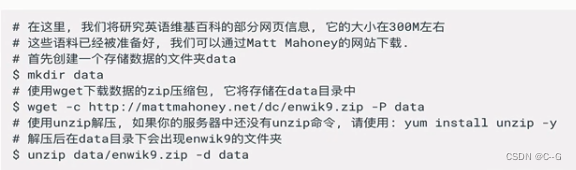
- 数据处理


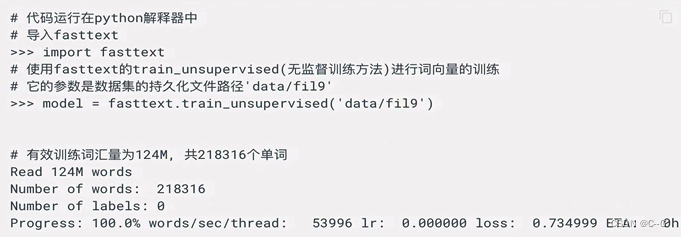
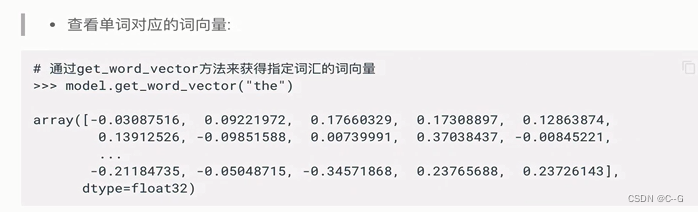
- 训练词向量
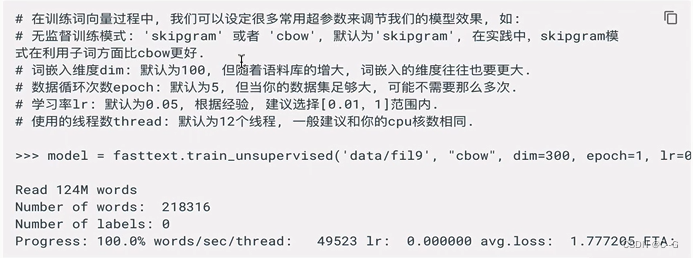
- 模型超参数设定
- 模型效果检验

- 模型的保存与重加载

文本数据分析

标签数量分布


在这里插入图片描述
句子长度分布








不同词汇总数统计


高频形容词词云






文本特征处理

n-gram特征




文本长度规范



文本数据增强



附
jieba词性对照表


hanlp词性对照表


案例:新闻主题分类任务

# 导入相关torch工具包
import torch
import torchtext
# 导入torchtext.datasets中的文本分类任务
from torchtext.datasets import text_classification
import os
load_data_path = "./data"
if not os.path.isdir(load_data_path):
os.mkdir(load_data_path)
# 选取torchtext中的文本分类数据集‘AG_NEWS’即新闻主题分类数据,保存在指定目录下
# 并将数值映射后的训练和验证数据加载到内存中
train_dataset,test_dataset = text_classification.DATASETS['AG_NEWS'](root=load_data_path)


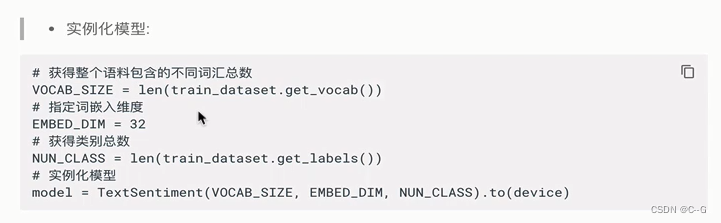
构建带有Embedding层的文本分类模型



对数据进行batch处理


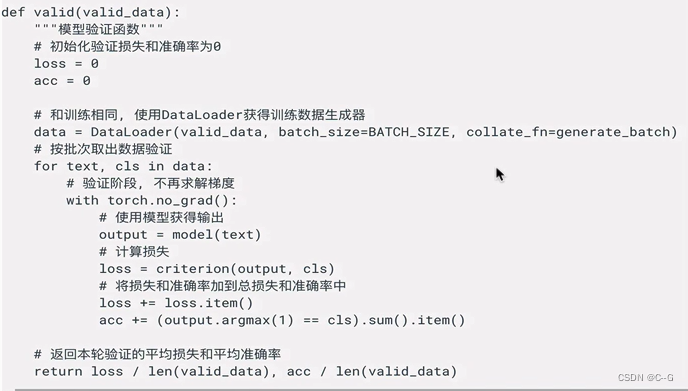
构建训练与验证函数


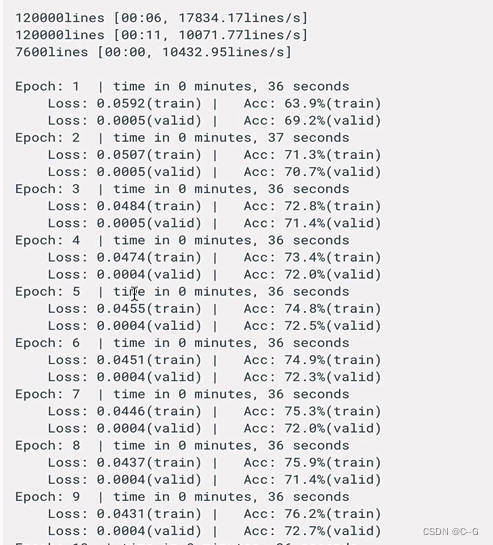
进行模型训练和验证


经典序列模型——HMM与CRF
HMM



CRF


















 5593
5593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









