







归一化深度图约束nerf未归一化深度重建
class ScaleAndShiftInvariantLoss(nn.Module):
"""
Scale and shift invariant loss as described in
"Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer"
https://arxiv.org/pdf/1907.01341.pdf
"""
def __init__(self, alpha: float = 0.5, scales: int = 4, reduction_type: Literal["image", "batch"] = "batch"):
"""
Args:
alpha: weight of the regularization term
scales: number of scales to use
reduction_type: either "batch" or "image"
"""
super().__init__()
self.__data_loss = MiDaSMSELoss(reduction_type=reduction_type)
self.__regularization_loss = GradientLoss(scales=scales, reduction_type=reduction_type)
self.__alpha = alpha
self.__prediction_ssi = None
def forward(
self,
prediction: Float[Tensor, "1 32 mult"],
target: Float[Tensor, "1 32 mult"],
mask: Bool[Tensor, "1 32 mult"],
) -> Float[Tensor, "0"]:
"""
Args:
prediction: predicted depth map (unnormalized)
target: ground truth depth map (normalized)
mask: mask of valid pixels
Returns:
scale and shift invariant loss
"""
scale, shift = normalized_depth_scale_and_shift(prediction, target, mask)
self.__prediction_ssi = scale.view(-1, 1, 1) * prediction + shift.view(-1, 1, 1)
total = self.__data_loss(self.__prediction_ssi, target, mask)
if self.__alpha > 0:
total += self.__alpha * self.__regularization_loss(self.__prediction_ssi, target, mask)
return total
def __get_prediction_ssi(self):
"""
scale and shift invariant prediction
from https://arxiv.org/pdf/1907.01341.pdf equation 1
"""
return self.__prediction_ssi
prediction_ssi = property(__get_prediction_ssi)
scale,shift计算公式
出自MonoSDF


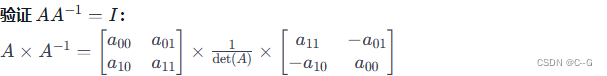

def normalized_depth_scale_and_shift(
prediction: Float[Tensor, "1 32 mult"], target: Float[Tensor, "1 32 mult"], mask: Bool[Tensor, "1 32 mult"]
):
"""
More info here: https://arxiv.org/pdf/2206.00665.pdf supplementary section A2 Depth Consistency Loss
This function computes scale/shift required to normalizes predicted depth map,
to allow for using normalized depth maps as input from monocular depth estimation networks.
These networks are trained such that they predict normalized depth maps.
Solves for scale/shift using a least squares approach with a closed form solution:
Based on:
https://github.com/autonomousvision/monosdf/blob/d9619e948bf3d85c6adec1a643f679e2e8e84d4b/code/model/loss.py#L7
Args:
prediction: predicted depth map
target: ground truth depth map
mask: mask of valid pixels
Returns:
scale and shift for depth prediction
"""
# system matrix: A = [[a_00, a_01], [a_10, a_11]]
a_00 = torch.sum(mask * prediction * prediction, (1, 2))
a_01 = torch.sum(mask * prediction, (1, 2))
a_11 = torch.sum(mask, (1, 2))
# right hand side: b = [b_0, b_1]
b_0 = torch.sum(mask * prediction * target, (1, 2))
b_1 = torch.sum(mask * target, (1, 2))
# solution: x = A^-1 . b = [[a_11, -a_01], [-a_10, a_00]] / (a_00 * a_11 - a_01 * a_10) . b
scale = torch.zeros_like(b_0)
shift = torch.zeros_like(b_1)
det = a_00 * a_11 - a_01 * a_01
valid = det.nonzero()
scale[valid] = (a_11[valid] * b_0[valid] - a_01[valid] * b_1[valid]) / det[valid]
shift[valid] = (-a_01[valid] * b_0[valid] + a_00[valid] * b_1[valid]) / det[valid]
return scale, shift
MiDaSMSELoss
class MiDaSMSELoss(nn.Module):
"""
data term from MiDaS paper
"""
def __init__(self, reduction_type: Literal["image", "batch"] = "batch"):
super().__init__()
self.reduction_type: Literal["image", "batch"] = reduction_type
# reduction here is different from the image/batch-based reduction. This is either "mean" or "sum"
self.mse_loss = MSELoss(reduction="none")
def forward(
self,
prediction: Float[Tensor, "1 32 mult"],
target: Float[Tensor, "1 32 mult"],
mask: Bool[Tensor, "1 32 mult"],
) -> Float[Tensor, "0"]:
"""
Args:
prediction: predicted depth map
target: ground truth depth map
mask: mask of valid pixels
Returns:
mse loss based on reduction function
"""
summed_mask = torch.sum(mask, (1, 2))
image_loss = torch.sum(self.mse_loss(prediction, target) * mask, (1, 2))
# multiply by 2 magic number?
image_loss = masked_reduction(image_loss, 2 * summed_mask, self.reduction_type)
return image_loss
GradientLoss
出自于:https://arxiv.org/pdf/1907.01341.pdf
# losses based on https://github.com/autonomousvision/monosdf/blob/main/code/model/loss.py
class GradientLoss(nn.Module):
"""
multiscale, scale-invariant gradient matching term to the disparity space.
This term biases discontinuities to be sharp and to coincide with discontinuities in the ground truth
More info here https://arxiv.org/pdf/1907.01341.pdf Equation 11
"""
def __init__(self, scales: int = 4, reduction_type: Literal["image", "batch"] = "batch"):
"""
Args:
scales: number of scales to use
reduction_type: either "batch" or "image"
"""
super().__init__()
self.reduction_type: Literal["image", "batch"] = reduction_type
self.__scales = scales
def forward(
self,
prediction: Float[Tensor, "1 32 mult"],
target: Float[Tensor, "1 32 mult"],
mask: Bool[Tensor, "1 32 mult"],
) -> Float[Tensor, "0"]:
"""
Args:
prediction: predicted depth map
target: ground truth depth map
mask: mask of valid pixels
Returns:
gradient loss based on reduction function
"""
assert self.__scales >= 1
total = 0.0
for scale in range(self.__scales):
step = pow(2, scale)
grad_loss = self.gradient_loss(
prediction[:, ::step, ::step],
target[:, ::step, ::step],
mask[:, ::step, ::step],
)
total += grad_loss
assert isinstance(total, Tensor)
return total
def gradient_loss(
self,
prediction: Float[Tensor, "1 32 mult"],
target: Float[Tensor, "1 32 mult"],
mask: Bool[Tensor, "1 32 mult"],
) -> Float[Tensor, "0"]:
"""
multiscale, scale-invariant gradient matching term to the disparity space.
This term biases discontinuities to be sharp and to coincide with discontinuities in the ground truth
More info here https://arxiv.org/pdf/1907.01341.pdf Equation 11
Args:
prediction: predicted depth map
target: ground truth depth map
reduction: reduction function, either reduction_batch_based or reduction_image_based
Returns:
gradient loss based on reduction function
"""
summed_mask = torch.sum(mask, (1, 2))
diff = prediction - target
diff = torch.mul(mask, diff)
grad_x = torch.abs(diff[:, :, 1:] - diff[:, :, :-1])
mask_x = torch.mul(mask[:, :, 1:], mask[:, :, :-1])
grad_x = torch.mul(mask_x, grad_x)
grad_y = torch.abs(diff[:, 1:, :] - diff[:, :-1, :])
mask_y = torch.mul(mask[:, 1:, :], mask[:, :-1, :])
grad_y = torch.mul(mask_y, grad_y)
image_loss = torch.sum(grad_x, (1, 2)) + torch.sum(grad_y, (1, 2))
image_loss = masked_reduction(image_loss, summed_mask, self.reduction_type)
return image_loss
self.depth_loss = ScaleAndShiftInvariantLoss(alpha=0.5, scales=1)
masked_reduction
def masked_reduction(
input_tensor: Float[Tensor, "1 32 mult"],
mask: Bool[Tensor, "1 32 mult"],
reduction_type: Literal["image", "batch"],
) -> Tensor:
"""
Whether to consolidate the input_tensor across the batch or across the image
Args:
input_tensor: input tensor
mask: mask tensor
reduction_type: either "batch" or "image"
Returns:
input_tensor: reduced input_tensor
"""
if reduction_type == "batch":
# avoid division by 0 (if sum(M) = sum(sum(mask)) = 0: sum(image_loss) = 0)
divisor = torch.sum(mask)
if divisor == 0:
return torch.tensor(0, device=input_tensor.device)
input_tensor = torch.sum(input_tensor) / divisor
elif reduction_type == "image":
# avoid division by 0 (if M = sum(mask) = 0: image_loss = 0)
valid = mask.nonzero()
input_tensor[valid] = input_tensor[valid] / mask[valid]
input_tensor = torch.mean(input_tensor)
return input_tensor














 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









