







Improving Fake News Detection by Using an Entity-enhanced Framework to Fuse Diverse Multimodal Clues
Motivation
作者认为:
- 大部分工作只是单独的抽取图像特征,并没有尝试其它的方式去挖掘图像的高层语义信息
- 新闻文本中的实体应和图片中的实体信息基本一致
- 图片中的嵌入文本可以作为原始文本的补充
Method
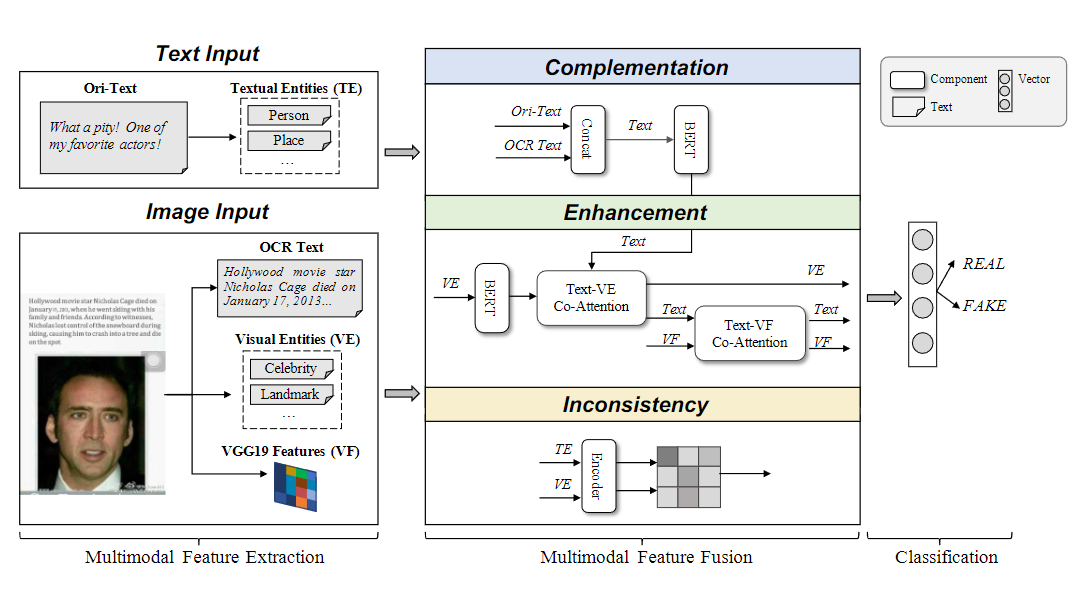
模型的主要架构包括了:
- 编码器(文本、视觉)
- 实体识别模块(文本、图像):采用百度api,或者开源软件
- 模态互补融合
- 实体一致性
- 分类头
编码器
文本使用Bert,视觉采用VGG-19
实体识别模块
采用百度api,以及github开源软件,根据不同语言选择对应可使用的
模态互补融合
具体使用两轮协同注意力操作:
- 第一轮,将文本与视觉实体进行一次协同注意力,输出 x v e 、 x t 1 x_{ve}、x_{t1} xve、xt1
- 再将第一轮输出的文本特 x t 1 x_{t1} xt1与视觉特征做一次协同注意力输出 x v 、 x t 2 x_v、x_{t2} xv、xt2
- 对 x v e 、 x v 、 x t 2 x_{ve}、x_v、x_{t2} xve、xv、xt2进行平均操作,作为最后的特征表示 x v e ′ 、 x v ′ 、 x t 2 ′ x^{'}_{ve}、x^{'}_{v}、x^{'}_{t2} xve′、xv′、xt2′
实体一致性
将实体进行编码后,将不同模态间同种类的实体进行相似性计算,取最大值。p(v)为目标检测时输出该实体的在概率分布中的值。
若某类实体不存在,则取相似度为1,代表这个实体没有发作用。
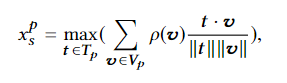
最后将每一类的相似性结果concat得到 x s x_s xs
分类头
将 x v e ′ 、 x v ′ 、 x t 2 ′ 、 x s x^{'}_{ve}、x^{'}_{v}、x^{'}_{t2}、x_s xve′、xv′、xt2′、xs concat送入全连接层进行分类。
Result
总的结果
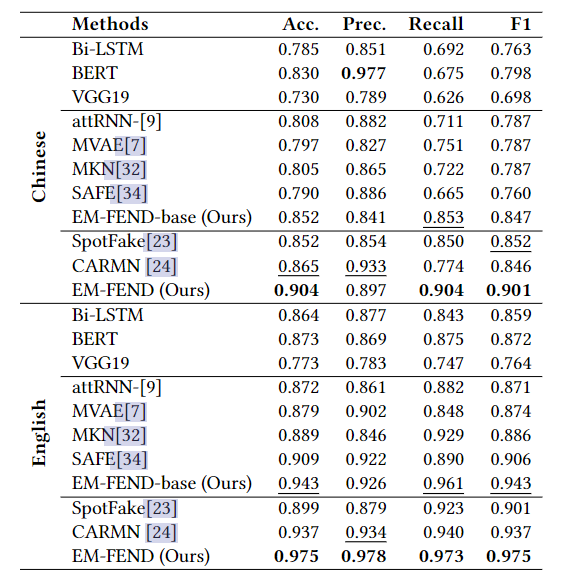
中文数据集:Weibo2017
英文数据集:另一个不常见的
消融实验
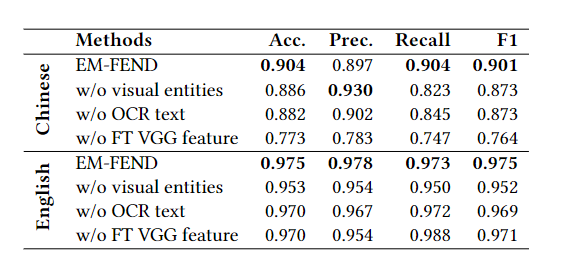
作者发现:
- 在weibo数据集上,vgg抽取的特征很重要,因为weibo图片的质量比较差(模糊),一些低层次的特征就能表现很好
- 在英文的这个数据集上,由于来自的平台图片质量比较高,vgg抽取的特征可能帮助不大,反而是实体级的语义特征能够对结果有帮助。
















 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









