







Reference:
如何从RNN起步,一步一步通俗理解LSTM_v_JULY_v的博客-CSDN博客_lstm结构
LSTM - 长短期记忆递归神经网络 - 知乎 (zhihu.com)
LSTM是一个应用非常广泛的深度学习模型,其不仅对时序数据处理有着不错的效果,在NLP中也有很优秀的表现。本人也在逐步的学习当中,所以先将所了解的一点基础知识在此做一个汇总和总结,与各位分享学习,借此共勉。
1、RNN
在学习LSTM之前,我们需要了解什么是RNN,NN很明显是神经网络的意思,而R代表循环。如果我们之前有两结果多层感知器或者BP神经网络之类的,我们就会知道神经网络结构是一个单向的,先由输入层输入数据计算传递给隐含层,再由隐含层计算传递给下一个隐含层,最后传递给输出层输出结果,是一个单项进行的网络结果。
就上述经典的神经网络结构来说,处理序列数据问题(数据之间存在着依赖)就有些不太方便,而RNN的出发点就是引入一个隐含单元来表达之前数据的信息,我们称其为状态。通过这个状态我们就可以在本时刻计算时同时也顾及之前的信息。
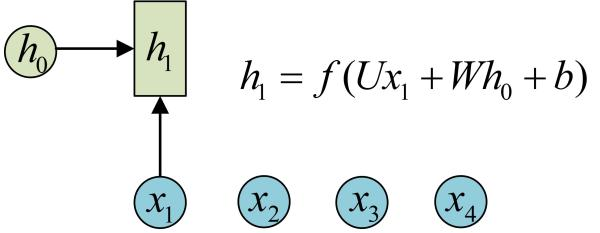
如上图(源于Reference,下同)所示,h0为状态初值,第一个时刻输出数据为x1,那们其对应的状态就为h1,如此类推如下,输出值y是关于当前时刻状态值h的函数。
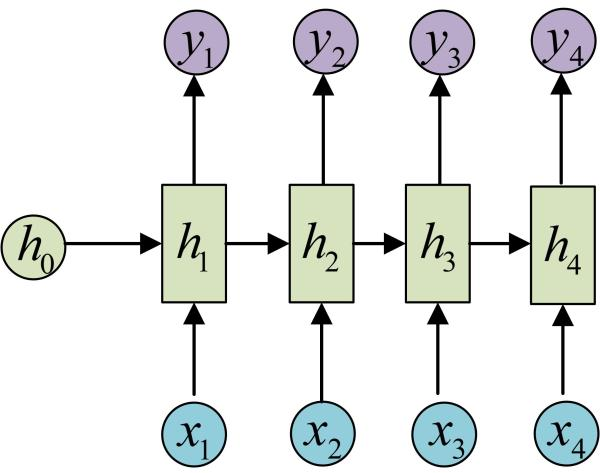
需要注意的是,在每一个时刻的时候,所使用的参数U、W、b都是相同的。所以RNN就可以表现为如下的循环模式。(此处用h表示网络的输出,用A来表示神经网络的结构,用x来代表输入)

现在我们再回过头来看RNN的数学原理和模型结构,我们发现RNN对每次输出信息的处理都是一样的(因为是相同的U、W、b参数)。换句话说,它对我们每次的输入信息的保存方法都是相同的,那也就无所谓重要与否。
那会存在什么问题呢?在序列数据的处理中,肯定会依赖于当前时刻之前的数据来进行处理,但是也不是所有的之前的信息都需要保存,也就是说,如果对每个时刻的信息都使用相同的处理方法,那其实所保存的信息并非都是有用的,当序列变得很长时,该算法模型就会表现欠优。那么我们就希望在保存状态机制同时引入一个机制,将输入的信息选择性的保存下来,并同时遗忘一些东西。也就是将要介绍的LSTM模型。
2、LSTM
LSTM长短期记忆神经网络是在循环神经网络RNN的基础上,通过改进其信息的保存机制,增加遗忘门和细胞状态等方法来保存那些有用的信息并舍弃那些没用的信息,从而使得LSTM能够处理更长序列的数据。LSTM的模型结构主要如下图:
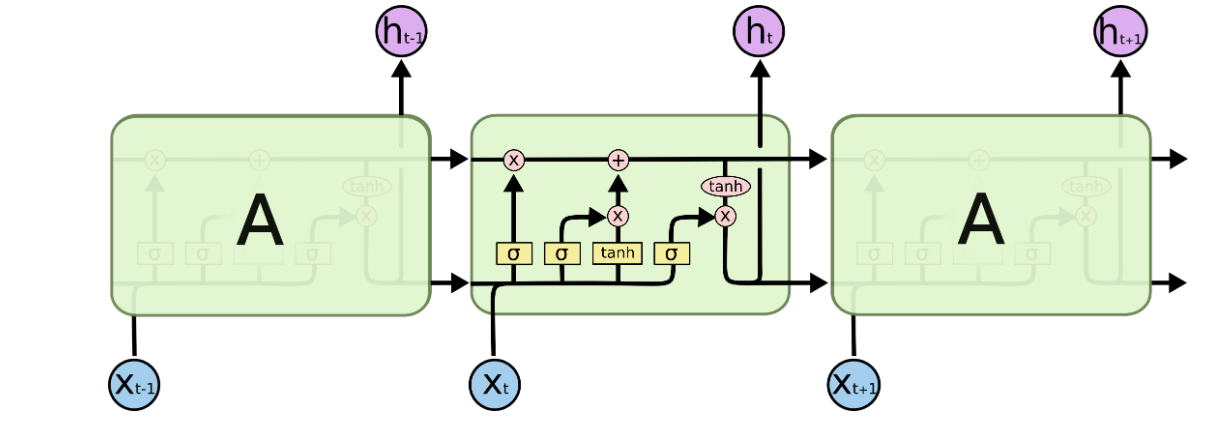
其内部看起来结构很复杂,其实是由几个功能单元组合而成,一般将这些功能单元称为门,主要分为输入门、输出门、遗忘门、细胞状态的更新。下文将一一介绍。
2.1 遗忘门
遗忘门的主要功能是指在这一个时刻需要遗忘上一个细胞状态值C中的什么东西,由输入x决定。其结构如下图所示。
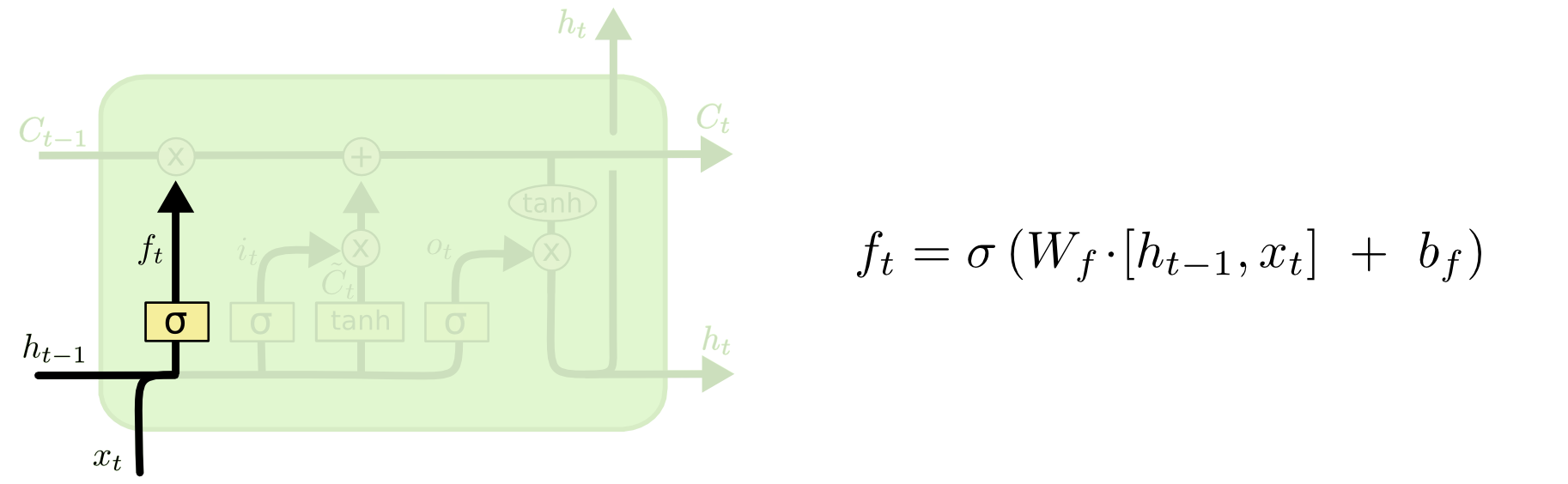
上式中:W为参数矩阵,h(t-1)是上一个状态的输出值,x(t)是当前状态的输入,b是偏执参数。我个人把计算获得的结果理解为遗忘门算子,将上个细胞状态C来乘以这个遗忘门算子就是遗忘后细胞状态。
2.2 输入门
细胞状态时贯穿整模型始终的,它需要不断的忘记无关紧要的信息,记住重要的信息。所以输入也是很重要的。我们通过输入值x来确定需要在细胞状态中更新什么东西,输入门的结果如下图所示。
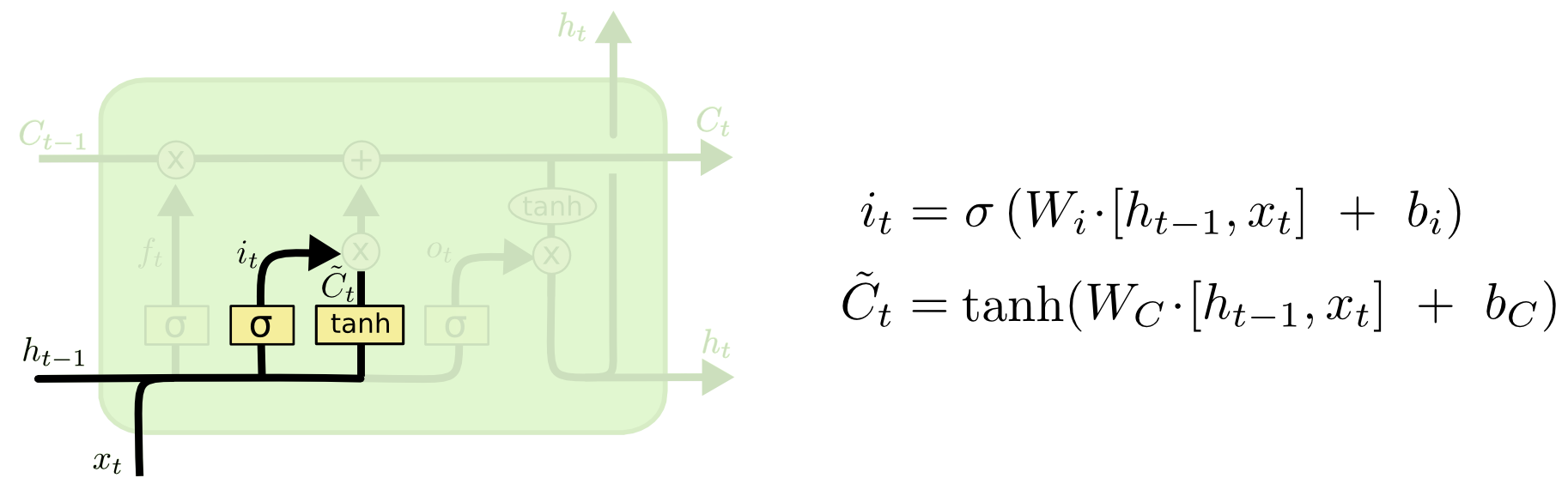
上式中:W(i) W(c)为参数矩阵,h(t-1)为上个状态的输出值,x(t)为本状态的输入值,b(i) b(c)均为偏执参数。由输入们我们就可以确定那需要更新的状态。
2.3 细胞状态的更新
在进行了遗忘门和输入门的处理之后,我们现在能将上个时刻的细胞状态进行更新,遗忘那些不重要的并添加那些重要的信息,以此获得本时刻的细胞状态。
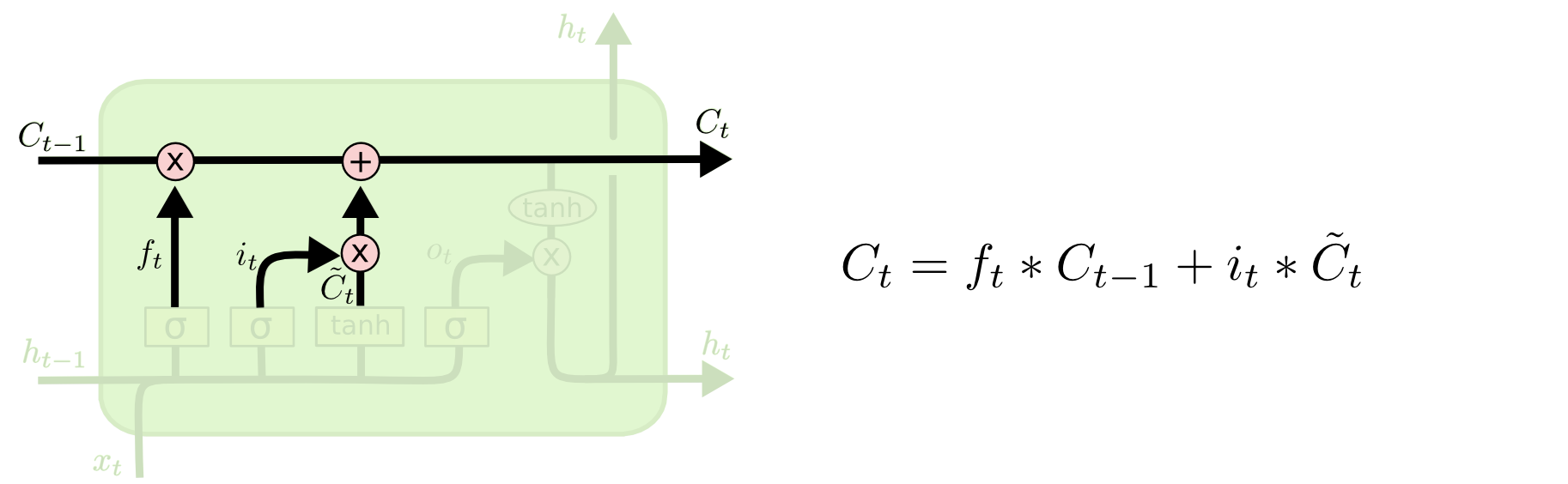
就上文而言,可知,f(t) * C(t-1) 是对状态的遗忘,i(t) * C'(t) 是对状态的更新。对上一个细胞状态进行遗忘和更新也就获得了这个时刻的状态值。
2.4 输出门
模型每个时刻的输出值是基于当前时刻的细胞状态的
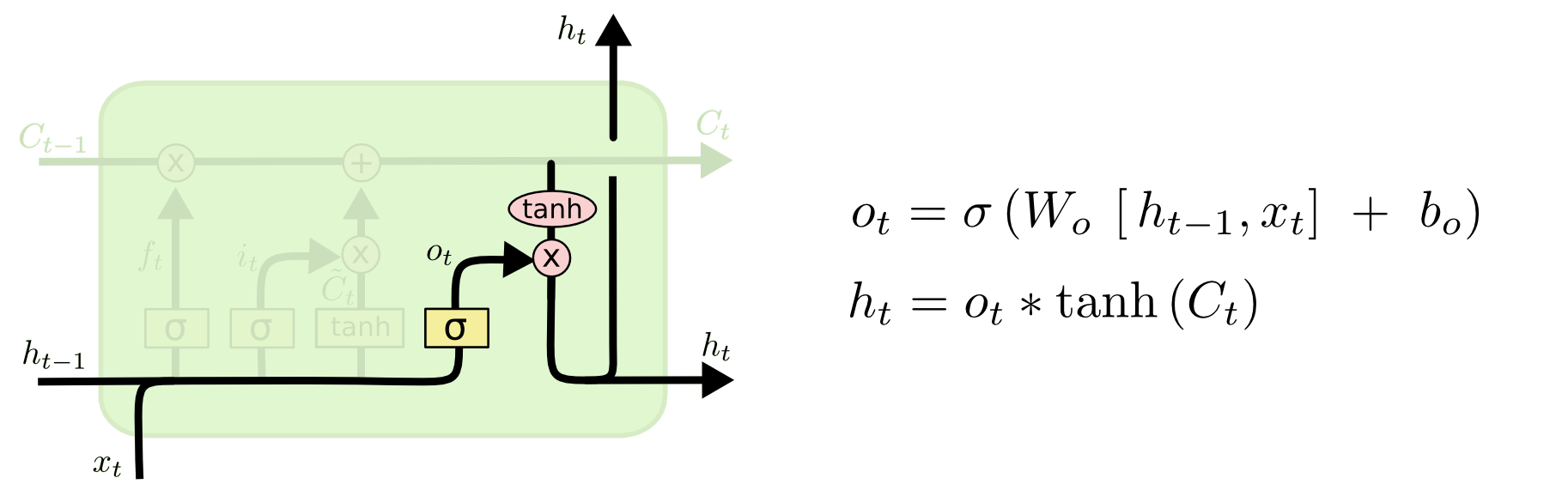
上式便给出了基于输入值和当前细胞状态实现对模型的输出,h(t)即为输出。
2.5 训练方法
1)训练集组织方法:
自然语言处理(NLP)我不太了解,以单一时序数据处理为例
假设有时序数据:x(1)、x(2)、x(3)、........ x(n)
首先确定窗口长度M:假设为5。
那么就可以组件如下的数据集
输入集 | 标签 |
x(1),x(2),x(3),x(4),x(5) | x(6) |
x(2),x(3),x(4),x(5),x(6) | x(7) |
x(3),x(4),x(5),x(6),x(7) | x(8) |
... | ... |
x(n-5),x(n-4),x(n-3),x(n-2),x(n-1) | x(n) |
2)误差下降方法,其中的参数均可采用梯度下降的方法进行迭代更新,其中还有很多如何预防梯度消失或梯度爆炸的知识点本人也还没深入学习,此处就不介绍了。
3、结语
针对RNN的模型的弊端,LSTM引入了细胞状态的更新机制,基于输入数据来对细胞状态进行遗忘和更新,使得LSTM网络能够更准确的处理长时间的序列数据。
以上
有任何问题欢迎邮件:2264787072@qq.com(QQ同)
才疏学浅,拙作难免有误,望各位读者不吝赐教,以此共勉















 1231
1231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









