







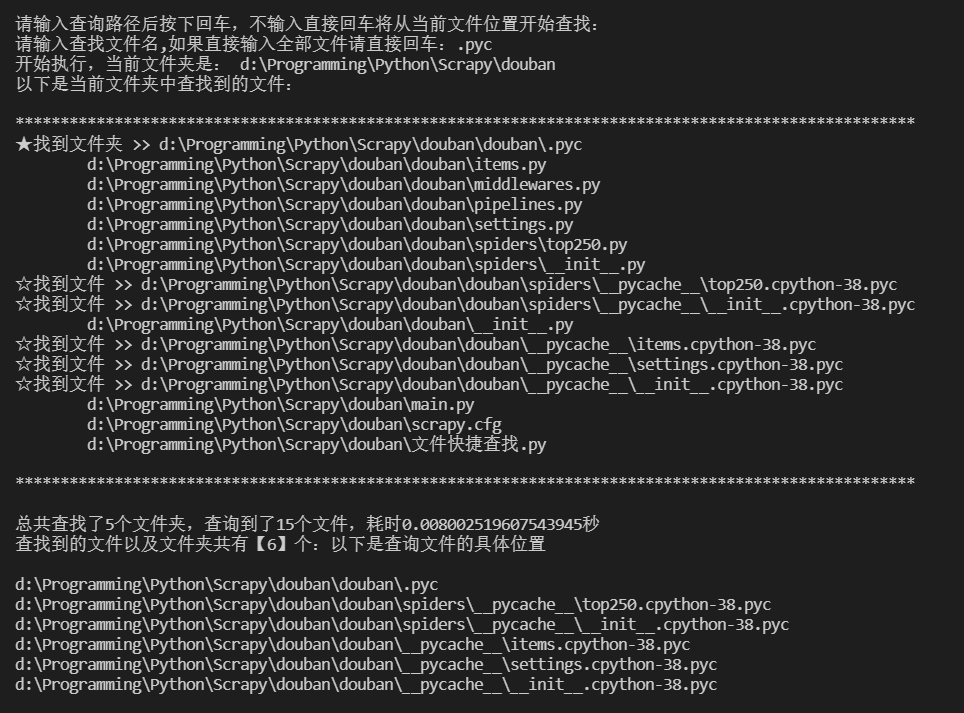
🍗先看运行效果
🍔 具体思路
🍟 一、主要使用的模块以及方法
模块:python 自带的 os 以及 time 模块,time模块没发挥太多作用
方法:
- os.path.isdir() #判断路径文件是否是文件夹,是返回True,反之False
- os.path.isfile() #判断路径文件是否是文件,是返回True,反之False
- os.path.abspath() # 得到一个当前传入路径的绝对路径
- os.path.dirname() # 传入 file 获取当前文件所在路径的父级目录
- os.listdir() # 传入一个目录,得到该目录下的子级文件或文件名的列表,不含父级目录
- time.time() # 获取到当前时间戳
- str.index() #内置字符串查找方法,当传入的值中在str中时得到传入值得下标,如果没有则抛出异常值: ValueError
🌭 二、主要思路以及代码
🍿 1、开始位置
这里主要是通过输入需要查找父级文件夹和需要查找得文件进行判断已经定义一些下面需要使用的变量
user_route = input('\n请输入查询路径后按下回车,不输入直接回车将从当前文件位置开始查找:')
user_file = input('请输入查找文件名,如果直接输入全部文件请直接回车:')
father_route = os.path.abspath(user_route)
find_file_list = []
find_file_name = '★ 找到文件 >> '
find_dir_name = '☆ 找到文件夹 >> '
# 如果不输入路径就重新用给父级路径赋值,赋值内容为当前文件所在位置
if user_route == '':
father_route = os.path.dirname(__file__)
# 如果不输入查找文件名,则直接将两个找到的文件的给予的变量赋值为空
father_bool = os.path.isdir(father_route)
if not father_bool:
print('你的路径有问题,请重新输入')
continue
start_time = time.time()
total_file = 0 #初始化总文件变量
total_dir = 0 #初始化总文件夹变量
🧂 2、关键位置
下面是主要执行文件查找得递归函数,主要的思路是在该函数中传入查找的父级目录,先通过方法 os.path.isdir() 判断传入的是不是一个目录,如果是就通过 os.listdir()方法查找该目录的下一级中的所有文件或文件夹得到一个列表,通过遍历该列表得到文件或文件夹名,再进行地址拼接得到一个准确的文件地址,继续通过 两个方法【 os.path.isdir() 和 os.path.isfile()】对拼接的文件地址进行判断,如果已经是文件了就直接输出地址,如果是文件夹就继续进行递归查询。
def find_path(dir_father):
global total_file, total_dir # 定义全局上的两个总数变量
father_bool = os.path.isdir(dir_father) # 判断传入的是不是还是一个文件夹
if father_bool:
dir_list = os.listdir(dir_father) # 将传入的文件夹继续遍历到列表中
for dir in dir_list:
dir_child = dir_father + '\\' + dir # 拼接合成路径
dir_bool = os.path.isfile(dir_child) # 再次判断该路径是不是一个文件
# 通过判断该路径下的文件是不是一个文件后进行判断输出
if dir_bool:
# 有文件后总文件数 +1
total_file += 1
try:
index = dir_child.index(user_file)
if index > 1:
print(find_file_name+dir_child)
find_file_list.append(dir_child)
else:
print(dir_child)
except ValueError:
print('\t'+dir_child)
else:
try:
index = dir_child.index(user_file)
if index > 1:
print(find_dir_name+dir_child)
find_file_list.append(dir_child)
else:
print(dir_child)
except ValueError:
pass
find_path(dir_child)
# 有文件夹后文件夹数加一
total_dir += 1
find_path(father_route)
🥓 3、结果输出
这里和开头差不多,没太多好说的,就是最后代码执行完毕后对结果进行输出。通过time模块得到时间戳,获取输出的时间。
end_time = time.time()
total_time = end_time - start_time
print('\n总共查找了{}个文件夹,查询到了{}个文件,耗时{}秒'.format(
total_dir, total_file, total_time))
if user_file != '':
file_len = len(find_file_list)
if file_len == 0:
print('未查找到该文件或文件夹')
else:
print('查找到的文件以及文件夹共有【{}】个:以下是查询文件的具体位置\n'.format(file_len))
for file in find_file_list:
print(file)
🧇 完整源码
有的朋友需要源码,这里就把源码贴上了吧,方便大家。
以下代码是自己打包成查找程序前的源码,虽然和上述代码有些差异了,但是换汤不换药,各位可以直接复制使用,也可以根据自己需求进行修改
import os
import time
print('\n\t====================欢迎使用文件查找程序,以下是使用文档,请查看后使用====================\n')
print(' 1、当前的程序是从系统盘开始执行的,所以如果不输入查询路径会直接从当前程序开始执行位置遍历查找文件,不建议这么做,因为基本找不到')
print(' 2、查询使用的是模糊查询,会将你输入的查找文件名进行模糊查询,这也意味着你不用输全文件名,也能找到该文件,但也会找到一些和你输入的无关文件,如果需要精确查找建议输入全文件名')
print(' 3、在输入文件名时,如果不输入将会把该文件夹位置下的所有文件包括文件夹输出到控制台')
print(' 4、提示输入后需要回车。请按规定使用\n')
while True:
user_route = input('\n请输入查询路径:')
user_file = input('请输入查找文件名:')
father_route = os.path.abspath(user_route)
find_file_list = []
find_file_name = '☆ 找到文件 >> '
find_dir_name = '★ 找到文件夹 >> '
# 如果不输入路径就重新用给父级路径赋值,赋值内容为当前文件所在位置
if user_route == '':
father_route = os.path.dirname(__file__)
# 如果不输入查找文件名,则直接将两个找到的文件的给予的变量赋值为空
father_bool = os.path.isdir(father_route)
if not father_bool:
print('您的路径貌似有点问题,请检查后重新输入:')
continue
print('开始执行,当前查找文件夹是:', father_route, '\n以下是该文件夹中的文件:')
print('\n'+'*'*100 + '\n')
start_time = time.time()
total_file = 0
total_dir = 0
def find_path(dir_father):
global total_file, total_dir # 定义全局上的两个总数变量
father_bool = os.path.isdir(dir_father) # 判断传入的是不是还是一个文件夹
if father_bool:
dir_list = os.listdir(dir_father) # 将传入的文件夹继续遍历到列表中
for dir in dir_list:
dir_child = dir_father + '\\' + dir # 拼接合成路径
dir_bool = os.path.isfile(dir_child) # 再次判断该路径是不是一个文件
# 通过判断该路径下的文件是不是一个文件后进行判断输出
if dir_bool:
# 有文件后总文件数 +1
total_file += 1
try:
index = dir_child.index(user_file)
if index > 1:
print(find_file_name+dir_child)
find_file_list.append(dir_child)
else:
print(dir_child)
except ValueError:
print('\t'+dir_child)
else:
try:
index = dir_child.index(user_file)
if index > 1:
print(find_dir_name+dir_child)
find_file_list.append(dir_child)
else:
print(dir_child)
except ValueError:
pass
find_path(dir_child)
# 有文件夹后文件夹数加一
total_dir += 1
find_path(father_route)
print('\n'+'*'*100)
end_time = time.time()
total_time = end_time - start_time
print('\n总共查找了{}个文件夹,查询到了{}个文件,耗时{}秒'.format(
total_dir, total_file, total_time))
if user_file != '':
file_len = len(find_file_list)
if file_len == 0:
print('未查找到该文件或文件夹')
else:
print('查找到的文件以及文件夹共有【{}】个:以下是查询文件的具体位置\n'.format(file_len))
for i in range(file_len):
print(str(i) + '、' + find_file_list[i])
try:
index = int(input('\n你可以通过输入文件前的序号直接打开文件,不输入回车跳过:'))
for f in range(file_len):
if f == index:
os.startfile(find_file_list[f])
else:
pass
except:
pass
user_break = input('请问还继续查找吗?继续查找请输入 y:')
user_continue = user_break.lower()
if user_continue == 'y':
continue
else:
break
🥞 结尾
通过这个代码可以很快得查询到你需要得文件夹位置,然后通过复制该位置得地址,直接进入该文件位置或者打开该文件,如果感觉所有文件都输出不太好,也可将输出位置进行注释,只保留最后得结果输出就可以了
🥐 最后
最后附上一篇一位大佬从这篇文章构思的文章,本人都只能默默给她点赞了
有毕设论文需要构思的可以参考一下
目录
- 引言
1.1 编写目的
1.2 背景
1.3 定义 - 需求分析
2.1 可行性分析
2.1.1 技术可行性分析
2.1.2 操作可行性分析
2.1.3 社会因素可行性分析 - 基本功能需求分析
3.1 功能需求
3.2 非功能需求分析
3.2.1 可维护性
3.2.2 易用性
3.2.3 可靠性
3.2.4 兼容性
3.2.5 安全性 - 主要使用的模块和方法
- 主要思路及代码
- 运行结果
- 总结 12
7.1 对现有系统与开发系统的研究总结
7.2 研究中的不足
- 引言
当今社会是一个讲求效率的社会,时间就是金钱,那么开发简单又易于操作的程序不仅可以节省时间,还可以提高效率。本次开发的项目是一个通过python遍历来查询文件或文件夹的操作系统,使用方便,简单易学,是便于个人时间管理的一个小工具。
1.1 编写目的
由于互联网的发展及线上教学的普遍,本地会存放大量的文件数据,很多时候想要及时找到想要的文件却是力不从心,最终也只能通过很低的效率来获得微不足道的结果。这对于想要在有限的时间里发挥其应有的作用和效果显得有些许无力。此项目就是为了解决这个问题。
1.2 背景
互联网的广泛使用,随之产生的文件数据也逐渐庞大,利用便利的程序查找文件终将会占有一席之地。用程序对目标或广泛目标进行查找的优点是检索迅速,查找方便,节约时间成本,可以有效提高查找文件的效率。
1.3 定义
使用python递归遍历文件项目是一个功能实用,操作方便,简单明了的查找文件的小工具,能够实现在繁杂且庞大的文件数据中快速且精准的查找到想要的文件,是学生和上班族提升学习和工作效率的福音。
2. 需求分析
2.1 可行性分析
2.1.1 技术可行性分析
硬件条件:PC机
本地PC操作系统:Windows 11
开发环境:Spyder(Python 3.9)
部分更新后的Windows 11 系统不支持最新的anaconda,建议使用老版的anaconda
北京外国语大学开源软件镜像站:https://mirrors.bfsu.edu.cn/anaconda/archive/
当前开发人员对其一般性的软件和操作环境都比较熟悉,对其不熟悉的小白也可通过上面的链接下载anaconda安装包,就可以使用spyder,操作小工具了。作为目前阶段性产物,利用现有的人力和物力是完全具备可以开发出来的能力,且日后的发展空间也很大,实现方法简单容易,在技术上是完全可行的。
2.1.2 操作可行性分析
本次开发的python递归遍历小程序,可以在使用上为用户提供方便,高效快捷,直接在spyder页面运行后在控制台输入想要遍历的路径和文件名即可在庞大的数据下查找目标文件,且本程序无需占据多大内存,也有效解决了占据内存的困扰。本次开发成本很低,后续如需修改,也会比较方便和快捷。
2.1.3 社会因素可行性分析
在现有系统处理大量数据时,无可避免的会触到大量的数据,导致程序加载缓慢,更有甚者出现卡顿等现象,文件检索功能的研究已经无可避免的摆在眼前,也成为日常说中不可或缺的一部分。
综上所述,研究并实现文件检索的功能,可以得到很好的发展,本次通过对python的学习并在其基础上开展对文件和文件夹递归遍历的研究。
- 基本功能需求分析
3.1 功能需求
本项目是一个功能实用、操作方面、简单明了的查询和遍历文件或文件夹的程序,可以实现通过绝对路径和父级路径加上文件名的方式查询所有路径下符合条件的数据并展示在列表中,基于对输入的准确性的基础上,给出了不论是否输入绝对准确的文件名,都会输出当前路径下所有文件或文件夹的数据列表,展示在控制台,便于用户查找,为查询数据提供便利。本项目的顺利运行主要通过在控制台中获取路径和文件&文件名的查询结果,在给出的路径中查找相应的符合条件的所有数据,并在控制台中输出所有查找到的文件的具体位置。
需要手动输入的具体位置说明:
一:输入查询的路径
可以手动输入父级路径或通过直接回车的方式,路径为当前文件所在位置;也可以输入具体路径,具体路径可以是绝对路径或非绝对路径。路径这里有个判断,如果路径找不到,后面就无法遍历,所以会有个拦截操作。
二:输入查找的文件名
是否输入完整的文件名并不重要,这里用到的是模糊查询方法,会将用户输入的文件名进行模糊查询;如果需要精确查找,可以输入完整的文件名;也可以不输入文件名,通过直接回车的方式查找当前目录下的所有文件和文件夹中所包含的文件。最后一种方式在文件数量很大的情况下不建议使用,浪费资源。
三:继续查询
在完成前面两个操作后对整个程序的一个循环,可以通过输入Y进行再次查询遍历操作,再次查询的结果与之前的操作不再有任何联系,继续对路径和文件名进行判断。
3.2 非功能需求分析
3.2.1 可维护性
从接到修改请求后,对于普通修改,可在一天内完成,对于重大修改在一周内完成。
3.2.2 易用性
Python递归遍历文件或文件夹小程序简单易用,用户能直接通过控制台界面掌握所有目标数据。
3.2.3 可靠性
当输入不符合规范的路径时,会提示“您的路径貌似有点问题,请检查后重新输入:”;
当未输入路径时,程序从父级路径开始查起;
当输入路径,未输入文件名时,程序从当前输入的目录查起。
3.2.4 兼容性
支持MAC OS、Windows操作系统
3.2.5 安全性
能经受住来自互联网的一般性恶意攻击。
- 主要使用的模块和方法
模块:python 自带的os以及time模块,time模块在此项目中的使用主要用于获取时间差,对于少量数据而言,作用不大。
方法:
os.path.isdir() 判断路径文件是否是文件夹,是返回True,反之False
os.path.isfile() 判断路径文件是否是文件,是返回True,反之False
os.path.abspath() 得到一个当前传入路径的绝对路径
os.path.dirname() 传入 file 获取当前文件所在路径的父级目录
os.listdir() 传入一个目录,得到该目录下的子级文件或文件名的列表,不含父级目录
time.time() 获取到当前时间戳
str.index() 内置字符串查找方法,当传入的值中在str中时得到传入值得下标,如果没有则抛出异常值: ValueError
- 主要思路及代码
- 开始位置:这里主要是通过输入需要查找父级文件夹和需要查找得文件进行判断。
定义父级路径:
如果不输入路径就重新用给父级路径赋值,赋值内容为当前文件所在位置。针对父级路径需要进行判断,如果不符合父级路径的要求,会提示重新输入。
2.关键位置:下面是主要执行文件查找得递归函数,主要的思路是在该函数中传入查找的父级目录,先通过方法 os.path.isdir() 判断传入的是不是一个目录,如果是就通过 os.listdir()方法查找该目录的下一级中的所有文件或文件夹得到一个列表,通过遍历该列表得到文件或文件夹名,再进行地址拼接得到一个准确的文件地址,继续通过 两个方法【os.path.isdir() 和 os.path.isfile()】对拼接的文件地址进行判断,如果已经是文件了就直接输出地址,如果是文件夹就继续进行递归查询。
针对os.listdir(),也可以用os.walk()替换,两种方法只在输出时有不同点,主要就是listdir默认是按照文件和文件夹存放的字母顺序进行输出,而walk则是先输出顶级文件夹,然后时顶级文件,再输出第二级文件夹,以及第二级文件,以此类推,可以根据需要进行修改。
- 结果输出:这里和开头差不多,就是最后代码执行完毕后对结果进行输出。通过time模块得到时间戳,获取输出的时间。
6. 运行结果
在编写的同时需要对代码运行的准确性进行测试,以下列举了测试代码运行过程中的测试结果。
1.随意输入查询路径和文件名后,程序会对输入的数据进行简单的判断,不符合条件的直接给出异常提示,之后可以再次输入查询条件,运行结果正确。
2.在控制台中输入具体的路径名称,可以查询到所有目录下的文件路径,可以直接复制控制台的路径粘贴到搜索框中打开,运行结果正确。
在控制台的输出结果可以定义的total_file和total_dir会根据具体查询到的结果进行遍历赋值,可以对查询结果一目了然,一般对于查询多条数据,都需要默认给个数据总量的输出。
time.time():返回当前时间的时间戳,time()函数日常可以用于获取单独的年月日信息,如time.localtime(),在此处通过结束时间和开始时间的时间差来获取运行的秒差。
3.输入路径和文件名后,在系统找不到文件名的情况下,会默认将当前目录下的所有文件全部列出,并提示“未找到文件或文件夹”,运行结果正确。
4.输入路径和文件名后,系统可以找到目标文件或文件夹,输出结果时会遍历查询结果的条数。在输出遍历序号时,需要注意一点的是,因为上面给file_len变量赋值为0,所以当查到文件或文件夹时,i的值默认为0,输出时序号i需要+1
5.已经查找到的文件,控制台有空五角星的标识,如果是文件夹,则是实五角星的标识,只针对查找完整文件或文件名时有效。在这里可以通过下方控制台输入具体的文件前的序号直接打开文件。
7. 总结
7.1 对现有系统与开发系统的研究总结
工作负荷
由于数据量越来越大,而在繁杂的数据中想要即时准确的找到目标文件,无意是很头痛的事情,且对时间需求很大。 本项目的开发可以精准及时找到目标文件。
局限性
在面对庞大的数据时,系统会出现无法响应用户的现象,造成时间和精力的浪费,因此,本项目应运而生。在通过python遍历时,不会出现卡顿现象,且查找的效率很高。
由此分析得出,需要一个能够适应新的信息化时代的文件检索程序,所以本次项目的开发还是有必要的。
7.2 研究中的不足
本项目的开发,存在着很多不完美的地方,部分功能在设计上也存在着缺陷,针对的用户目前只有学生和上班族,比较局限,没有可以独立的程序,可以使该程序的应用更广泛。希望本次使用python递归遍历文件或文件夹的学习可以更好的激发对于在python领域的探索和学习,吸引更多的人踏入python的学习当中,在python领域中大展身手。
















 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











