







DataWhale暑期夏令营学习笔记 番外篇之竞赛上分技巧
竞赛流程
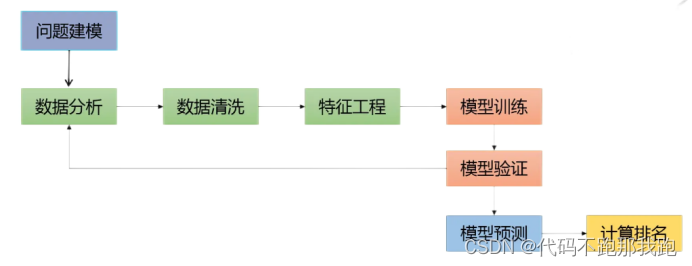
1. 问题建模
问题建模要从对赛题的理解和对理解的线下验证两个角度出发。
对赛题的理解首先可以从业务层面进行入手,比如针对还款情况的分析,可以从还款意愿、还款能力、其他因素等方面进行考虑。还款的意愿又可以从历史逾期、是否黑名单、是否属于诈骗团体、是否提供虚假信息等方面判断其是否有欺诈倾向;还款能力可以从收入水平、债务情况、工作变动情况等判断;其他因素中,工资结算日、节假日等也可能对其还款情况产生影响。
其次,再通过对于赛题数据进行理解,查看每种数据集之间的关系、数据中的缺失值情况、类别特征和数值特征的基本分布,比如类别数、均值、最值等。
然后,对模型的评价指标进行选择,分类指标主要有精确率、召回率、AUC、logloss等,回归指标主要有MAE、MAPE、RMSE等。
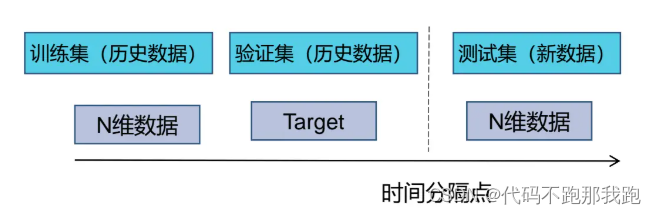
线下验证有时序验证、K折交叉验证等思路。
时序验证:
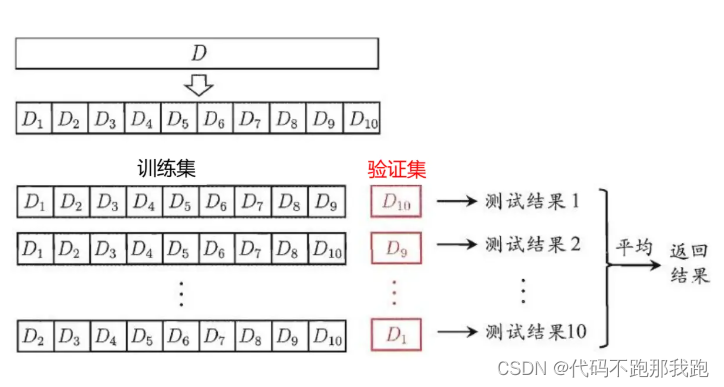
K折交叉验证:
2. 数据探索性分析(EDA)
何为EDA?
如何EDA?

3. 特征工程
3.1 数据预处理
- 离群点处理:对于数据中,偏离数据群体的点可以当作缺失值进行处理,也可删掉离群点所在样本,或使用统计值进行填充,可以多做尝试,选择效果最佳的方案。
- 缺失值处理:要查看是否有特定的业务意义,有的话可以用填充max(fea)+1/min(fea)-1;无业务意义的真正缺失值可以使用各种填充方案,也可以不填充(比如设置为np.nan),通过对比各种方案的效果进行选择处理。
- 错误值处理:对具有明显错误的特征,比如血压9999999,体重800等进行修正,在匿名特征中出现-1和999可能表示了缺失值,替换np.nan。
3.2 特征提取
特征分为类别特征、数值特征、时间特征等。

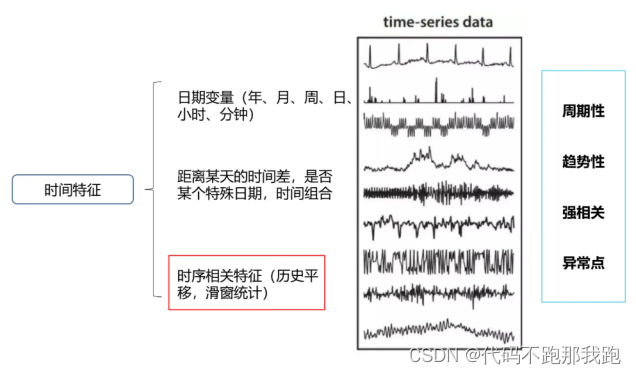
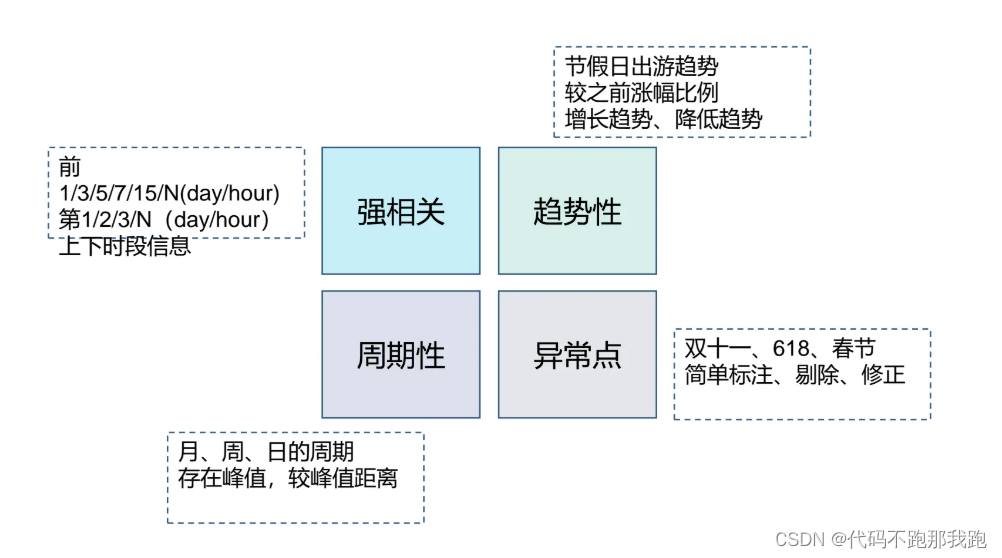
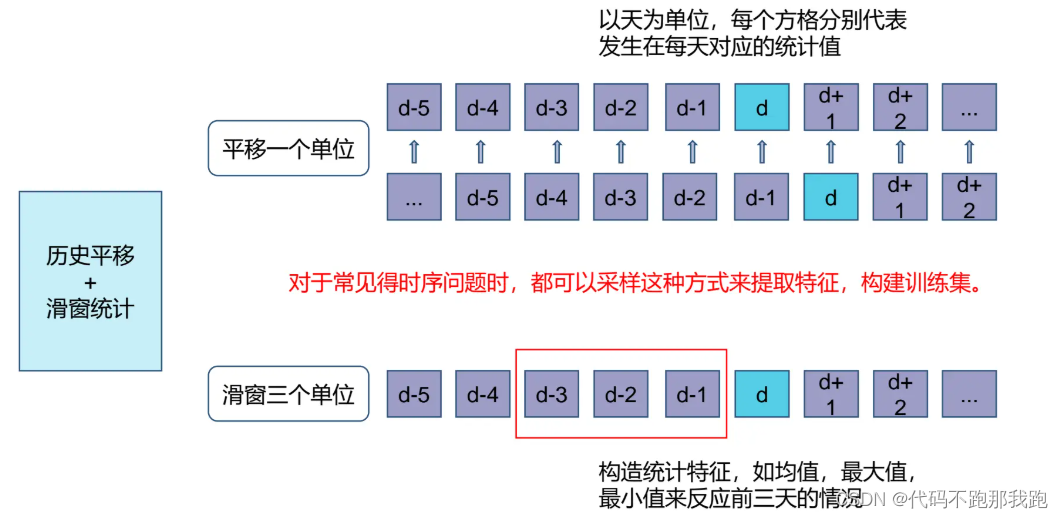
对于常见的时序问题,我们可以采用历史平移、滑窗统计等方法进行特征提取。
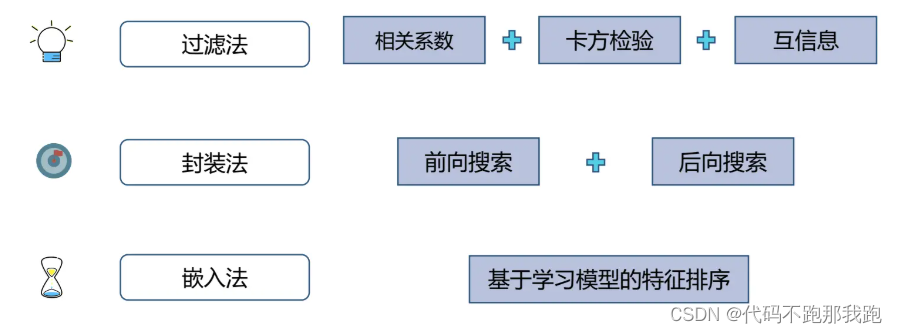
3.3 特征选择
4. 必备模型
- XGBoost:对特征处理要求低;
- LightGBM: 对类别和连续特征友好;
- NN模型: 缺失值不需要填充;
5. 模型融合
鱼佬给的示例。

















 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











