






一、索引
(一)简单的操作
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。
作用:
-> 数据库中的表、数据、索引之间的关系,类似于书架上的图书,书籍内容和书籍目录的关系。
->索引的作用类似于书籍目录,可用于快速定位,检索数据。
->索引对于提高数据库的性能有很大的帮助。
索引付出的代价:消耗更多的空间;虽然提高了查找的效率,但降低了增加、删除、修改的效率。
1、查看索引
show index from 表名;
看针对哪个列进行的索引。本例中 为id列。
2、创建索引
create index 索引名 on 表名(列名);创建索引操作,是一个低效操作。如果表里的数据多,创建索引操作,可能会非常耗时+且带来大量的硬盘IO;

3、删除索引
drop index 索引名 on 表名;
(二)索引如何提高查询效率的?
数据结构一般有:顺序表、链表、二叉树、栈、队列、哈希表、二叉搜索树
->哈希表,不适合做数据库的索引:哈希表的增删查找时间复杂度为O(1),其只能查询 值相等 的情况。如果是小于、大于、between and这种大小的范围查询,不能进行。
->二叉搜索树,不适合做数据库的索引。
......
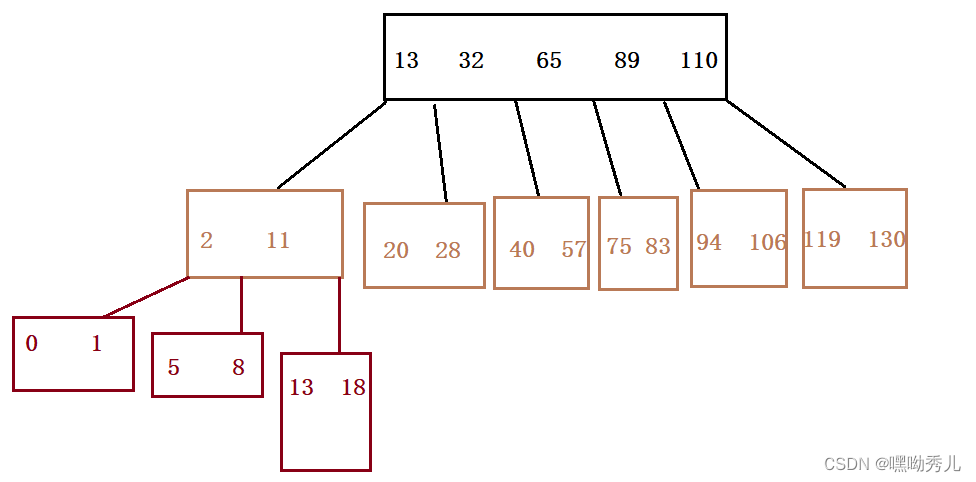
表示索引的数据结构:B+树
B树:是一个N叉搜索树。每个节点上,可能会包含N-1个值,也可以更少;这些值划分为N个空间。
优势:表示数据集合时,比二叉树的深度小,IO次数下降。
其实现比较难。
B树与B+树:
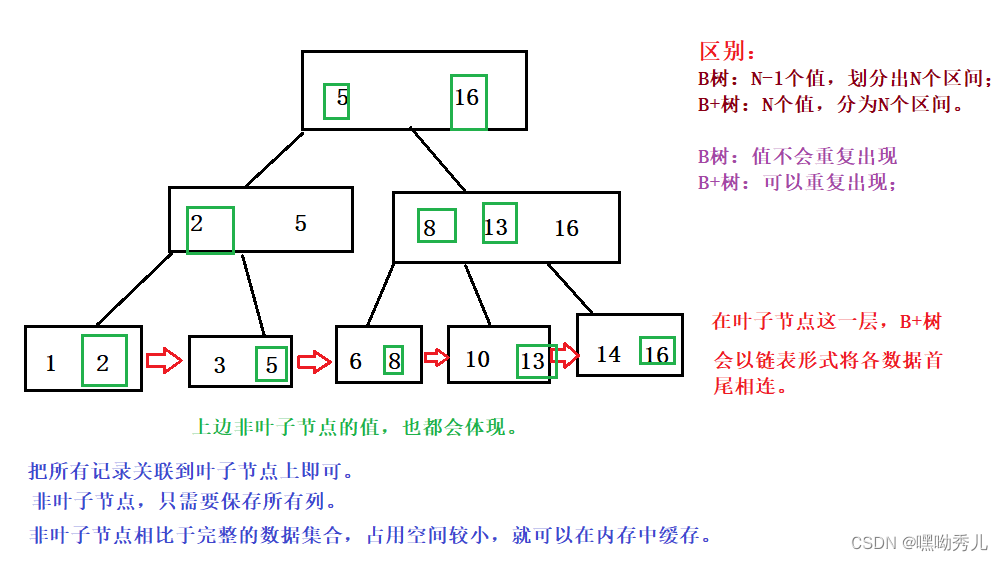 把真正的整条记录都放在叶子节点上。
把真正的整条记录都放在叶子节点上。
二、事务
核心就是解决原子性问题。
事务是指逻辑上的一组操作,组成这个操作的各个单元,要么全部成功,要么全部失败。
1、原子性【事务最核心的性质】
(1)事务,是保证原子性的。
原子性表示,把多个SQL语句看作一个整体,要么都执行完,要么都不执行;在执行过程中出现问题时,会发生回滚。
->当执行过程出现问题时,自动地把前边执行的SQL语句一一还原,回到最初始的位置。->回滚【Rollback】;
(2)开启事务
start transaction;事务结束
commit;2、一致性
表示在事务执行前后,数据处在"一致"的状态。
一致性是指数据处于一种语义上的有意义且正确的状态。
一致性是数据库处理前后结果应与其所抽象的客观世界中真实状况保持一致。这种一致性是一种需要管理员去定义的规则。管理员如何指定规则,数据库就严格按照这种规则去处理数据。
比如:对银行转帐事务,不管事务成功还是失败,应该保证事务结束后表中两人存款和不变。
3、持久性
只要事务成功结束,它对数据库所做的更新就必须永久保存下来。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
4、隔离性
在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。
隔离性存在的意义:让并发执行事务的过程中,问题在可控范围内。
并发执行事务过程中,可能带来的影响:
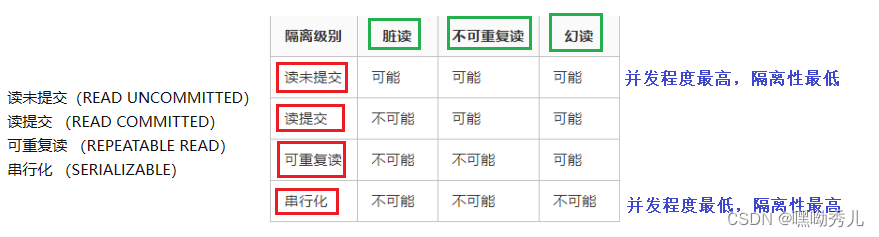
(1)脏读问题/读脏数据
一个事务A在修改数据,提交之前,事务B读取了正在修改的数据;但A后序可能有对数据进行了修改,那么此时事务B读取的数据就是脏数据。
脏读问题的解决:对写操作加锁。【写的时候,不能读】
(2)不可重复读
在事务A中,B多次读取同一个数据,发现读取的数据不一样。是因为在读的过程中,A修改了数据。
不可重复读的解决:对读操作进行加锁。【在问题1中,已经进行了写加锁,此处有进行了读加锁】。
随着引入写加锁,读加锁,并发效率降低,隔离性变高了【数据准确性提高】。
(3)幻读
甲在读文件A时,乙去修改B文件【这样不会影响到甲正在读的文件A】。这样出现的问题是,乙再次读取的时候,关心的数据一样,但是结果集合发生了变化【这次读的时候不止一个文件, 可能是多个】。
解决幻读:串行化
(4)隔离级别:
















 1414
1414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









