






1、线程的状态
NEW->安排了工作,未开始行动 。
RUNNABLE->可工作的。分为正在工作和即将开始工作。
BLOCKED->排队等着。
TIMED_WAITING->排队等着。
TERMINATED->工作完成。
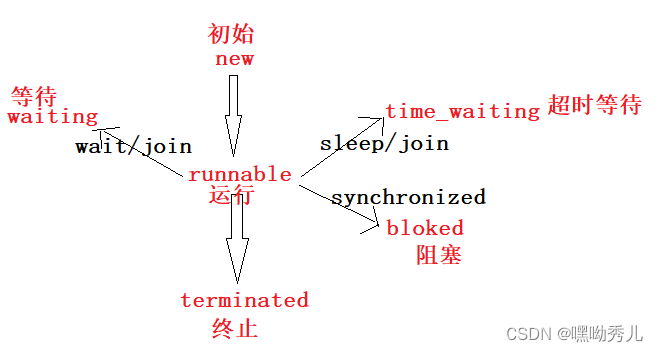
->BLOCKED表示等待获取锁
->WAITING和TIMED_WAITING表示等待其他线程发来通知
->TIMED_WAITING线程等待唤醒,但是又时间限制
->WAITING线程在无限等待唤醒
此外:yield()可以让出CPU, 不改变线程的状态, 但是会重新去排队.
2、多线程带来的风险----线程安全问题
理解线程安全问题:如果多线程环境下运行代码的结果是符合预期的,也即与在单线程环境下的结果一致,则说明这个程序是线程安全的。
线程不安全的原因:
(1)抢占式执行
多个线程的调度执行过程,可视为全随机
(2)多个线程修改共享数据
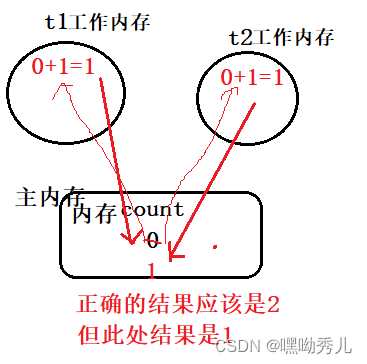
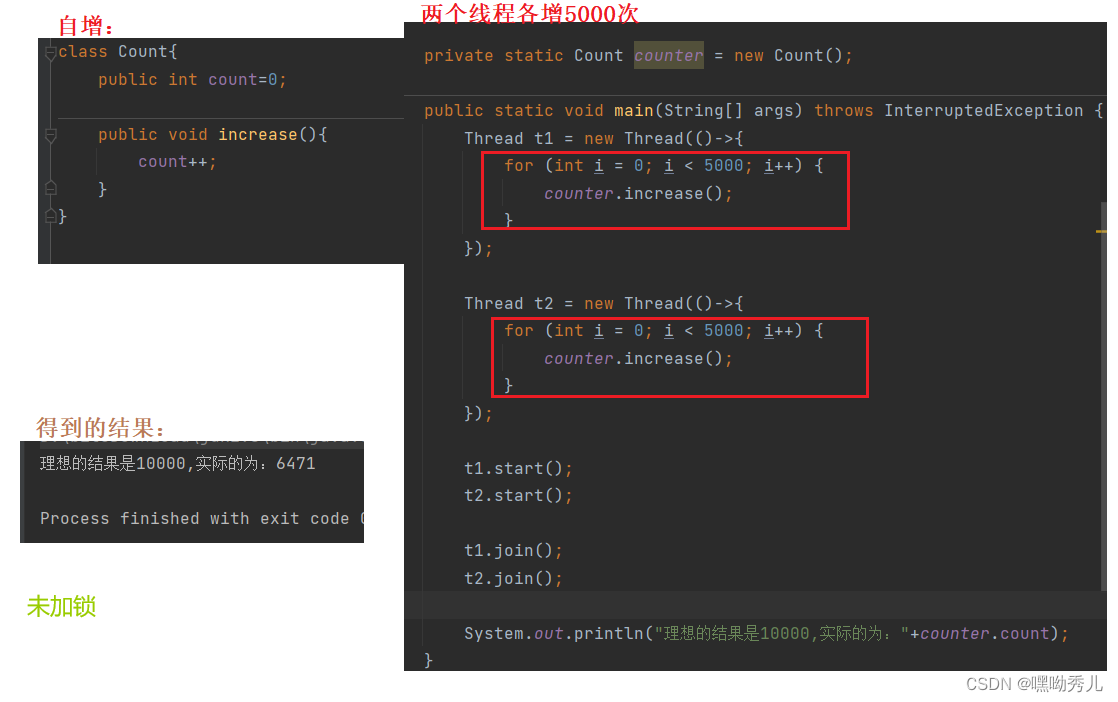
举例:count++操作。首先,CPU是以一条指令为单位进行执行。再进行修改操作时,一般有三个CPU指令:1)load:把内存中的数据读取到CPU的寄存器中
2)add:把CPU寄存器中的值进行+1操作
3)save:把寄存器中的值,写回到内存中
当前,用2个线程修改同一个变量count。每次修改都是3个步骤,不是原子性操作。再由于线程的调度是随机的,所以真正执行这些操作时,有多种排列顺序。比如:
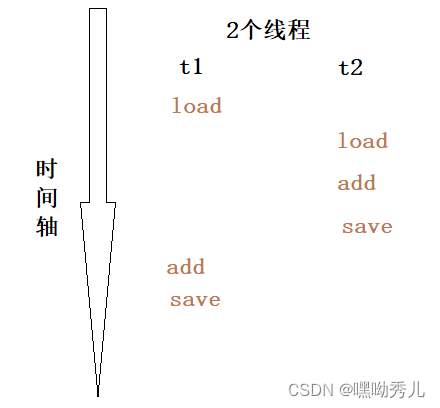
(3)修改操作不是原子的
可以从这一原因入手,解决线程不安全问题。
(4)内存可见性问题
可见性是指,当一个线程对共享变量值的修改,能够及时的被其他线程看到。
Java内存模型:目的是屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并发效果.
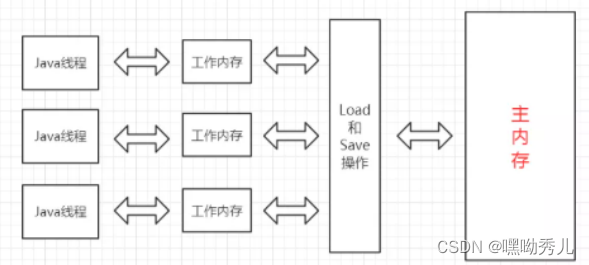
->线程之间的共享变量存在 主内存。
->每个线程都有自己的工作内存。
->当线程要读取一个共享变量时,会先把变量从主内存拷贝到工作内存,再从工作内存读取数据。
->当线程要修改一个共享变量时,也会先修改工作内存中的副本,再同步回主内存。
"主内存" 才是真正硬件角度的 "内存". 而所谓的 "工作内存", 则是指 CPU 的寄存器和高速缓存.
拷来拷去也是因为 CPU 访问自身寄存器的速度以及高速缓存的速度, 远远超过访问内存的速度 。
(5)指令重排序
代码重排序,也会引发线程不安全。
编译器对指令重排序的前提是”保持逻辑不发生变化“。 多线程代码执行复杂度更高,编译器很难在编译阶段对代码的执行效果进行预测, 因此激进的重排序很容易导致优化后的逻辑和之前不等价.
3、针对线程不安全问题,怎么解决?
针对上述count++的例子,
synchronized关键字
(1)synchronized的特性
互斥:
某个线程执行到某个对象的synchronized中时,其他线程如果也执行到同一个对象的synchronized就会阻塞等待。
->进入synchronized修饰的代码块,相当于加锁;退出synchronized修饰的代码块,相当于解锁 。
->阻塞等待: 针对每一把锁,都有一个等待队列。当这个锁被某个线程占有的时候,其他线程尝试进行加锁,就加不上。就得阻塞等待,知道之前的线程解锁后,操作系统会唤醒一个新的线程,再来获取到这个锁。
刷新内存【不一定】:
synchronized 的工作过程: 获得互斥锁->从主内存拷贝变量到工作内存->执行变量的相关操作->将更改后的共享变量的值刷新到主内存->释放锁。
所以 synchronized 也能保证内存可见性.
可重入:
synchronized同步块对同一条线程来说是可重入的,不会出现自己把自己锁死的问题。
自己把自己锁死的问题 :自己加锁,但忘了解锁;二次加锁时,无法操作==》死锁。【这里只是死锁出现的一种形态,还会有其他形态。】
synchronized是可重入的。
-》可重入锁的底层实现:让锁里面记录好,是哪个线程持有的这把锁即可。
-》可重入锁进行解锁:引入一个计数器。每次加锁,计数器++;解锁,计数器--。如果计数器为0,此时的加锁才是真加锁;同样的,计数器为0,此时的解锁才是真解锁。
(2)synchronized的用法
修饰方法:
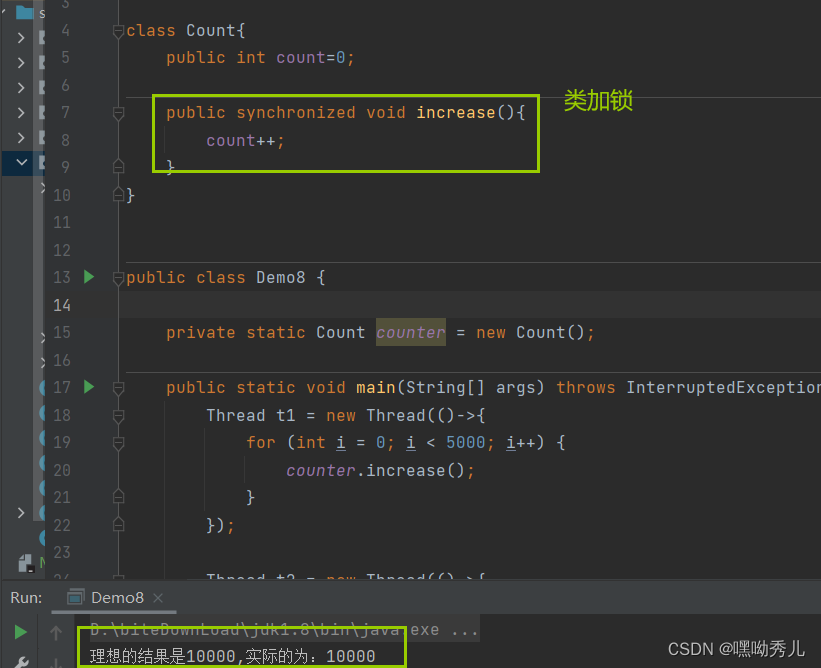
修饰代码块:
把要加锁的逻辑方法到synchronized修饰的代码块中,也能起到加锁的作用。
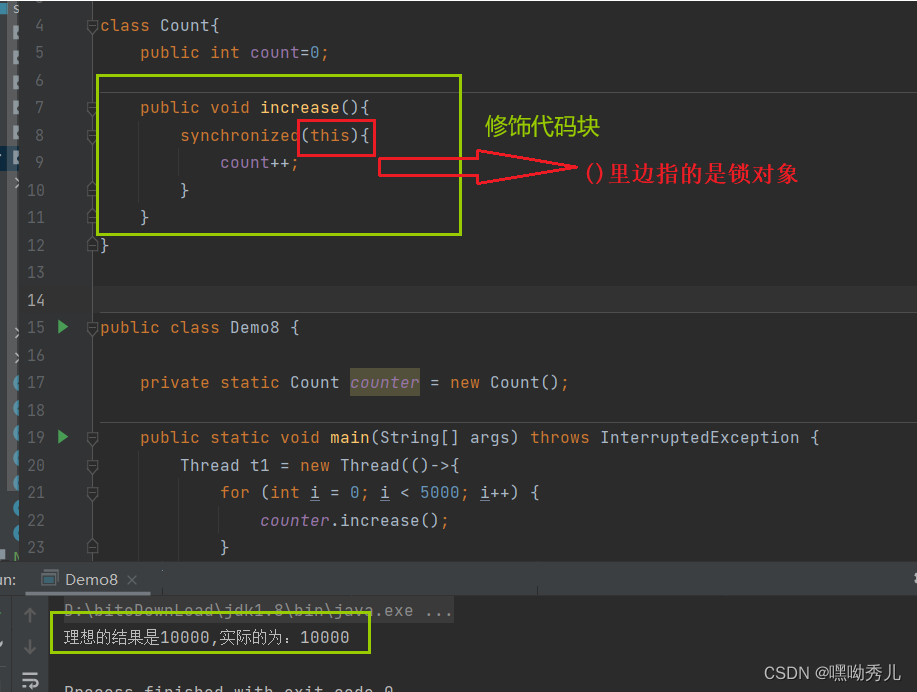
->在java中,任意的对象都可以进行加锁。例如下面:
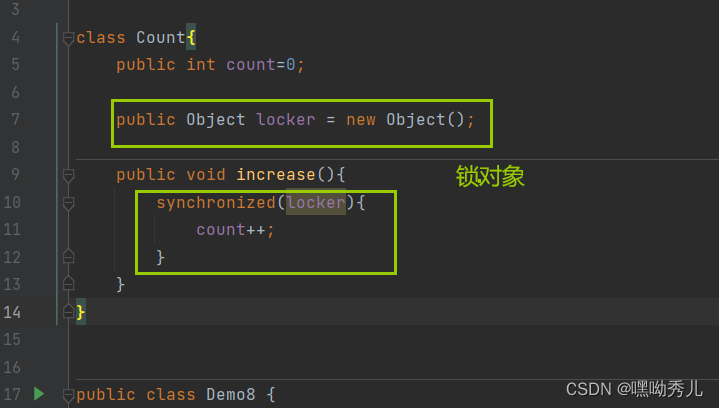
->在写多线程代码时,不关心这个锁对象是什么。只需关心两个线程是否锁同一个对象;如果是,就会产生锁竞争 ,锁不同对象,就无锁竞争。
锁对象只是用来控制线程之间的互斥的。
->针对不同对象加锁,就不会出现锁竞争。
->下面这两种写法都是线程安全的。
写法1:
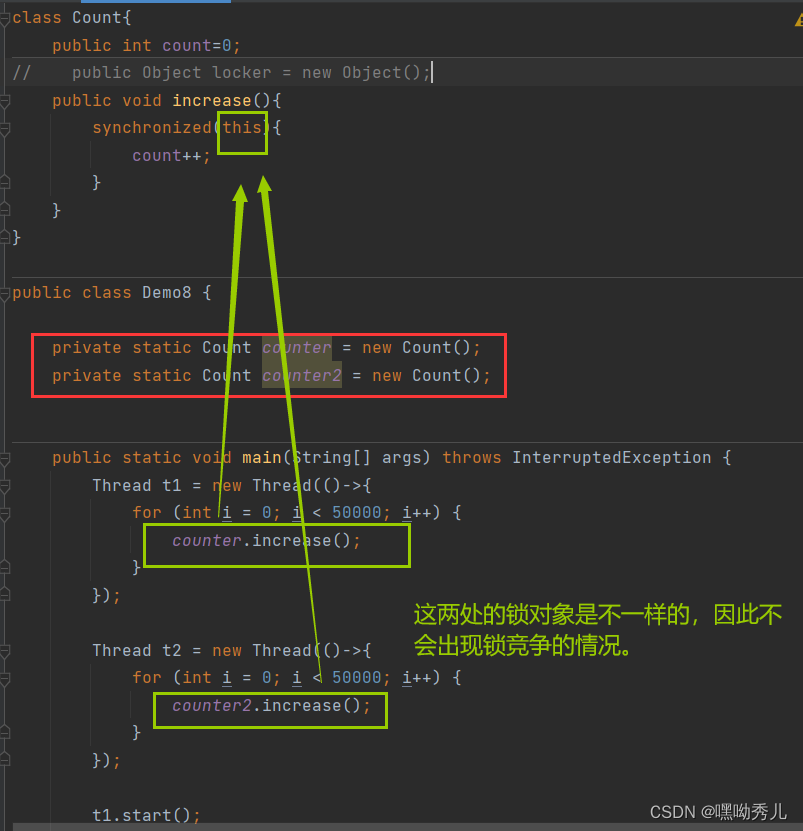
写法2 、3:
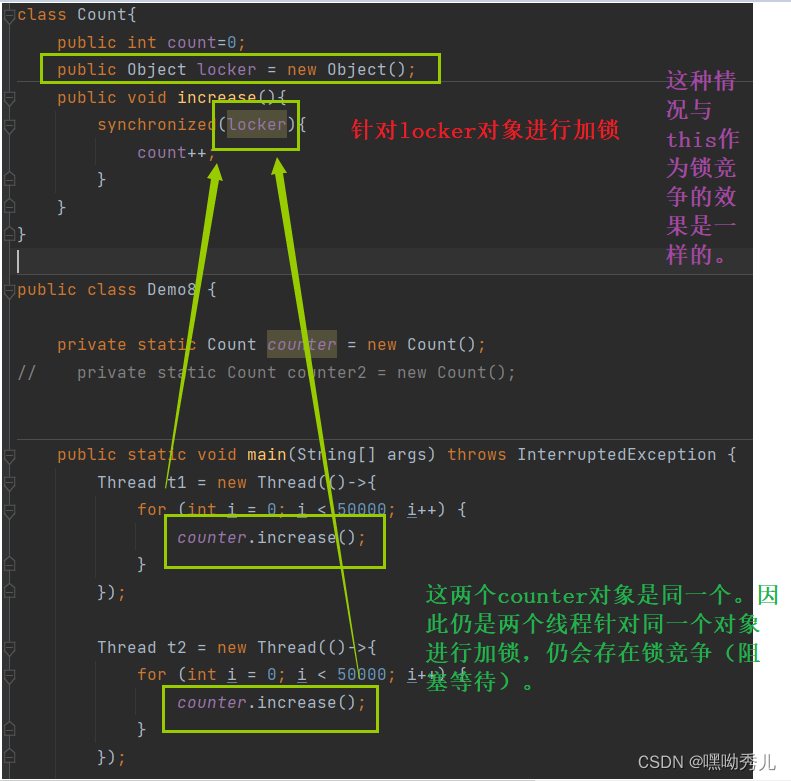
->写法4:
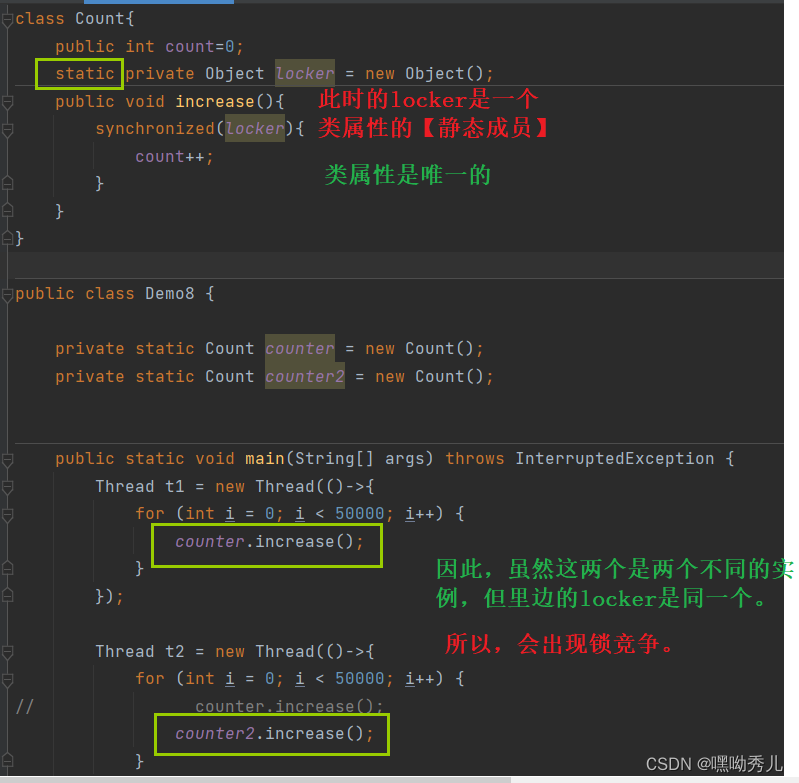
->写法5:
类对象在JVM中只有一个 。
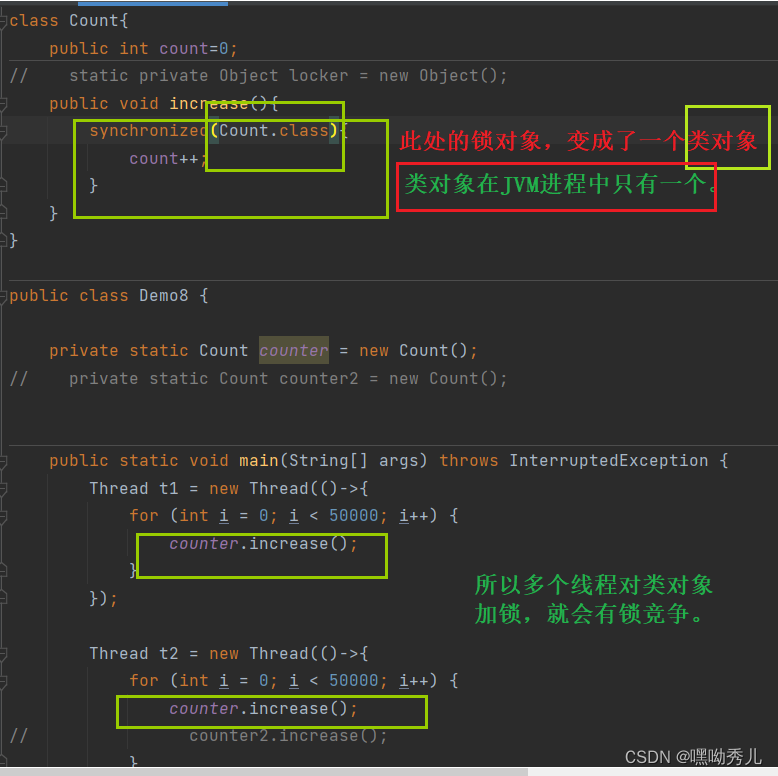
锁对象的核心原则:两个线程竞争同一个锁对象,就有竞争;不同的锁对象,就没有竞争。
锁竞争的目的:保证线程安全。
(3)总结一下synchronize:
synchronize的几种写法:
->修饰普通方法:锁对象相当于this
->修饰代码块:锁对象在()中指定
->修饰静态方法:锁对象相当于类对象。
















 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









