




05 Group - Pinned sprint collection
| The Link Your Class | Here |
|---|---|
| The Link of Requirements of This Assignment | Lab3-2 Requirement |
| Team Name | RIDS-IoT-Group |
| Team Project Topic | IoT Garbage Manager |
| Sprint Collection Link | Sprint Collection Link |
| Sprint Summary Link | [Sprint Summary Link] |
| Video demo link | Preview Demo and Pervious Oral |
| GitHub link | Github Repo |
1 Our Sprint plan
2 Our five Sprint log (Click)
| Sprint Log Link | Completed workload(%) | Remaining workload(%) | Proportion of total amount(%) | Date |
|---|---|---|---|---|
| Sprint log 1(1/5) | 60 | 40 | 10 | 2022.12.06 |
| Sprint log 2(2/5) | 68 | 32 | 8 | 2022.12.08 |
| Sprint log 3(3/5) | 80 | 20 | 12 | 2022.12.10 |
| Sprint log 4(4/5) | 90 | 10 | 10 | 2022.12.12 |
| Sprint log 5(5/5) | 100 | 0 | 10 | 2022.12.14 |
Burnout Diagram
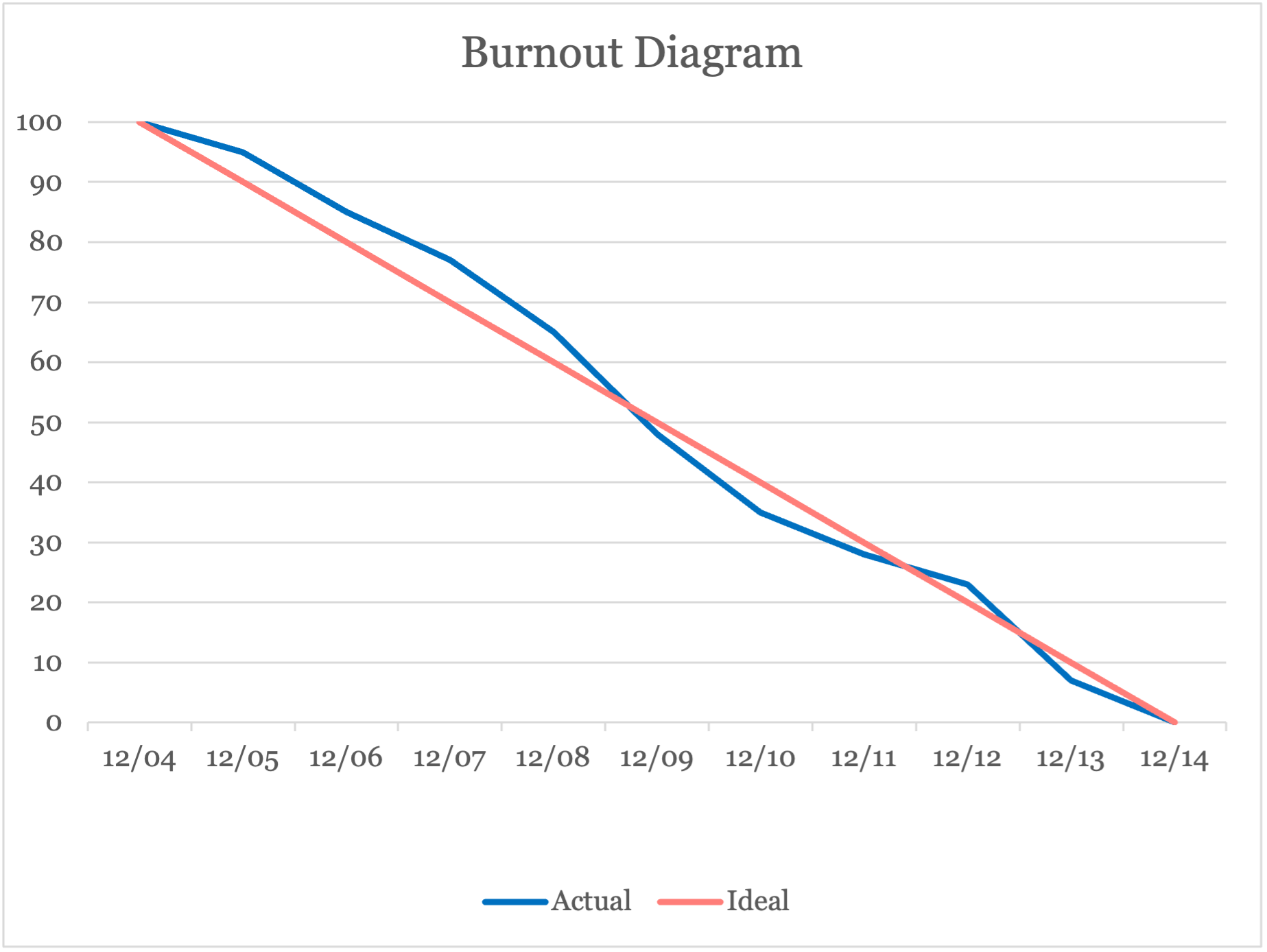
3 Github Repo Link
Here is the Github repository of our project.
Mindmap of our project


This blog is written by Zhijun Zhao and Hanlin Cai.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











