







目录
1. 初始化浏览器对象和访问页面
from selenium import webdriver
browser = webdriver.Chrome() # 初始化浏览器对象
browser.get('https://www.taobao.com/') # 访问淘宝页面
print(browser.page_source) # 得到页面源代码
browser.close()运行代码,之后会自动弹出窗口,并访问淘宝,输出网页HTML代码。
2. 查找节点及节点交互
Selenium可以驱动浏览器完成各种操作,例如填充表单、模拟点击、输入等。但想要点击、输入等需要找到输入的地方即节点,之后点击、输入即节点交互。
2.1 查找单个节点
下面我们以淘宝网为例:

这是个输入的表单节点,之后我们获取它。可以发现这个input节点 id属性为 'q',name='q'等等,我们可以通过其属性去获取节点(属性多种,获取方式也多种)。
(1)获取方法1——特定方法
以下是所有特定方法:
browser.find_element_by_id('')
browser.find_element_by_name('')
browser.find_element_by_css_selector('') # CSS选择器
browser.find_element_by_xpath('')
browser.find_element_by_link_text('')
browser.find_element_by_partial_link_text('')
browser.find_element_by_tag_name('')
browser.find_element_by_class_name('')(2)通用方法
find_element(查找方法,方式的取值),使用这个最好先from selenium.webdriver.common.by import By,方便使用。
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome() # 初始化浏览器对象
browser.get('https://www.taobao.com/') # 访问淘宝页面
inputElement1 = browser.find_element_by_id('q')
# inputElement11 = browser.find_element(By.ID, 'q') # 通用方法
inputElement2 = browser.find_element_by_css_selector('#q')
inputElement3 = browser.find_element_by_xpath('//*[@id="q"]')
print(inputElement1, inputElement2, inputElement3) # 三个值相同
browser.close()
2.2 查找多个节点
例如下面的导航条:
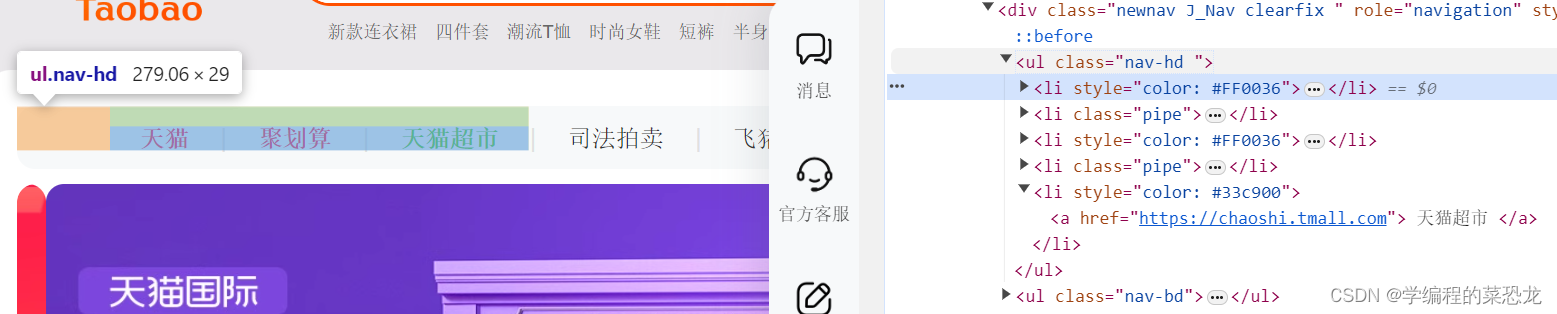
获取方法:在前面单个节点的两个获取方法的element加s即可,返回的是个列表。
from selenium import webdriver
browser = webdriver.Chrome() # 初始化浏览器对象
browser.get('https://www.taobao.com/') # 访问淘宝页面
inputElement = browser.find_elements_by_css_selector('.nav-hd li')
print(inputElement)
browser.close()
2.3 节点交互
现要浏览器自动去淘宝搜索ipad,我们需要先驱动浏览器打开淘宝,获取输入框节点,再使用send_keys方法输入文字,获取搜索按钮节点,用 click 方法点击按钮。
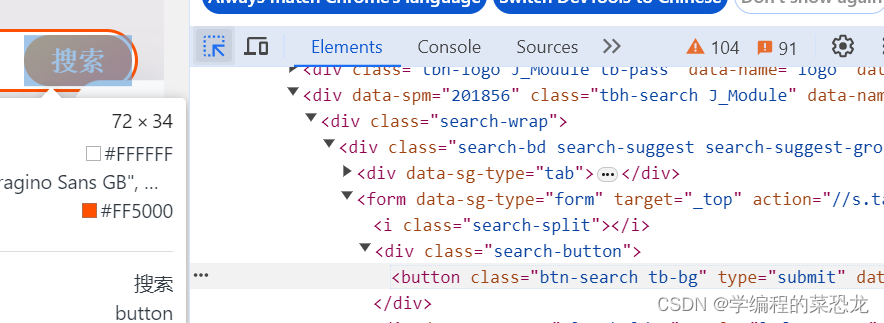
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome() # 初始化浏览器对象
browser.get('https://www.taobao.com/') # 访问淘宝页面
inputElement = browser.find_element_by_id('q') # 获取输入框节点
inputElement.send_keys('ipad') # 输入文字
findButton = browser.find_element_by_css_selector('.search-button button')
# 获取搜索按钮节点
findButton.click() # 点击按钮运行程序,可以看到过程。因为没有登陆,所以会停留在登陆页面。更多操作可看官方文档介绍:7. WebDriver API — Selenium Python Bindings 2 documentation。
3. 动作链
在前面,交互操作都是针对某个节点执行的。还有一些操作妹纸特定的执行对象,比如鼠标拖拽、键盘按键等,需要用另一种方式执行,那就是动作链。
例如,可以这样实现拖拽节点的操作,将某个节点从一处拖拽至另一处:
实例链接:菜鸟教程在线编辑器
现用代码实现拖拽:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()browser.switch_to.frame('iframeResult')用于切换到子页面中,详情见:7.1.3 Selenium的用法2-CSDN博客
依次选中要拖曳的节点source和拖曳到的目标节点target,接着声明 ActionChains 对象并将其赋值为 actions 变量,然后通过调用 actions 变量的 drag_and_drop() 方法,再调用 perform() 方法执行动作,此时就完成了拖曳操作。
结果:

更多的动作链操作可以参考官方文档的动作链介绍:7. WebDriver API — Selenium Python Bindings 2 documentation
4. 执行 JavaScript 之下拉进度条
对于某些操作,Selenium API 并没有提供。比如,下拉进度条,它可以直接模拟运行 JavaScript,此时使用 execute_script() 方法即可实现(双引号中为固定代码,多个网站都适用),代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
# browser.get('https://www.zhihu.com/explore')
browser.get('https://news.baidu.com/')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')有了这个方法,基本上 API 没有提供的所有功能都可以用执行 JavaScript 的方式来实现了。
5. 获取节点信息
前面说过,通过 page_source 属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup、pyquery 等)来提取信息了。
不过,既然 Selenium 已经提供了选择节点的方法,返回的是 WebElement 类型,那么它也有相关的方法和属性来直接提取节点信息,如属性、文本等。这样的话,我们就可以不用通过解析源代码来提取信息了,非常方便。
接下来,就看看通过怎样的方式来获取节点信息吧。
5.1 获取属性
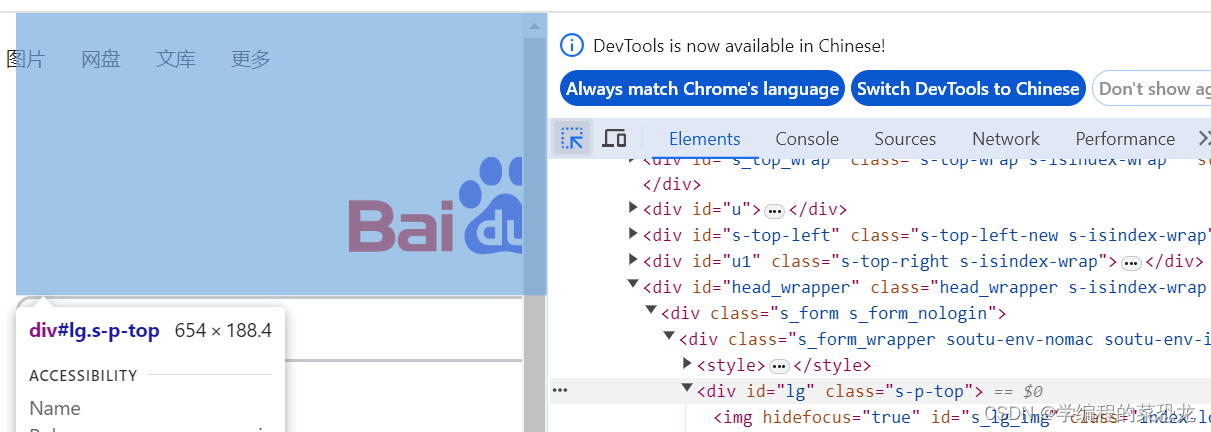
可以使用 get_attribute() 方法来获取节点的属性,但是其前提是先选中这个节点,示例如下:获得百度这个logo的class属性。
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.baidu.com/'
browser.get(url)
baiduLogo = browser.find_element_by_id('lg')
print(baiduLogo)
print(baiduLogo.get_attribute('class'))输出:<selenium.webdriver.remote.webelement.WebElement(session="ae1b17e9e092f2155263522772036f37", element="f.25E08F3EDDDDC250A5E5784201893A30.d.2BB430665B7C306121BC019488525624.e.10")>
s-p-top5.2 获取文本值
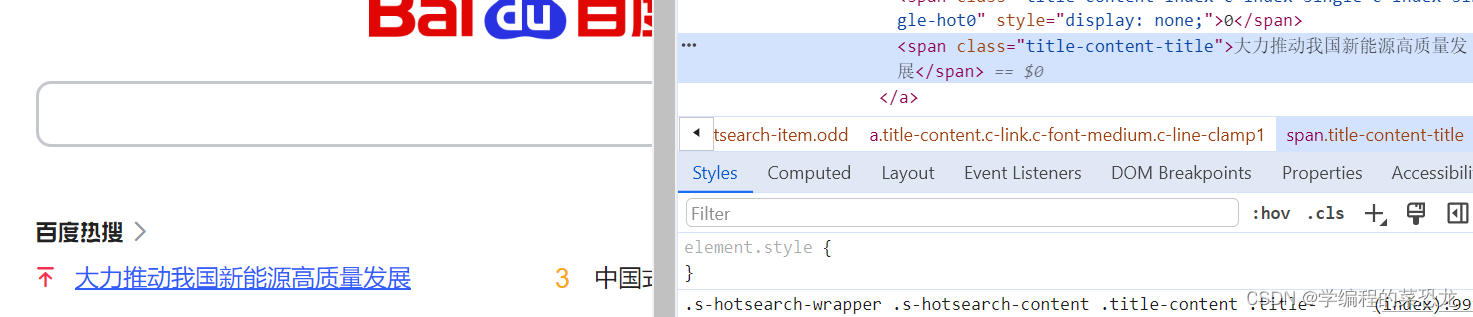
每个 WebElement 节点都有 text 属性,直接调用这个属性就可以得到节点内部的文本信息。
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.baidu.com/'
browser.get(url)
content = browser.find_element_by_class_name('title-content-title')
print(content.text)
browser.close()
# 输出:
# 大力推动我国新能源高质量发展5.3 获取 ID、位置、标签名、大小
上述同样的方法,找到获取节点,用属性即可。
节点.id
节点.location
节点.tag_name
节点.size本人新手,若有错误,欢迎指正;若有疑问,欢迎讨论。若文章对你有用,点个小赞鼓励一下,谢谢,一起加油吧!














 541
541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









