






一、概述
由于深度学习广泛的应用,深度学习模型的安全问题也受到普遍关注,模型算法的安全隐患更是加剧了被对抗样本欺骗以及隐私泄露等安全风险。
二、对抗攻击
以下介绍几个基本概念:
深度学习:深度学习是一种深层模型,利用多层非线性变换进行特征提取;由低层特性抽取出高层更抽象的表示。主要类型:循环神经网络、深度置信网络、卷积神经网络等。
对抗攻击:通过设计一种有针对性的数值型向量从而让机器学习模型做出误判,这便被称为对抗性攻击。
对抗样本:人为构造的样本。通过对正常样本x添加难以察觉的扰动ŋ,使得分类模型f对新生成的样本x’产生错误的分类判断。新生成的对抗样本为:x’=x+ŋ。同时:
![]()
可迁移性:类型:在同一数据集训练的不同模型之间的可迁移性、在不同机器学习技术之间的可迁移性、执行不同任务的模型之间的可迁移性。影响因素:模型类型、对抗样本的攻击力、非目标攻击比目标攻击更容易迁移、数据统计规律。
鲁棒性:(健壮性)控制系统在一定(结构,大小)的参数摄动下,维持其它某些性能的特性。
对抗样本产生的原因
①2014 年,Szegedy 等人[11]提出对抗样本位于数据流形的低概率区域由于分类器在训练阶段只学习局部子区域,而对抗样本的存在超出学习的子集,导致深度神经网络分类错误。如图,A类和B类分别表示不同的样本空间,由于模型训练所得的分类边界(曲线)与真实决策边界(直线)并不重合,在曲线与直线相交的区域出现的样本,会导致模型判断失误,曲线和直线包围的区域即为对抗区域。
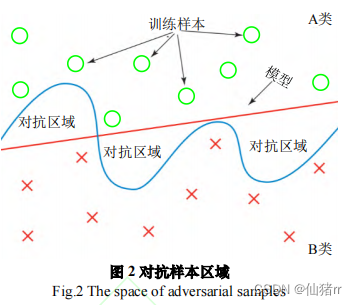
②2015 年,Goodfellow 等人[12]反驳了上述的观点,认为深度神经网络的脆弱性是由于模型的局部线型特性所导致。
③2017 年, Arpit 等人[31]通过分析神经网络对训练数据的记忆能力,发现记忆程度高的模型更容易受到对抗样本的影响。
④2018 年,Gilmer 等人[42-44]认为对抗样本的产生原因为数据流形高维几何结构产生,并在合成数据集的基础上对对抗样本与数据流形高维几何结构的关系进行分析论证。
三、对抗样本的攻击方式及目标
分类:
- 根据所获模型信息:
- 白盒攻击:攻击者了解攻击模型的详细信息,如数据预处理方法、模型结构、模型参数,某些
情况下攻击者还能够掌握部分或全部的训练数据信息。
- 黑盒攻击:攻击者不了解攻击模型的关键细节,攻击者仅能够接触输入和输出环节,不能实质性地接触到任何内部操作和数据。
- 根据攻击目标:
- 目标攻击:攻击者指定攻击范围和攻击效果,使被攻击模型不但把样本分类错误,并且把样本错误分类成指定的类别。
- 无目标/无差别攻击:攻击者的攻击目标更为宽泛,攻击目的只需要让被攻击模型对样本进行分类错误,但并不指定分类成特定类别。
- 普遍攻击:攻击者设计一个单一的转换(例如图像扰动),会对所有或者大多数输入值造成模型混乱的攻击。
四、对抗样本的生成方法
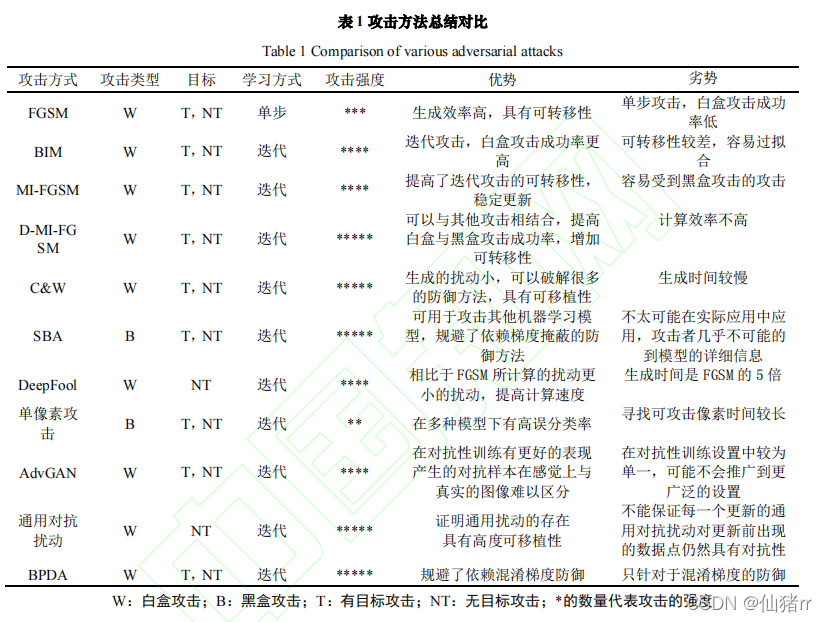
(一)快速梯度攻击(FGSM)
原文地址:https://arxiv.org/abs/1412.6572
原理:计算关于输入的损失函数的梯度,将一个选定的小的常数与梯度的符号向量相乘来产生一个小的扰动。
①在白盒环境下,通过求模型对输入的导数
②用符号函数得其梯度方向
③乘以一个步长,得到“扰动”
④攻击样本为原输入加“扰动”
公示如下:
![]()
ε表示调节系数,![]() 为相对于输入x损失函数的一阶导数。
为相对于输入x损失函数的一阶导数。
其中x是输入,x’是扰动后的输入,y是输出,L是损失函数,θ是模型参数,sgn是符号函数,ε为调节系数(步长)。
目的:使模型分类错误。增加“扰动”使模型的loss增大,利用loss对输入求导而“更新”输入。
注:神经网络通用模型学习方式基于反向传播的梯度调整权重来最小化损失loss;梯度攻击是通过调整输入数据以基于相同的方向传播梯度来最大化损失loss。
符号函数:限制扰动程度,使得扰动处在某个阈值(输入梯度方向已定)。
- 大于阈值的部分减短到阈值
- 小于阈值的部分提升到阈值
神经网络的可攻击性:
- 扰动造成的影响在神经网络中会不断积累变大,尤其是线性模型(这里的神经网络倾向于使用Relu这种类线性的激活函数)。
- 输入的维度越大,模型越容易受到攻击。
例:加入了扰动的样本使得左图的熊猫被错误的分类为长臂猿。这种方法在各个维度上移动相同大小的一步,虽然一步很小,但每一个维数的效果加在一起,通常也足以对分类器的判别结果产生很大的影响。

(二)基本迭代方法(BIM,I-FGSM)
原文地址:
原理:在快速梯度攻击中,若目标损失函数J(x,y)与x之间是近似线性的,要使目标损失函数J(x+ŋ,y)- J(x,y)最大,直接使ŋ=ϵ∗sign(∇x J(x,y))最大;若线性假设不成立,则J和x不是线性的,在( 0 ,ϵ∗sign(∇x J(x,y))) 之间存在一个使得J增大时,x的修改量较小的扰动。于是采用迭代的方式寻找每个像素点的扰动,每次在上一步的对抗样本基础上,各个像素点增长(或减少)α,然后再进行裁剪(为保证每个新样本的个像素在x和ϵ领域内,溢出的值用0或1代替),使得可能在各个像素点变化小于ϵ的情况下找到对抗样本(若找不到则效果退回FGSM)。
公式如下:
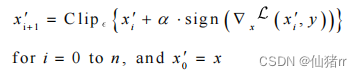
目的:得到更精准的扰动,攻击效果更好,但是计算代价更高,可移植性下降。
扩展:迭代最小似然类方法(ILCM算法)。将输入的图像分类为原本最不可能分类到的类别,主要在BIM基础上进行了两处修改,一个是α前面加号变成减号,一个是将原本真实的标签改为最不可能的类别标签。
BIM: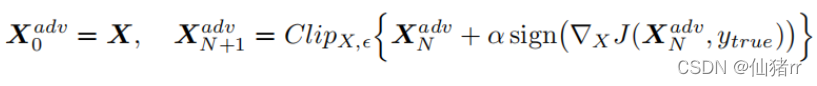
ILCM:

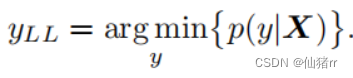
实验对比:ILCM的攻击效果最好,改动最小。
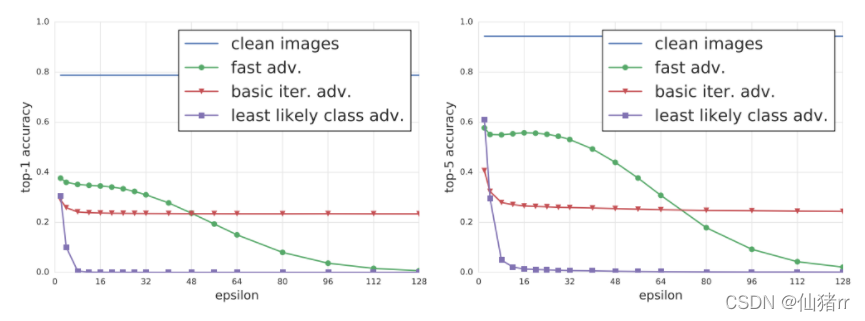
(三)动量迭代的快速梯度方法(MI-FGSM)
原文链接:https://arxiv.org/abs/1710.06081
原理:基于动量的方法通过在迭代过程中沿着损失函数的梯度方向累积速度矢量来加速梯度下降算法的技术,稳定更新方向并避免出现不良的局部最大值。
由于失真导致线性假设可能不成立,使得FGSM生成的对抗样本不足于模型,限制了其攻击能力;而对于I-FGSM在每次迭代中将对抗样本沿梯度符号的方向贪婪的移动,导致对抗样本很容易掉进不良局部最大值并“过拟合”模型,极大的降低了模型的可移植性。
将动量整合到I-FGSM中,以稳定更新方向并避免出现差的局部最大值。当增加迭代次数时,基于动量的仍然可以保持对抗样本的可传递性,同时对于像I-FGSM这样的白盒攻击也具有很强的对抗性。其减轻了攻击能力和可传递性之间的折衷,证明了强大的黑盒攻击。
公式如下:
gt使用等式(6)中定义的衰减因子μ收集前 t 次迭代的梯度。如果μ=0,则MI-FGSM退化为I-FGSM。每次迭代,当前梯度∇x J(xt*,y)通过自身的L1距离(任何距离度量都是可行的)进行归一化,因为我们注意到不同迭代中梯度的大小在大小上有所不同。

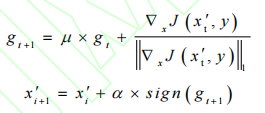
目的:大多数现有的对抗攻击攻击黑箱模型的成功率很低。基于动量的迭代算法可以增强对抗性攻击,通过将动量项整合到攻击的迭代过程中,可以稳定更新方向,并在迭代的过程中摆脱不良局部最大值,从而产生更具可传递性的对抗样本。进一步提高黑盒攻击的成功率。
攻击集成模型:
向量范数:





(四)基于多样性的快速梯度攻击
(五)C&W攻击
(六)替代黑盒攻击
(七)DeepFool攻击
(八)单像素攻击
(九)AdvGAN攻击
(十)通用对抗扰动
五、对抗防御
对抗防御主要分为对抗攻击检测和提高模型鲁棒性两个方法。
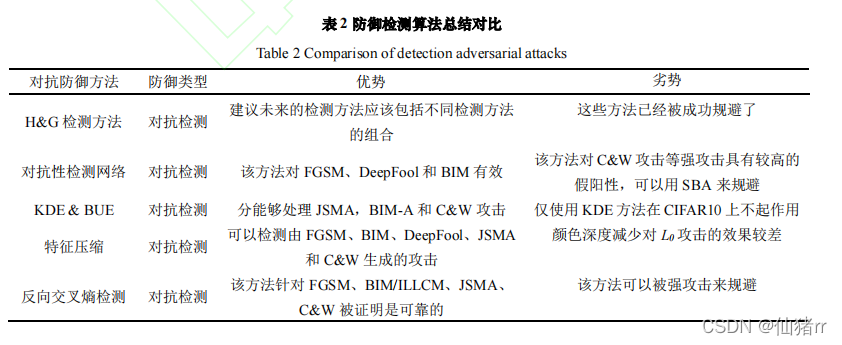
对抗攻击的检测
(一)H&G检测方法
(二)对抗性检测网络
(三)核密度法和贝叶斯不确定性估计法
(四)特征压缩
(五)逆交叉熵检测
对抗攻击的防御
目前主流防御方法主要为以下四类:
(一)数据扩充
①对抗训练
②映射梯度下降对抗训练
③综合对抗训练
④逻辑配对防御机制
(二)预处理方法
①去噪特征映射
②综合分析
③ME-Net
④总方差最小化和图像拼接
⑤温度计编码防御方法
(三)正则化方法
(四)数据随机化处理

六、对抗样本应用实例
(一)利用对抗样本提高图像识别准确率(AdvProp方法)
(二)利用对抗性特征解决超分辨率问题
(三)利用对抗扰动检测木马
七、值得研究的方向
①应用对抗样本技术作为数据增强的手段
②改进对抗训练
③研究除范数约束和对抗训练之外的攻击防御方法。
参考连接:https://blog.csdn.net/ilalaaa/article/details/106070091


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









