







文章目录
前言
只谈用法,不谈原理。
一、数据库
点击云开发:
点击数据库:
进入到如下界面:
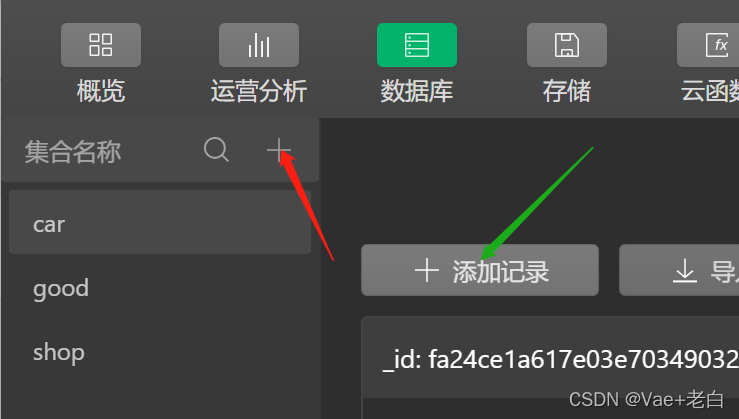
红色箭头:创建新的集合
绿色箭头:为当前集合手动添加一条数据
在云开发数据库中,一个集合就是一张表,表中的数据都是一条条json格式的数据。
集合的创建不需要像关系型数据库创建表一样指定字段名和约束:
表中的不同的记录不一定需要有相同的字段:


不同的记录中同名的字段可能类型也不相同:


可以注意到所有记录都有一个_id,显然这个是记录的主键,该字段一般有系统自动生成,在导入数据的时候,要注意导入的数据当中这个字段不能有重复。
二、编写云函数
创建云函数
右键点击:
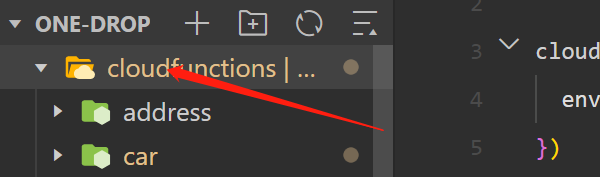
点击新建云函数:
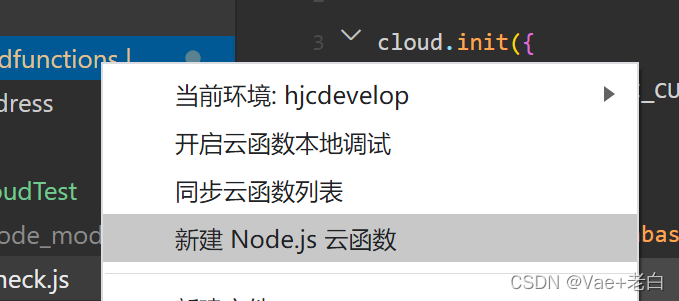
创建云函数后一般将里面代码修改成这样:
// 云函数入口文件
const cloud = require('wx-server-sdk')
cloud.init({
env: cloud.DYNAMIC_CURRENT_ENV
})
const db=cloud.database()//
const _ = db.command
const $ = _.aggregate
// 云函数入口函数
exports.main = async (event, context) => {
const wxContext = cloud.getWXContext()
//TODO--
return {
event,
openid: wxContext.OPENID,
appid: wxContext.APPID,
unionid: wxContext.UNIONID,
}
}
其中db为操作数据库的重要对象
使用db配合云开发提供API的进行拼接,再使用await进行调用可以实现像SQL语句一样对数据库进行操作
使用await 调用db拼接的语句后有返回值,获取返回值的方式有两种:
一:使用变量接
var res= await db.collection('user').get()
二:使用回调函数
await db.collection('user').get()
.then(res=>{
})
注意:回调函数里面不能使用await操作,当你有两次await 操作,第二次操作与第一次操作的返回值有关,第一次操作尽量使用第一种方式,简单来说,这样使用会报错(详细原因自己查)。
await db.collection('user').get()
.then(res=>{
await db.collection('user').get()
})
简单CRUD操作
//1、查询
await db.collection('user').get()
.then(res=>{
//返回值的数据在res.data当中,其类型是数组
if(res.data.length>0){
}
})
//相当于 Select * from user
//2、删除
await db.collection('user').remove()
//相当于 delete from user where 1 = 1
//3.添加
await db.collection('user').add({
data:{
username:'szu',
password:'123'
}
})
//4、更新
await db.collection('user').update({
data:{
username:'szu',
password:'123'
}
}).then(res=>{
//更新是否成功在res.stats.updated中
if(res.stats.updated>0){
}
})
//相当于update user set username='szu',password='123' where 1 = 1
//5、计算记录条数
await db.collection('user').count()
.then(res=>{
//返回值的数据在res.total当中,其类型是数组
if(res.total>0){
}
})
//相当于 Select count(*) from user
复杂条件查询
等值查询:
await db.collection('user')
.where({
username:'szu',//字段之间是AND关系
password:'123'
})
//.where(_.or([//字段之间是OR关系
//{
// username:'szu'
//},
//{
// password:'123'
//}
//]))
.field({
username:true,//用于筛选字段
password:true
})
.orderBy('username', 'desc')//依据多个条件排序的时候,多拼接几次
.orderBy('password', 'asc')
.skip(1)//就像是sql中的limit(1,10)
.limit(10)
.get()
.then(res=>{
//返回值的数据在res.data当中,其类型是数组
if(res.data.length>0){
}
})
比较查询
command操作符
await db.collection('user')
.where({
age:_.gte(18)//年龄大于等于18
})
.field({
username:true,//用于筛选字段
password:true
})
.get()
常见逻辑操作:
_.and([…]):
_.or([…]):
_.not():
常见比较相关操作:
_.eq():等于
_.neq():不等
_.lt():小于
_.lte():小于等于
_.gt():大于
_.gte():大于等于
_.in([…]):存在
_.nin([…]):不存在
另外除了用where还可以用doc来查询,不过doc参数为记录的主键_id,实际上就是selectById操作,使用的相对较少。
await db.collection('user')
.doc(userID)
.field({
username:true,//用于筛选字段
password:true
})
.get()
aggregate操作符
await db.collection('user')
.where(_.expr($.and([
$.gt(['$age', 18])
])))
.field({
username:true,//用于筛选字段
password:true
})
.get()
常见逻辑操作:
$.and([…]):
$.or([…]):
$.not():
常见比较相关操作:
$.eq([’ $value ‘,’ $value ‘]):等于
$.neq([’ $value ‘,’ $value ‘]):不等
$.lt([’ $value ‘,’ $value ‘]):小于
$.lte(’ $value ‘,’ $value ‘):小于等于
$.gt([’ $value ‘,’ $value ‘]):大于
$.gte([’ $value ‘,’ $value ']):大于等于
$.in([…]):存在
$.nin([…]):不存在
这个套api可以用于更复杂的业务逻辑,"$field"可以获取某个字段的值。
详细的情况建议去查看一下微信开发者文档,还有很多其他的用法。
聚合查询
基本操作
看到这里,相比于SQL语句,很多功能都已经有了,但是之前的查询方式无法进行联表和分组,联表和分组需要通过聚合查询进行操作。
聚合查询常用模板:
await db.collection('good')
.aggregate()
.match({//与where用法相同
})
.sort({//根据字段排序,1为升序,-1为降序
age: -1,
score: -1
})
.project({//筛选字段
title: 1,
author: 1
})
.skip(1)//就像是sql中的limit(1,10)
.limit(10)
.end()
.then(res=>{
//返回值在res.list,当中,类型为数组
if(res.list.length>0){
}
})
联表操作
一个字段的Join:
//进行联表操作
await db.collection('good')
.aggregate()
.match({//与where用法相同
})
.lookup({
from: 'shop',
localField: 'shopID',//当前表的字段名
foreignField: '_id',//对应另一个表字段名
as: 'shopInfo',
})
//注意到这里生成的字段ShopInfo字段是一个数组,这里保证里面最多只有一个元素
.unwind("$shopInfo")//这里由于shopInfo只有一个元素,将数组解开,将数组字段变成Object
.end()
.then(res=>{
//返回值在res.list,当中,类型为数组
if(res.list.length>0){
}
})
解释一下:
首先是查询到good表的数据,对于good表的每一条数据,使用该记录的goodID字段与shop表当中_id字段进行equal Join,将shop表中相等的记录(上述写法由于_id是主键,最多只会有一条记录,在一些条件下有可能是多条)放到该记录的一条新的数组字段shopInfo当中,再使用unwind解数组,解数组就是将原本只有一个元素的数组类型的shopInfo变成Object类型,其值就是原本shopInfo当中仅有的那个元素。
多个字段的Join:
//进行联表操作
await db.collection('good')
.aggregate()
.match({//与where用法相同
})
.addFields({//good表中没有userID,我先加一个
userID:"This is a UserID"
})
.lookup({
from: 'shop',//联shop表
let: {//这里是主流水线和次流水线进行数据传递的地方
shopID: '$shopID',
userID: '$userID'
},
pipeline: $.pipeline()//这里也是一个流水线
.match(_.expr($.and([
$.eq(['$shopID', '$$shopID']),
$.eq(['$userID', '$$userID']),
$.eq(['$disable', false])
])))
.done(),//流水线处理结束,将结果封装到shopInfo中
as: 'shopInfo',
})
.end()
.then(res=>{
//返回值在res.list,当中,类型为数组
if(res.list.length>0){
}
})
这个Join的方式有点难理解,首先我们知道,我们的聚合操作最终的返回值是一个数组,使用lookup进行联表操作之后,得到的数据也是以数组的形式存在于一个字段当中。而我们使用聚合操作也就是主流水线是针对good表的流水线操作,而lookup则是新开一个针对shop表的流水线操作,将shop表的产物又汇总到原来good表的流水线中。
这个多个字段的join操作,实际上是在主流水线的基础上,再开一个针对shop表的操作,上面的let{…}是用于将原本good表中的一些信息,传送到shop流水线,用作筛选数据的条件。筛选的语法方式与前面条件查询使用$.xxx那套api相同
上述代码结合需求理解:
我希望找出这个商品所属商店,并且商店的所属用户(字段userID)是userID的数据。
那么我在lookup之前,先添加了一个userID的字段,随后将userID和shopID传递给处理shop表的流水线,找出shop表中满足userID和shopID与我传递过去的相等的数据。最后shop表结果封装到shopInfo当中。
分组操作(groupby)
下面这段代码就是计算good表中所有价格大于10的商品:
await db.collection('good').aggregate()
.match({
price:_.gte(10)
})
.group({
_id: null,
total: $.sum(1)
})
.end()
.then(res=>{
//返回值在res.list,当中,类型为数组
if(res.list.length>0){
var totalAmount=res.list[0].total
}
})
这段代码则是计算每个年级的平均分
await db.collection('final_grade')//期末成绩表
.aggregate()
.group({
_id: "$grade",//按照年级
avgScore: $.avg("$score")//分数
})
.end()
.then(res=>{
//返回值在res.list,当中,类型为数组
if(res.list.length>0){
var totalAmount=res.list[0].total
}
})
上面那个_id就是指定你需要groupby的字段。
如果groupby需要多个字段,则如下:
这段代码则是计算每个年级的平均分,按照男女分开
await db.collection('final_grade')//期末成绩表
.aggregate()
.group({
_id: {
"$grade",//按照年级
"$gender"
}
avgScore: $.avg("$score")//分数
})
.end()
.then(res=>{
//返回值在res.list,当中,类型为数组
if(res.list.length>0){
}
})
聚合操作小结
聚合操作实际上是一种流水线操作,在.aggregate()到.end()之间的操作都可以重复出现(可以多次match,多次lookup…),一点一点打磨拼接,直到加工出自己想要的数据。
查询语句动态拼接
普通查询语句和聚合查询语句是可以动态拼接的,
举个例子:
如果用户输入0,我就把数据库所有的数据全部查询出来,如果,输入时大于0的数字,则把status字段值等于该数字的记录查询出来。
var tmpDB = db.collection('order').aggregate()
.match({
disable:false
})
if (input > 0) {
tmpDB = tmpDB.match({
status: input
})
}
var res=await tmpDB.end()
同理,使用where也可以动态拼接,但有点不同:
var tmpDB = db.collection('order').
.where({
disable:false
})
if (input > 0) {
tmpDB = tmpDB.where({
disable:false,//不同
status: input
})
}
var res=await tmpDB..get()
聚合操作中,多次使用match时叠加效果,而在普通查询操作,多次使用where则是覆盖操作。
查询语句重复利用
例如,我们要实现分页查询,我们希望返回该页码的数据的同时告诉前端这一页后面还有没有数据(hasMore),因此需要通过数据库总记录数来计算得到。
var tmpDB = db.collection('order').
.where({
disable:false
})
var totalSize=await tmpDB.count()//计算总条数
var pageIndex = initInfo.pageIndex > 0 ? initInfo.pageIndex : 1;
var pageSize = initInfo.pageSize ? initInfo.pageSize : 10;
ret.hasMore = pageIndex >= Math.ceil(totalSize.total / pageSize) ? false : true
var res=await tmpDB.get()//获取数据
而由于聚合操作是一次性流水线操作,上个流水线结束后需要重新构建流水线,因此无法重复利用。
开启事务的两种方式
//第一种:
try{
const transaction = await db.startTransaction()
//TODO--
await transaction.commit()
}catch(err){
await transaction.rollback(-100)
}
//第二种:
try{
const result = await db.runTransaction(async transaction => {
//TODO
})
}catch(err){
await transaction.rollback(-100)
}
注意事项:
1、开启事务后,希望被事务管理的操作(一般是增删改操作)使用await transaction.collection(‘test’)…,而不需要被事务所管理的部分使用await db.collection(‘test’)…也可以使用,换句话说,当触发回滚的时候只有await transaction.collection(‘test’)…的部分会回滚。
2、事务操作是能针对单个数据,换句话说在事务操作里不能使用where,只能使用doc,而且不能使用聚合操作。
云开发数据库的高级操作
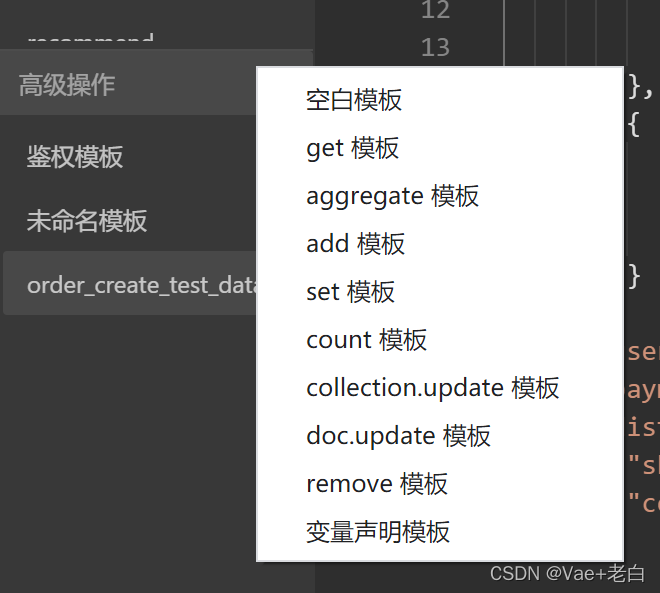
点击旁边加号可以添加模板,一般写接口的时候可以现在这里将主要功能写好,再将其移到云函数当中做进一步完善。
三、 云函数部署和更新
将云函数写好之后,右键点击,将云函数上传并部署到云端:
 实际开发中都是一个云函数有很多个文件,每次有修改都上传全部云函数耗费时间太多,一般修改一个文件之后直接右键点击该文件增量上传(记得保存再上传):
实际开发中都是一个云函数有很多个文件,每次有修改都上传全部云函数耗费时间太多,一般修改一个文件之后直接右键点击该文件增量上传(记得保存再上传):

四、调试
右键点击一个云函数开始本地调试:

新创建的云函数需要安装node modules,点击确定并等待其完成。
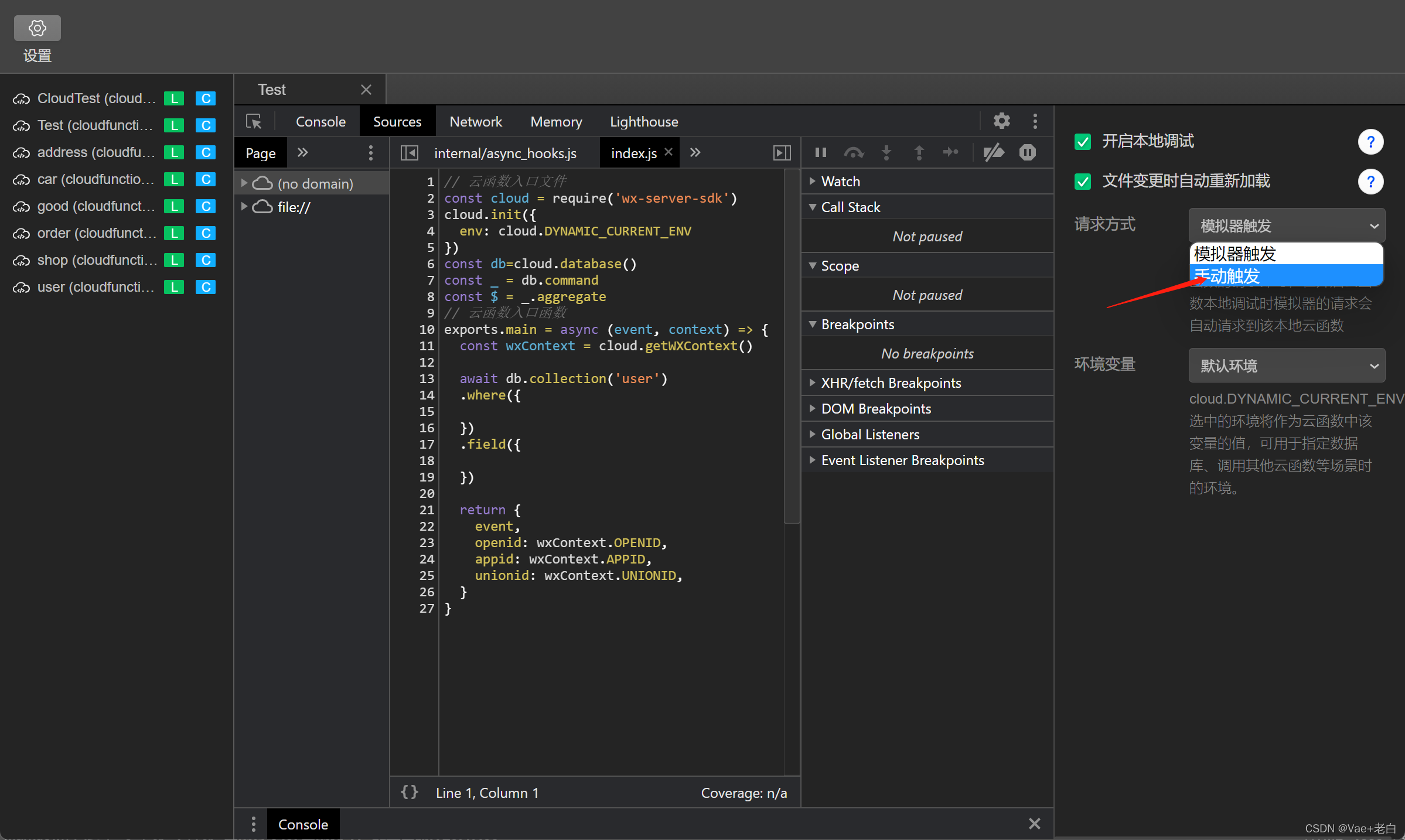
点击手动触发:
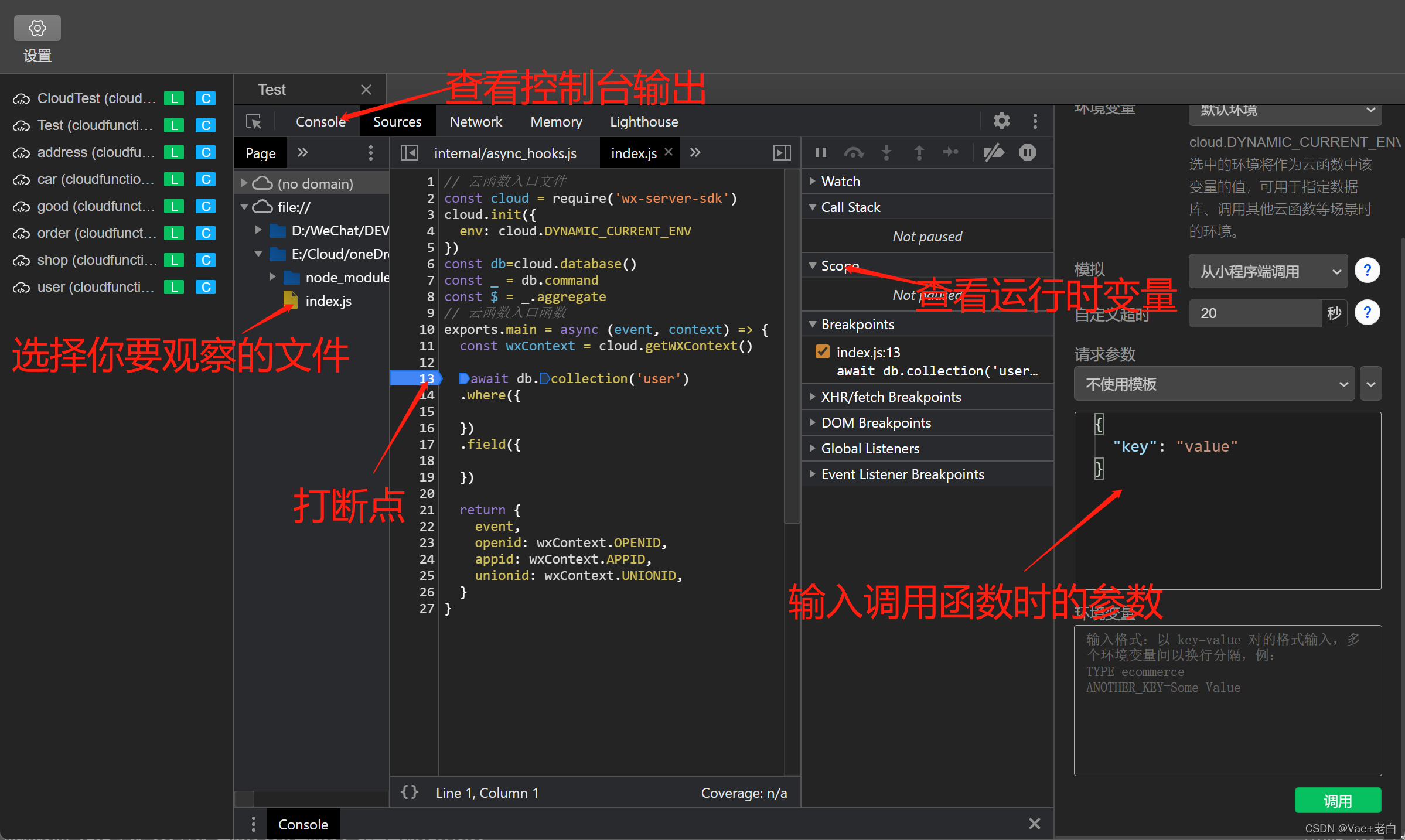
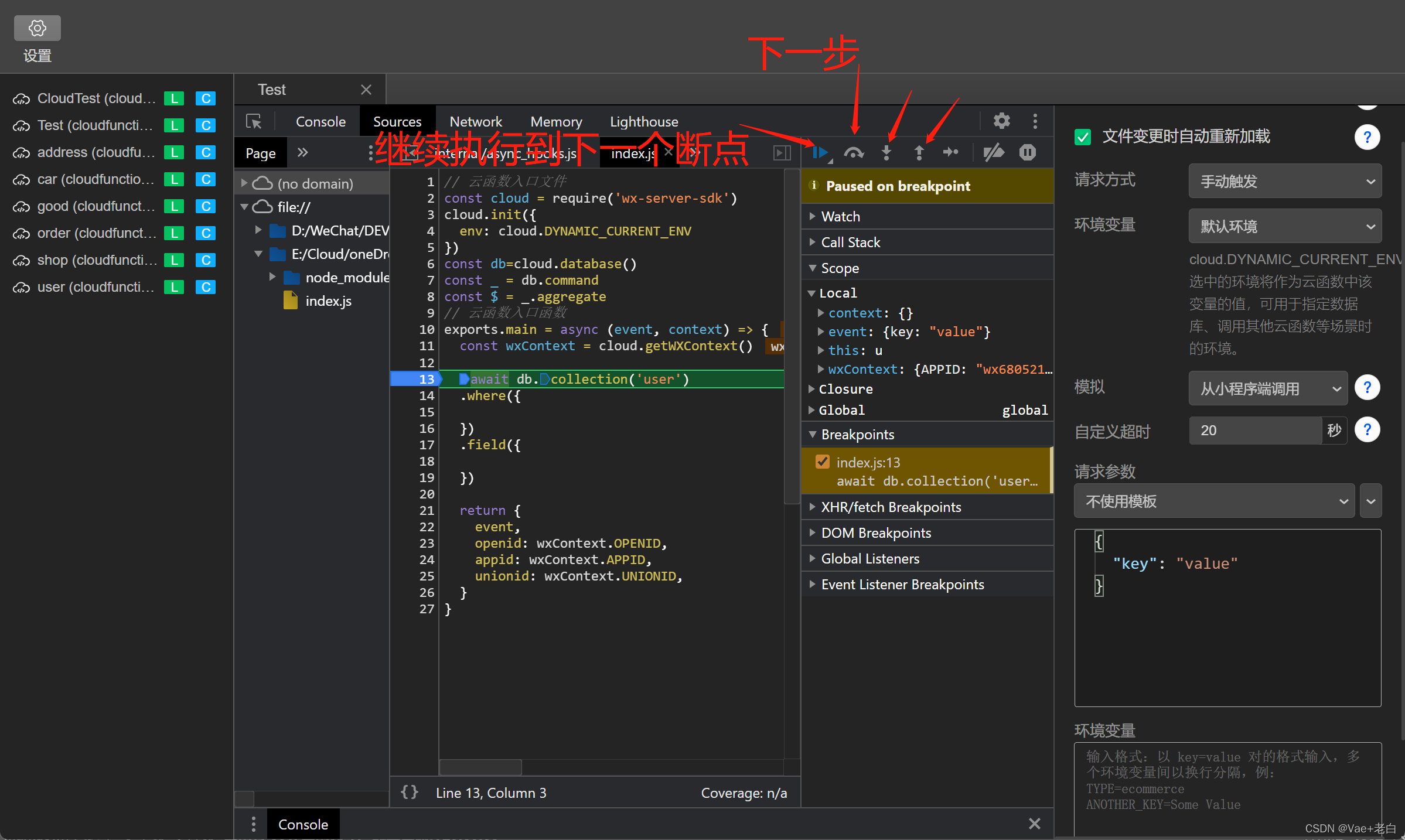
调试发现问题之后,到原文件中修改,点击保存(先不需要上传到云端),再次进入到本地调试中可以继续调试修改后的文件,当调试结束,所有功能准确无误的时候,再将文件更新至云端。
还有一个无法开启本地调试的问题。
当某一次你打开本地调试发现出错的时候:
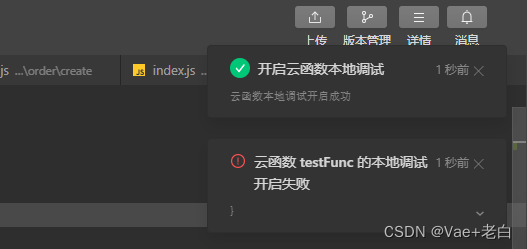
并且这里一片空白:
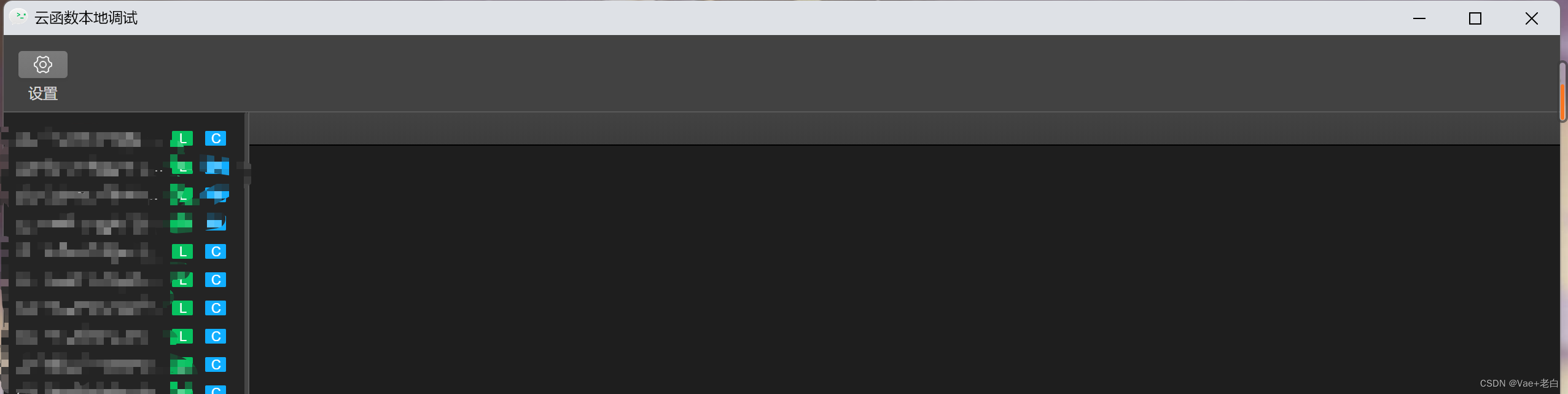
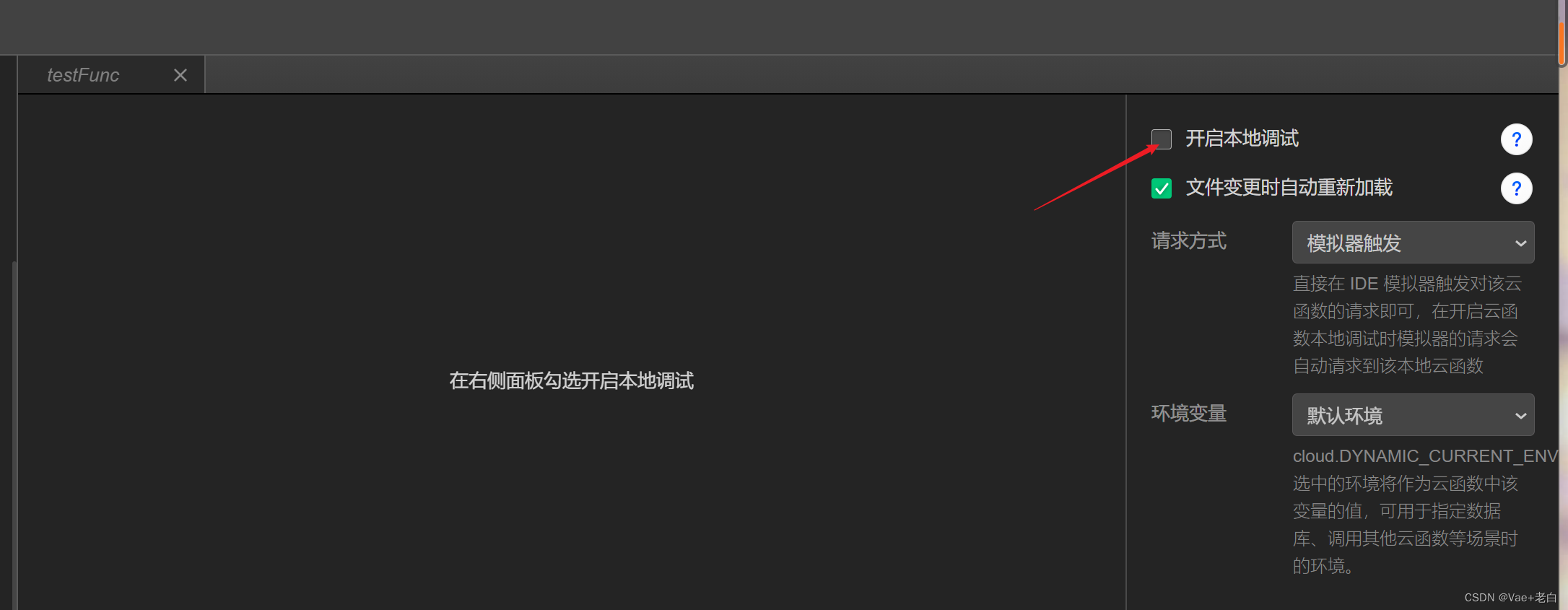
在左侧栏目中找到你想要调试的云函数,点击后进入如下界面,点击开启本地调试:
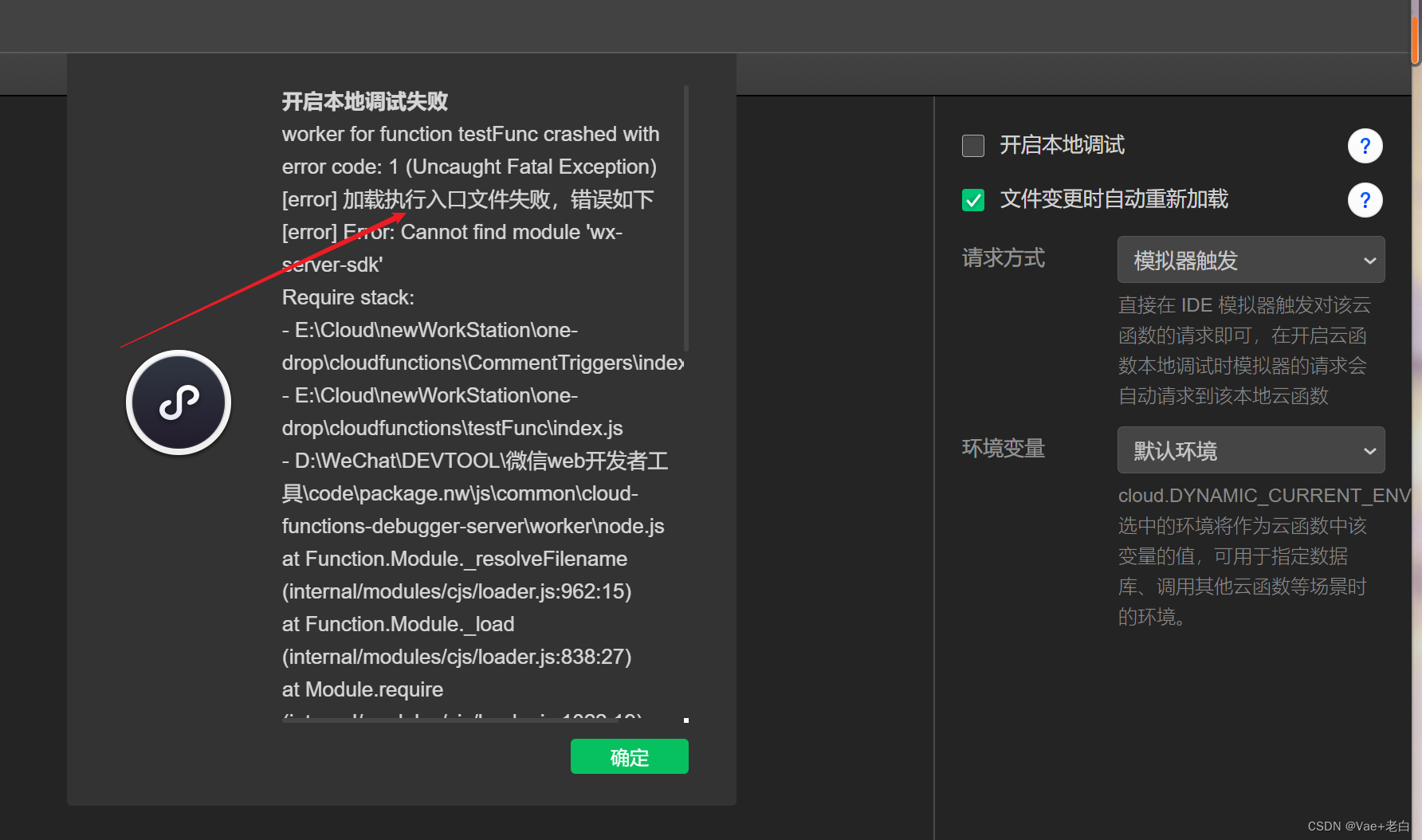
随后你可以看到一些详细的错误,按照上面的错误进行修改即可。
五、总结
我这里讲的内容其实是少之又少,重要的是要多看文档,多练,才能得心应手。
遇到复杂的需求要学会查文档:
云卡发->开发者资源->往下拉
微信云开发文档
遇到疑难杂症就到交流社区需求帮助:
小程序交流社区

















 1874
1874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









