






Intro: 一些废话
大家都知道,有的网站进行post请求的时候需要带上参数,确认登录状况。之前一直碰到的情况是Headers里面需要Cookie参数,同时payload中带上一串加密代码,一般是bs64加密。
最近进行爬虫的时候发现了Authorization这种情况,发起请求时不带Cookie,而是在headers里面带上Authorization参数,json data中是请求参数。以往碰到需要JS加密需要逆向解密的爬虫,我都是急流勇退选择转用selenium了,然而这次发现久不用selenium,它竟然升级了,变得比较复杂。同时也因为Authorization这种授权的方式导致加载Cookie进行登录的方式失效,利用Selenium更需要滑动验证码一连串复杂指令,还是requests更加方便。
分析思路
首先是发现Authorization这个参数可以使用一段时间。这个无需多言,把抓包到的headers参数全部带上,不要偷懒就能运行一段时间。大概15分钟之后,token失效,这时返回的内容为“token expired”。
这时候我在网页端随意点选了一个(注意不是刷新页面!),让动态页面加载更新的东西从而生成新的Authorization,然后我发现抓包界面显示了一个“refresh”的请求,这就是突破口!
多说一句,这个refresh请求需要一些耐心,因为网页端很难自然refresh,所以最好是先写一段代码用原始的有效的Authorization运行,直到它返回token expired,再去网页端点选,创造捕捉refresh的条件。
如图所示就是这个refresh请求的内容,这里终于用到了Cookie
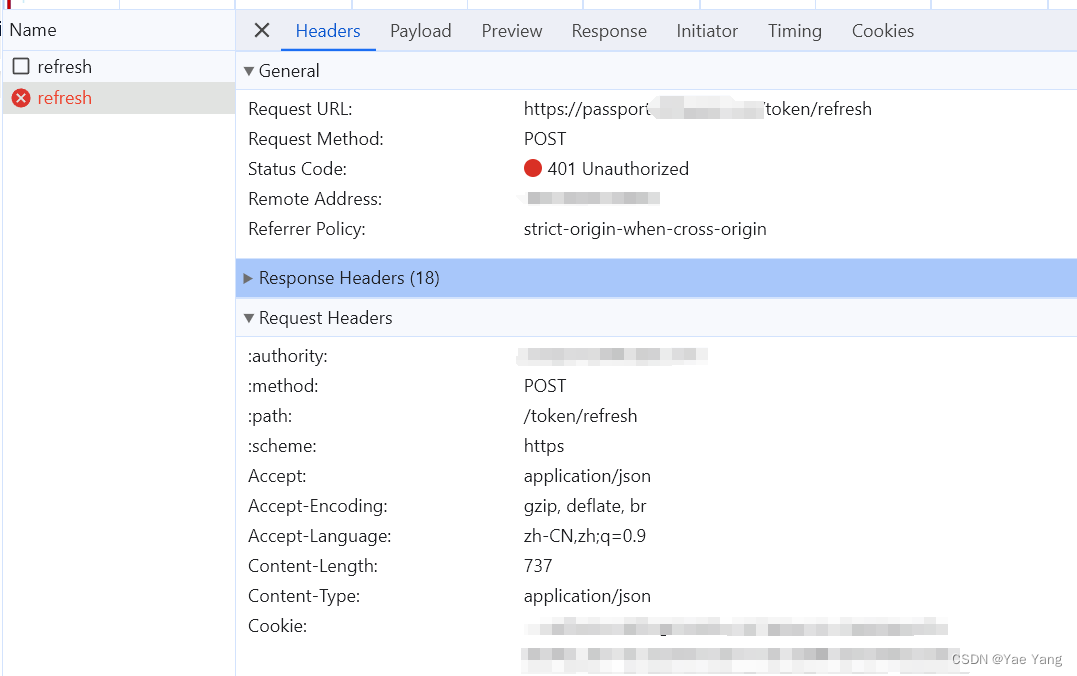
它的返回值为:
{"refresh_token":"...","token":"..."}
经过尝试和分析,可知refresh_token是用于payload发起下一次refresh请求,而token则是用于构造Authorization参数
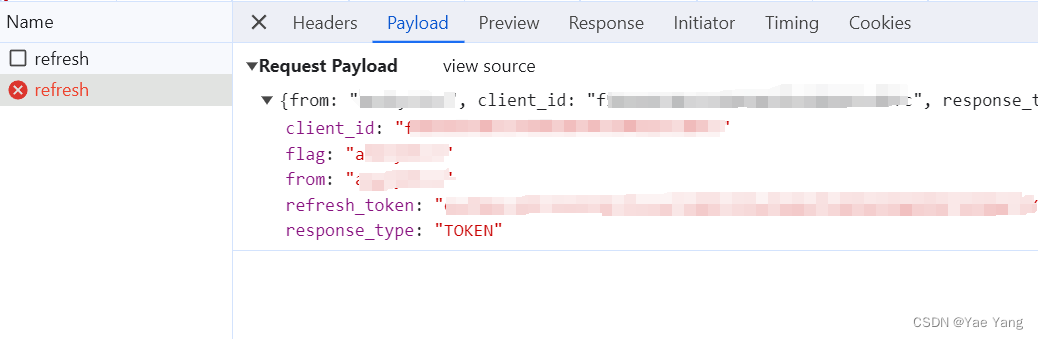
验证猜想
写了一串代码来验证我的思路对了没:
# 测试refresh参数
import requests
import json
from lxml import etree
def get_token(token_refresh):
url = 'https://.../token/refresh'
# headers参数全部用浏览器复制的,不知道这样的爬虫会不会有法律问题,所以我都省略了,请见谅
headers = {
'authority': 'passport. ... .com',
'method': 'POST',
'path': '/token/refresh',
'scheme': 'https',
'Accept': 'application/json',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Content-Length': '737',
'Content-Type': 'application/json',
'Cookie': '...',
'Origin': 'https://analytics. ... .com',
'Referer': 'https://analytics. ... .com/',
'Sec-Ch-Ua': '...',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': 'Windows',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'User-Agent': '...',
}
data = {
"from": "analytics",
"client_id": "...",
"response_type": "TOKEN",
"flag": "...",
"refresh_token": token_refresh, } # 这个是传入的参数
res = requests.post(url=url, headers=headers, json=data)
content = etree.HTML(res.content)
# print(content)
content_s = etree.tostring(content).decode().replace('\n', '').replace('<html><body><p>', '').replace(
'</p></body></html>', '').replace('b{', '{').replace(' ', '')
parse = json.loads(content_s)
print(content_s)
token = parse['token']
token_refresh_forNext = parse['refresh_token']
print(token)
print(token_refresh_forNext)
return token, token_refresh_forNext
if __name__ == "__main__":
token,token_refresh = get_token('第一个token传入浏览器复制的')
get_token(token_refresh)运行成功没有报错,也成功打印了新的token和refresh_token
另外一个惊喜发现就是refresh_token也是之前的有效Authorization中能提取出的,就能解决这个函数传入的第一个参数的来源了。
分析思路 续
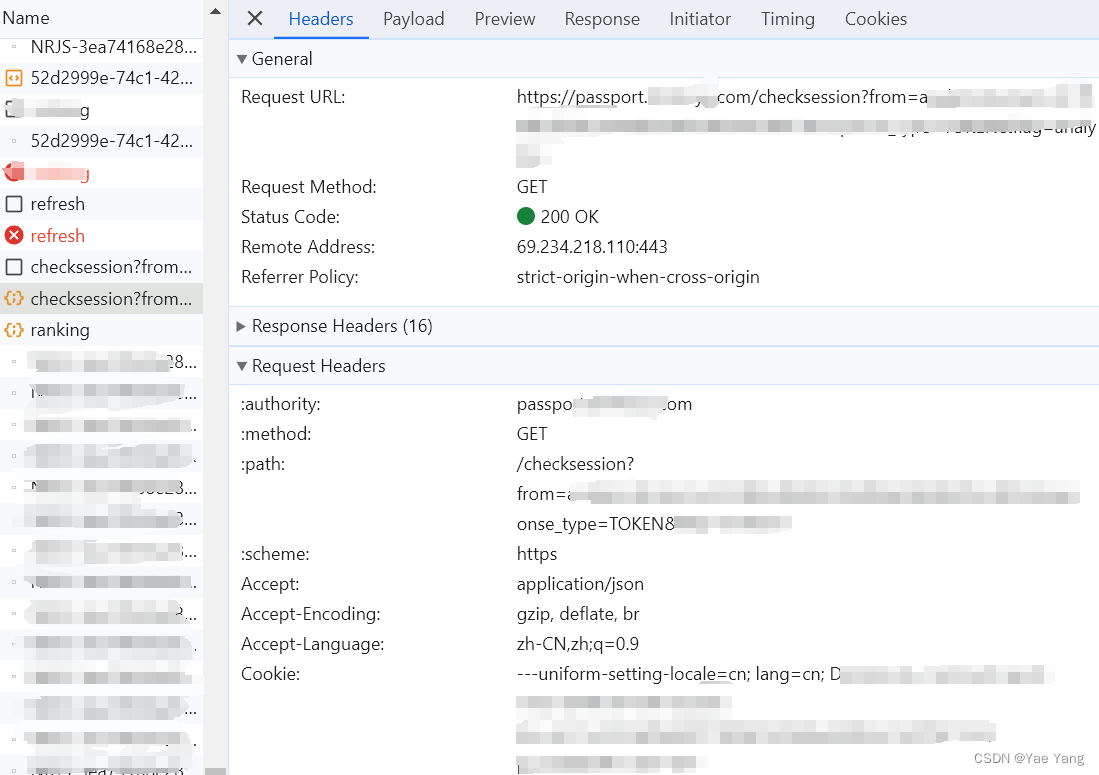
后面我写完整代码的时候,发现有时候对refresh发起请求也会报错,错误代码是:{errcode: "30405"}。这次还是依葫芦画瓢在网页端点选一次(是的,浏览器里那个页面我一直没关),这次捕捉到了一个全新的页面:checksession(如图)
可以看到是一个get请求,需要加载json data,但里面不像refresh一样需要refresh_token,response里生成refresh_token和token,这点同refresh页面。小小总结一下就是这个checksession也能用于生成token,而且限制变少了,携带的变量参数只有一个可能会更新的Cookie参数。
问题解决
这样一来,JS逆向解密的过程就被简化为自行请求refresh,得到新生成的token,并构造新的Authorization,实现爬虫了,完美!
保留声明
弱弱地说一句,因为担心逆向爬虫会有legal问题,所以我就不放是哪个网站了,因此有些说不清楚的问题欢迎大家来交流!此文章仅提供思路!

















 1178
1178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









