







NumPy 数组基础笔记
1. 理解数组的维度 (Dimensions)
NumPy 数组的维度 (Dimension) 或称为 轴 (Axis) 的概念,与我们日常理解的维度非常相似。
直观判断: 数组的维度层数通常可以通过打印输出时**中括号 `[]` 的嵌套层数**来初步确定:
一层 [ ]: 一维 (1D) 数组。
两层 [ ]: 二维 (2D) 数组。
三层 [ ]: 三维 (3D) 数组,依此类推。
2. NumPy 数组与深度学习 Tensor 的关系
在后续进行频繁的数学运算时,尤其是在深度学习领域,对 NumPy 数组的理解非常有帮助,因为 PyTorch 或 TensorFlow 中的 Tensor 张量本质上可以视为支持 GPU 加速和自动微分的 NumPy 数组。掌握 NumPy 的基本操作,能极大地降低学习 Tensor 的门槛。关于 NumPy 更深入的性质,我们留待后续探讨。
3. 一维数组 (1D Array)
一维数组在结构上与 Python 中的列表(List)非常相似。它们的主要区别在于:
打印输出格式:当使用 print() 函数输出时:
NumPy 一维数组的元素之间默认使用空格分隔。
Python 列表的元素之间使用**逗号**分隔。
示例 (一维数组输出):
[7 5 3 9]
4. 二维数组 (2D Array)
二维数组可以被看作是“数组的数组”或者一个矩阵。其结构由两个主要维度决定:
行数:代表整个二维数组中包含多少个一维数组。
列数: 代表每个一维数组(也就是每一行)中包含多少个元素。
值得注意的是,二维数组不一定是正方形(即行数等于列数),它可以是任意的 n * m、 形状,其中 n 是行数,m 是列数。
5. 数组的创建
NumPy 的 array()`函数非常灵活,可以接受各种“序列型”对象作为输入参数来创建数组。这意味着你可以将 Python 的列表 (List)、元组 (Tuple),甚至其他的 NumPy 数组等数据结构直接传递给 np.array() 来创建新的 NumPy 数组。
数组的简单创建
import numpy as np
a = np.array([2,4,6,8,10,12]) # 创建一个一维数组
b = np.array([[2,4,6],[8,10,12]]) # 创建一个二维数组
print(a)
print(b)[ 2 4 6 8 10 12]
[[ 2 4 6]
[ 8 10 12]]
# 分清楚列表和数组的区别
print([7, 5, 3, 9]) # 输出: [7, 5, 3, 9](逗号分隔)
print(np.array([7, 5, 3, 9])) # 输出: [7 5 3 9](空格分隔) [7, 5, 3, 9]
[7 5 3 9]
a.shape # numpy中可以用shape来查看数组的形状(6,)
zeros = np.zeros((2, 3)) # 创建一个2行3列的全零矩阵
zerosarray([[0., 0., 0.],
[0., 0., 0.]])
ones = np.ones((3,)) # 创建一个形状为(3,)的全1数组
onesarray([1., 1., 1.])
# 顺序数组的创建
arange = np.arange(1, 10) # 创建一个从1到10的数组
arangearray([1, 2, 3, 4, 5, 6, 7, 8, 9])
数组的随机化创建
1. 在后续深度学习中,我们经常需要对数据进行随机化处理,以确保模型的泛化能力。
2. 为了测试很多函数的性能,往往需要随机化生成很多数据。
numpy随机数生成方法对比
| 方法 | 作用范围/分布 | 记忆口诀 | 典型应用场景 | 示例 |
| np.random.randint(a,b) | [a,b]整数 | "int"结尾表示整数 | 生成随机索引/标签 | np.random.randint(1,10) |
| random.random() | [0,1)浮点数 | 纯"random"最基础 | 简单概率模拟 | random.random() → 0.548 |
| np.random.rand() | [0,1)均匀分布 | "rand"=random+uniform | 蒙特卡洛模拟 | np.random.rand(3) → [0.2,0.5,0.8] |
| np.random.randn() | 标准正态分布 | 多一个"n"=normal | 数据标准化/深度学习初始化 | np.random.randn(2,2) → [[-0.1,1.2],[0.5,-0.3]] |
记忆技巧:
1. 看结尾:
"int" → 整数
"n" → 正态(normal)
2. 看前缀:
纯"random" → Python基础随机
"np.random" → NumPy增强版
3. 功能差异:
rand()和random()都是均匀分布,但rand()能直接生成数组
randn()生成的数据会有正有负,其他方法都是非负数
# 创建一个2*2的随机数组c,区间为[0,1)
c = np.random.rand(2, 2)
carray([[0.40396838, 0.67658735],
[0.11142565, 0.39165721]])
import numpy as np
np.random.seed(42) # 设置随机种子以确保结果可重复
# 生成10个语文成绩(正态分布,均值75,标准差10)
chinese_scores = np.random.normal(75, 10, 10).round(1)
# 找出最高分和最低分及其索引
max_score = np.max(chinese_scores)
max_index = np.argmax(chinese_scores)
min_score = np.min(chinese_scores)
min_index = np.argmin(chinese_scores)
print(f"所有成绩: {chinese_scores}")
print(f"最高分: {max_score} (第{max_index}个学生)")
print(f"最低分: {min_score} (第{min_index}个学生)")所有成绩: [80. 73.6 81.5 90.2 72.7 72.7 90.8 82.7 70.3 80.4]
最高分: 90.8 (第6个学生)
最低分: 70.3 (第8个学生)
import numpy as np
scores = np.array([5, 9, 9, 11, 11, 13, 15, 19])
scores += 1 # 学习一下这个写法,等价于 scores = scores + 1
sum = 0
for i in scores: # 遍历数组中的每个元素
sum += i
print(sum)100
数组的运算
1. 矩阵乘法:需要满足第一个矩阵的列数等于第二个矩阵的行数,和线代的矩阵乘法算法相同。
2. 矩阵点乘:需要满足两个矩阵的行数和列数相同,然后两个矩阵对应位置的元素相乘。
3. 矩阵转置:将矩阵的行和列互换。
4. 矩阵求逆:需要满足矩阵是方阵且行列式不为0,然后使用伴随矩阵除以行列式得到逆矩阵。
5. 矩阵求行列式:需要满足矩阵是方阵,然后使用代数余子式展开计算行列式。
import numpy as np
a = np.array([[1, 2], [3, 4], [5, 6]])
b = np.array([[7, 8], [9, 10], [11, 12]])
print(a)
print(b)[[1 2]
[3 4]
[5 6]]
[[ 7 8]
[ 9 10]
[11 12]]
print(a + b) # 计算两个数组的和[[ 8 10]
[12 14]
[16 18]]
print(a - b) # 计算两个数组的差[[-6 -6]
[-6 -6]
[-6 -6]]
print(a / b) # 计算两个数组的除法[[0.14285714 0.25 ]
[0.33333333 0.4 ]
[0.45454545 0.5 ]]
a * b # 矩阵点乘,ipynb文件中不使用print()函数会自动输出结果,这是ipynb文件的特性array([[ 7, 16],
[27, 40],
[55, 72]])
a @ b.T # 矩阵乘法,3*2的矩阵和2*3的矩阵相乘,得到3*3的矩阵array([[ 23, 29, 35],
[ 53, 67, 81],
[ 83, 105, 127]])
数组的索引
一维数组索引
arr1d = np.arange(10) # 数组: [0 1 2 3 4 5 6 7 8 9]
arr1darray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 1. 取出数组的第一个元素。
arr1d[0]0
# 取出数组的最后一个元素。-1表示倒数第一个元素。
arr1d[-1]9
# 3. 取出数组中索引为 3, 5, 8 的元素。
# 使用整数数组进行索引,可以一次性取出多个元素。语法是 arr1d[[index1, index2, ...]]。
arr1d[[3, 5, 8]]array([3, 5, 8])
# 切片取出索引
arr1d[2:6] # 取出索引为2到5的元素(不包括索引6的元素,取左不取右)array([2, 3, 4, 5])
# 取出数组中从头到索引 5 (不包含 5) 的元素。
# 使用切片 slice [:stop]
arr1d[:5]array([0, 1, 2, 3, 4])
# 取出数组中从索引 4 到结尾的元素。
# 使用切片 slice [start:]
arr1d[4:]array([4, 5, 6, 7, 8, 9])
# 取出全部元素
arr1d[:]array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 7取出数组中所有偶数索引对应的元素 (即索引 0, 2, 4, 6, 8)。
# 使用带步长的切片 slice [start:stop:step]
arr1d[::2]array([0, 2, 4, 6, 8])
二维数组索引
# 数组:
arr2d = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]])
arr2darray([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12],
[13, 14, 15, 16]])
索引顺序:在二维数组 arr2d 里,第一个索引值代表行,第二个索引值代表列。比如 arr2d[i, j] ,i 是行索引,j 是列索引。
# 取出第 1 行 (索引为 1) 的所有元素。
#
# 使用索引 arr[row_index, :] 或 arr[row_index]
arr2d[1, :]array([5, 6, 7, 8])
# 也可以省略后面的 :
arr2d[1]# 取出第 2 列 (索引为 2) 的所有元素。
# 使用索引 arr[:, column_index]
arr2d[:, 2]array([ 3, 7, 11, 15])
# 取出位于第 2 行 (索引 2)、第 3 列 (索引 3) 的元素。
# 使用 arr[row_index, column_index]
arr2d[2, 3]12
# 取出由第 0 行和第 2 行组成的新数组。
# 使用整数数组作为行索引 arr[[row1, row2, ...], :]
arr2d[[0, 2], :]array([[ 1, 2, 3, 4],
[ 9, 10, 11, 12]])
# 取出由第 1 列和第 3 列组成的新数组。
# 使用整数数组作为列索引 arr[:, [col1, col2, ...]]
arr2d[:, [1, 3]]array([[ 2, 4],
[ 6, 8],
[10, 12],
[14, 16]])
# 取出一个 2x2 的子矩阵,包含元素 6, 7, 10, 11。
# 使用切片 slice arr[row_start:row_stop, col_start:col_stop]
arr2d[1:3, 1:3]
array([[ 6, 7],
[10, 11]])
三维数组索引
arr3d = np.arange(3 * 4 * 5).reshape((3, 4, 5))
arr3d array([[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]],
[[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29],
[30, 31, 32, 33, 34],
[35, 36, 37, 38, 39]],
[[40, 41, 42, 43, 44],
[45, 46, 47, 48, 49],
[50, 51, 52, 53, 54],
[55, 56, 57, 58, 59]]])
# 选择特定的层
# 使用整数数组 [0, 2] 作为第一个维度 (层) 的索引
arr3d[1, :, :]array([[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29],
[30, 31, 32, 33, 34],
[35, 36, 37, 38, 39]])
arr3d[1, 0:2, :]array([[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]])
arr3d[1, 0:2, 2:4]array([[22, 23],
[27, 28]])
SHAP值的深入理解
现在重新审视一下之前的SHAP数组
# 先运行之前预处理好的代码
import pandas as pd
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings("ignore")
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('data.csv') #读取数据
# 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
# Home Ownership 标签编码
home_ownership_mapping = {
'Own Home': 1,
'Rent': 2,
'Have Mortgage': 3,
'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)
# Years in current job 标签编码
years_in_job_mapping = {
'< 1 year': 1,
'1 year': 2,
'2 years': 3,
'3 years': 4,
'4 years': 5,
'5 years': 6,
'6 years': 7,
'7 years': 8,
'8 years': 9,
'9 years': 10,
'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)
# Purpose 独热编码,记得需要将bool类型转换为数值
data = pd.get_dummies(data, columns=['Purpose'])
data2 = pd.read_csv("data.csv") # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:
if i not in data2.columns:
list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:
data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名
# Term 0 - 1 映射
term_mapping = {
'Short Term': 0,
'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True) # 重命名列
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表
# 连续特征用中位数补全
for feature in continuous_features:
mode_value = data[feature].mode()[0] #获取该列的众数。
data[feature].fillna(mode_value, inplace=True) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。
# 最开始也说了 很多调参函数自带交叉验证,甚至是必选的参数,你如果想要不交叉反而实现起来会麻烦很多
# 所以这里我们还是只划分一次数据集
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
# --- 1. 默认参数的随机森林 ---
# 评估基准模型,这里确实不需要验证集
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time # 这里介绍一个新的库,time库,主要用于时间相关的操作,因为调参需要很长时间,记录下会帮助后人知道大概的时长
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))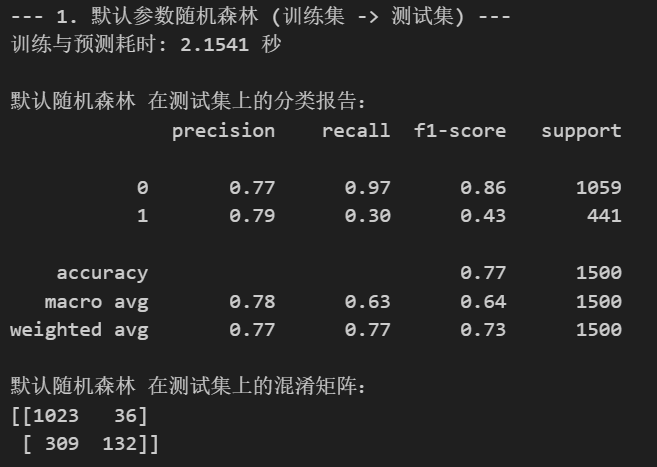
import shap
import matplotlib.pyplot as plt
# 初始化 SHAP 解释器
explainer = shap.TreeExplainer(rf_model)
# 计算 SHAP 值(基于测试集),这个shap_values是一个numpy数组,表示每个特征对每个样本的贡献值
shap_values = explainer.shap_values(X_test) # 这个计算耗时或许是因为我的shap版本不对,输出的shap_values是列表而非二维数组,所以在这里多进行一步转换
shap_array = np.array(shap_values)
shap_array_aligned = np.transpose(shap_array, axes=(1, 2, 0))
shap_array_aligned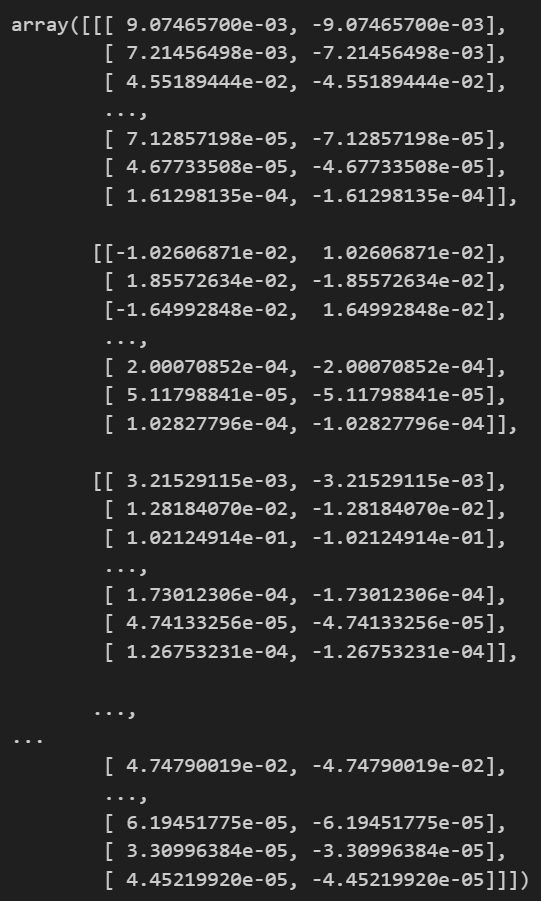
print("转换后形状:", shap_array_aligned.shape)转换后形状: (1500, 31, 2)
shap_array_aligned[0, :, :]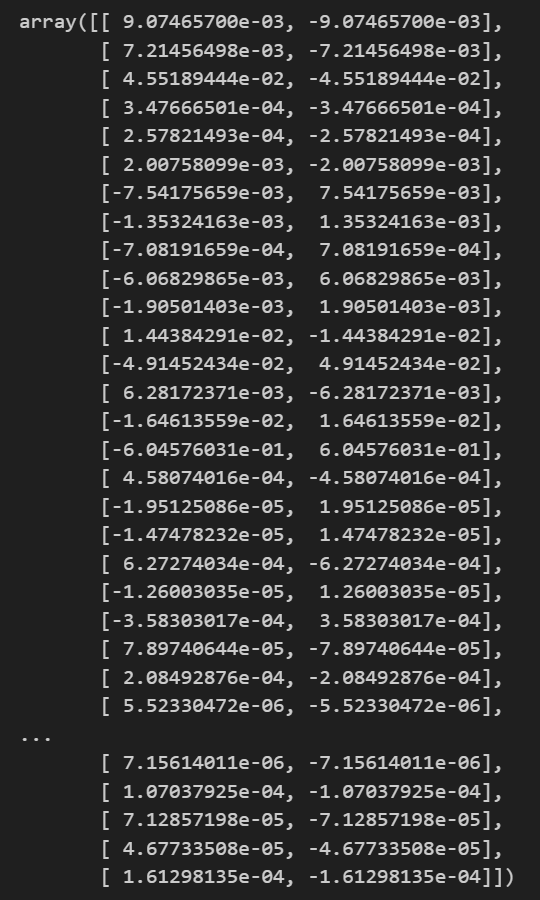
shap_array_aligned[0, :, :].shape(31, 2)
这个对应的是(特征数,类别数目)----每个特征对2个目标类别的shap值贡献
所以这个值对应的就是这个样本对应的这个特征对2个目标类别的shap值贡献
# 三个维度
# 第一个维度是样本数
# 第二个维度是特征数
# 第三个维度是类别数
shap_array_aligned.shape(1500, 31, 2)
# 比如我想取出所有样本对第一个类别的贡献值
shap_array_aligned[:,:,0]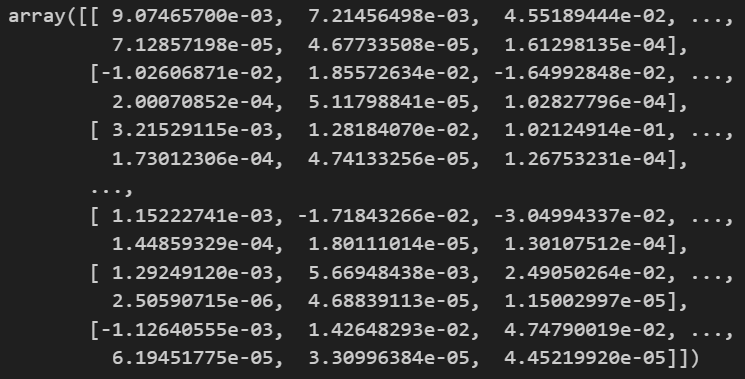
此时可以理解为什么shap.summary_plot中第一个参数是所有样本对预测类别的shap值了。
传入的 SHAP 值 (shap_array_aligned[:,:,0]) 和特征数据 (X_test) 在维度上需要高度一致和对应。
shap_array_aligned[:,:,0] 的每一行代表的是 一个特定样本每个特征对于预测类别的贡献值(SHAP 值)。缺乏特征本身的值
X_test 的每一行代表的也是同一个特定样本的特征值。
这二者组合后,就可以组合(特征数,特征值,shap值)构成shap图的基本元素


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









