







问题发现
上一篇在这里:gensim进阶:TFIDF模型训练以及查找具体词汇的tfidf值_tfidfmodel-CSDN博客文章浏览阅读3.8k次,点赞4次,收藏24次。经过整整一天的不懈奋斗,我终于破解了gensim的语料导入!首先把完整的训练模型和保存的代码放上:from gensim import modelsfrom gensim import corporafrom gensim.models import TfidfModelwith open("文件.txt","r",encoding='utf-8') as f: txts = eval(f.read()) # 用eval()把字符串化的列表还原为列表dictionary = _tfidfmodelhttps://blog.csdn.net/weixin_51143561/article/details/122541859?spm=1001.2014.3001.5502训练模型时设置参数为normalize=False,查询tfidf值也是通过doc_name, id和tf进行曲折的查询。
这一次我又拿新的数据训练了一个模型,虽然注意到了normalize的参数,但这次并没有设置参数,因为官方文档中就没有参数。将每个文档的词语的tfidf值导出来之后,发现竟然每个词语的tfidf值都是1,这可惊掉我的下巴了,毕竟之前可没有这个问题。思来想去觉得就是这个参数的问题。
模型对比
于是我多训练了一个normalize=False的模型作为对比,果然这次输出的tfidf值就是正确的了。如何确定tfidf值是正确的?我找了两个文档中同一个词语的 tf 值和 tfidf值,交叉检验:
两个文本中“不断”的idf除下来,相等,证明了tfidf值的准确性。

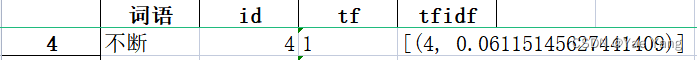
分析
normalize参数究竟意味着什么?看了gensim的官方文档,得知normalize=True的话,会进行Normalize document vectors to unit euclidean length(将文档向量归一化到单位欧式长度,也就是把文档向量转换为单位向量)。熟悉机器学习的朋友可以想到,这么做是为了消除文档长度的影响,因为长文档自然会有更多的terms,TF就会更高。
参考Standford NLP中相似文档查询的章节:Dot productsDot products![]() https://nlp.stanford.edu/IR-book/html/htmledition/dot-products-1.html#sec:inner
https://nlp.stanford.edu/IR-book/html/htmledition/dot-products-1.html#sec:inner
总结
设置normalize=True,能查询归一化的tfidf值,代码如下。如此设置适用于相似词和相似文档的查询。
text = [[]]
dictionary = Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
tf_idf_model_n = TfidfModel(corpus, normalize=False)
# 输出整个corpus的tfidf值(注:不能得到每个文档的词语tfidf)
tfidf_value = list(tfidf_model_n[corpus])
print(tfidf_value)
设置normalize=False,还是按照tf和id进行查询,详见我之前的博文。如此设置适用于想要获得原始TFIDF值。
word_tf_tdf = list(tfidf_model[[(int(str(id)), int(str(tf)))]])















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









