







 文章探讨了利用机器学习、深度学习和图分析技术在CMU-CERT数据集上进行内部威胁检测的方法,重点关注Ensemble策略、LSTM在异常检测中的应用,以及Log2vec等图嵌入技术在检测企业内部网络安全威胁中的作用。
文章探讨了利用机器学习、深度学习和图分析技术在CMU-CERT数据集上进行内部威胁检测的方法,重点关注Ensemble策略、LSTM在异常检测中的应用,以及Log2vec等图嵌入技术在检测企业内部网络安全威胁中的作用。
文章目录
- UEBA,内部威胁 CMU-CERT数据集相关文章阅读笔记
- 1.Analyzing Data Granularity Levels for Insider Threat Detection Using Machine Learning
- 2.Ensemble Strategy for Insider Threat Detection from User Activity Logs
- 3.Deep learning for insider threat detection: Review, challenges and opportunities
- 4.Anomaly Detection for Insider Threats Using Unsupervised Ensembles
- 5.Behavioral Based Insider Threat Detection Using Deep Learning
- 6.Log2vec: A Heterogeneous Graph Embedding Based Approach for Detecting Cyber Threats within Enterprise
UEBA,内部威胁 CMU-CERT数据集相关文章阅读笔记
CMU-CERT数据集介绍
在网上看了很多介绍该数据集的博客,一直有个疑问,这个数据集的标注在哪,本着先入为主的想法结合现有的资料对这个数据集的结构做了一下猜测(可能还是不严谨和正确)
1.标注在哪
2.什么是“密集针”(dense needle)
以下是gpt的回答我感觉还蛮有道理。(如果路过的佬懂的请分享一下正确理解)

3.场景
1.Analyzing Data Granularity Levels for Insider Threat Detection Using Machine Learning
1.1 摘要
2.2 框架
3.3 算法
2.Ensemble Strategy for Insider Threat Detection from User Activity Logs
2.1 摘要
2.2 框架
2.3 算法
3.Deep learning for insider threat detection: Review, challenges and opportunities
3.1 摘要
3.2 框架
3.3 算法
4.Anomaly Detection for Insider Threats Using Unsupervised Ensembles
4.1 摘要
4.2 框架
4.3 算法
5.Behavioral Based Insider Threat Detection Using Deep Learning

5.1 摘要
内部人员由于可以绕过安全检测发起攻击,通常最有害的攻击被认为是内部人员发起。通过分析用户行为来检测内部威胁,主要分析一些类时间和活动进行特征选择。选择特征向量用于训练。采用cmu-cert r4.2用于训练。
提出的算法与长期短期记忆-卷积神经网络、随机森林、长期短期记忆-循环神经网络、一类支持向量机、马尔可夫链模型、多状态长短期术语记忆和卷积神经网络、门控循环单元和skipgram进行了对比。
5.2 相关工作
A. 基于用户行为的内部威胁检测技术
- 使用LSTM-CNN
- 使用XGBoost从审计日志提取
- 先对日子进行特征和字段进行行为审计,再利用这些字段训练IHHM模型
- 使用PCA和LSTM-RNN
- 使用无监督学习从日志中进行多域特征的特征选择,在将特征用于训练OCSVM
- 使用了混合方法 AD-DNN ,它使用自适应合成方法来解决类别不平衡问题
- 使用两层深度自动编码器的基于监督时间序列的解决方案也可用于内部攻击检测
B.基于图的内部威胁检测
通常用户数据都为多源异构数据,使用图可以应对这些结构化和异构的数据。
- [13]给出了一种基于图分析和异常检测的混合框架,它由两个模块“图形处理单元”(GPU)和“异常检测单元”(ADU)组成,用于内部威胁检测
- [36]提出了一种使用用户结构异常检测(SA)和心理分析(PP)相结合的方法进行内部威胁检测的框架
5.3 思路
论文提出了一种基于LSTM-AE的框架,由于cert数据集具有多源花时间序列数据,在此基础上提出了这个模型。
LSTM 用于模型训练。由于 LSTM 旨在查看历史数据来进行预测,因此它会处理最多 (t-lookback) 的数据,以在给定时间 t 进行预测。它采用 3D 数组作为输入。
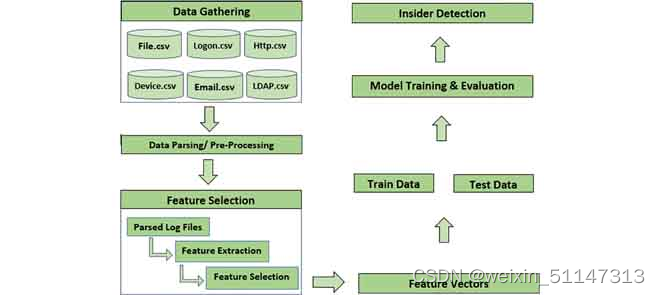
A.数据预处理
- 将cert里的六个csv合并成一个csv
- 处理缺失值,通过相关特征的估计平均值替换缺失值(本文的缺失值处理方法)
B.特征提取
所有 CSV 文件都会被解析并识别相关数据字段,从而可以有效地学习和预测用户行为。此外,这取决于我们正在处理的内部情况。例如,用户正常工作时间是早上8点到晚上7点,那么用户在这个时间段内登录和退出是正常的。但是,如果用户在办公时间后登录,使用某些闪存驱动器或 USB,然后不久就离开,则此行为被视为恶意。(具体的活动例子在answer文件夹里面有进行描述)Psychometric.csv(几个csv中的一个) 不用于特征选择。所有其他 csv 文件的特征包括整数编码的日期、时间、个人电脑、用户 ID、个人电脑、用户角色、用户功能单位、用户部门和活动特征。特征的 ID 是多余的,不包括在内。
大多数以前的方法使用基于固定时间窗口的特征,但是它可能会降低检测异常行为的可能性。使用基于用户会话的灵活时间窗口,而不是使用基于固定时间的窗口。(如何基于灵活时间窗口进行,下面是对用户会话的定义,提到的特征都是csv原本的特征还未处理)
用户会话包括各种活动,即。它以登录活动开始,然后是其他活动(http、电子邮件、文件等),并以注销活动结束。
日期、时间、user_id、PC 和活动功能显示基于用户会话的活动和信息。
然而,user_role、function_unit 和department 显示了与用户工作角色和职责相关的重要信息,并且针对每个用户进行填充。论文中使用的特征值如下图所示,(这是基于将所有字段合并后作者选择所要使用的特征)
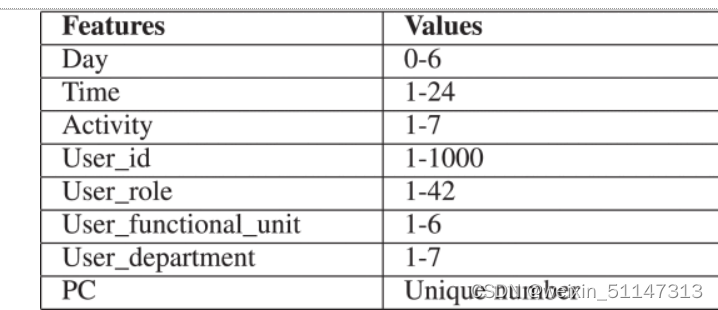

虽然选出了这些特征但是这些特征包含多种格式的数据,不能直接作为输入还需要进行编码,当特征存在是用1表示,不存在则用0表示。
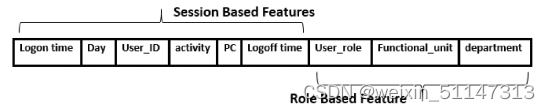
如图每个用户 U 在时间间隔 t 的特征向量,(i指第几个用户)
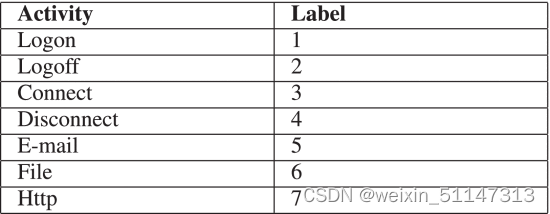
用户特征向量中的activity的定义
5.4实验与结论
A.实验过程
该模型使用 Epochs = 200、batchsize = 64、学习率 = 0.0001 进行训练,激活函数为“relu”,使用的优化器为“Adam”。用于输入和输出的尺寸相同。LSTM自动编码器的架构如图所示。
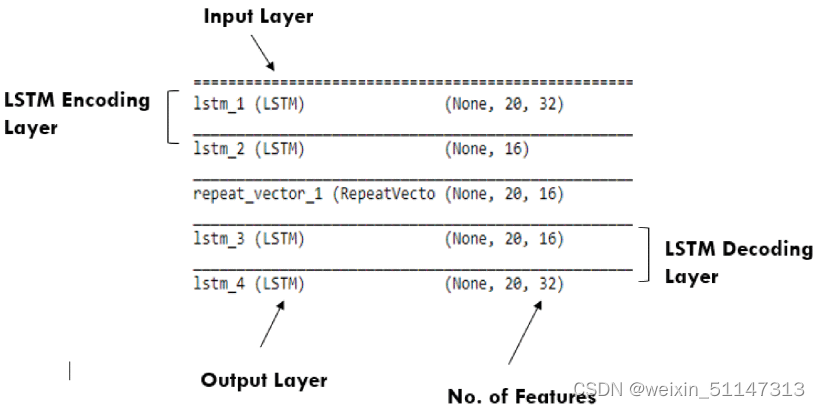
在训练阶段,LSTM 自动编码器将输入序列重建为输出序列,并计算 MSE 损失函数来识别差异。设置阈值(如何设置本文未提及)以隔离内部用户和普通用户。如果重建误差高于阈值,则被视为“内鬼”,如果低于阈值,则被视为“正常”。普通用户的重建误差很低,因为模型是用普通数据训练的。模型训练完成后,就会在包括正常实例和恶意实例的混合数据样本上进行测试。与普通用户相比,内鬼用户的重建误差非常高。
此外cert数据集与其他异常检测数据集一样存在类别不平衡问题,其中 70 个是恶意内部人员。该数据集仅包含 0.03% 的异常实例和 99.7% 的正常实例。本文提出的解决类别不平衡问题的方式是随机过采样,异常实例的副本在数据集中扩散。数据集分为训练数据、有效数据和测试数据,用于模型训练、验证和测试。数据划分比例包括:70%训练数据、10%验证数据和20%测试数据。测试数据包含正常数据和恶意数据的实例。日志总数为 32,770,220 个,其中 17,193 个是可训练参数。
B.评估
对于LSTM 自动编码器的结果生成一个混淆矩阵,用于评估我们的分类模型的性能。每行代表一个类别:正常和内部,而每个列单元格显示预测值。采用精度、F-Score、召回率等与其他算法进行性能对比评估
C.结论
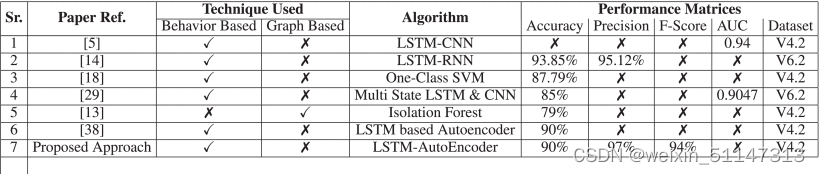
如下表,为改图与其他使用cert数据集的论文对比
6.Deep learning based attribute classification insider threat detection for data security
第五篇的引文[5],(6.7两篇都是从5的引文来的,查了一下会议级别实在是没查到,不在ccf索引之内,感觉应该比较xx,后面在看ccfb和a的几篇(1,2,3,4,8),这篇是ieee的可以直接网上翻译就先看了。)
6.1 摘要
本文提出了一种基于用户行为的DNN,具体来说就是使用LSTM-CNN框架来发现用户行为。(LSTM如此常用。)
- 使用LSTM来学习用户行为的语言并提取抽象的时间特征。
- 将提取的特征转换为固定大小的特征矩阵(即CNN的输入。)
- 采用CNN对这些固定大小的矩阵进行处理来检测内部威胁。
- 使用AUC分数来说明模型有效。
6.2 简介
先说明内部威胁是具有挑战的任务,原因:
- 内部人员利用其可信访问权限进行未经授权的操作;
- 内部人攻击的表现形式多种多样,例如心怀不满的员工植入逻辑炸弹破坏系统、窃取知识产权谋取私利等;
- 内部人员攻击行为具有多样性,且在工作时间内进行,使其异常行为混杂在大量正常行为中
基于以上三点得出难度大。
内部威胁检测的关键是对正常行为进行建模以区分异常行为(针对如何实现提出以下几个例子。)
聚合用户一天内的所有操作来表示用户在同一天的行为。然而,一天之内发生的异常行为可能会被遗漏。例如,用户在下班后登录到其指定的计算机并将数据上传到 wikileaks.org。(同样这是cert数据集给定的几个内鬼场景之一。)
就此本文认为每个用户的用户操作序列对于检测内部威胁非常重要。(针对这个用户序列操作的问题本文提出来如上LSTM-CNN框架。)
直接使用 LSTM 对用户动作序列进行分类的效率并不高,因为 LSTM 的输出只包含每个序列的一位信息。相反,我们使用经过训练的 LSTM 来预测下一个用户操作,并使用 LSTM 模型的一系列隐藏状态(隐状态)来生成一个固定大小的特征矩阵,并将其提供给 CNN 分类器。LSTM 可以更好地捕获对用户操作序列的长期时间依赖性(本文是18年的,所以这个是创新点),因为 LSTM 的隐藏单元可能记录时间行为模式。
6.3 相关工作
A.内部威胁检测
大部分仍是OC-SVM,IHHM,这边提到了一个新的名词ECM,用来 对建模时的时间序列中嵌入因果关系。
B.深度神经网络
本文这部分介绍的很随便大同小异,这边也就一笔带过我感觉没啥意义。
6.4 思路
模型框架如下,个人动作(例如,下班后登录指定的计算机)代表用户的操作;用户在一天内所做的操作代表了用户的行为(动作序列?)。与自然语言建模类似,一个动作对应一个单词,一个动作序列对应一个句子。因此,我们尝试学习用户行为语言作为检测内部威胁的新方法。LSTM用于提取用户行为特征。CNN 使用这些特征来发现异常行为。如下是原文。(实验部分对此有更好的描述)
模型框架
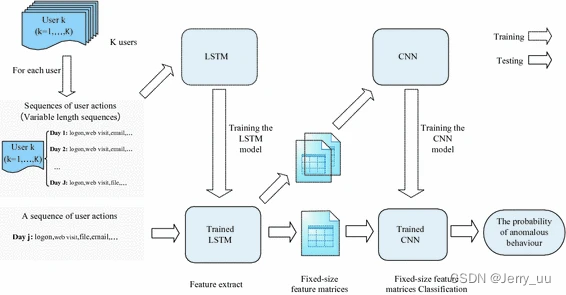

A.特征提取(LSTM来完成)
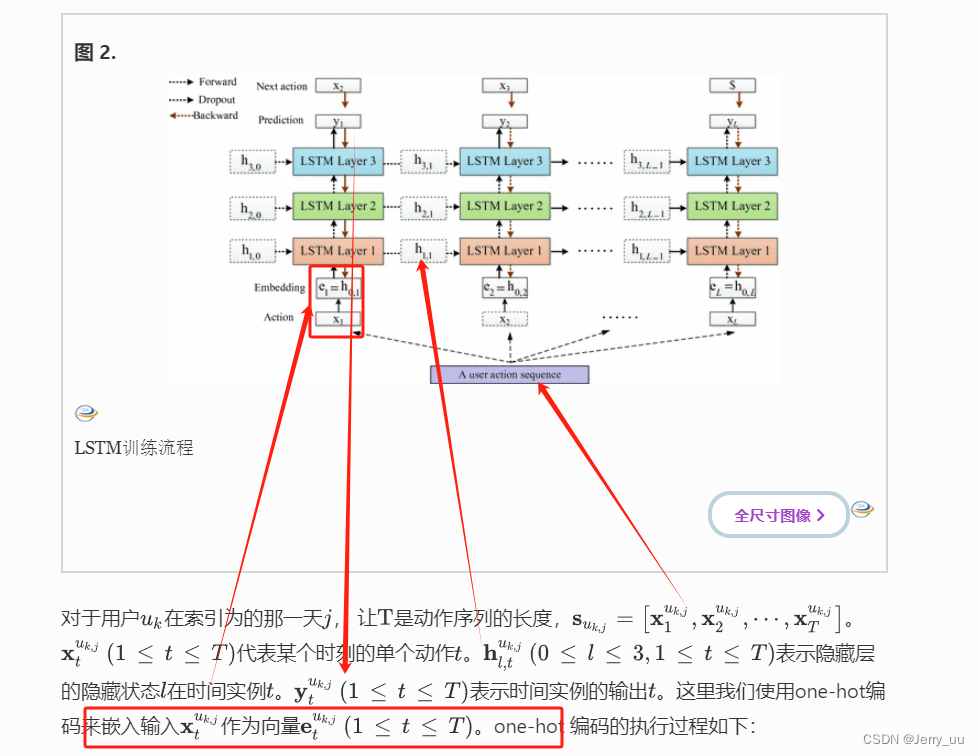

接下来还有很多公式对lstm提取特征的解释这一部分我还不够熟练不好在这梳理,有兴趣的uu可以自行观看原文3.2部分,但感觉影响不是很大,本主要的对5个行为csv的处理写的好像不够详细,特别是提取用户行为序列成配置文件这一块没有描述,感觉这一块还是很重要的。原文
B. CNN分类
论文使用CNN将用户行为的固定大小特征矩阵分类为正常行为和异常行为。CNN 由一个输入层、两个卷积池层、一个全连接层和一个输出层组成。接下图对于用户...![]()
首先使用带有正常或异常注释的固定大小特征矩阵来训练 CNN。Softmax 函数也应用于 CNN 的输出。训练后,我们使用训练后的 CNN 来计算用户操作序列的异常概率。
6.5 实验与结论
A.实验
在r4.2上进行的测试和训练,其中包含五种不同类型的活动:登录/注销、电子邮件、设备、文件和 http(分别对应5个csv)。解析每个日志行以获得时间戳、用户 ID、PC ID、操作详细信息等详细信息。我们在五种类型的活动中选择一整套 64 个actions,并根据用户操作序列构建 1000 个用户特定配置文件(?1000多个不同序列?)。用户操作的一个示例是在上午 8:00 到下午 5:00 之间在指定的计算机上访问求职网站(场景描述由作者自己举例),下表列出了用户操作的枚举 。

(action这一列即上面lstm提取特征中提到的单个动作,8:00-下午5:00即一天即索引中的j,具体的用户特定配置文件笔者感到好奇怪,文章没有给出)
前一个子集(约 70% 的数据)用于模型选择和超参数调整。后一个子集(约 30% 的数据)用于评估模型的性能。我们的分类是按照用户日的粒度进行的。需要注意的是,当我们以用户日为粒度进行分类时,我们删除了数据的周末,因为工作日和周末的用户行为有质的不同。(没有公开代码,数据处理这一部分感觉差点意思)
B.评估
没有对不平衡的数据集做增强或者其它处理,本文选择以ROC和AUC来评估。一方面,我们可以可视化分类器的 TPR 和 FPR 之间的关系。另一方面,可以比较两个或多个分类器的准确性。
7.User Behavior Analytics for Anomaly Detection Using LSTM Autoencoder - Insider Threat Detection
同6

7.1 摘要
7.2 相关工作
7.3 思路
7.4 实验与结论

















 612
612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









