






从朴素匹配到KMP的优化过程
1. 朴素字符串匹配算法
朴素匹配算法(Brute Force)是最直观的方法,其思路非常简单:
- 从主串的第一个字符开始,尝试匹配模式串
- 如果匹配失败,从主串的第二个字符开始重新尝试
- 重复上述过程,直到找到匹配或遍历完主串
代码实现:
void bruteForce(const char* s, int m, const char* p, int n) {
for (int i = 0; i <= m - n; i++) {
int j;
for (j = 0; j < n; j++) {
if (s[i + j] != p[j])
break;
}
if (j == n)
printf("%d ", i); // 找到匹配,输出位置
}
}
时间复杂度:
- 最坏情况:O(m * n),其中m是主串长度,n是模式串长度
- 例如:s = “AAAAA”, p = “AAB”,每次匹配都会在最后一个字符失败
2. 优化思路:避免无谓的重新匹配
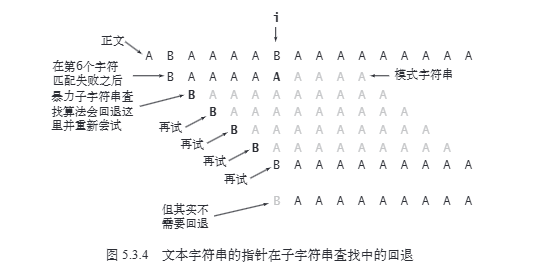
朴素算法的主要问题在于:当匹配失败时,会完全放弃已经匹配的信息,从头开始。
例如,假设我们有:
- 主串 s = “ABABCABABC”
- 模式串 p = “ABABC”
当我们从s[0]开始匹配,匹配到s[4]=p[4]='C’成功后,下一步会从s[1]重新开始。但是我们已经知道s[0:4]=“ABABC”,这包含了重要信息,可以帮助我们跳过一些不必要的比较。
3. 初步优化:利用已知信息
考虑一个初步优化:如果我们在位置i匹配了k个字符后失败,我们可以根据已知的这k个字符确定下一次应该从哪里开始匹配,而不是简单地i+1。
例如,对于上述例子,当我们完成第一次完整匹配(“ABABC”)后,下一步不必从s[1]开始,因为我们知道s[1:4]="BABC"与p[0:3]="ABAB"不可能匹配。我们可以直接跳到s[5]开始新的匹配。
因为一般的匹配过程都是从两个字符串第一个相同的字符开始比较,我们直接转到下一个相同的开始比较就行
4. 关键洞察:前缀与后缀的关系
进一步思考,当模式串内部存在相同的前缀和后缀时,匹配失败后的跳转可以更加高效。
例如,对于模式串p = “ABABC”:
- 如果我们匹配了"ABAB"后在’C’处失败
- 我们注意到"ABAB"的前缀"AB"与其后缀"AB"相同
- 这意味着我们可以将模式串向右移动2位,使前缀"AB"对齐主串中刚匹配过的后缀"AB"
这正是KMP算法的核心思想
5. KMP算法:使用next数组
前缀函数的理解
前缀函数(即next数组)是KMP算法的核心,它定义为:
- 对于字符串s,π[i]表示子串s[0…i]中,最长的相等的真前缀与真后缀的长度
- 特别规定π[0] = 0
例如对于字符串"ABABC":
- π[0] = 0(规定)
- π[1] = 0("AB"没有相同的真前缀和真后缀)
- π[2] = 1("ABA"的前缀"A"和后缀"A"相同,长度为1)
- π[3] = 2("ABAB"的前缀"AB"和后缀"AB"相同,长度为2)
- π[4] = 0("ABABC"没有相同的真前缀和真后缀)
next数组计算的直观理解
next数组的计算过程看起来复杂,但其实有一个直观的理解:
void computeNext(const char* p, int n, int* next) {
next[1] = 0; // 第一个字符没有真正的前缀
for (int i = 2, j = 0; i <= n; i++) {
while (j > 0 && p[i] != p[j + 1]) j = next[j];
if (p[i] == p[j + 1]) j++;
next[i] = j;
}
}
这个算法中:
- j表示当前已经匹配的前缀长度
- 对于每个位置i,尝试延长已匹配的前缀
- 如果p[i]不等于p[j+1],需要回退j,直到找到一个j使得p[i]=p[j+1]或j=0
- 这个回退过程就像在模式串自身上执行KMP匹配
完整KMP算法的细节解释
void KMP(const char* s, int m, const char* p, int n, int* next) {
for (int i = 1, j = 0; i <= m; i++) {
// 当前字符不匹配时,回退j
while (j > 0 && s[i] != p[j + 1]) j = next[j];
// 当前字符匹配,j前进
if (s[i] == p[j + 1]) j++;
// 完全匹配,输出位置并继续
if (j == n) {
printf("%d ", i - n); // 找到匹配,输出位置
j = next[j]; // 继续寻找下一个匹配
}
}
}
关键点解释:
- j表示已经匹配的模式串长度
- 当匹配失败时,j回退到next[j],相当于模式串右移
- 当j=n时,找到完整匹配,然后j回退到next[j]继续查找下一个匹配
- 整个过程中,i(主串指针)只向前移动,不会回退
效率分析
KMP算法的时间复杂度是O(m + n):
- 计算next数组需要O(n)时间
- 主匹配过程需要O(m)时间
- 虽然内部有while循环,但总的字符比较次数不会超过2m次,因为:
- i只向前移动,总移动次数为m
- j的增加次数最多为m(每次匹配成功j加1)
- j的减少次数不会超过j的增加次数,即最多m次
这种"不回头"的匹配方式是KMP算法高效的关键。
模式匹配的实际应用
KMP算法在许多实际场景中非常有用:
- 文本编辑器中的查找功能
- 生物信息学中的DNA序列匹配
- 网络数据包中的模式检测
- 编译器中的词法分析器
- 数据压缩算法中的重复串识别
与其他字符串匹配算法(如Boyer-Moore、Rabin-Karp)相比,KMP算法的特点是:
- 预处理仅需要O(n)时间
- 匹配过程中主串指针不回溯
- 适合模式串中存在大量重复子模式的情况


附录(tx面试题)
问题描述
给定两个字符串 text 和 pattern,完成以下两个任务:
计数任务:计算 pattern 作为连续子串在 text 中出现的次数,将结果存为 count。
字符频率统计任务:统计 text 中所有被 pattern 匹配覆盖到的位置上的字符频率,将结果存为 countChar(一个字符到频率的映射)。
要求细节
子串匹配必须是连续的,不是子序列。
字符频率统计只计算那些被匹配覆盖的位置上的字符,每个位置最多计数一次(即使该位置被多个匹配覆盖)。
输出为两部分:子串出现次数 count 和字符频率映射 countChar。
实现语言为 C++。
要求不使用 substr() 函数,鼓励使用更高效的算法如双指针或 KMP 算法。
示例
输入:
text = “abababababaccccc”
pattern = “aba”
输出:
count = 5
countChar = {‘a’:6, ‘b’:5}
解释:
pattern “aba” 在 text 中出现了 5 次,起始位置分别是索引 0, 2, 4, 6, 8。
这些匹配覆盖了 text 中从索引 0 到 10 的所有字符(即 “abababababa”)。
在这个被覆盖的区域内,字符 ‘a’ 出现了 6 次,字符 ‘b’ 出现了 5 次。
索引 11 之后的字符(“ccccc”)没有被任何匹配覆盖,因此不计入字符频率统计。
参考
- https://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
- https://oi-wiki.org/string/kmp/
- https://www.acwing.com/solution/content/14666/


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









