







Seeing What You Said Talking Face Generation Guided by a Lip Reading Expert
文章认为以往工作很少关注唇语清晰度,希望通过惩罚不准确结果来提升唇部区域动作的可理解性。
原文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Wang_Seeing_What_You_Said_Talking_Face_Generation_Guided_by_a_CVPR_2023_paper.pdf
文章目录
1.贡献
- 通过利用唇读专家来解决语音驱动的说话面孔生成的阅读清晰度问题
- 提出了一种新颖的跨模式对比学习策略,并由唇读专家协助
- 采用同步训练的transformer编码器来考虑整个音频话语的全局时间依赖性
- 提出了一个评测talking face generation的基准并开源代码
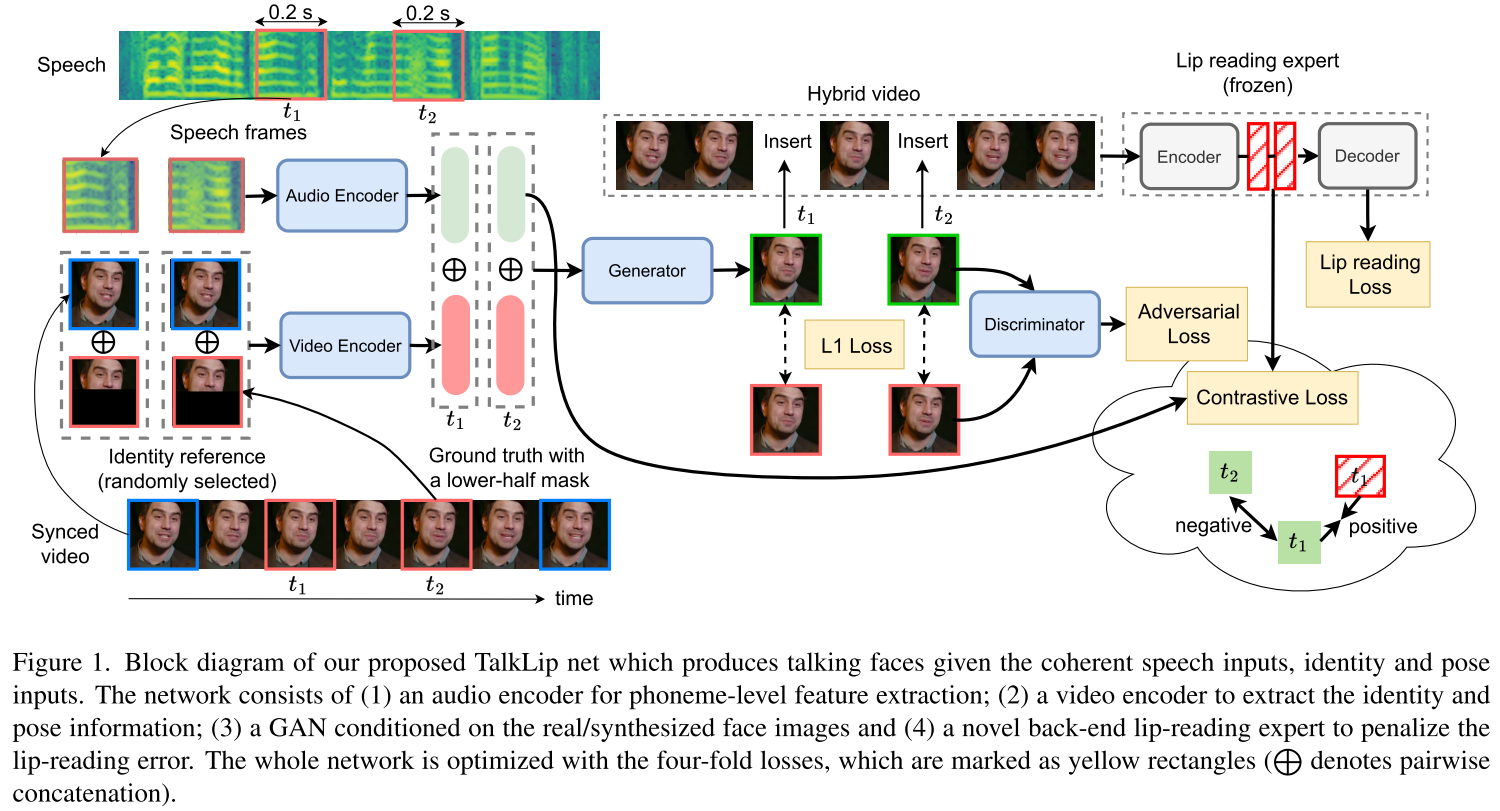
3.方法
TalkLip 网络以图像作为身份和姿势参考,同时以连贯语音作为嘴唇运动参考。给定来自生成器的合成视频,唇读专家被用来通过唇读损失来惩罚不准确的嘴唇运动。
3.1 lip-reading expert
引入AV-Hubert解决数据缺少问题。

然后,通过将视觉前端和在自监督中预训练的 Transformer 编码器与随机初始化的 Transformer 解码器相结合,构建唇读网络。 这个唇读网络在文本转录的监督下进行微调。 一旦微调完成,唇读网络就会被冻结,并充当说话人脸生成训练的专家,如图 1 所示。
3.2. Audio encoder
音频编码器对音素级嵌入进行编码,并将嵌入提供给生成器作为嘴形和嘴唇运动的参考。我们使用两种不同的音频编码器来提取嵌入。 我们将它们称为本地和全局音频嵌入。 使用基于 CNN 的网络提取本地音频嵌入。Transformer编码器将整个语音作为输入,生成所有帧的音频上下文特征。 然后,我们选择一帧上下文特征,它与姿势参考在时间上对齐作为全局音频嵌入,如图 2 所示。
3.3. Video encoder
视频编码器从图像中提取身份和姿势信息以形成统一的视觉嵌入,并将嵌入提供给生成器以合成与所提供的身份和姿势一致的图像。身份参考从一张随记图像中提取,姿势参考从遮盖了下半脸的图像中提取。
3.4. Video generation
生成器由转置的CNN块组成,并且在视频编码器和生成器之前采用了想u-net一样的跳跃连接,在重建效果和计算效率之间取了均衡。
应用两个生成损失来提高视频生成质量,重建损失和GAN损失。
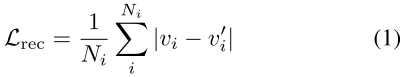
GAN可以增加生成人脸视频的真实感,并且性能出色,因此本文采用了GAN损失,D表示判别器。

3.5. Lip reading loss
唇读专家应用于混合视频,即地面实况视频,其中一些帧被相应的合成图像替换。生成图像的梯度将反向传播以优化模型。
假设 Y ∈ R L × C Y \in \mathbb{R}^{L \times C} Y∈RL×C 作为真实视频的文本内容,其中L和C表示文本长度和输出类别。
唇读专家包括:(1)一个3D卷积层和一个ResNet-18提取唇部运动特征(2)一个 Transformer 编码器,通过计算全局时间依赖性来生成上下文特征 R ∈ R T × f R \in R^{T \times f} R∈RT×f,其中 f 是特征维度;(3)一个 Transformer 解码器,用于预测文本 Y ^ ∈ R L × C \hat Y \in \mathbb{R}^{L \times C} Y^∈RL×C。唇读专家被冻结,使用交叉熵计算损失。
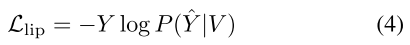
3.6. Contrastive loss
给定来自音频编码器的音频嵌入 Ea 和来自唇读专家的视觉上下文特征 R,对比损失计算如下:
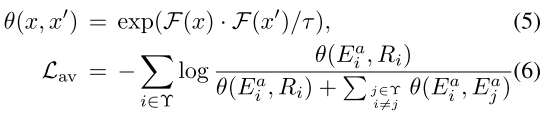
公式5用于计算两个正或负样本之间的相似度。公式6的主要作用则是最大限度拉近正样本之间的距离,拉远正负样本之间的距离。
关于infoNCE,infoNCE。
模型网络总的loss如下:
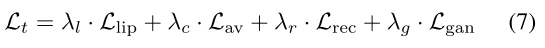
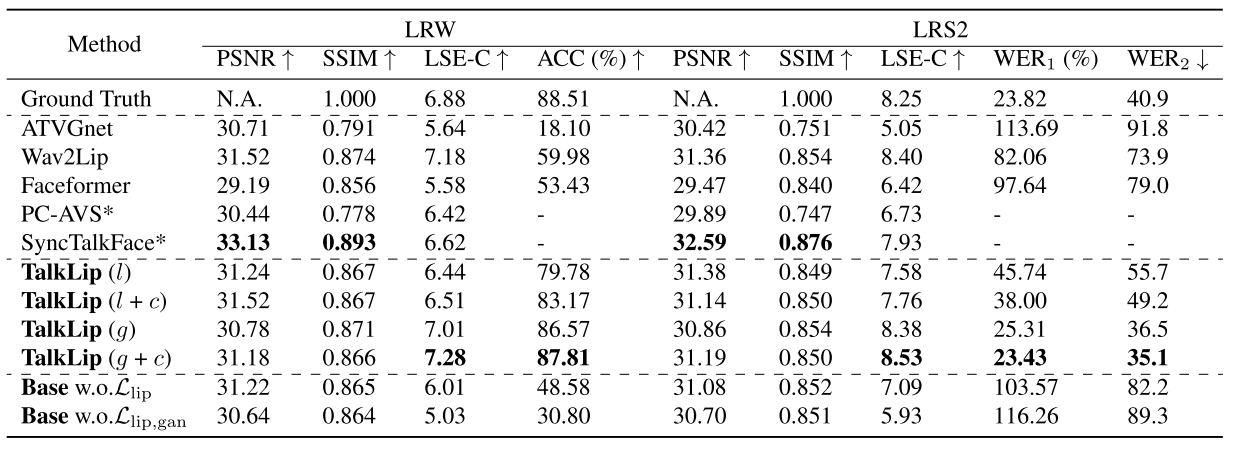
4.实验

5.结论
本文提出了 TalkLip 网络,用于合成具备高阅读可理解性和唇语同步的视频。TalkLip 利用预训练唇读模型纠正生成视频中的错误唇读预测,并通过单词准确率(ACC)和词错误率(WER)评估阅读可理解性。实验表明,TalkLip 在主观和客观评估中均优于其他方法。此外,通过对比学习和预训练音频编码器,进一步提升了唇语同步和音频嵌入效果。最终,TalkLip 能生成具有优越阅读可理解性、唇语同步性和视觉质量的说话人视频。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









