







A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild
这篇文章中提出的wav2lip,这几年在唇形生成乃至人脸生成的领域,几乎成为了必须被引用和对比的模型,在唇形同步等指标上广泛被参考和对比。
论文原文:https://arxiv.org/abs/2008.10010
贡献
-
提出了一种新的可以在任意视频上显示任意语音的唇同步网络,wav2lip
-
提出了一个新的评估框架,以实现对无约束视频中唇同步的公平判断
-
收集数据集ReSyncED
-
第一个独立于说话者的模型,性能优秀
2 相关工作
以往相关的任务都对生成的身份或词汇等,有限制和约束,并且只接受特定说话人物的训练,无法合成新的身份或声音。本文的工作重点是唇同步不受约束的说话脸视频,以匹配任何目标语音,不受身份,声音或词汇的限制。
还有一些任务,在给定静态图像和音频时效果比较好,但在尝试对未见过且不受约束的视频进行唇同步时,会产生不准确的嘴唇生成。与GAN不同,本文采用了预先已经训练好的唇同步鉴别器,该模块未使用生成器进行进一步训练,实现了更好的对口型同步的效果。
3 方法
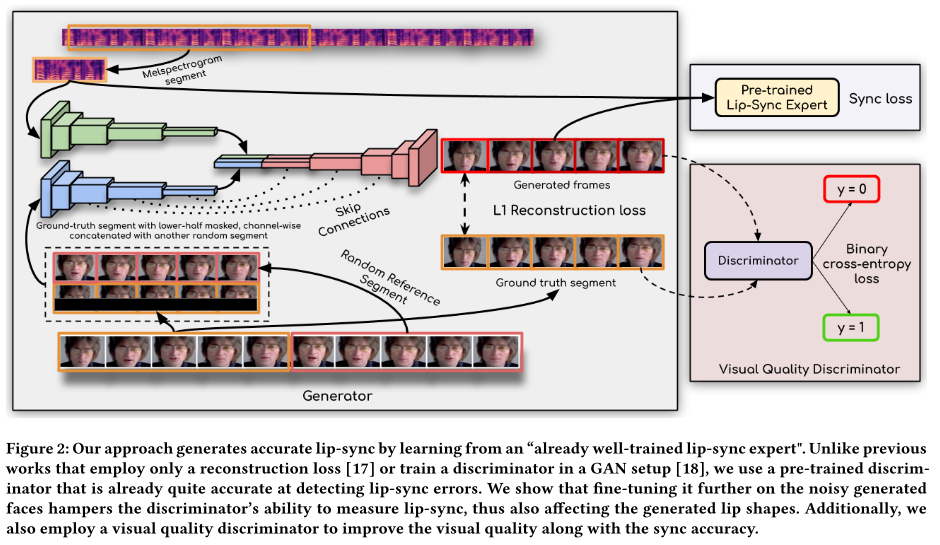
本文核心架构为:向唇形同步专家学习生成准确口型。
在wild视频中,产生不准确口型有两个关键原因,现有工作中使用的L1损失和LipGAN中的L1重建损失不足以惩罚不准确的唇同步生成。
3.1
在人脸重建的过程中,为了保持背景、人物身份等一致性,需要计算全局损失。嘴唇区域的重建损失只占不到总损失的4%,因此有一个强大的嘴唇同步鉴别器提供额外的监督是至关重要的。
3.3 唇形同步器
使用一个在数据集上预训练完成、准确率较高的专家唇形同步鉴别器指导模型训练。
针对原始的SyncNet,做了三点改进如下:
- 将按照通道方式输入灰度图像改为输入彩色图像
- 引入残差,增加模型深度
- 使用余弦相似度和二进制交叉熵损失。
通过上述改变,相比原模型将唇形同步率从0.56提高到了0.91 。
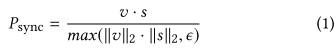
3.4 生成器
整个面部生成器如图2中所示,使用与LipGAN类似的结构。包含三个模块:1.身份编码器,2.语音编码器,3.面部解码器。身份编码器是残差卷积层的堆栈,其编码随机参考帧R,沿着通道轴与姿态先验P(下半部分被遮盖的面部)级联。语音编码器也是2D卷积的堆栈,以编码输入语音段S,然后将其与面部特征连接。解码器也是一个卷积层的堆栈,沿着转置卷积进行上采样。生成器被训练以最小化所生成的帧L d和地面实况帧LG之间的L1重建损失:
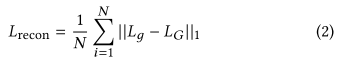
生成的连续乌镇输入唇形鉴别器得到唇同步损失:
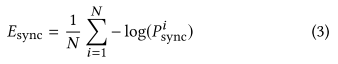
3.5 生成逼真面部
唇形同步器在监督生成器生成准确唇形的同时会造成模糊和伪影,造成视觉质量损失。为减轻这种损失,增加一个视觉质量鉴别器。
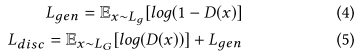
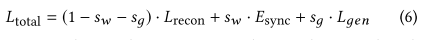
4 实验
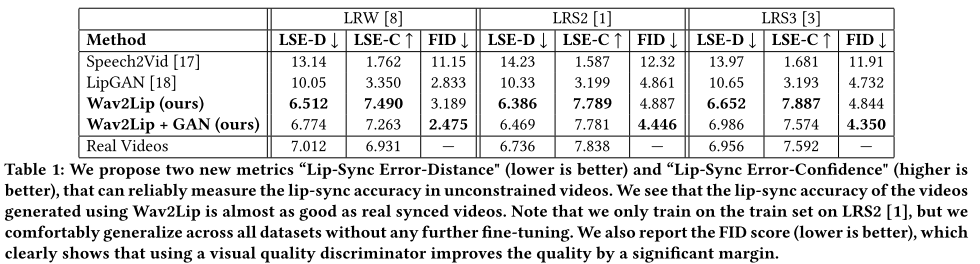
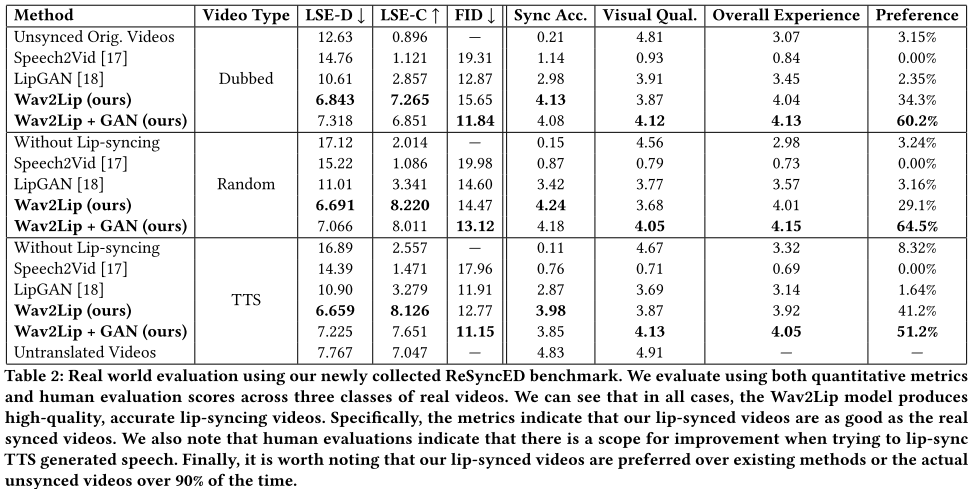
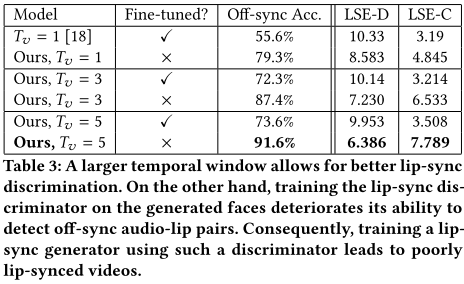
实验部分作者重新引入并验证了多个参数,及唇同步器微调的必要性,证明了模型设计的合理性。
5 结论
本文提出了一种在生成准确唇形同步视频的方法,并且提出了当前方法在对不受约束的视频进行口型同步时不准确的两个主要原因,第一点时预训练一个准确的唇形同步专家模块,第二点是提出了几个新的评估基准和指标以及一个现实世界中的评估数据集。
















 8495
8495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









