






题目:
一、Hadoop架构有哪些组件?分别有什么作用?
1.HDFS-分布式文件系统,解决分布式存储
2.Mapreduce-分布式计算框架
3.Yarn-分布式资源管理系统
4.Common-支持所有其他模块的公共工具程序
了解:Hadoop1.x中的Mapreduce同时处理业务逻辑运算和资源的调度,耦合性较大,并且存在只能运行Mapreduce程序这个问题。而在Hadoop2.x中,不仅分离了Mapreduce部分功能,将资源调度和运算分开,而且增加了Yarn,Yarn只负责资源调度,Mapreduce只负责运算。Yarn不仅能运行Mapreduce程序,还能运行Spark程序,Yarn目前发展成一个通用的资源调度框架,很多计算框架都支持在Yarn上运行。
二、HDFS有哪些组件?分别有什么作用?
Client(客户端):
1.文件上传至HDFS中的时候会进行文件切分,切分成一个一个的block,然后存储。
2.查询文件时,会与NameNode进行交互,获取文件位置信息。
3.会与DataNode交互,读取或写入数据。
4.client提供一些命令来管理HDFS。
5.client可以通过一些命令来访问HDFS。
NameNode(元数据节点):
1.管理HDFS的名称空间。
2.管理数据块映射信息及副本信息。
3.处理客户端的读写请求。
DataNode(实际存储数据块的节点):
1.实际存储的数据块。
2.执行数据块的读、写操作。
Secondary NameNode:
1.辅助NameNode,分担其工作量。
2.定期合并FSimage和Edits,并推送给NameNode。
3.在紧急情况下,可辅助恢复NameNode。
三、HDFS的优缺点是什么?
优点:
1.高容错性
2.适合大数据处理
3.流式数据访问,能保证数据的一致性
4.可构建在廉价的机器上,可以多副本机制,提高可靠性
缺点:
1.不合适低延时数据访问
2.无法高效的对大量小文件进行存储
3.不支持并发写入、文件随机修改场景
四、HDFS读写流程是什么?
读数据流程:
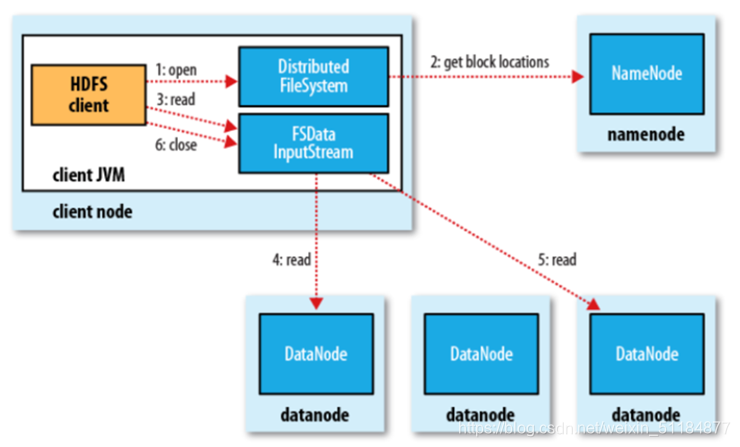
1.客户端创建DFS(DistributedFileSystem)实例。
2.DFS向NameNode发起RPC(远程过程调用)请求,获得文件开始部分或者全部block有序列表及DataNode地址。如果客户端本身就是一个DataNode,那么它将从本地读取文件。
3.DFS会向客户端返回一个支持文件定位的输入流对象FSDIS(FileSystemDataInputStream),用于客户端读取数据。
4.客户端调用read()方法,DFSIS(DistributedFileSystemInputStream)就会找出离客户端最近的DataNode并连接。
5.DFSIS依次读取第一批次的bock。如果第一批block都读完了,重复2~5,直至所有批次的block全部读取完成。
6.关闭DFSIS、FSDIS、DFS。
注意:NameNode只返回客户端请求包含块的DataNode地址,并不是返回请求块的数据。最终读取所有的block都会合并成一个完整的文件。
写数据流程:
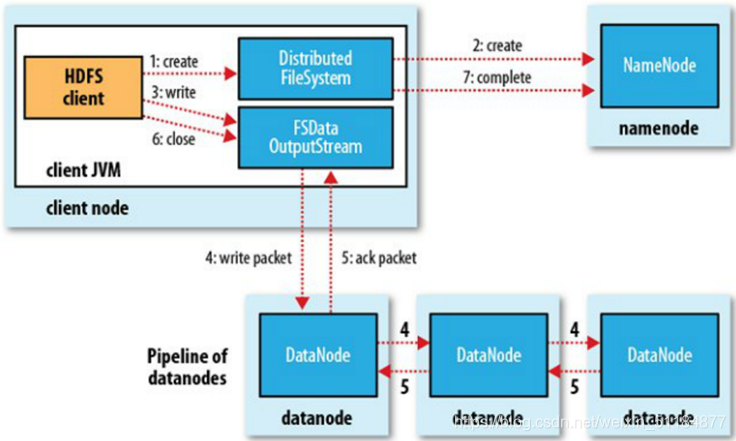
1.客户端通过DFS模块向NameNode请求上传文件,NameNode检查目标文件是否已经存在,父目录是否已经存在。
2.NameNode返回是否可以上传。如果不能上传,则会返回异常。
3.如果可以上传,那么客户端就会切分并请求第一个block上传到哪个DataNode服务器上。
4.NameNode返回3个DataNode节点,假定分别为:dn1、dn2、dn3.
5.客户端通过FSDOS(FileSystemDataOutputStream)模块请求dn1上传数据,dn1收到请求后会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6.dn1、dn2、dn3逐级应答客户端。
7.客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet(64KB)为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet,会放入一个应答队列等待应答。
8.当一个block传输完毕后,客户端再次请求NameNode上传第二个block的服务器。(重复3~7)
五、MapReduce的优缺点是什么?
优点:
1.易于编程
2.可扩展性
3.高容错性
4.高吞吐量
缺点:
1.难以实时计算
2.不适合流式计算
3.不适合有向图(DAG)计算
六、MapReduce的shuffle流程是什么?
MapTask:
1.收集Mapper发送数据到环形缓冲区
2.环形缓冲区数据量达到80%时溢出
3.将所有小文件分区、排序、合并成一个大文件
4.大文件按照分区、键值双重排序
ReduceTask:
1.所有MapTask结束后ReduceTask启动,并主动从所有的MapTask端,拉取属于该分区的数据的每个Maptask一个文件
2.根据排序合并所有MapTask端的小文件为一个大文件
3.分组提取合并后数据信息,一个分组一个Reducer
七、Combiner是做什么的?一定要有吗?使用Combiner时有什么限制条件?
1.Combiner是一个特殊的reduce,它的存在就是提高当前网络IO传输的能力,也是MapReduce的一种优化手段,能减少Reducer提取数据的传输负载。
2.不一定要有。
3.要有相同的key才能使用Combiner。
八、Map端的join和Reduce的join的使用场景分别是什么?有什么区别?
map端join:
1.使用场景:大文件+小文件
2.map端缓存多长表,提前处理业务逻辑,这样增加map端业务,减少reduce端数据的压力,尽可能减少数据倾斜。
reduce端join:
1.使用场景:大文件+大文件
2.shuffle阶段出现大量的数据传输,效率很低
3.合并操作是在reduce阶段完成的
4.map节点的运算负载很低,资源利用率不高
九、Yarn的组件有哪些?分别有什么作用?
ResourceManager(RM,全部资源管理器):
1.接收和处理客户端(RunJar)的请求
2.管理NodeManager
3.启动和管理AM(ApplicationMaster)
4.分配和调度资源
NodeManager(NM):
1.管理单节点资源
2.处理来自RM、AM的命令
ApplicationMaster(AM):
1.数据切分和划分
2.程序资源的申请以及内部map和reduce任务的分配
3.任务的管理和容错
Container:
1.对计算机资源(CPU、内存、网络、硬盘等)的封装和抽象
十、简述一下Yarn的Job提交流程
1.job提交:
· 客户端调用job.waitForCompletion()方法,向整个集群提交MapReducejob
· 客户端向ResourceManager申请一个job ID
· ResourceManager给客户端返回该job资源的提交路径(临时目录+job ID生成的路径)
· 客户端提交jar包、切片信息和配置文件到指定的资源提交路径
· 客户端提交完资源后,向ResourceManager申请运行MRAppMaster
2.jon初始化
· 当ResourceManager收到客户端的请求之后,先将该job添加到容量调度器的队列当中
· 通知一个空闲的NodeManager领取到该job
· 该NodeManager创建Container,并产生一个MRAppMaster
· 然后下载客户端提交的资源到本地
3.任务分配
· MPAppMaster向ResourceManager申请多个运行MapTask任务资源
· ResourceManager将运行MapTask任务分配给另外两个NodeManager,然后分别领取任务并创建容器
4.任务运行
· MRAppMaster向两个接受到的任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,然后MapTask对数据分区排序等操作
· MRAppMaster等待所有MapTask运行完毕后,向RsourceManager申请容器,运行ReduceTask
· ReduceTask拷贝MapTask相应分区的数据,然后进行操作
· 程序运行完毕后,MRAppMaster会向ResourceManager申请注销自己
5.进度和状态更新
· Yarn中的任务,将其进行和状态(包括Container)返回个MRAppMaster,客户端每秒向MRAppMaster请求进度更新,展示给用户
(时间间隔可以通过mapreduce.client.completion.pollinterval来设置)
6.job完成
· 除了向MRAppMaster请求job进度外,客户端每5秒都会有通过调用waitForCompletion()来检查job是否完成
· job完成后,MRAppMaster和Container会清理工作状态。job的信息会被历史服务器存储,以备之后用户核查
(时间间隔可以通过mapreduce.client.completion.pollinterval来设置)
十一、Hadoop自带的作业调度器有哪几种?分别是什么?
1.先进先出调度器(FIFO):这是一种批量调度器,会先按照作业的优先级,再按照时间先后选择被执行的作业。
2.容量调度器(Capacity Scheduler):该容器会对同一用户提交的作业所占资源量进行限定。
3.公平调度器(Fair Scheduler):该调度器支持队列多用户,每个队列中的资源可以配置,同一队列中的作业公平共享队列中的所有资源。














 502
502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









