







小伙伴们,我们认识一下。
俗世游子:专注技术研究的程序猿
最近在做新项目的数据库设计,目前为止一共出了80张表,预计只做了一半,心好累o(╥﹏╥)o
前一节我们聊过了多线程的基础问题,但是还漏掉一个知识点:
- 线程同步
这里我们补上
线程基础
线程同步
我们总是在说多线程操作,会出现线程不安全的问题,那么该怎么解释这个线程安全呢?
通俗的来讲,当多个线程操作同一份共享数据的时候,数据的一致性被破坏,这就是线程不安全的。
举个例子:
循环的数值调大才能看出效果,本人试了很久
public class ThreadSafe {
public static void main(String[] args) throws InterruptedException {
ShareObj shareObj = new ShareObj();
new Thread(() -> {
for (int i = 0; i < 20_0000; i++) {
shareObj.num += 1;
}
System.out.println(shareObj.num);
}, "线程A").start();
new Thread(() -> {
for (int i = 0; i < 20_0000; i++) {
shareObj.num += 1;
}
System.out.println(shareObj.num);
}, "线程B").start();
}
}
class ShareObj {
int num = 0;
}
两个线程同时操作共享变量的话,就会出现数据不一致的问题:
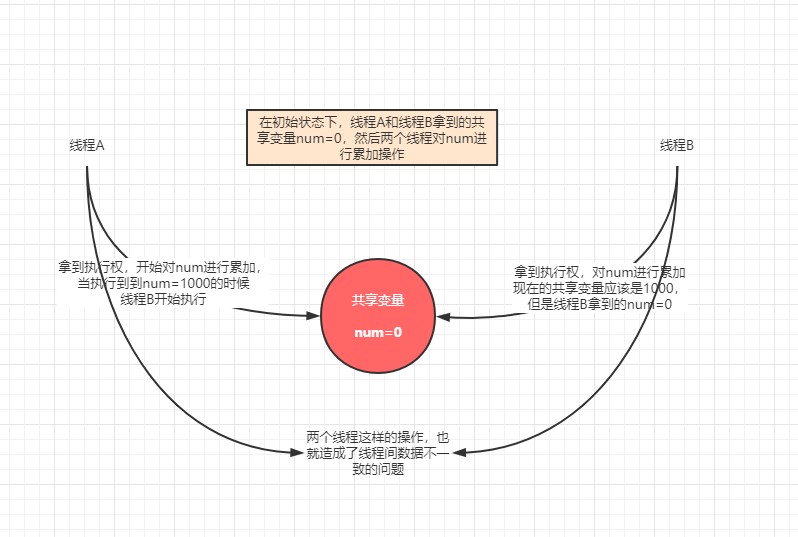
synchronized
那怎么解决这个问题呢,其实也就是加锁:synchronized,但是我们要注意加锁的资源
synchronized是对共享变量进行加锁,只有线程抢占到锁之后,该线程才能继续操作,操作完成之后释放锁资源
那么,上面的小例子我们就可以进行调整:
public class ThreadSafe {
public static void main(String[] args) throws InterruptedException {
ShareObj shareObj = new ShareObj();
new Thread(() -> {
synchronized(shareObj) {
for (int i = 0; i < 20_0000; i++) {
shareObj.num += 1;
}
System.out.println(shareObj.num);
}
}, "线程A").start();
new Thread(() -> {
synchronized(shareObj) {
for (int i = 0; i < 20_0000; i++) {
shareObj.num += 1;
}
System.out.println(shareObj.num);
}
}, "线程B").start();
}
}
class ShareObj {
int num = 0;
}
这样就解决了问题,达到了我们预想的结果
那么我们来聊一聊synchronized:
同步锁,监视共享资源或共享对象(同步监视器),需要的是Object的子类。可以通过同步代码块或者同步方法的方法来加锁
同步方法也就是将业务逻辑抽离成一个普通方法,使用
synchronized进行修饰,是一样的效果
public synchronized void update() {
// 业务逻辑
}
- 必须是两个或者两个以上的线程在同时操作同一份共享资源
- 使用同步锁之后,线程只要抢到锁之后才能够继续执行,否则就必须等待锁释放
这种情况下执行效率可见一般
也就是说:
- 当线程A访问,锁定同步监视器,开始执行业务逻辑。当线程B访问,发现同步监视器锁定,无法访问
- 当线程A执行完成,解锁同步监视器,线程B访问,发现同步监视器未锁定,锁定并执行业务逻辑
除了这个问题之外,在线程中中还会出现非常严重的问题:死锁
死锁,一般情况下表示互相等待,是程序运行是出现的一种状态,简单一点理解:
就是说两个线程,各自需要对方的资源,但是自己又不释放自己的资源,就造成了死锁现象
死锁没办法解决,只能在编写代码的过程时刻注意
生产者和消费者
非常经典的一个案例,不知道你们在面试的时候有没有被它支配过
前提条件:
- 生产者负责生产产品,放到一个区域里,消费者从这个区域里取走产品
关键点:
- 先生产,再消费
定义的产品类
public class Goods {
// 品牌
public String brand;
// 名称
public String name;
public Goods() {
}
public Goods(String brand, String name) {
this.brand = brand;
this.name = name;
}
}
生产者
public class Producer implements Runnable {
private Goods goods;
public Producer(Goods goods) {
this.goods = goods;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
if (i % 2 == 0) {
goods.brand = "农夫山泉";
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
goods.name = "矿泉水";
} else {
goods.brand = "旺仔";
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
goods.name = "小馒头";
}
System.out.println(String.format("生产者生产了:%s---%s", goods.brand, goods.name));
}
}
}
消费者
public class Consumer implements Runnable {
private Goods goods;
public Consumer(Goods goods) {
this.goods = goods;
}
@Override
public void run() {
System.out.println("消费者开始消费");
for (int i = 0; i < 10; i++) {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(String.format("消费者消费产品:%s--%s", goods.brand, goods.name));
}
}
}
测试方法
public class Main {
public static void main(String[] args) {
Goods goods = new Goods();
new Thread(new Producer(goods)).start();
new Thread(new Consumer(goods)).start();
}
}
这里出现两个问题,看一下结果
- 出现先消费后生产的问题
- 出现品牌和名称不一致的问题

下面我们来第二版解决
- 首先是第一个问题:这里我们只需要让生产者先执行就好,那么如果首先执行到的是消费者,那么就让其等待
- 品牌名称不对应的问题,这是由于生产产品和消费产品的方式不是原子性操作,在中间容易被中断,所以我们通过同步代码方法来解决,保证在执行过程中不会被打断
在产品类中定义生产和消费的方法
public class Goods {
// 品牌
public String brand;
// 名称
public String name;
// 标志位
public boolean flag;
public Goods() {
}
public Goods(String brand, String name) {
this.brand = brand;
this.name = name;
}
public synchronized void set(String brand, String name) {
/**
* 如果生产者抢占到CPU资源,那么先判断当前有没有产品,如果有产品,那么就进入等待状态,等待消费者消费完之后再次生产
*/
if (flag) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
this.brand = brand;
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
this.name = name;
flag = true;
// 唤醒消费者消费
notify();
}
public synchronized void get() {
/**
* 如果flag=false,说明生产者没有生产商品,那么消费者进入等待状态,等待生产者生产产品之后,然后再次消费
*/
if (!flag) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(String.format("消费者消费产品:%s--%s", this.brand, this.name));
flag = false;
// 唤醒生产者进行生产
notify();
}
}
生产者
public class Producer implements Runnable {
private Goods goods;
public Producer(Goods goods) {
this.goods = goods;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
if (i % 2 == 0) {
goods.set("农夫山泉", "矿泉水");
} else {
goods.set("旺仔", "小馒头");
}
System.out.println(String.format("生产者生产了:%s---%s", goods.brand, goods.name));
}
}
}
消费者
public class Consumer implements Runnable {
private Goods goods;
public Consumer(Goods goods) {
this.goods = goods;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
goods.get();
}
}
}
其他不变
这样就解决了上面的两个问题,

其实还有一种解决方式是采用BlockingQueue(队列)来解决,等待和唤醒的操作就不用我们来进行,BlockingQueue会帮我们来完成
就是提一下,不懂的等之后学过了队列,就清楚了
BlockingQueue的版本,该类位于java.util.concurrent包下(JUC),后续我们详细聊
public class Main {
public static void main(String[] args) {
BlockingQueue<Goods> queue = new ArrayBlockingQueue<>(5);
new Thread(new Producer(queue)).start();
new Thread(new Consumer(queue)).start();
}
}
class Producer implements Runnable {
private BlockingQueue<Goods> queue;
public Producer(BlockingQueue<Goods> queue) {
this.queue = queue;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
if (i % 2 == 0) {
try {
queue.put(new Goods("农夫山泉", "矿泉水"));
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
try {
queue.put(new Goods("旺仔", "小馒头"));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
class Consumer implements Runnable {
private BlockingQueue<Goods> queue;
public Consumer(BlockingQueue<Goods> queue) {
this.queue = queue;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
try {
Goods take = queue.take();
System.out.println(String.format("消费者消费产品:%s--%s", take.brand, take.name));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class Goods {
// 品牌
public String brand;
// 名称
public String name;
public Goods() {
}
public Goods(String brand, String name) {
this.brand = brand;
this.name = name;
System.out.println(String.format("生产者生产了:%s---%s", brand, name));
}
}
线程池
WHY
在实际的使用中,线程是非常消耗系统资源的,而且如果对线程管理不善,很容易造成系统资源的浪费,
而且在实际开发中,会造成线程的不可控,比如:
- 线程名称不统一
- 线程的创建方式等等
因此我们推荐在实际开发中采用线程池来进行开发,拥有以下优点:
- 使用线程池可以使用已有的线程来执行任务,可以避免线程在创建和销毁时的资源消耗
- 由于没有了线程的创建和销毁过程,提高了系统的响应性能
- 可以通过服务器配置对线程池进行合理的配置,比如:可运行线程数大小等
核心参数
了解到这一点之后,我们来看一看其具体的实现方式,在Java中,创建线程池主要是通过ThreadPoolExecutor来构造,下面我们来具体了解一下
我们看参数最多的构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
工作原理
在了解这些参数之前,我们先来聊一个知识点,就是线程池的工作原理,不然下面聊着有点生硬。画个图:
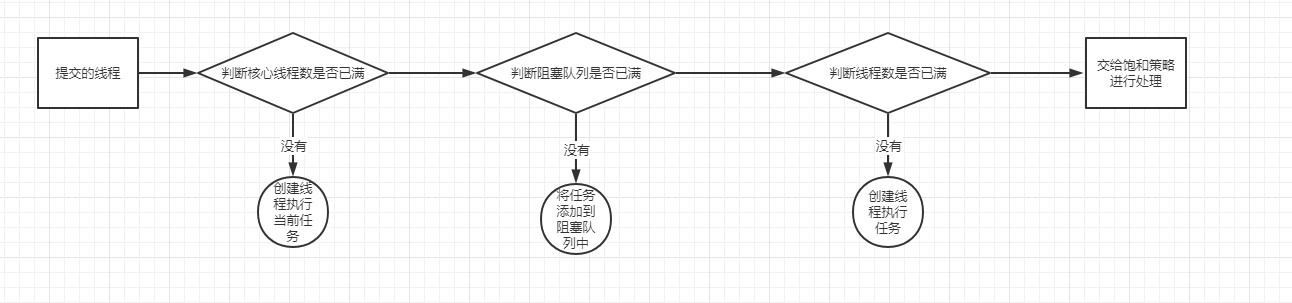
简单用文字描述一下就是这样的过程:
- 提交进行来的线程任务首先先判断核心线程池中的线程是否全部都在执行任务,如果不是,那么就创建线程执行提交进行来的线程任务,否则的话,就进入下一个判断
- 判断线程池中的阻塞队列是否已经占满,如果没有,就将任务添加到阻塞队列中等待执行,否则的话,就进行下一个判断
- 这里判断线程池中所有的线程是否都在执行任务,如果不是,那么就创建线程执行任务,否则的话就交给饱和策略进行处理
这是整体处理的一个过程,下面我们去实际源码中看看:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
在
execute()的注释中也有相当详细的说明
好了,下面看详细的参数,这里非常重要
corePoolSize和maximumPoolSize
corePoolSize表示核心线程数,maximumPoolSize表示线程池中允许存在的最大线程数。
那么
- 如果正在运行的线程数 小于 核心线程数,那么当新进任务的话,即使存在空闲状态下的线程,那么也会创建新的线程来执行当前任务
- 如果正在运行的线程数 大于 核心线程数,但是 小于 最大线程数,那么仅在等待队列满的时候才会创建新的线程
keepAliveTime和unit
keepAliveTime:当线程数大于核心时,多余的空闲线程在终止之前等待新任务的最长时间
unit表示空闲线程存活时间的表示单位
简单一点理解:
- 比如现在线程池中有30个核心线程数,当任务高峰来临时,当前核心线程数不足,那么会新创建出20个临时线程来执行任务,
- 当任务高峰结束后,发现当前30个核心线程数没有完全在执行任务,那么也就不会用到20个临时线程,这20个临时线程就是空闲的线程,然后经历过指定的时间后,如果还没有用到就会被销毁
workQueue
阻塞队列或者说是等待队列,用于存放等待执行的任务。
队列在这里先了解一下,等到后面聊 数据结构 的时候再详细介绍
数据结构很重要,这里简单聊一下
队列一般会和栈一起做对比,两者都是动态集合。栈中删除的元素都是最近插入的元素,遵循的是后进先出的策略(LIFO);而队列删除的都是在集合中存在时间最长的元素,遵循的是先进先出的策略(FIFO)。
这里我罗列出队列的类和说明,大家查看一下

threadFactory
创建新线程时需要用到的工厂,该参数,如果没有另外指定,则默认使用Executors.defaultThreadFactory() ,该工厂创建的线程全部位于同一ThreadGroup并且具有相同的NORM_PRIORITY优先级和非守护程序状态。 通过提供其他ThreadFactory,可以更改线程的名称,线程组,优先级,守护程序状态等。
/**
* The default thread factory
*/
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
Java还为我们提供了一种工厂方式:``Executors.privilegedThreadFactory()`。返回用于创建具有与当前线程相同权限的新线程的线程工厂
/**
* Thread factory capturing access control context and class loader
*/
static class PrivilegedThreadFactory extends DefaultThreadFactory {
private final AccessControlContext acc;
private final ClassLoader ccl;
PrivilegedThreadFactory() {
super();
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
// Calls to getContextClassLoader from this class
// never trigger a security check, but we check
// whether our callers have this permission anyways.
sm.checkPermission(SecurityConstants.GET_CLASSLOADER_PERMISSION);
// Fail fast
sm.checkPermission(new RuntimePermission("setContextClassLoader"));
}
this.acc = AccessController.getContext();
this.ccl = Thread.currentThread().getContextClassLoader();
}
public Thread newThread(final Runnable r) {
return super.newThread(new Runnable() {
public void run() {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
Thread.currentThread().setContextClassLoader(ccl);
r.run();
return null;
}
}, acc);
}
});
}
}
还有一点,如果我们想自定义线程工厂的话,那么我们可以参考上面两种的写法
handler
饱和策略,也可以称为拒绝策略。也就是当线程池中线程数都占满了无法再继续添加执行任务,最后就会交给饱和策略来处理
在线程池中饱和策略分为四种:
- ThreadPoolExecutor.AbortPolicy
这是Java提供的默认策略,也就是说当前策略会丢弃任务并抛出RejectedExecutionException异常
public static class AbortPolicy implements RejectedExecutionHandler {
/**
* Creates an {@code AbortPolicy}.
*/
public AbortPolicy() { }
/**
* Always throws RejectedExecutionException.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
* @throws RejectedExecutionException always
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
- ThreadPoolExecutor.CallerRunsPolicy
当前策略是通过调用线程处理该任务,只要线程池不关闭,那么就会执行该任务
public static class CallerRunsPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code CallerRunsPolicy}.
*/
public CallerRunsPolicy() { }
/**
* Executes task r in the caller's thread, unless the executor
* has been shut down, in which case the task is discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
- ThreadPoolExecutor.DiscardPolicy
什么都不做,直接将任务丢弃
public static class DiscardPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardPolicy}.
*/
public DiscardPolicy() { }
/**
* Does nothing, which has the effect of discarding task r.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
- ThreadPoolExecutor.DiscardOldestPolicy
也就是说,如果线程池没有关闭,那么将阻塞队列中的头任务丢弃,然后再通过execute()重新执行当前任务
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardOldestPolicy} for the given executor.
*/
public DiscardOldestPolicy() { }
/**
* Obtains and ignores the next task that the executor
* would otherwise execute, if one is immediately available,
* and then retries execution of task r, unless the executor
* is shut down, in which case task r is instead discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
JDK提供的线程池
在Java中,提供三种类型的线程池,下面我们一一来聊一聊
ThreadPoolExecutor
线程池执行器,为我们提供了以下几种:
- newCachedThreadPool
创建一个可根据需要创建新线程的线程池,但是在以前构造的线程可用时将重用它们,并在需要时使用提供的 ThreadFactory, 可用于业务逻辑处理时间短的操作
该方法是无参或者参数为ThreadFactory,其构建参数如下:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
拥有以下特性:
- 线程池数量没有固定,默认可以达到
Integer最大值 - 线程池中的线程可进行重复利用和回收,默认时长为1分钟
- 缓存队列采用的是无缓冲的等待队列,采用直接交接的排队策略
写个小案例
private static void newCachePoolExecutor() {
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 20; i++) {
newCachedThreadPool.execute(() -> System.out.println("anc"));
}
newCachedThreadPool.shutdown();
}
- newFixedThreadPool
创建一个可重用固定线程数的线程池,已无界队列方式来运行这些线程
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
拥有以下特性:
- 在线程池中的线程数处于一定的量,可以很好的控制线程的并发数
- 线程在显示关闭之前,线程池内的线程都将一直存在
- 采用无限队列的排队策略,当核心线程中的线程繁忙时,将新任务添加到队列中等待,在这里,参数
maximumPoolSize无效
写个小案例:
private static void newFixPoolExecutor() {
ExecutorService newFixedThreadPool = Executors.newFixedThreadPool(12);
for (int i = 0; i < 20; i++) {
newFixedThreadPool.execute(() -> System.out.println("anc"));
}
newFixedThreadPool.shutdown();
}
- newSingleThreadPoolExecutor
创建一个使用单个worker线程的Executor,已无界队列方式来运行该线程。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
拥有以下特性:
- 核心线程数为1,所以当前线程池只会存在一个正在运行的线程任务
- 可保证顺序的执行各个任务,并且在任意的时间点内不会存在多个活动线程
- 同样采用无限队列的排队策略
写个小案例:
private static void newSingleThreadPoolExecutor() {
ExecutorService newSingleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 20; i++) {
newSingleThreadExecutor.execute(() -> System.out.println("anc"));
}
newSingleThreadExecutor.shutdown();
}
ScheduledThreadPoolExecutor
这是一种可调度的执行器,也就是说可以执行定时任务,经常有面试会被问到
除了使用定时任务框架和Timer之外,还有什么技术可以实现定时任务?
其中一种就是采用该线程池技术
- newSingleThreadScheduledExecutor
该方法创建了一个单线程池的可调度执行器,
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
// ScheduledThreadPoolExecutor 继承自ThreadPoolExecutor
public ScheduledThreadPoolExecutor(int corePoolSize) {
// 这里调用父类的构造方法
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
拥有如下特性:
- 核心线程数为1,之后提交的线程任务会排在队列中一次等待执行
- 使用延时队列的方式来保存任务,只有当其中元素指定的延迟时间到了,才能从队列中获取到该元素。
写个小案例:
private static void newSingleScheduledPoolExecutor() {
ScheduledExecutorService newSingleThreadScheduledExecutor = Executors.newSingleThreadScheduledExecutor();
// 延迟1s执行,每个1s执行一次
newSingleThreadScheduledExecutor.scheduleAtFixedRate(() -> System.out.println("kk"), 1L, 1L, TimeUnit.SECONDS);
// 延迟1s执行
newSingleThreadScheduledExecutor.schedule(() -> System.out.println("kk"), 1L, TimeUnit.SECONDS);
}
- newScheduledThreadPool
创建一个线程池,可安排在给定延迟后运行命令或者定期执行,和上面线程池一样,最终调用的是同一个类,但是不同点在于:
该线程池可以指定核心线程数
写个小案例:
private static void newScheduledThreadPool() {
ScheduledExecutorService newScheduledThreadPool = Executors.newScheduledThreadPool(6);
newScheduledThreadPool.scheduleAtFixedRate(() -> System.out.println("kk"), 1L, 1L, TimeUnit.SECONDS);
newScheduledThreadPool.schedule(() -> System.out.println("aa"), 1L, TimeUnit.SECONDS);
}
ForkJoinPool
该线程池是JDK1.7之后添加进来的,采用了分而治之的思想,在大数据中很多地方都用到了这种思想。
创建一个带并行级别的线程池,并行级别决定了同一个时刻做多有多少线程在执行,如不传并行级别参数,将默认为当前系统的CPU个数
我直接给个案例吧,大家看看,毕竟这种方式本人在实际的开发中基本没有用过
这是计算总和的例子
public class SumTask extends RecursiveTask<Integer> {
private static final int THRESHOLD = 20;
private int[] arry;
private int start;
private int end;
public SumTask(int[] arry, int start, int end) {
this.arry = arry;
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
if (end - start < THRESHOLD) {
for (int i = start; i < end; i++) {
sum += arry[i];
}
return sum;
} else {
int middle = (start + end) / 2;
SumTask left = new SumTask(arry, start, middle);
SumTask right = new SumTask(arry, middle, end);
// left.fork();
// right.fork();
invokeAll(left, right);
return left.join() + right.join();
}
}
}
int[] arry = new int[100];
for (int i = 0; i < 100; i++) {
arry[i] = new Random().nextInt(20);
}
// 实际调用
SumTask sumTask = new SumTask(arry, 0, arry.length);
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
System.out.println("多线程执行结果:" + forkJoinPool.submit(sumTask).get());
实现类:
- RecursiveTask
通过泛型可以指定其执行的返回结果
- RecursiveAction
无返回值
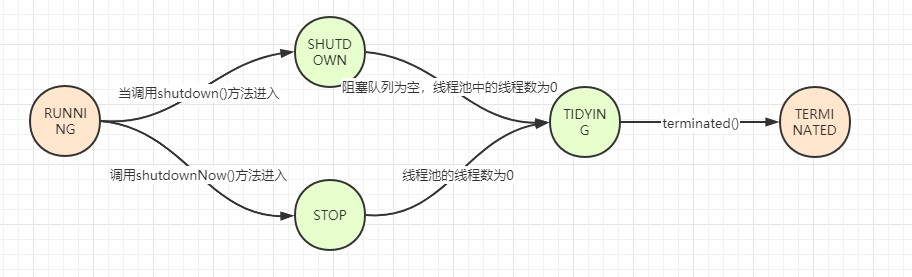
生命周期
线程池生命周期只有两种:
- RUNNING
线程池在RUNNING状态下,能够接收新的任务,并且也能够处理阻塞队列中的任务
- TERMINATED
线程池正式进入到已终止的状态
在这两种状态中间,还包含三种过度状态:
- SHUTDOWN
当线程池调用shutdown()方法的时候,会进入到SHUTDOWN状态,该状态下,线程池不再接收新的任务,但是阻塞队列中的任务却可以继续执行
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(SHUTDOWN); // SHUTDOWN状态
interruptIdleWorkers(); // 中断可能正在等待任务的线程
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate(); // 如果(SHUTDOWN状态和线程池和队列为空)或(STOP和线程池为空),则转换为TERMINATED状态
}
- STOP
当线程池调用shutdownNow()方法的时候,会进入到STOP状态,该状态下,线程池不再接收新的任务,也不会执行阻塞队列中的任务,同时还会中断现在执行的任务
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(STOP); // STOP状态
interruptWorkers(); // 中断所有线程,即使处于活动状态也是如此
tasks = drainQueue(); // 将没有执行的任务从队列中remove(),并添加到List中
} finally {
mainLock.unlock();
}
tryTerminate(); // 如果(SHUTDOWN状态和线程池和队列为空)或(STOP和线程池为空),则转换为TERMINATED状态
return tasks;
}
private List<Runnable> drainQueue() {
BlockingQueue<Runnable> q = workQueue;
ArrayList<Runnable> taskList = new ArrayList<Runnable>();
q.drainTo(taskList);
if (!q.isEmpty()) {
for (Runnable r : q.toArray(new Runnable[0])) {
if (q.remove(r))
taskList.add(r);
}
}
return taskList;
}
上面也就是
shutdown()和shutdownNow()的区别,更多的是推荐使用shutdown()
- TIDYING
当线程池中所有任务都已终止,并且 工作线程 为0,那么线程池就会调用terminated()方法进入到TERMINATED状态
用图来表示:
写在最后
多线程的基础知识就聊到这里,欢迎大家在评论区积极互动,提出自己的见解















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









