






(1)导入后续用到的库
from datetime import datetime
from urllib.parse import quote #对中文转码
import requests
import os
import warnings #过滤警告
warnings.filterwarnings("ignore")(2)定义获取json文件的方法
def hot_search():
url = 'https://weibo.com/ajax/side/hotSearch'
response = requests.get(url)
# 状态码200通常被称为"成功"状态码,它表示服务器已经成功地处理了客户端的请求,并且返回了一个响应。
if response.status_code != 200:
return None
return response.json()['data'](3)定义解析json文件的方法
def main(num):
data = hot_search() # 调用hot_search()函数获取数据源
if not data:
print('获取微博热搜榜失败')
return
print(f"置顶:{data['hotgov']['word'].strip('#')}") # 设置正能量推荐位(热搜置顶),加大对正向内容的宣推力度。
pq_time = datetime.now().strftime('20%y/%m/%d %H:%M:%S')
# montage = "标题,热度,类型,主题标签,分类,链接,日期" # 用来保存爬取到的数据
montage = f"{data['hotgov']['word'].strip('#')}"+',,置顶,,,,'+pq_time
for i, rs in enumerate(data['realtime'][0:num]):
j = i + 1
title = rs['word']
# 点击链接后,发现url的规律,其url组合为:https://s.weibo.com/weibo?q=+热搜标题+&Refer=top等后缀
# 由于url并不能为中文,因此在链接中会呈现为类似8%8C%85%E这样的编码。
# 如果我们要实现对url的组合,首先应该对中文字符串进行转码。
# 为此需要使用urllib.parse库quote方法,对中文转码,代码如下:
link = (f"https://s.weibo.com/weibo?q={quote(title)}&t=31&band_rank={j}&Refer=top")
try:
label = rs['label_name'] #标题
except: # 对异常进行捕获并处理,比如广告,就没有label_name键
label = ''
try:
hot = rs['raw_hot'] #热度
except:
hot = ''
try:
subject_label = rs['subject_label'] #主题标签
except:
subject_label = ''
try:
category = rs['category'].replace(',', '、') #类别
except:
category = ''
if hot != '':
montage = montage + '\n' + title + "," + str(hot) + "," + label + "," + subject_label + "," + category + "," + link + "," + pq_time
# 写入txt文件
dir_path = '热搜榜单数据/' + datetime.now().strftime('20%y年%m月%d日')
try:
os.mkdir(dir_path)
except FileExistsError:
print(dir_path + "目录已存在")
now = datetime.now().strftime('20%y年%m月%d日%H-%M-%S')
file_name = dir_path + '/' + now + '.txt'
if not os.path.exists(file_name):
f = open(file_name, "w", encoding='UTF-8')
f.write(montage)
f.close()
else:
f = open(file_name, "w", encoding='UTF-8')
f.write(montage)
f.close()
print(datetime.now().strftime('微博热搜榜 20%y年%m月%d日 %H:%M'))
print("导出文件名:", file_name) #文件第一行是表头,第二行是置顶的内容
(4)调用方法
if __name__ == '__main__':
print(datetime.now().strftime('微博热搜榜 20%y年%m月%d日 %H:%M'))
num = 55 #获取热搜的数量
main(num)(5)运行结果展示
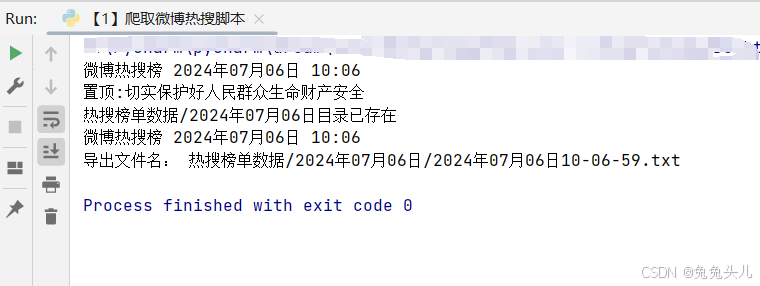
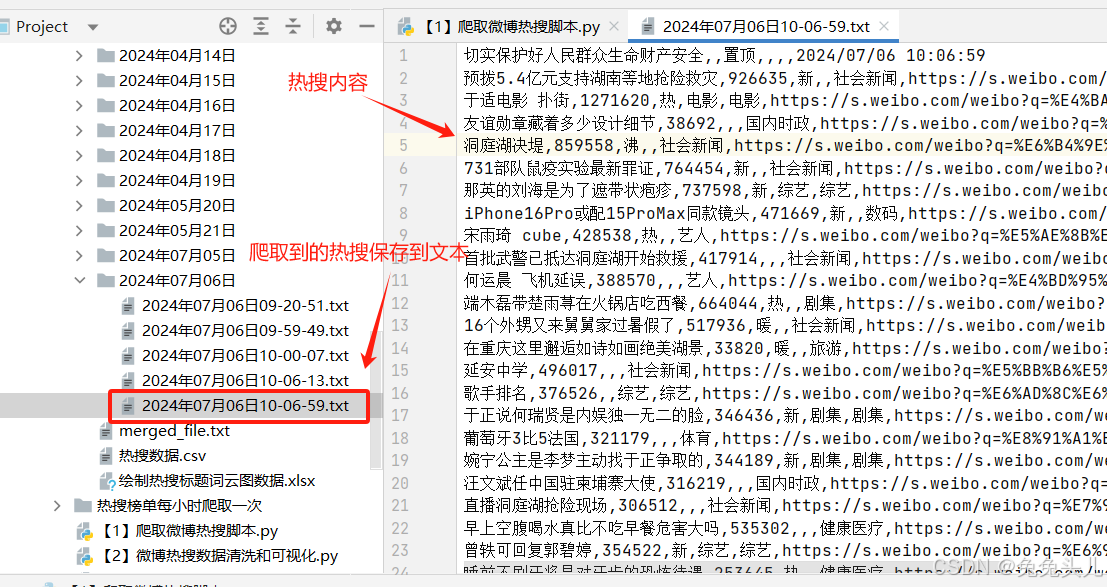
官网热搜榜单
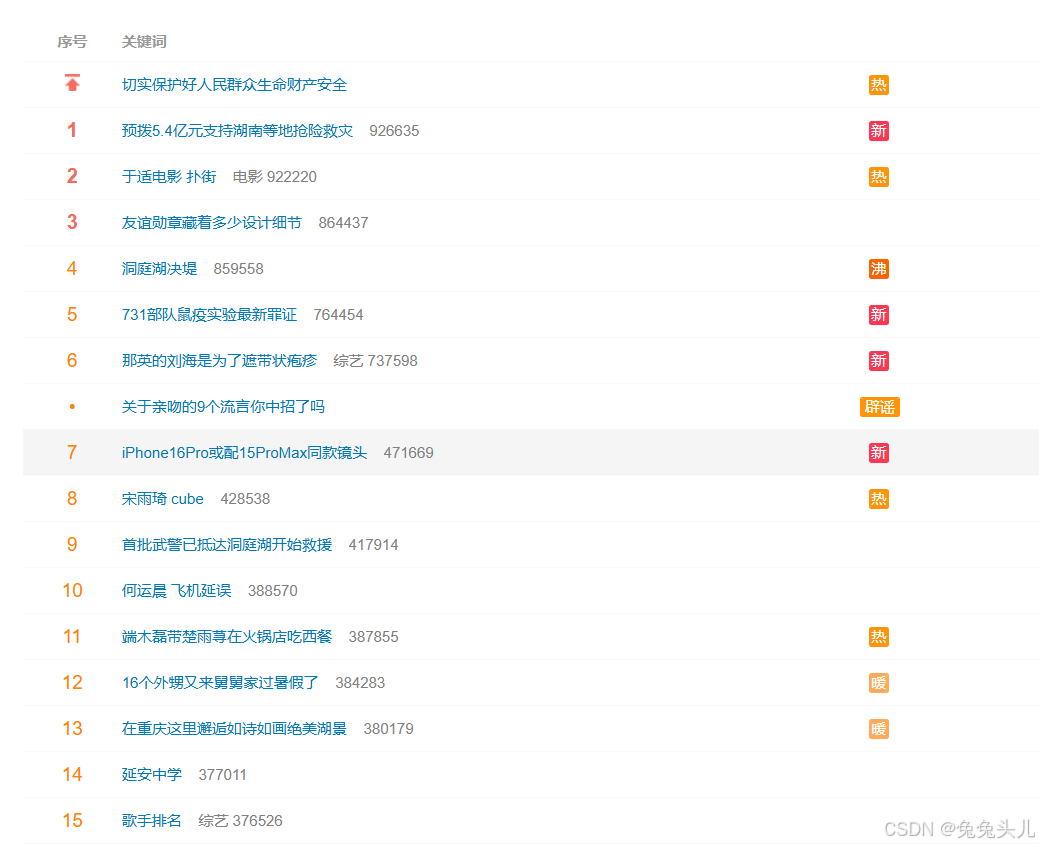
注:可能会有些许区别 因为热搜榜单更新频率较快!
最后,小伙伴们有什么问题可以评论区留言!

















 2199
2199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









