









在 遥感+深度学习领域,经常需要对较大尺寸的遥感图像进行批量裁切,制作样本集。在裁切过程中主要的参数有:
- 裁剪尺寸
- 步长
- 边缘裁切方式(不能完全裁切的情况,不裁切、补0裁切、改变方向裁切)
在裁切之后,经过模型预测的影像块需要进行拼接。如果裁切过程中设置了裁剪步长,相邻的影像块会存在重叠,此时在拼接过程,往往需要将重复的区域进行加权拼接。在边缘区域的影像重叠情况比较复杂,需要分情况讨论。
本文章使用matlab整理了批量裁切和加权拼接的方法,以143 * 248 * 1的影像为例,不同尺寸影像改变参数即可
裁切方法
使用两层for循环即可进行裁切。
注意:
- 如果不能裁切完全,可以使用全0填充原始影像的边缘。
- 步长分为左右裁切的步长和上下裁切的步长,一般两者相等
以143 * 248 单通道影像为例。
- 裁切尺寸:24
- 滑动步长:4
宽度143不能完全裁切,可添加一行0,144可以完全裁切。
裁切影像块共1767张,(57 * 31)。
下面对1767张裁切影像块进行平均拼接。
close all;
clear;
clc;
%批量裁剪代码
file_path = '';%待裁切影像数据文件夹
crop_file_dir = ''; %裁切结果文件夹
img_path_list = dir(strcat(file_path,'*.tif'));
img_num = length(img_path_list);
for j = 1:1:img_num %大循环,遍历每一张影像
image_name = img_path_list(j).name;
image = imread(strcat(file_path,image_name));
% 为每幅待裁切的影像创建一个文件夹,存放该影像的裁剪结果
crop_image_directory = strcat(crop_file_dir,image_name);
if exist(crop_image_directory,'dir')
rmdir(crop_image_directory,'s');
end
mkdir(crop_image_directory);
[h,w] = size(image);
k = 0;
% 添加1行0,使完全裁切 248 * 144 按24*24裁切,步长为4
add_0 = zeros(1,248);
img = [image;add_0];
for x = 1:4:h-23
for y = 1:4:w-23
k=k+1;
tmp_img = image(x:x+23, y:y+23);
str2 = strcat(crop_image_directory,'\',num2str(k),'.tif');
imwrite2tif(tmp_img,[],str2,'single','Copyright',...
'MRI', 'Compression',1);
end
end
end
加权拼接方法
对1767张影像块进行拼接,由于采用了滑动裁切,原始影像每一个像素都被多幅裁切影像块覆盖,并且情况比较复杂。
本文采用了一种先加和-再平均思路。
- 首先,按照裁剪顺序,将裁切影像块叠加到0矩阵上。
- 其次,分区域进行平均
以144*248原始尺寸,裁切步长4,裁切尺寸24,裁切数量1767为例。
先进行简单加和:
%叠加
for x = 1:4:h-23
for y = 1:4:w-23
img = imread(strcat(img_folder,img_list{n}));
result(x:x+23,y:y+23) = result(x:x+23,y:y+23)+img;
n = n+1;
end
end
分情况讨论。
整体分为三个区域。
- 四个角区域
- 四个边区域
- 一个内部区域
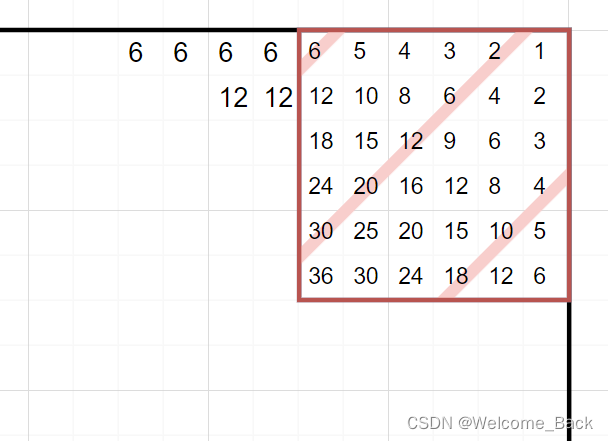
其中,角区域和边区域的情况如下图。数字代表该像素上有多少块裁切影像块,即需要除以几进行平均。
中间区域每个像素都被36个影像块覆盖,除以36即可。
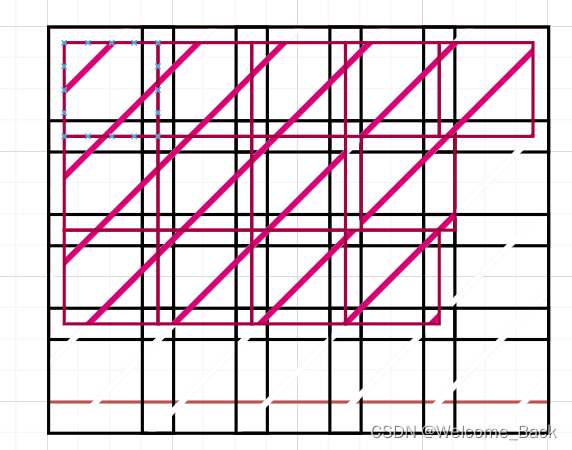
拼接代码如下:
注意
由于裁切影像块的命名方式为 1.tif 2.tif …
在读取时需要注意顺序,对folder_list = dir(dir_path)内的文件进行排序。
close all;
clc;
clear;
% 加权拼接方式
% 思路:先将所有影像块叠加到0矩阵上(相加方式),然后分区域进行平均取值!
dir_path = 'E:\delete\crop4\';%裁剪文件夹目录
out_path = 'E:\delete\weight_pinjie\';
mask = double(imread('E:\delete\china_mask2.tif'));
folder_list = dir(dir_path);
folder_list(1) = [];folder_list(1) = [];
for date = 1:length(folder_list)% 第二天开始
img_date = folder_list(date).name;
img_folder = strcat(dir_path,img_date,'\all_pred\');
img_list = dir(strcat(img_folder,'*.tif'));
num = length(img_list);
nameCell = cell(length(img_list),1);
for i = 1:length(img_list)
nameCell{i} = img_list(i).name;
end
img_list = sort_nat(nameCell);% 排序
h = 144;
w = 248;
result = zeros(h,w);
n = 1;
%叠加
for x = 1:4:h-23
for y = 1:4:w-23
img = imread(strcat(img_folder,img_list{n}));
result(x:x+23,y:y+23) = result(x:x+23,y:y+23)+img;
n = n+1;
end
end
%按区域进行平均
% 分为四个角、四条边、一个中 共三部分。除了中部,每个部分再切分为6种情况
%%四个顶
% 角1(1:24,1:24) 角2(1:24,225,248) 角3(121:144,1:24) 角4(121:144,225:248)
%%四条边
%上边(1:24,25:224)
%下边(121:144,25:224)
%左边(25:120,1:24)
%右边(25:120,225:248)
%%一个中
%中部(25:120,25:224)
%% 四个角(只需考虑一个右上(1:24,225,248))
%只需考虑一个右上(1:24,225,248)
x = 1;
for weight = 6:-1:1
w1 = weight*1;
w2 = weight*2;
w3 = weight*3;
w4 = weight*4;
w5 = weight*5;
w6 = weight*6;
result(1:4,224+x:224+x+3) = result(1:4,224+x:224+x+3)./w1;
result(5:8,224+x:224+x+3) = result(5:8,224+x:224+x+3)./w2;
result(9:12,224+x:224+x+3) = result(9:12,224+x:224+x+3)./w3;
result(13:16,224+x:224+x+3) = result(13:16,224+x:224+x+3)./w4;
result(17:20,224+x:224+x+3) = result(17:20,224+x:224+x+3)./w5;
result(21:24,224+x:224+x+3) = result(21:24,224+x:224+x+3)./w6;
x = x+4;
end
%% 四条边,每一条边6种情况。分别除以 6 12 18 24 30 36
x=1;
for weight=6:6:36
result(x:x+3,25:224) = result(x:x+3,25:224)./weight; % 上
result(120+x:120+x+3,25:224) = result(120+x:120+x+3,25:224)./(42-weight);% 下
result(25:120,x:x+3) = result(25:120,x:x+3)./weight; % 左
result(25:120,224+x:224+x+3) = result(25:120,224+x:224+x+3)./(42-weight); % 左
x=x+4;
end
%% 一个中
result(25:120,25:224) = result(25:120,25:224)./36;
result = result.*mask;
result(result==0) =NaN;
str = strcat(out_path,img_date,'_average2.tif');% 恢复到143*248,最后一行无用为0
imwrite2tif(result,[],str,'single','Copyright','MRI', 'Compression',1);
end
其他影像情况思路一样,只需改变对应的参数即可。全局加权平均的方式能够较好的去除拼接痕迹,提升拼接后影像的目视效果。
全局加权平均只是一种拼接方式,还可以使用多种方式。如忽略边缘的拼接方式,对于重复的影像块,只使用中间不重复的部分进行拼接。















 6018
6018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









