






1.确定要爬取的对象,并在数据库中建一个表
id------------------------------------------自增
CDName---------------------------------歌曲的名字
CDFile-------------------------------------歌曲的分类
singer------------------------------------歌手的名字
CDUrl-------------------------------------歌曲的url路径
CDImg------------------------------------歌曲的图片
2.利用scrapy创建项目
scrapy startproject (项目名字)
3.通过scrapy shell工具判断要爬取的网站的内容是否能显示出来
scrapy shell (网站网址)
ps:如果scrapy指令没有用,去https://blog.csdn.net/qq_37245397/article/details/81346728
学习如何下载scrapy
4.编写items.py(要爬取的内容)
5.在spiders文件夹中新建一个python文件,用来编写主要代码
 6.在anaconda中执行脚本语句
6.在anaconda中执行脚本语句
scrapy crawl (文件里面取的名字)Music -o music.csv
ps:数据库的一些配置
数据库字段表的定义
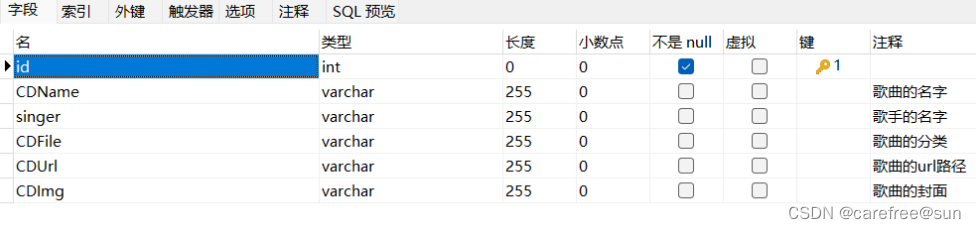 setting.py文件:
setting.py文件:
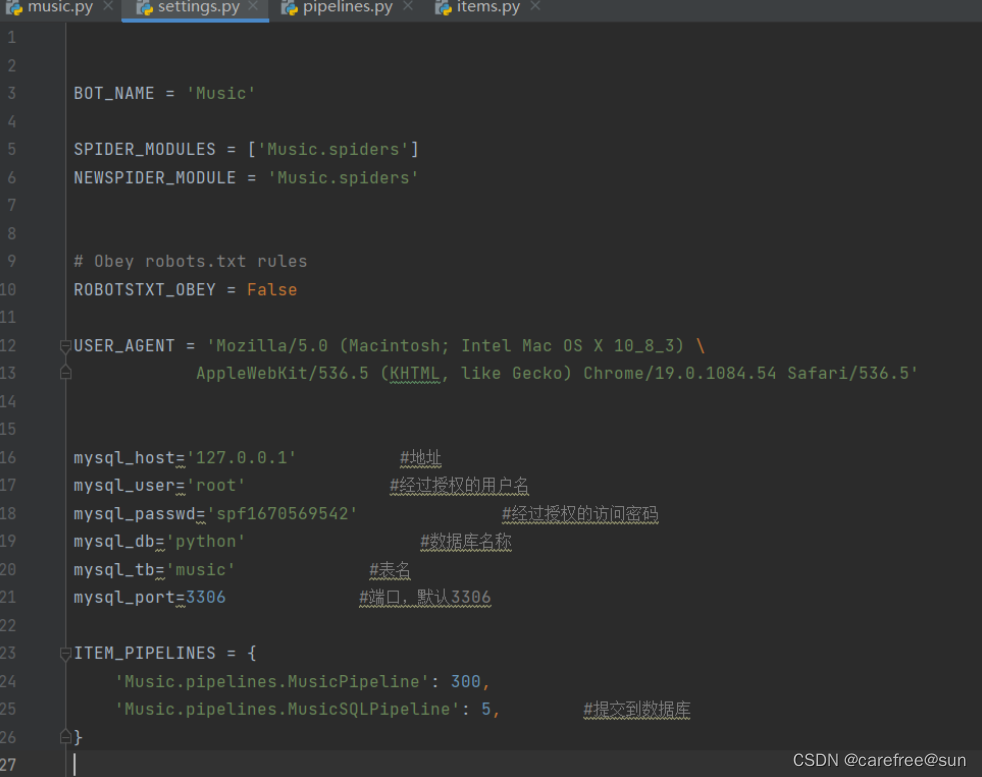
pipelines.py文件
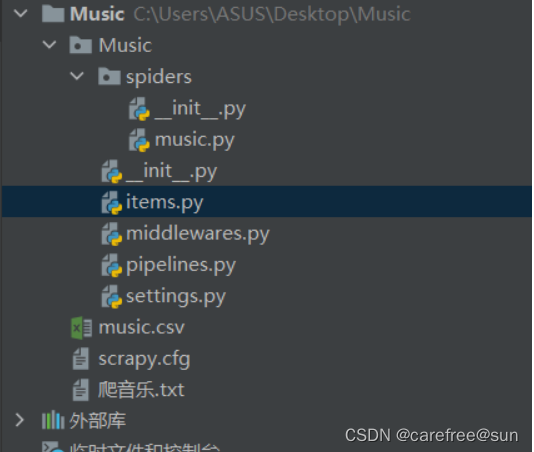
 完整代码项目目录:
完整代码项目目录:
结果截图















 2159
2159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









