






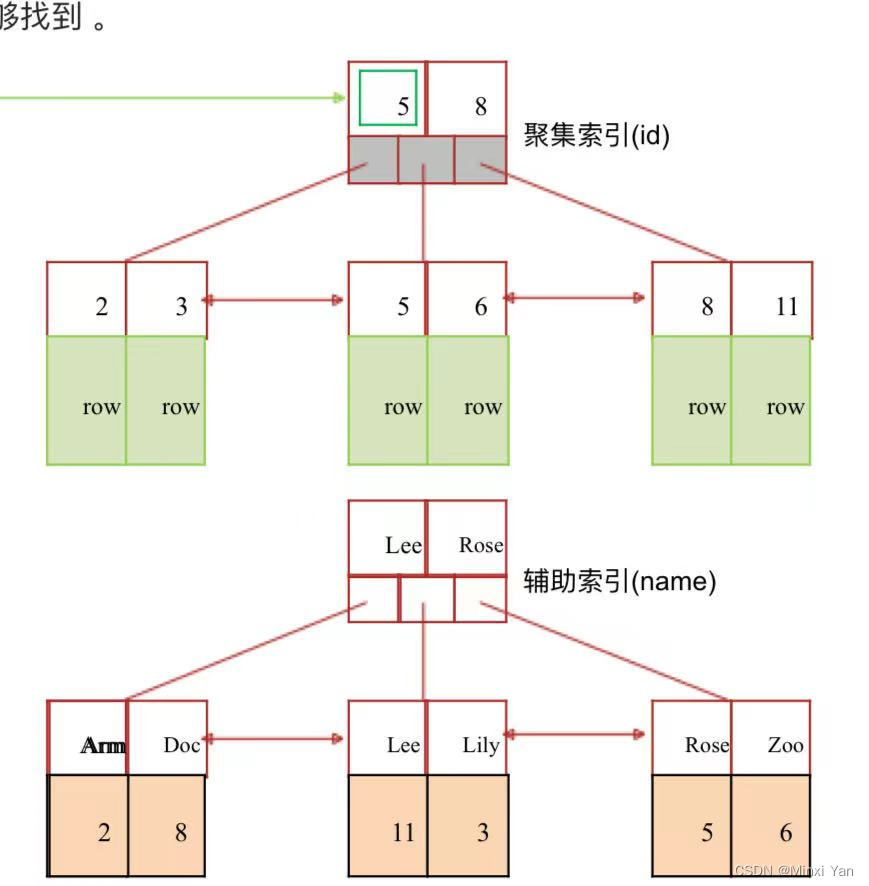
聚集索引、二级索引与回表
**聚簇索引:**将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据
**非聚簇索引:**将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
聚集索引
聚集索引是数据库表中数据的物理存储顺序与索引的顺序一致的一种索引。也就是说,数据行按照索引键的顺序进行存储。
例子: 如果一个表有一个基于某列(如id列)的聚集索引,那么表中的所有数据行将根据id列的值进行排序存储。
使用聚集索引查询效率更高,原因如下:
①顺序访问效率高: 因为数据行按索引键排序存储,对于顺序扫描(如范围查询)特别高效。读取一段连续的数据块,可以减少磁盘I/O操作。
②范围查询加速: 由于数据按顺序存储,范围查询(如BETWEEN,<,>等)可以利用顺序IO的优势,通过一次连续的磁盘读取完成,而不需要多次随机读取。
非聚集索引
二级索引,也称为非聚集索引(Non-Clustered Index),是数据库表中数据的逻辑顺序与索引的顺序无关的一种索引。它包含索引键和指向数据行的指针。
例子: 如果一个表有一个基于某列(如name列)的二级索引,那么数据库会维护一个包含name列值和指向实际数据行指针的索引结构。查询时,可以通过这个索引快速找到对应的数据行。
覆盖索引
覆盖索引是指索引包含了查询所需的所有列,这样查询就可以直接使用索引来获取数据,而不需要再访问主要的数据存储区域。
在某些情况下,聚集索引的键列就是查询需要的列。例如,如果查询的列包含在聚集索引的定义中,那么数据库引擎可以直接从索引中获取所需的数据,而不必再次访问主要的数据存储区域。
是指一个索引包含了查询语句所需的所有数据,不仅能够提供索引的搜索能力,还可以完全覆盖查询需求,避免了回表操作(即根据索引查找到主键,再根据主键获取数据的额外操作),从而提高查询性能和效率。
覆盖索引的关键特点包括:
- 包含查询所需的所有字段:在覆盖索引中,索引本身包含了查询语句中涉及的所有字段,从而避免了需要额外去主键索引中查找的操作。
- 避免回表操作:回表操作指的是在通过索引定位到行后,还需要通过主键再去表中检索数据的操作。覆盖索引避免了这种额外的操作,减少了I/O消耗,提高了查询效率。
















 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









