






ES
初识Elastic Search
是一个开源的、高扩展性的分布式全文搜索引擎,因为搜索文档的时候,如果是数据库的模糊匹配,效率非常低,。这时我们就需要ES。与Logstash(数据收集和日志解析引擎)和Kibana(数据可视化和管理工具)一起,形成Elastic Stack(以前称为ELK Stack),提供从数据收集、处理、搜索到可视化的完整解决方案。而且,ES提供简单易用的RESTful API,方便开发者集成到实际的应用中。
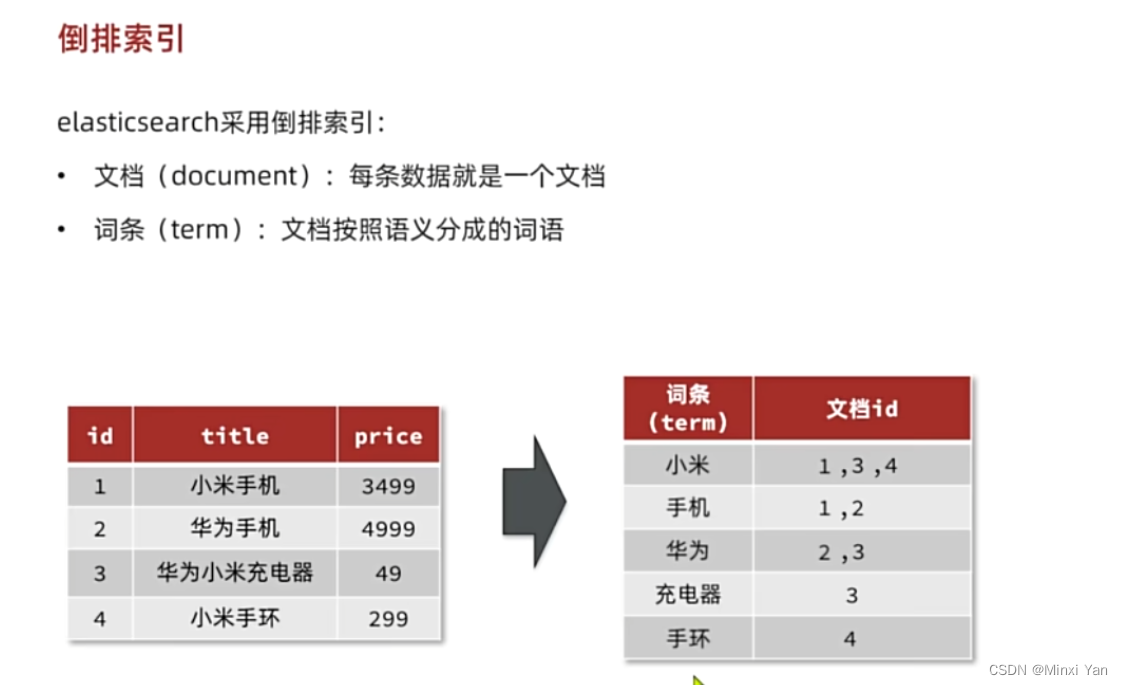
倒排索引
要了解倒排索引,首先要知道什么是正排索引,正排索引就是基于文档的id创建索引,根据id查询快,但是查询词条时必须先找到文档,而后判断是否包含词条。
IK分词器
IK分词器是一款基于词典分词和规则分词相结合的分词算法实现的中文分词器。它能够将一段连续的中文文本切分成一个个有意义的词语,为后续的索引、搜索、文本挖掘等任务提供支持。
如何设置自定义字典?
设置自定义的字典在IK分词器中是一个重要的功能,它允许用户根据特定的需求添加或修改词汇。以下是一个清晰的步骤指南,用于在IK分词器中设置自定义字典:
1. 编辑IKAnalyzer.cfg.xml配置文件
- 找到IK分词器的配置文件
IKAnalyzer.cfg.xml。这个文件通常位于${ES_HOME}/plugins/ik/config/目录下。 - 打开该文件,你会看到类似以下的配置结构:
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!-- 用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!-- 用户可以在这里配置自己的扩展停止词字典 -->
<entry key="ext_stopwords"></entry>
<!-- ... 其他配置项 ... -->
</properties>
2. 创建自定义字典文件
- 在
config目录下新建一个名为ext.dic的文件(或其他你指定的文件名,但需要在配置文件中对应修改)。 - 使用文本编辑器打开
ext.dic文件,并确保文件的编码为UTF-8,否则可能会导致词典不生效。 - 在该文件中添加你的自定义词汇,每个词汇占一行。例如:
自定义词汇1
自定义词汇2
自定义词汇3
3. (可选)配置远程扩展字典
- 如果你希望从远程位置加载自定义词典,你可以取消注释
<entry key="remote_ext_dict">words_location</entry>这一行,并将words_location替换为你的远程词典位置。
4. 重启Elasticsearch
- 在完成上述配置后,你需要重启Elasticsearch以使更改生效。
注意事项:
- 确保自定义词典文件的路径与
IKAnalyzer.cfg.xml中的配置相匹配。 - 自定义词典文件应使用UTF-8编码,以避免出现乱码或无法识别的问题。
- 如果Elasticsearch集群包含多个节点,你需要在每个节点上都进行相同的配置。
- 在进行任何更改之前,建议备份原始配置文件和词典文件,以防意外情况发生。
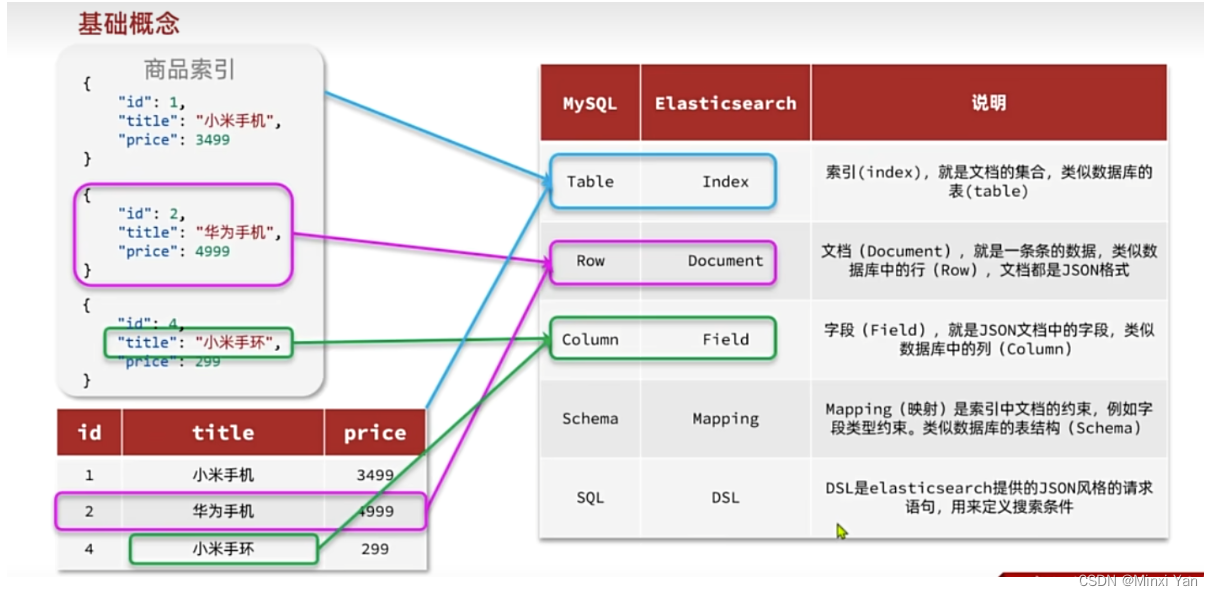
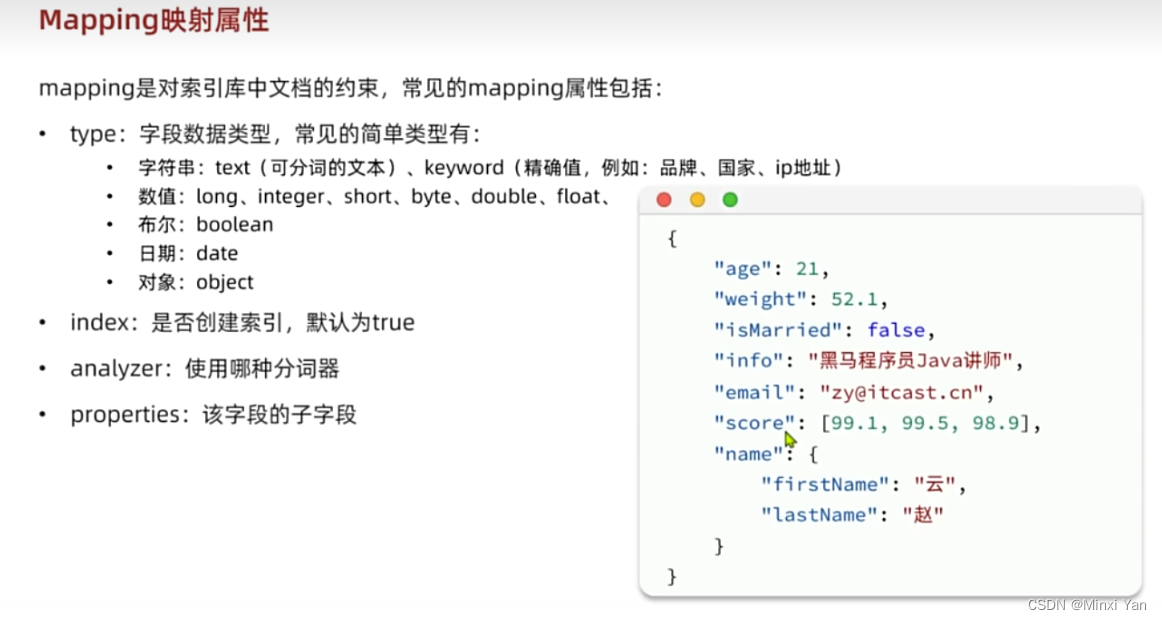
ES里的基础概念
索引:Index,就是相同类型的文档的集合。
映射:mapping,索引中文档的字段约束信息,类似表的结构约束
mapping映射属性
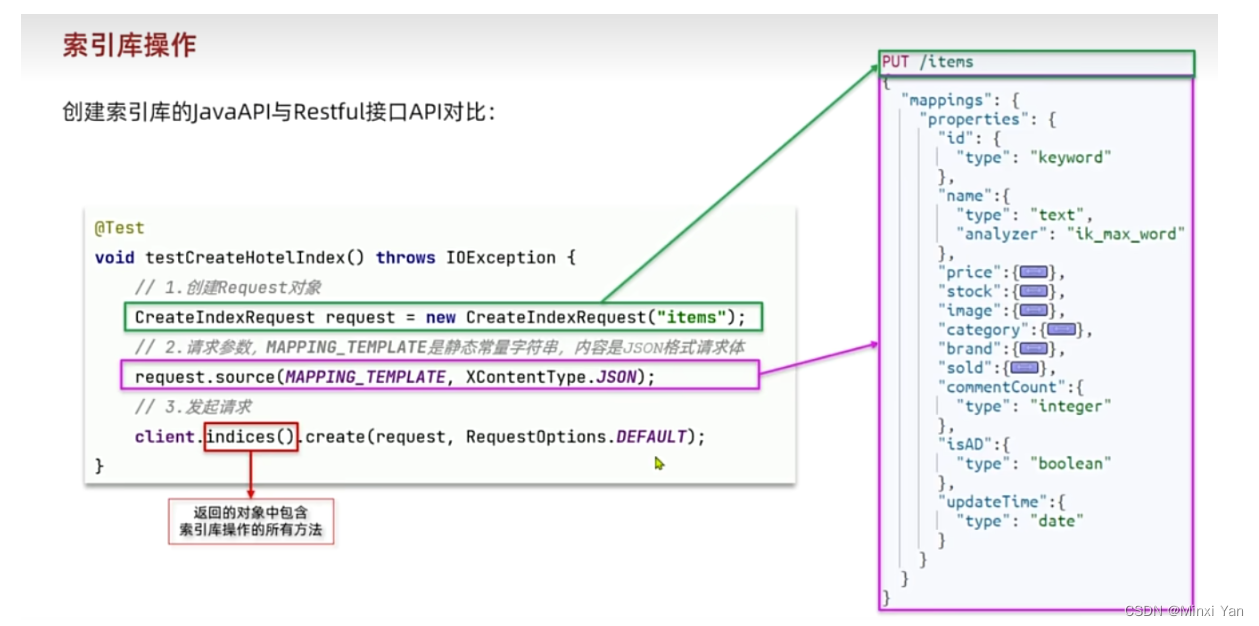
索引库操作
- 增
PUT /people
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
},
"mappings": {
"properties": {
"name": { "type": "text" },
"age": { "type": "integer" },
"birthday": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" },
"address": { "dynamic": "true", "type": "object" }
}
}
}
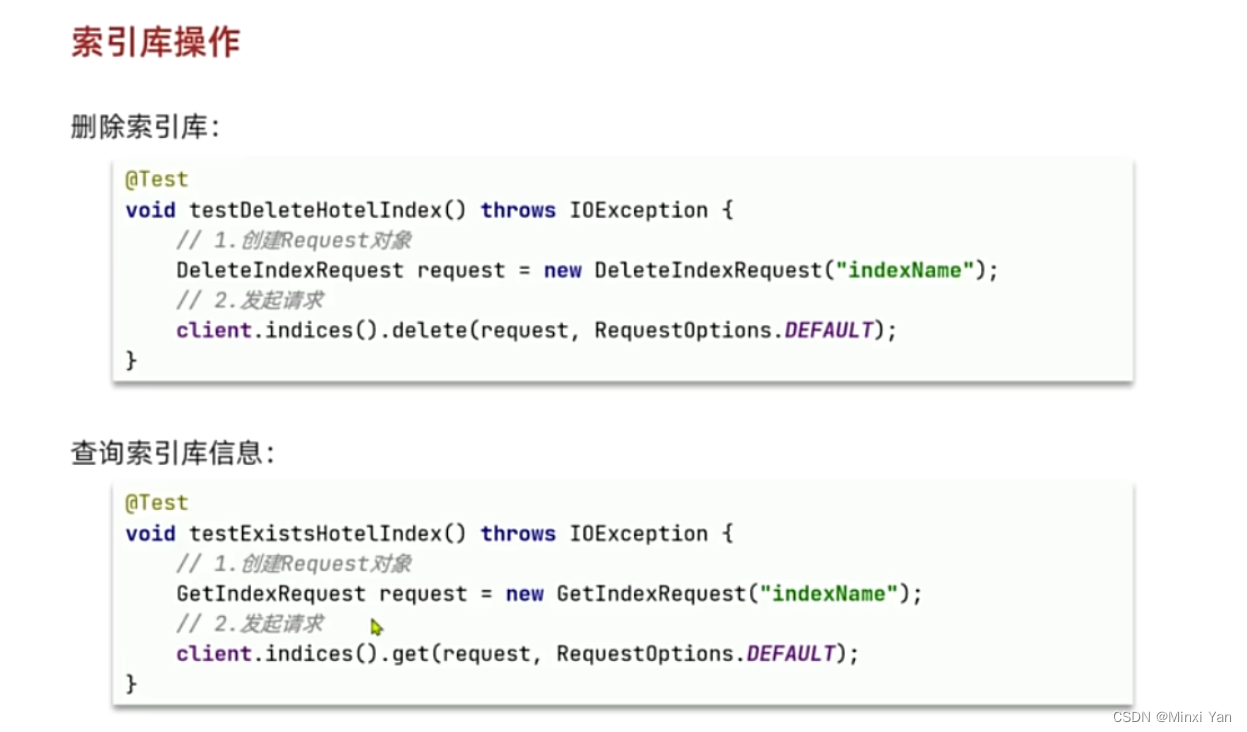
- 删
DELETE /people
- 改

PUT/people/_mapping
- 查
GET /people
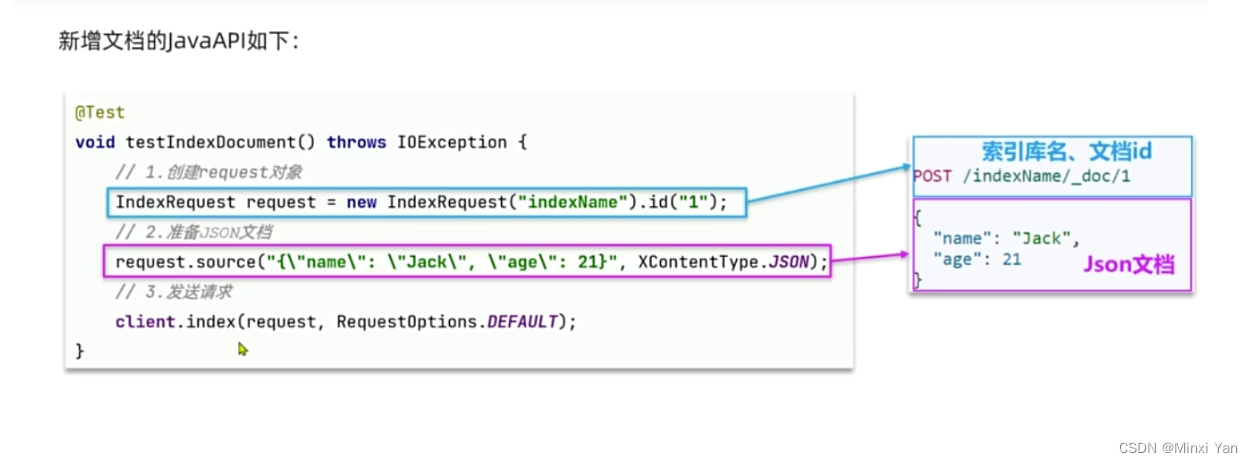
文档CRUD
- 增
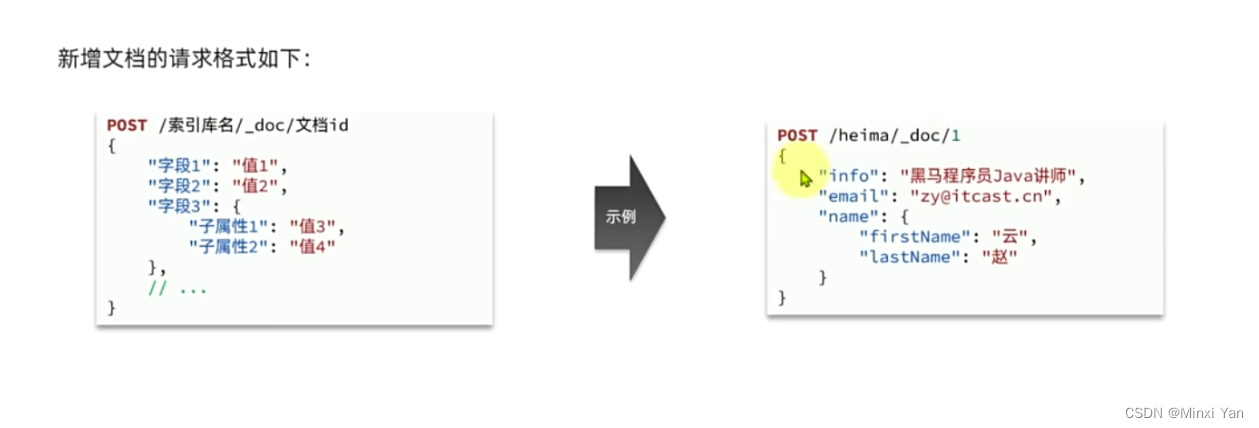
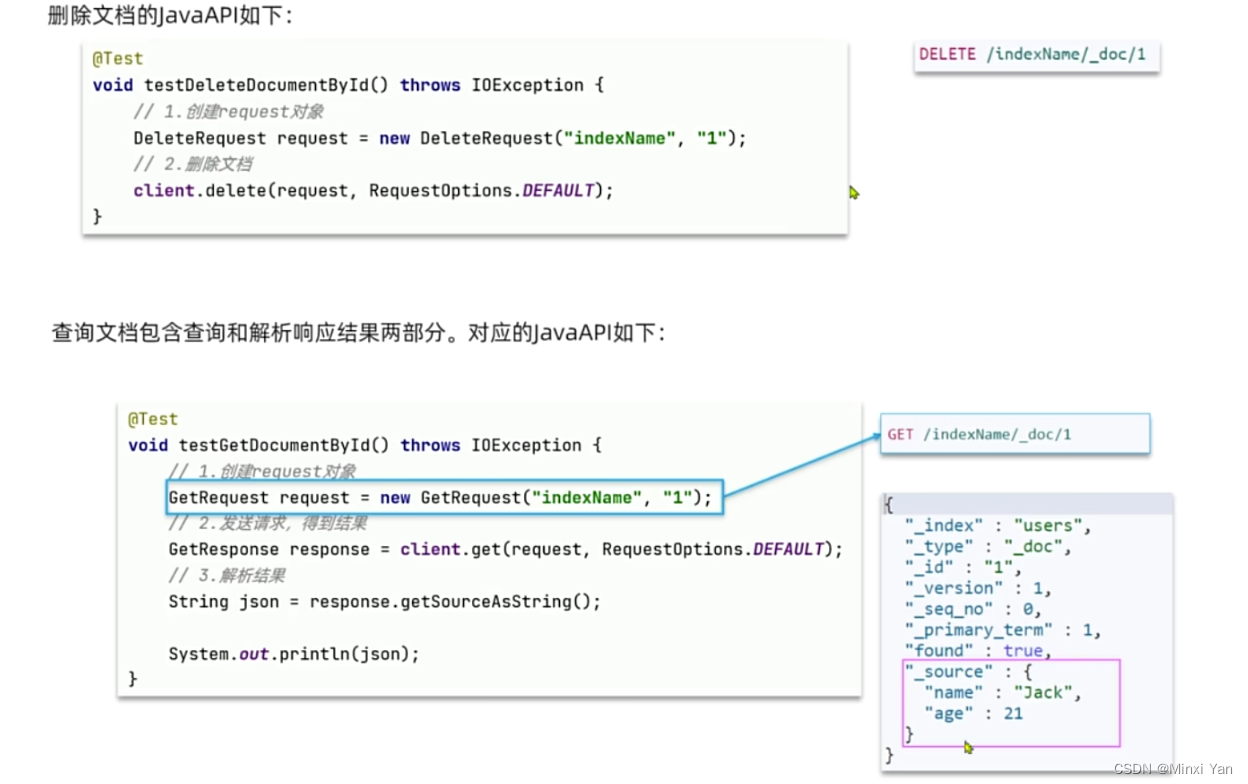
- 查
GET /heima/_doc/1
- 删除
DELETE /heima/_doc/1
- 改

批量处理

Java REST Template
索引库操作
文档操作

DSL


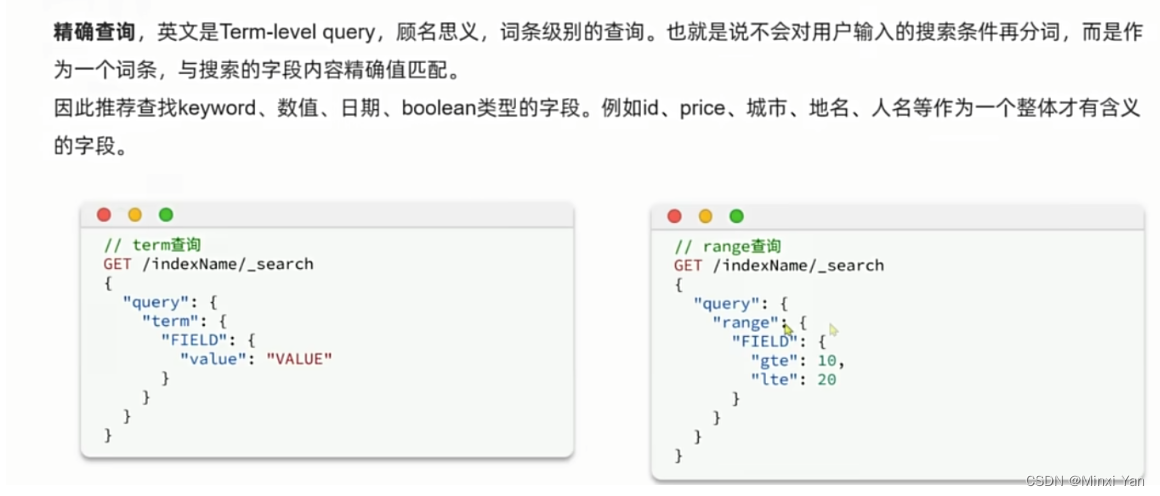

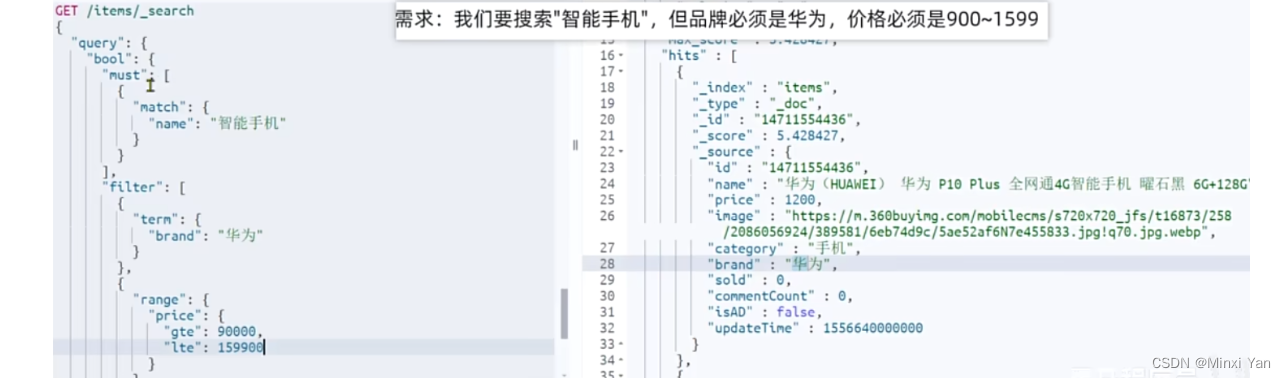
高亮
















 2902
2902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









