







第二章 数据预处理
1、数据挖掘中的数据
(1) 数据挖掘中使用的数据是数据对象及其属性的集合。属性是指对象的特性。
(2) 不同的属性类型:分类属性和数值属性;分类属性又分标称型和序数型,数值属性又分区间型和比率型。如性别为标称型,好坏等级为序数型,日期时间为区间型,分数为比率型。因此,根据属性的不同性质,属性可分为四种:标称、序数、区间、比例。
2、为什么要数据预处理
- 现实世界中的原始数据往往存在一定的质量问题:不完整的,有感兴趣的属性缺少属性值;含噪声的,包含错误或“孤立点”;不一致的,在命名或编码上存在差异
- 没有高质量的数据,就没有高质量的挖掘效果
- 意义和目的:提供干净、简洁、准确的数据,提高挖掘效率和准确性
3、数据预处理一般工作
包括:数据清理、数据集成、数据变换、数据归约、离散化及特征选择等。数据清理包括填写空缺数据,平滑噪声数据,识别、删除孤立点等。数据集成是集成多个数据库,数据立方体或文件。数据变换是对原始数据进行规范化和特征构造。数据归约是对数据集进行压缩表示及特征选择。数据离散化是通过概念分层和数据离散化来归约数据。
(1)抽样:用数据较小的随机样本表示大的数据集
- 数据挖掘使用抽样是因处理所有数据的费用太高、太费时间
- 有效抽样原理:使用样本与使用整个数据集的效果几乎一样
- 简单随机抽样:无放回抽样,有放回的抽样
- 分层抽样
- 应用场景:总体由不同类别的对象组成,每种类型的对象数量差别很大
- 利用聚类实现分层抽样:将数据集 D 划分成 m 个不相交的类,再在聚类结果的类上进行简单随机抽样
(2)噪声的处理方法
包括:分箱(将数据落入箱中来平滑数据)、聚类(通过聚类监测并且去除孤立点)、回归(通过让数据适应回归函数来平滑数据)。
中位数的定义:设给定的 N 个不同值的数据集按数值升序排序,如果 N 是奇数,则中位数是有序集的中间值,否则中位数是中间两个值的平均值。
中列数是指数据集中极大值与极小值的平均。
众数的定义:数据集中出现次数最多的值。
规范化
- 最小最大规范化(重点)
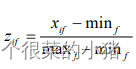
将值转化到区间[0,1] - z-score规范化(了解)
- 小数定标规范化(了解)
(3)数据归约策略
得到数据集的简约表示,可用产生几乎相同的分析结果
(4)特征提取
由原始数据创建新的特征集
(5)特征选择
选择具有代表性的特征,提高数据处理的效率,解决维数灾难(降维)问题
(6)离散化与概念分成
等宽离散化、等频离散化
4、相似度
(1)cosine相似度(余弦相似度)
两个向量的夹角余弦值为相似度
c
o
s
(
p
,
q
)
cos(p,q)
cos(p,q)=
p
⋅
q
∣
p
∣
2
∣
q
∣
2
\frac{p·q }{|p|^2 |q|^2}
∣p∣2∣q∣2p⋅q=
∑
i
=
1
m
q
i
p
i
(
∑
i
=
1
m
q
i
2
∑
i
=
1
m
p
i
2
)
\frac{\sum_{i=1}^{m} q_i p_i}{\sqrt (\sum_{i=1}^{m} q_i ^2\sum_{i=1}^{m} p_i^2)}
(∑i=1mqi2∑i=1mpi2)∑i=1mqipi















 8197
8197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









