







C++中的继承
一、继承的概念及定义
1.1 继承的概念
继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象程序设计的层次结构,
体现了由简单到复杂的认知过程。以前我们接触的复用都是函数复用,继承是类设计层次的复用。
class Person
{
public:
void Print()
{
cout << "name : " << _name << endl;
cout << "age : " << _age << endl;
}
protected:
string _name = "peter";
int _age = 18;
};
// 继承后父类的Person成员(成员函数+成员变量)都会变为子类的一部分
class Student : public Person
{
protected:
int _stuid; // 学号
};
class Teacher : public Person
{
protected:
int _jobid; // 工号
};
int main()
{
Student s;
Teacher t;
s.Print();
t.Print();
return 0;
}
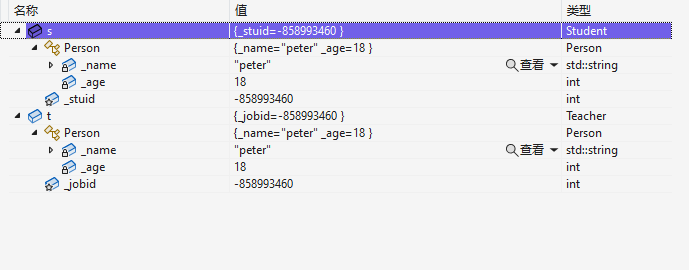
因此,继承就是让子类可以去使用父类的成员(继承了父类的所有成员)
1.2 继承的定义
下面我们看到Person是父类,也称作基类。Student是子类,也称作派生类。

继承关系和访问限定符:

公有对应3种方式、私有、保护也是
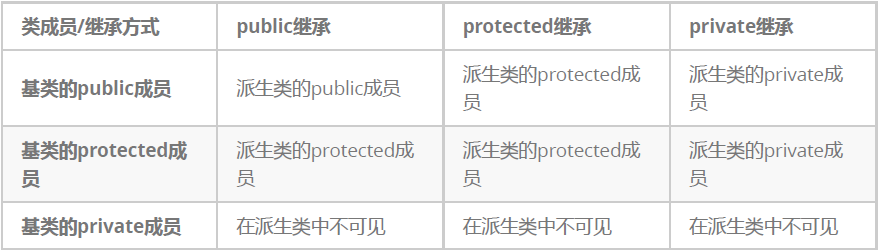
1、基类private成员在派生类中无论以什么方式继承都是不可见的。这里的不可见是指基类的私有成员还是被继承到了派生类对象中,但是语法上限制派生类对象不管在类里面还是类外面都不能去访问它。
class Person
{
public:
void Print()
{
cout << "name : " << _name << endl;
cout << "age : " << _age << endl;
}
protected:
string _name = "peter";
int _age = 18;
private:
int _aa;
};
// 继承后父类的Person成员(成员函数+成员变量)都会变为子类的一部分
class Student : public Person
{
protected:
int _stuid; // 学号
};
class Teacher : public Person
{
protected:
int _jobid; // 工号
};
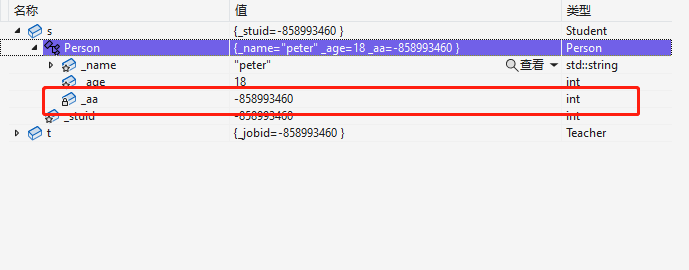
可以明显发现私有成员是继承了下来,但是是访问不了的
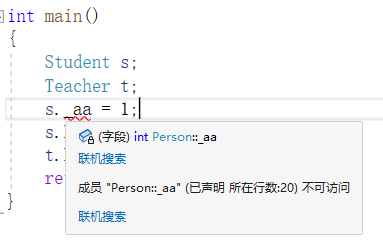
在类里面也没办法去访问
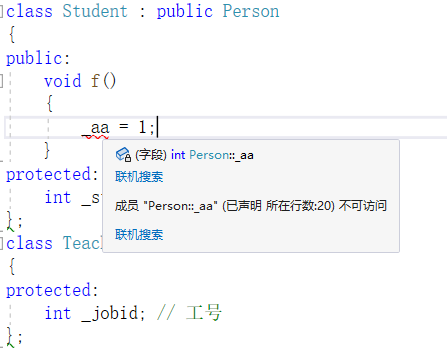
因此不可见的意思是在类外还是类里面都无法去访问
2、实际上面的表格我们进行一下总结会发现,基类的私有成员在子类都是不可见。基类的其他成员在子类的访问方式 == min(成员在基类的访问限定符,继承方式),public > protected > private。
3、基类private成员在派生类中是不能被访问,如果基类成员不想在类外直接被访问,但需要在派生类中能访问,就定义为protected。可以看出保护成员限定符是因继承才出现的。
protected:不想让别人来访问,但是想让子类可以访问就定义为保护
保护和私有在父类中没有区别
在子类中,private成员是不可见,protected是可见的
4、在实际运用中一般使用都是public继承,几乎很少使用protetced/private继承,也不提倡使用protetced/private继承,因为protetced/private继承下来的成员都只能在派生类的类里面使用,实际中扩展维护性不强。
常见继承方式:
父类成员:公有和保护
子类继承方式:公有继承
5、使用关键字class时默认的继承方式是private,使用struct时默认的继承方式是public,不过最好显示的写出继承方式。
class Student : Person
{
public:
protected:
int _stuid; // 学号
};
不写继承方式,默认是私有继承
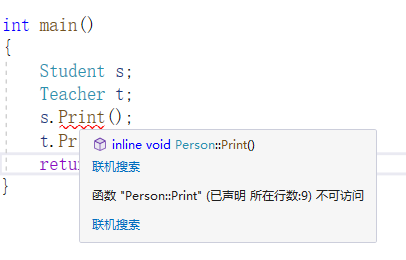
但是类里面可以用,这就是私有的意义
如果是写的struct,则默认就是公有继承
struct Student : Person
{
public:
protected:
int _stuid; // 学号
};
尽量不要去使用缺省,避免给自己找麻烦
注意继承方式选择的什么仅仅是影响继承下来的成员,而不影响子类中定义的公有、保护还是私有
// 继承后父类的Person成员(成员函数+成员变量)都会变为子类的一部分
class Student : private Person // 如果选择了私有继承方式 则Person中公有、保护都变为了私有,这样子就在类外无法去使用
{
public:
// 虽然是私有继承,但是他自己本身的public还是可以去使用的
// 上面继承方式影响的是父类继承下来的成员,不影响这个类定义的公有等
void f()
{
Print();
}
protected:
int _stuid; // 学号
};
class Teacher : public Person
{
protected:
int _jobid; // 工号
};
二、基类和派生类对象赋值转换
赋值兼容规则:派生类对象 可以赋值给 基类的对象 / 基类的指针 / 基类的引用。这里有个形象的说法叫切片或者切割。寓意把派生类中父类那部分切来赋值过去。
C++中同类型的对象可以互相赋值(int给int,自定义类型就需要去调用默认生成或者自己定义的)
不同类型对象之间可以互相赋值吗?——可以,相关类型可以隐式类型转化,不相关类型进行显示类型转化
那如果父类给子类/子类给父类呢?
父类 = 子类
class Person
{
protected:
string _name;
string _sex;
int _age;
};
class Student : public Person
{
public:
int _No; // 学号
};
int main()
{
Person p;
Student s;
// 父类 = 子类赋值 -> 切割/切片(这里仅限于公有继承)
// 这里不存在类型转化,是语法天然支持行为
p = s;
Person* ptr = &s;
Person& ref = s; // 这里不需要加const,因为不是类型转化,没有产生临时变量
return 0;
}
因此父类 = 子类赋值 -> 切割/切片(这里仅限于公有继承)是可以的
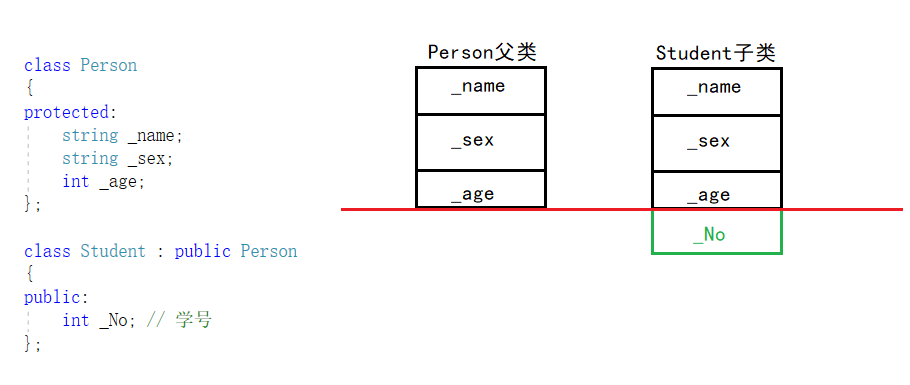
将子类中包含父类的那些成员赋值过去,这个过程就叫做切割或者切片,不仅可以给父类对象,也可以父类的指针或者是父类的引用
int main()
{
int i = 1;
double d = 2.2;
i = d;
return 0;
}
这里不是直接把d赋值给i,中间要产生一个临时变量
int main()
{
int i = 1;
double d = 2.2;
int& ri = d; // 会报错
return 0;
}
ri不能引用d,因为中间有类型转化,中间产生临时变量,临时变量具有常性,所以他不行,如何解决?——加const const int& ri = d;
私有/保护继承就不能实现切割和切片了——为什么?
class Person
{
protected:
string _name;
string _sex;
public:
int _age;
};
class Student : private Person
{
public:
int _No; // 学号
};
int main()
{
Person p;
Student s;
// 私有继承以下都不能使用了
p = s; // 切割切片时,右边变为私有,左边还是公有和保护,就没办法实现了,权限发生了变化
Person* ptr = &s;
Person& ref = s;
int i = 1;
double d = 2.2;
int& ri = d;
return 0;
}
若是私有继承,从Person来看这些成员还是公有和保护的,在子类中他是私有的,这样子就不合适了,因此不行
子类 = 父类

不可以这样子,子赋值给父的时候,子的成员多,可以进行切片,但是父给子,就不够了,因此不能这样子
但是在这里仅仅是对象之间赋值不行,指针和引用是可以的,只需要加强制类型转换
int main()
{
Person p;
Student s;
// s = (Student)p; // 不行
Student* pptr = (Student*)&p;
Student& rref = (Student&)p;
return 0;
}
但是会存在越界风险
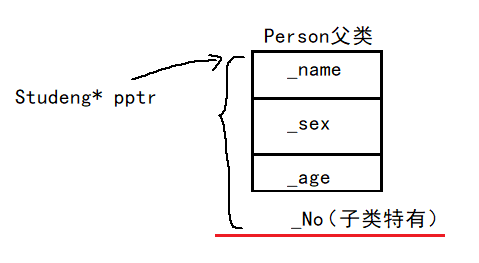
下面多余的这段空间不是我的,所以很危险
int main()
{
Person p;
Student s;
// s = (Student)p; // 不行
Student* pptr = (Student*)&p; // 因为原本子类是有_No的,但是父类是没有的,子类访问父类的_No就会越界
Student& rref = (Student&)p;
pptr->_No = 1; // 就会越界,因为_No不是我的
return 0;
}
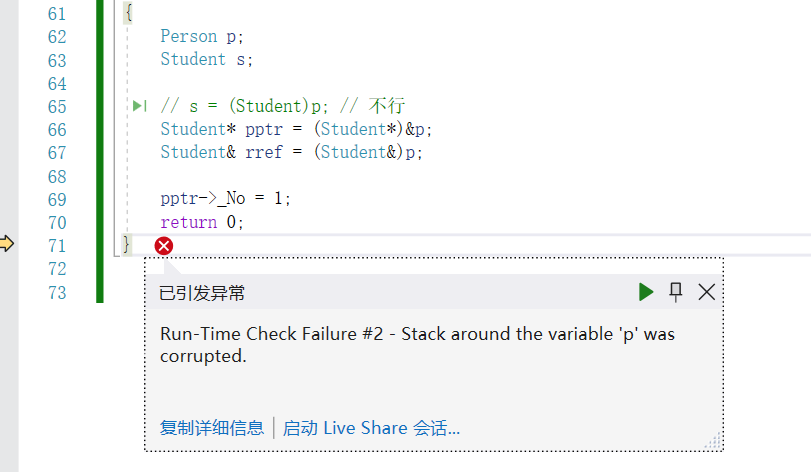
因此尽量不去使用子类(多) = 父类(少)
三、继承中的作用域
- 在继承体系中基类和派生类都有独立的作用域。
- 子类和父类中有同名成员,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫隐藏,也叫重定义。(在子类成员函数中,可以使用 基类::基类成员 显示访问)
- 需要注意的是如果是成员函数的隐藏,只需要函数名相同就构成隐藏,参数可以相同,也可以不相同。
- 注意在实际中在继承体系里面最好不要定义同名的成员。
int a = 0;
int main()
{
int a = 1;
cout << a << endl; // 访问局部
cout << ::a << endl; // 想要访问外部需要加作用域
return 0;
}
同样的,当基类和子类有同名变量时,是可以同时存在的
class Person
{
protected:
string _name = "zmm";
int _num = 111;
};
class Student : public Person
{
public:
void Print()
{
cout << "姓名:" << _name << endl;
cout << _num << endl; // 访问自己的_num,就近原则
}
protected:
int _num = 999;
};
在这里Student就有两个_num,想要访问基类的也应该加作用域
class Person
{
protected:
string _name = "zmm";
int _num = 111;
};
class Student : public Person
{
public:
void Print()
{
cout << "姓名:" << _name << endl;
cout << _num << endl;
cout << Person::_num << endl; // 想要访问父类的,应该指定作用域
}
protected:
int _num = 999;
};
子类和父类出现同名成员:隐藏/重定义——子类会隐藏父类的同名成员
问题1:
class A
{
public:
void fun()
{
cout << "func()" << endl;
}
};
class B : public A
{
public:
void fun(int i)
{
cout << "func(int i)->" << i << endl;
}
};
void Test()
{
B b;
b.fun(10);
};
1:A和B中的func构成函数重载
2:编译报错
3:运行报错
4:A和B的func构成函数隐藏
答案——4
他们不构成函数重载——因为函数重载要求在同一作用域,虽然func继承下来了,但是从定义的角度来说,两个是独立的作用域,他们构成隐藏
成员函数只要函数名相同就构成隐藏(无论参数是否相同还是不相同都不影响)
问题2:
class A
{
public:
void fun()
{
cout << "func()" << endl;
}
};
class B : public A
{
public:
void fun(int i)
{
cout << "func(int i)->" << i << endl;
}
};
void Test()
{
B b;
b.fun(); // 和第一题不一样的在这里
};
1:A和B中的func构成函数重载
2:编译报错
3:运行报错
4:A和B的func构成函数隐藏
答案——2
两个func构成了隐藏,下面的func就隐藏了上面的func,所以无法访问到无参的func了,如果想去调用,必须指定作用域
void Test()
{
B b;
b.A::fun();
};
补充
// 无法编译通过
typedef reverse_iterator<iterator, T&, T*> reverse_iterator;
typedef reverse_iterator<const_iterator,const T&,const T*> const_reverse_iterator;
// 可以编译通过
typedef reverse_iterator<const_iterator, const T&, const T*> const_reverse_iterator;
typedef reverse_iterator<iterator, T&, T*> reverse_iterator;
这里就是作用域的问题:
typedef reverse_iterator<const_iterator,const T&,const T*> const_reverse_iterator;
这里的reverse_iterator就要向上找这个类,但是他是优先在局部中找,在他的上一行刚刚定义了一个reverse_iterator,这样子就不会去zmm这个类里面去找reverse_iterator了
而第二种能编译通过是因为在当前局部找,找不到定义的reverse_iterator,所以要去外部找
所以这里编译不通过的解决方法有两种,一种是上述交换下顺序,第二种就是指定作用域
typedef reverse_iterator<iterator, T&, T*> reverse_iterator;
typedef zmm::reverse_iterator<const_iterator,const T&,const T*> const_reverse_iterator;
四、派生类的默认成员函数
派生类重点的四个默认成员函数,我们不写编译器会默认生成会干些什么事情?
如果我们要写,应该做什么事情?
class Person
{
public:
Person(const char* name = "peter")
: _name(name)
{
cout << "Person()" << endl;
}
Person(const Person& p)
: _name(p._name)
{
cout << "Person(const Person& p)" << endl;
}
Person& operator=(const Person& p)
{
cout << "Person operator=(const Person& p)" << endl;
if (this != &p)
_name = p._name;
return *this;
}
~Person()
{
cout << "~Person()" << endl;
}
protected:
string _name; // 姓名
};
class Student : public Person
{
public:
protected:
int _num; //学号
};
int main()
{
Student s;
return 0;
}
因此,如果我们不去写默认生成的派生类的构造和析构:
1、父类继承下来的(调用父类的默认构造函数和析构函数)
2、自己的(内置类型和自定义类型)(与普通类一样——内置类型完成值拷贝、浅拷贝,对于自定义类型调用它的拷贝构造)
 可以发现对于内置类型不进行处理,如果是自定义类型就调用它的默认构造函数去进行初始化
可以发现对于内置类型不进行处理,如果是自定义类型就调用它的默认构造函数去进行初始化
如果我们不去写默认生成的拷贝构造和operator=呢?
1、父类继承下来的(去调用父类的默认构造函数和析构函数)
2、自己的(内置类型和自定义类型)(与普通类一样——内置类型完成值拷贝、浅拷贝,对于自定义类型调用它的拷贝构造)
继承下来调用父类的处理,自己的按原来的基本规则进行处理
什么情况下必须自己写?如果我们要自己写怎么办?如何写?
Person(const char* name) // 将原先的修改Person(const char* name = "peter")
: _name(name)
{
cout << "Person()" << endl;
}
这样子就会报错,为什么修改后就会报错?——因为父类没有默认的构造函数
对于原先的Student,对自己的成员好进行处理,但是对父类的处理方式是去调用父类的默认构造,此时父类是没有默认的构造函数,所以就报错了
1、因此父类没有默认构造,就需要我们自己去写构造
那么什么时候需要我们自己去写析构?
2、如果子类有资源需要去释放,就需要自己显示写析构
class Student : public Person
{
public:
protected:
int _num = 1; //学号
string _s = "hello world"; // 缺省值
int* _ptr = new int[10]; // 这里就需要自己去写
};
3、如果子类存在浅拷贝问题,就需要自己完成拷贝构造和赋值解决浅拷贝问题
那么我们就自己实现构造函数:
class Student : public Person
{
public:
Student(const char* name = "zmm", int num = 1) // 首先要有父类的成员,以及自己的
:_name(name)
,_num(num)
{
}
protected:
int _num = 1; //学号
// string _s = "hello world"; // 缺省值
// int* _ptr = new int[10];
};
可以像如上的代码这样子写吗?——不能

怎么写?——父类成员调用父类对应的构造、拷贝构造、operator=和析构进行处理
Student(const char* name = "zmm", int num = 1) // 首先要有父类的成员,以及自己的
:Person(name) // 必须显示的去调用父类的构造函数
, _num(num)
{}
class Student : public Person
{
public:
Student(const char* name = "zmm", int num = 1) // 首先要有父类的成员,以及自己的
:Person(name) // 必须显示的去调用父类的构造函数
,_num(num)
{
}
// s2(s1) 把s1父类部分赋值给s2父类部分
Student(const Student& s) // 这里的s就是s1
:Person(s) // 这里要传一个父类对象,子类对象传给父类会自动切片
,_num(s._num)
{}
// s2 = s1
Student& operator=(const Student& s)
{
if (this != &s)
{
// 这里会有问题,因为父子函数同名,会优先调用自己的,就无限递归
// operator=(s); // 把子类对象传过去进行切片,父类的那一部分就出来了
Person::operator=(s); // 把子类对象传过去进行切片,父类的那一部分就出来了
_num = s._num;
}
return *this;
}
~Student()
{
// ~Person(); 这里不能这么去调用
// 析构函数的名字会被统一处理为destructor()(为什么会处理为这个?后续多态解释)
// 那么子类的析构函数和父类的析构函数就会构成隐藏,所以要加域限定符
Person::~Person();
// delete[] _ptr; // 假设有 int* _ptr = new int[10];
}
protected:
int _num = 1; //学号
// string _s = "hello world"; // 缺省值
// int* _ptr = new int[10];
};
因此子类自己成员就按正常的方式处理
继承下来的东西调父类的处理,父类就要去调用父类自己的
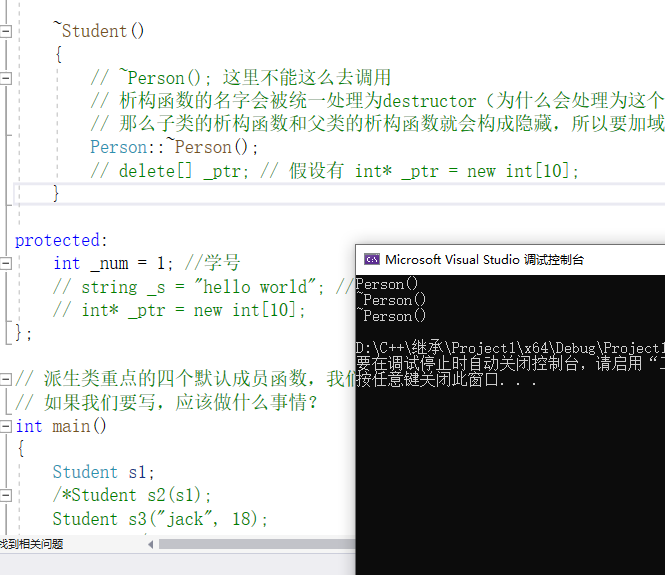
那么按照目前完成的部分,执行代码会发现会调用两次析构函数,这是为什么?
因为子类的析构函数不需要去显示的去调用,否则还会调用一次
子类析构函数结束时,会自动调用父类的析构函数
因此析构函数应该是下面这种形式
class Student : public Person
{
public:
~Student()
{
}
protected:
int _num = 1; //学号
};
那么这是为什么?
因为子类对象有两部分:一部分是子类自己的,还有一部分是父类继承下来的。他们定义在栈里,s1先构造,s2后构造;s2先析构,s1后析构,这里也一样
先父类构造,然后子类构造,之后子类先析构,父类后析构,因此刚刚如果子类析构函数里面包含了父类析构函数,就直接把父类先给析构了,所以就出现了问题,因此为了子类先析构,在出了子类析构函数作用域后自动去调用父类析构,因此不需要去显示调用
我们在自己实现子类析构函数时,不需要显示的调用父类析构函数
总结:
子类自己的成员就按以前的方式(普通类进行处理)
继承的成员去调用父类的几个默认成员函数去处理
五、继承与友元
友元关系不能继承,也就是说基类友元不能去访问子类的私有和保护成员
class Student;
class Person
{
public:
friend void Display(const Person& p, const Student& s);
protected:
string _name; // 姓名
};
class Student : public Person
{
protected:
int _stuNum; // 学号
};
void Display(const Person& p, const Student& s)
{
cout << p._name << endl;
cout << s._stuNum << endl; // 这一句是不行的
}
int main()
{
Person p;
Student s;
Display(p, s);
}

因为只说明了他是父类的朋友,并没有说他是子类的朋友,想解决的话在加入一个友元
class Student : public Person
{
friend void Display(const Person& p, const Student& s);
protected:
int _stuNum; // 学号
};
因此是父类的友元,并不是子类的友元
六、继承与静态成员
基类定义了static静态成员,则整个继承体系里面只有一个这样的成员。无论派生出多少个子类,都只有一个static成员实例 。也就是说普通成员继承下来有一份,而静态成员继承下来只有唯一一份,都是一样的。
class Person
{
public:
Person() { ++_count; }
protected:
string _name; // 姓名
public:
static int _count; // 统计人的个数。
};
int Person::_count = 0;
class Student : public Person
{
protected:
int _stuNum; // 学号
};
class Graduate : public Student
{
protected:
string _seminarCourse; // 研究科目
};
int main()
{
Person p;
Student s;
Graduate g;
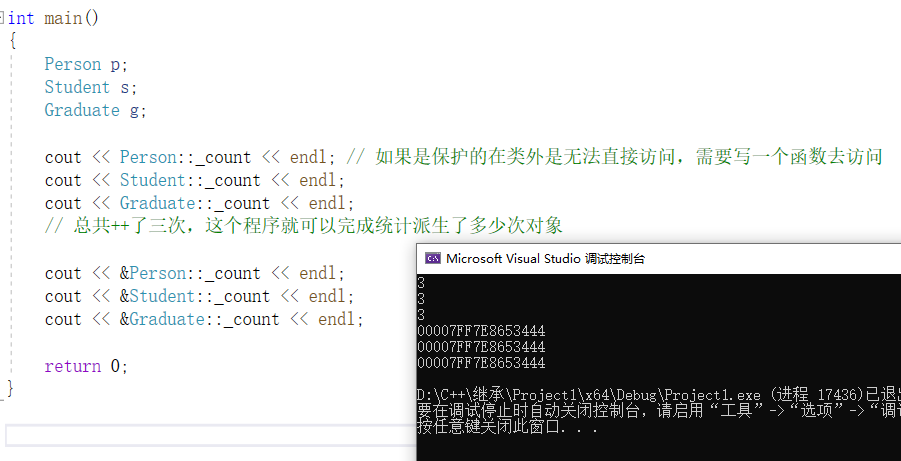
cout << Person::_count << endl; // 如果是保护的在类外是无法直接访问,需要写一个函数去访问
cout << Student::_count << endl;
cout << Graduate::_count << endl;
// 总共++了三次,这个程序就可以完成统计派生了多少次对象
cout << &Person::_count << endl;
cout << &Student::_count << endl;
cout << &Graduate::_count << endl;
return 0;
}
七、菱形继承及菱形虚拟继承
单继承:一个子类只有一个直接父类的继承关系称为单继承
多继承:一个子类有两个或以上直接父类时称这个继承关系为多继承
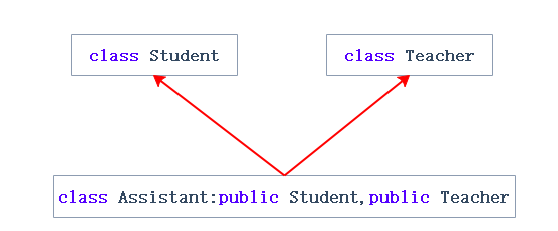
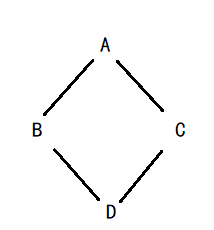
菱形继承:菱形继承是多继承的一种特殊情况(只要最上面有公共的祖宗就是菱形继承,形状不一定如下图所示)
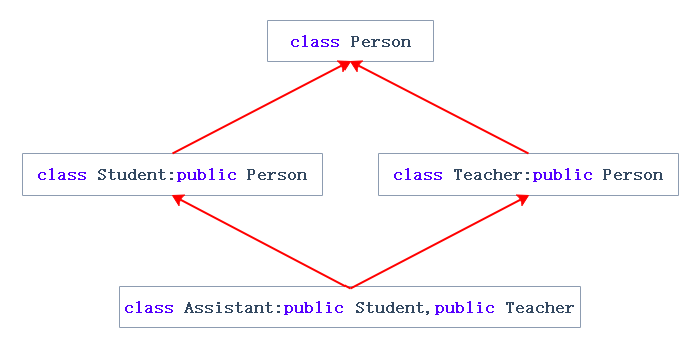
Assistant 存在数据冗余和二义性,因为有两份person(学生有一份person,老师也有一份person)
使用的时候不要去使用菱形继承
class Person
{
public:
string _name; // 姓名
};
class Student : public Person
{
public:
int _num; //学号
};
class Teacher : public Person
{
public:
int _id; // 职工编号
};
class Assistant : public Student, public Teacher
{
protected:
string _majorCourse; // 主修课程
};
int main()
{
Assistant a;
a._id = 1;
a._num = 2;
a._name = "zhangsan"; // 二义性
return 0;
}
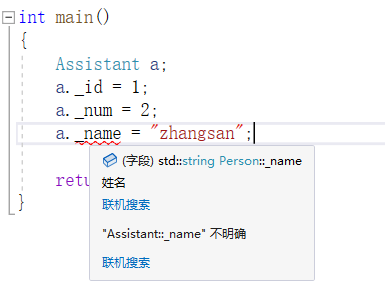
指定作用域是可以解决二义性的
int main()
{
Assistant a;
a._id = 1;
a._num = 2;
// a._name = "zhangsan";
a.Student::_name = "zhangsan";
a.Teacher::_name = "lisi";
return 0;
}
但是这里还是有问题.
class Person
{
public:
string _name; // 姓名
int _a[1000];
};
如果是这种场景,会继承下来两份数组,就造成了数据冗余
如何解决?——虚继承解决数据冗余和二义性
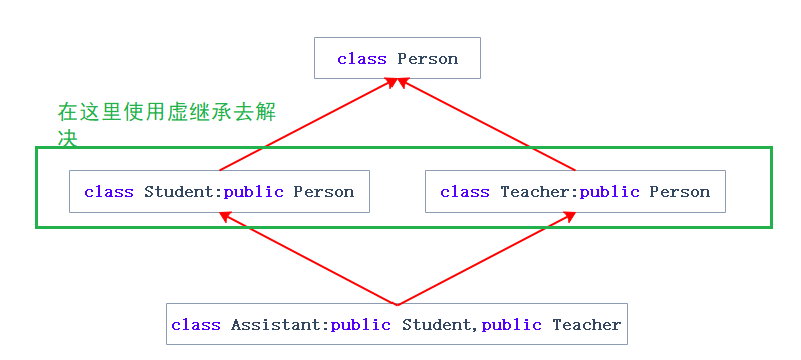
class Person
{
public:
string _name; // 姓名
int _a[1000];
};
class Student : virtual public Person
{
public:
int _num; //学号
};
class Teacher : virtual public Person
{
public:
int _id; // 职工编号
};
class Assistant : public Student, public Teacher
{
protected:
string _majorCourse; // 主修课程
};
int main()
{
Assistant a;
a._id = 1;
a._num = 2;
a.Student::_name = "zhangsan";
a.Teacher::_name = "lisi";
a._name = "阿巴阿巴";
return 0;
}
改为虚继承以后:
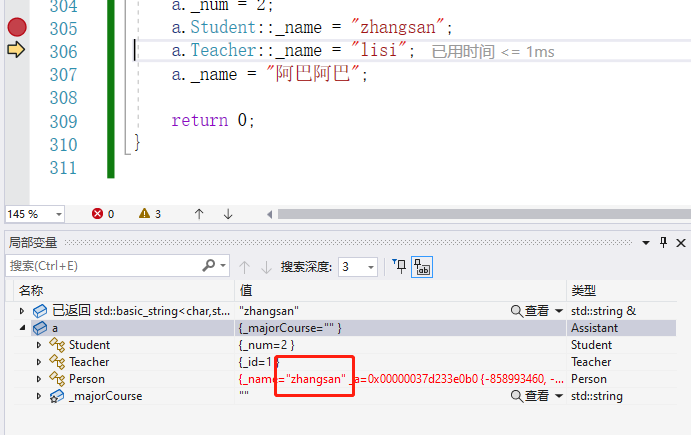
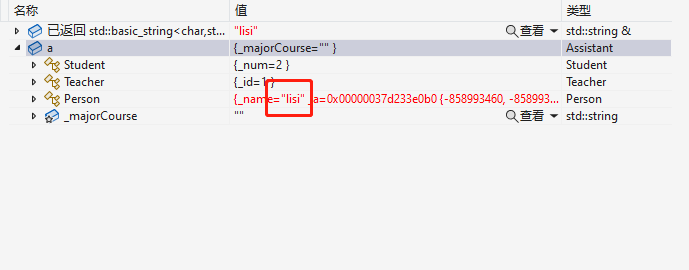
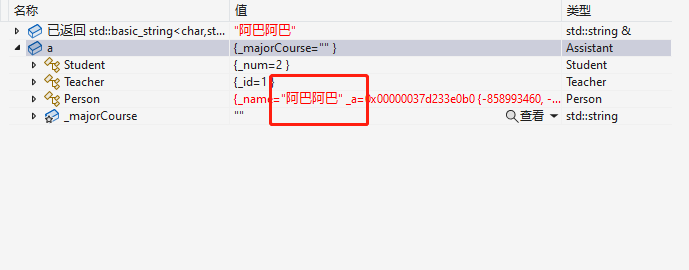
这时候三者访问的都是同一个,就没有了数据冗余
由于监视窗口是编译器做过优化后,无法从底层去查看他具体是什么样,所以我们借助内存窗口去进行观察对象成员的模型
C++对象模型可以概括为以下2部分:
1、语言中直接支持面向对象程序设计的部分;
2、对于各种支持的底层实现机制。
对象模型表示静态的、结构化的系统的“数据”性质。
对象模型:对象的成员在底层的内存上是如何存储的
class A
{
public:
int _a;
};
// class B : public A
class B : virtual public A
{
public:
int _b;
};
// class C : public A
class C : virtual public A
{
public:
int _c;
};
class D : public B, public C
{
public:
int _d;
};
int main()
{
D d;
d.B::_a = 1;
d.C::_a = 2;
d._b = 3;
d._c = 4;
d._d = 5;
return 0;
}
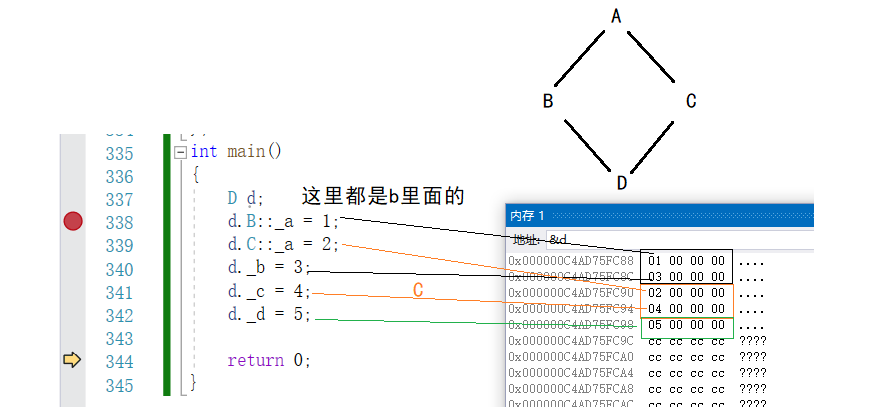
我们通过内存窗口来进行查看
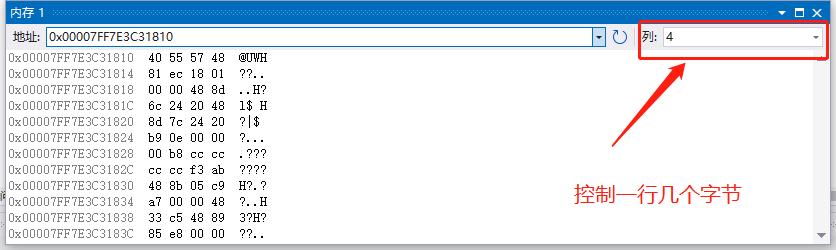
在非虚继承的情况下:
class B : public A
{
public:
int _b;
};
class C : public A
{
public:
int _c;
};

class D : public B, public C是先继承B在继承C,在内存中也是这样
class D : public C, public B是先继承C在继承B
改为虚继承
class A
{
public:
int _a;
};
class B : virtual public A
{
public:
int _b;
};
class C : virtual public A
{
public:
int _c;
};
class D : public B, public C
{
public:
int _d;
};
int main()
{
D d;
d.B::_a = 1;
d.C::_a = 2;
d._b = 3;
d._c = 4;
d._d = 5;
d._a = 0;
return 0;
}
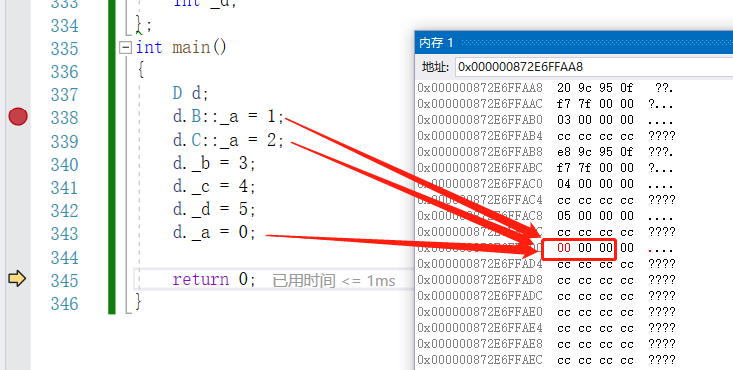
在这里,a就放在了一个公共的地方

虚继承中,A一般称为虚基类,在D里面,A会放在一个公共的位置,有时候B和C需要去找A,就通过虚基表中偏移量来计算
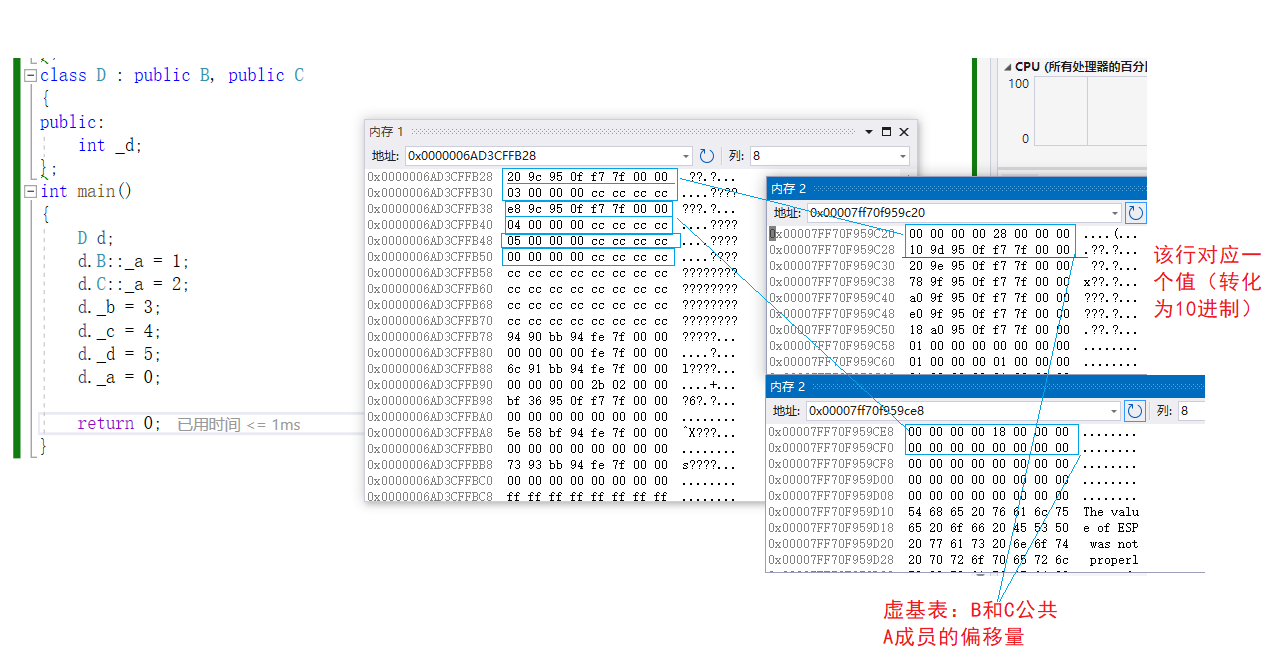
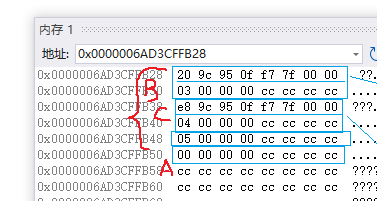
根据这个偏移量,就可以用来计算B起始到A的偏移量
B b = d;
C c = d;
这个时候,就会发生切片
B里面还有_a,需要找到_a位置,就需要虚基表来找偏移量
B* pb = &d;
pb->_a = 10;
这里找到公共的虚基类,也需要使用虚基表来找偏移量
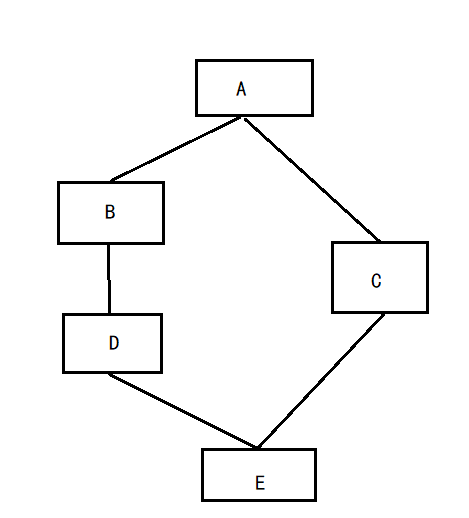
该图中,是在何处进行虚继承?——在B、C处进行虚继承(因为数据冗余和二义性是在直接继承A的地方出现的,在A类出现的数据冗余和二义性)之后因虚基表存放偏移量,以便去查找公共的类
八、继承总结
8.1 多继承以及菱形继承
有了多继承,就存在菱形继承,有了菱形继承就有菱形虚拟继承,底层实现就很复杂。所以一般不建议设计出多继承,一定不要设计出菱形继承。否则在复杂度及性能上都有问题。
多继承可以认为是C++的缺陷之一(目前了解到的缺陷还有C++没有垃圾回收器,new了后需要自己去主动释放)
8.2 继承与组合
继承是为了复用,但是还有其他复用的方式吗?——组合也是一种复用
class A
{
int _a;
};
class B : public A // 继承 (B就是A --- is a关系)
{
int _b; // B可以直接去访问A的公有和保护
};
class C
{
int _c;
};
class D // 组合
{
// 想复用C可以这样用吗?
C _obj; // 可以
// D只能使用C的公有,不能直接使用保护成员
int _d;
};
- public继承是一种is-a的关系。也就是说每个派生类对象都是一个基类对象。(如Person和Student,Student就是一个人,子类就是一个特殊的父类,这种情况就用继承)
- 组合是一种has-a的关系。假设B组合了A,每个B对象中都有一个A对象。(眼睛和头的关系)
- 若两种关系都说得通的时候,优先用组合,而非使用继承;完全符合is-a就用继承,完全符合has-a就用组合,两种都可以用,就用组合
- 继承允许你根据基类的实现来定义派生类的实现。这种通过生成派生类的复用通常被称为白箱复用(white-box reuse)。术语“白箱”是相对可视性而言:在继承方式中,基类的内部细节对子类可见 。继承一定程度破坏了基类的封装,基类的改变,对派生类有很大的影响。派生类和基类间的依赖关系很强,耦合度高。
- 对象组合是类继承之外的另一种复用选择。新的更复杂的功能可以通过组装或组合对象来获得。对象组合要求被组合的对象具有良好定义的接口。这种复用风格被称为黑箱复用(black-box reuse),因为对象的内部细节是不可见的。对象只以“黑箱”的形式出现。 组合类之间没有很强的依赖关系,耦合度低。优先使用对象组合有助于你保持每个类被封装。
- 实际尽量多去用组合。组合的耦合度低,代码维护性好。不过继承也有用武之地的,有些关系就适合继承那就用继承,另外要实现多态,也必须要继承。类之间的关系可以用继承,可以用组合,就用组合。
白箱和黑箱区别是什么?
白箱和黑箱也叫作白盒和黑盒——对你透明还是不透明,能不能看到他的实现细节
白盒测试与黑盒测试中要求更高的是白盒测试(因为清楚内部实现,根据源代码和功能去写测试用例,这样子就需要各种情况都要测试,白盒要求要求测试者要看懂代码)
上文提及的白箱复用,对继承而言,除了父类的私有成员都是透明的,私有对子类是不可见的(实际上是很少去定义私有,一般是定义保护和公有)保护和公有是可以直接去复用的,可以去使用的,白箱某种程度上就破坏了封装
类之间、模块(C++中,会把模块打为动态库等互相用,这一个块就叫模块)之间的关系最好是低耦合(类与类之间的关系越弱越好)、高内聚(内部成员之间关系非常紧密,与类无关的东西不要塞入同一个类,一个类里面成员关联度要非常高),它的好处是方便维护(程序写好后,还可以更好的升级,加功能等)
```cpp
class A
{
int _a;
};
class B : public A
{
int _b;
};
class C
{
int _c;
};
class D
{
C _obj;
int _d;
};
A类若有5个公有成员、5个保护成员,C类也一样,对于D类而言,有关联关系的只有5个公有成员,C类更改了保护对D类是没有影响的(组合)
但是对于继承而言,任意一个成员的修改都会对自己有影响(因为公有保护都可以用)
UML设计中用例图、类图等,一个工程有很多功能,画出各个类之间的功能,各个类之间关系为低耦合这样子就很好,修改了一个类不会影响很多类,因此需要各个类之间关系很少
既然组合这么好,可以抛弃继承吗?——不行
要切割切片,传递对象就是一个优势,D对象不能直接赋值给C对象,而且多态是建立在继承的基础上














 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









