







- 在Pig Latin中主要有六类关系运算符,分别为加载和存储、诊断、分组和连接、过滤、排序、合并和拆分。使用这六类运算符,再结合通用运算符,能够对本地货HDFS集群中的数据进行分析。
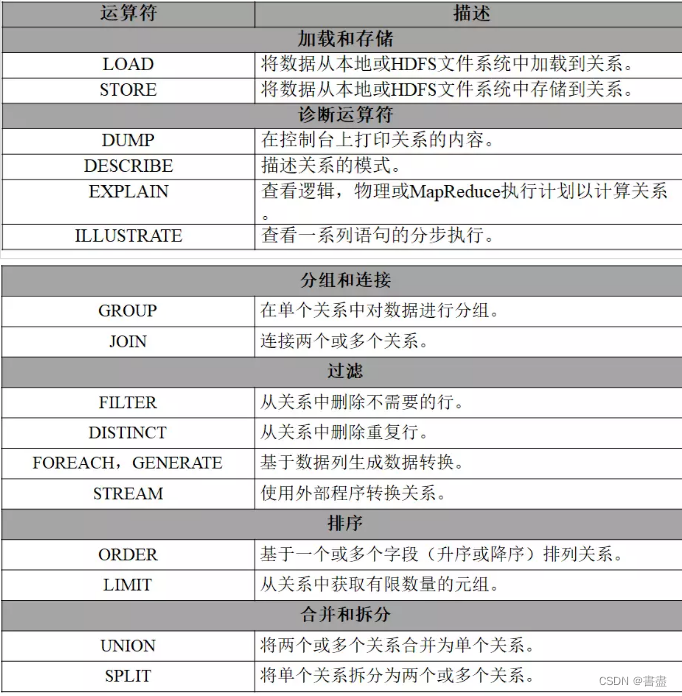
一、加载和存储运算符
- 包含两个运算符:LOAD和 STORE,用于从本地或者HDFS文件系统中加载或存储到关系中。
1. LOAD
- 主要包含两个部分,使用等号分隔,等号左侧指定存储数据的关系,右侧需要定义存储数据的方式。
Relation_name = LOAD 'Input file path' USING function as schema;
- Relation_name: 数据保存的目标关系名称
- Input file path 数据保存的路径, 可以是本地或者hdfs路径。如果是hdfs中的数据,格式为:“hdfs://localhost:9000/path"
- function 必须从Apache Pig中提供的一组加载函数中选择一个函数,
PigStorage() 加载和存储结构化文件
TextLoader() 将非结构化数据加载到Pig中
BinStorage() 使用机器可读写格式将数据加载并存储到Pig中
JsonLoader() 将非Json数据加载到Pig中
- schema 数据模式,加载数据时必须指定数据模式,语法格式如下:
(column1:data type,column2:data type,column3:data type);
示例
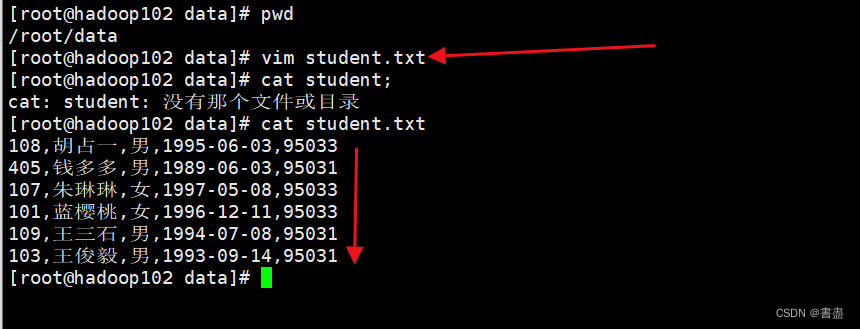
创建数据文件
- 在Linux主机中创建student.txt文件,并输入内容,列之间使用逗号分隔,保存到主目录中
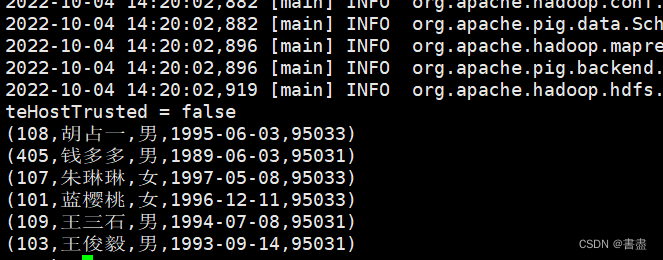
108,胡占一,男,1995-06-03,95033
405,钱多多,男,1989-06-03,95031
107,朱琳琳,女,1997-05-08,95033
101,蓝樱桃,女,1996-12-11,95033
109,王三石,男,1994-07-08,95031
103,王俊毅,男,1993-09-14,95031
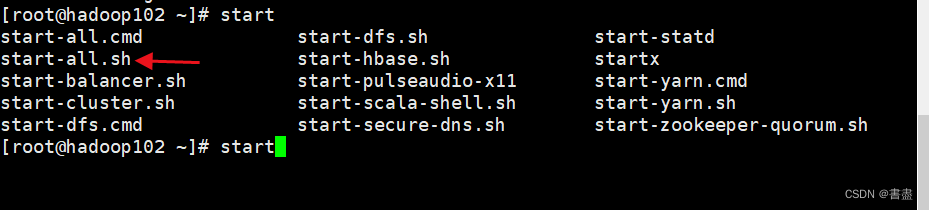
- 启动hadoop服务器
start-all.sh
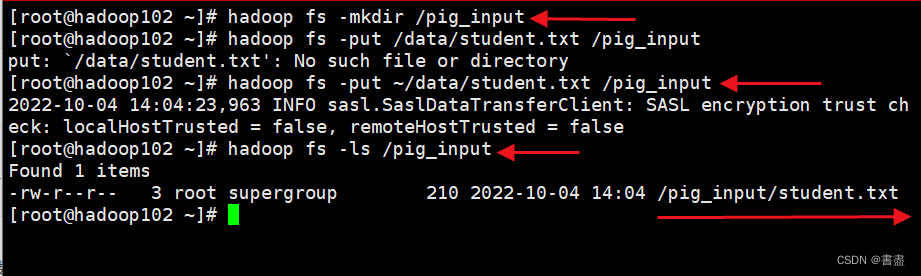
- 创建hdfs文件夹,并上传到新建的文件夹中
hadoop fs -mkdir /pig_input
hadoop fs -put ~/data/student.txt /pig_input
hadoop fs -ls /pig_input
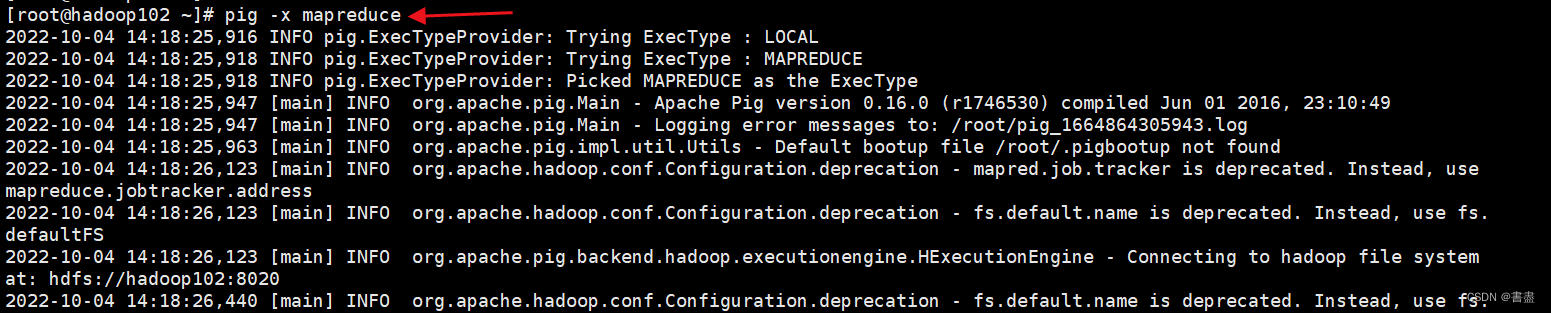
- 以HDFS模式启动Grunt Shell,将student.txt中的数据加载到Pig中。使用Pig加载HDFS数据时需要启动hadoop的历史服务器
pig -x mapreduce
#注意自己设置的 HDFS 端口
student = LOAD 'hdfs://hadoop102:8020/pig_input/student.txt' USING PigStorage(',') as (sno:chararray,sname:chararray,ssex:chararray,sbirthday:chararray,class:chararray);
dump student;


2. STORE
- 由于屏幕能够显示的信息有限,需要将数据经Pig分析后的结果保存到持久化存储系统中。在Pig中可以使用STORE运算符将加载的数据存储在文件系统中
STORE Relation_name INTO 'required_directory_path' [USING function];
- 参数说明
- Relation_name: 关系名
- required_directory_path: 关系目标存储路径USING
- function: 加载函数
示例
- 将名为student的关系中的数据导出到HDFS的/pigfile_ouput目录下并查看
#注意自己设置的 HDFS 端口
STORE student INTO 'hdfs://hadoop102:8020/pigfile_output' USING PigStorage(',');
fs -cat /pigfile_output/part-m-00000

二、诊断运算法
- 诊断运算符能够验证使用LOAD语句加载到关系中的数据是否正确。
dump
- 用于执行Pig Latin 语句,并打印结果,通常用于对代码进行调试
dump student;

describe
- 用于查看关系的模式
describe student;

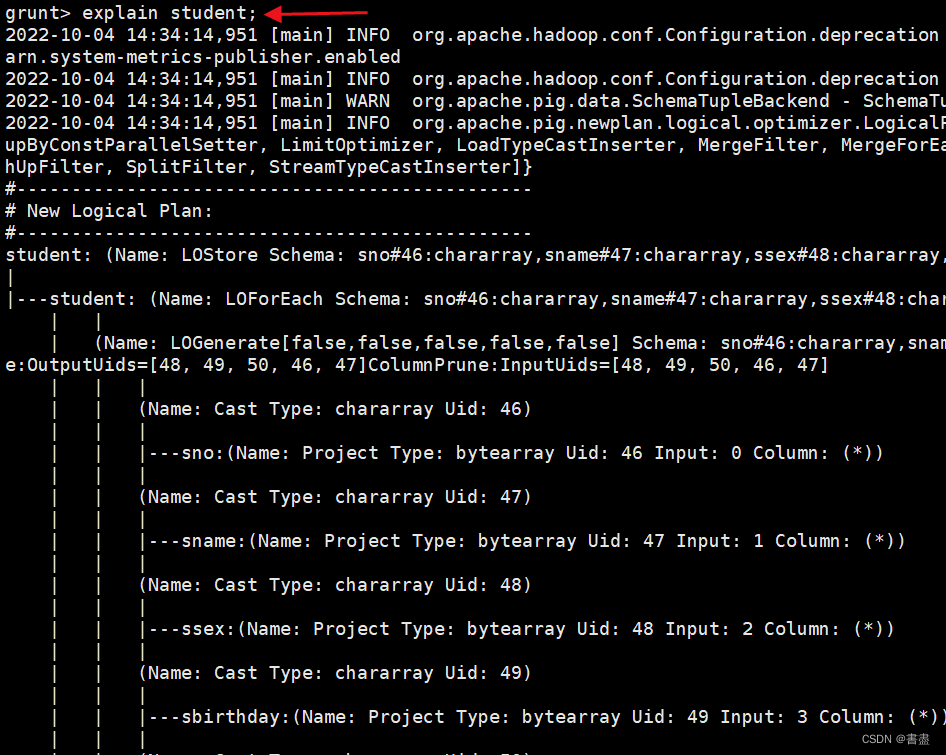
explain
- 用于显示关系的逻辑、物理或MapReduce执行计划
explain student;
illustrate
- 输出语句逐个执行的结果
illustrate student;

三、分组运算符
- GROUP运算符能够对一个或多个关系中的数据进行分组,对多个关系进行分组时模型至少要包含一个相同的key。
# 对一个关系中的数据进行分组
Group_data = GROUP Relation_name BY Group_key;
# 对多个关系中的数据进行分组
Group_data = GROUP Relation_name BY Group_key, Relation_name2 BY Group_key;
- 参数说明
- Relation_name :关系名
- Group_key: 分组key
示例
- 当前有两个数据文件,分别为contract.txt 和 temporary.txt, 在Linux系统中创建两个文件并将其上传到HDFS的/pig_input目录下
vim contract.txt
001,Rajiv,21,1254745857,Hyderabad
002,Siddarth,22,54786541785,Kolkata
003,Rajesh,22,14856978541,Delhi
004,Preethi,21,13254785642,Pune
005,Trupthi,23,9848022336,Bhuwaneshwar
006,Archana,23,487965214857,Chennai
007,Komal,24,35478595417,Trivendram
008,Bharathi,24,12547896547,Chennai
vim temporary.txt
001,Robin,22,Newyork
002,Bob,23,Kolkata
003,Maya,23,Tokyo
004,Sara,25,London
005,David,23,Bhuwaneshwar
006,Maggy,22,Chennai
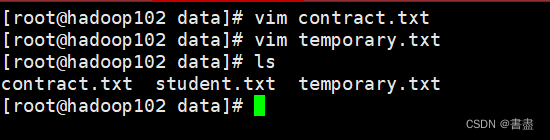
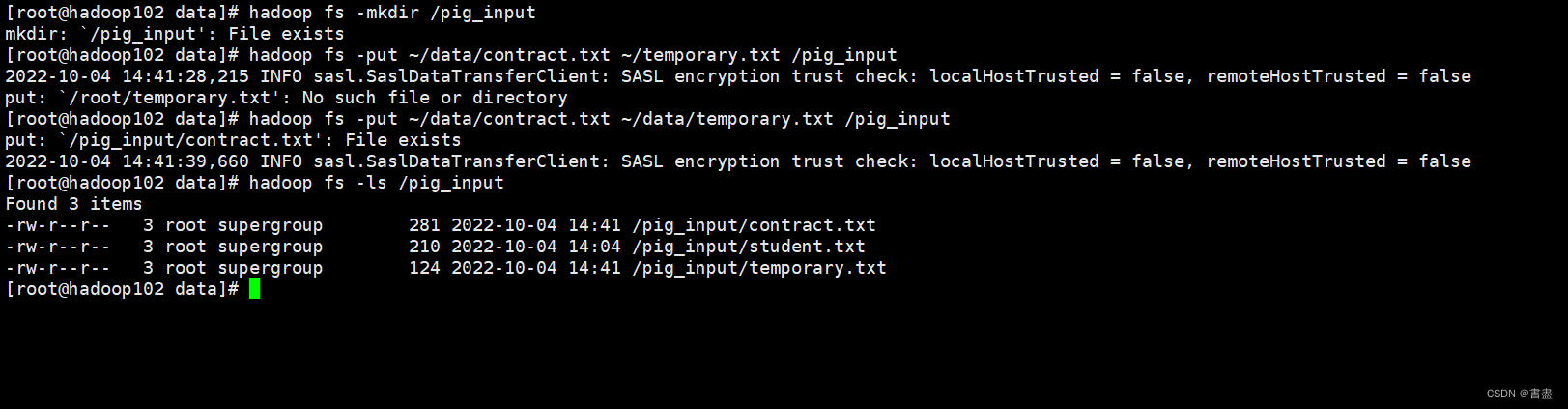
- 上传文件至hdfs
hadoop fs -mkdir /pig_input
hadoop fs -put ~/data/contract.txt ~/data/temporary.txt /pig_input
hadoop fs -ls /pig_input
- 以MapReduce模式运行Grunt Shell, 将两个文件中的数据分别加载到contract.txt 和 temporary 关系中
pig -x mapreduce
#注意自己设置的 HDFS 端口
contract = LOAD 'hdfs://hadoop102:8020/pig_input/contract.txt' USING PigStorage(',') as (id:int,firstname:chararray,age:int,phone:chararray,city:chararray);
dump contract;
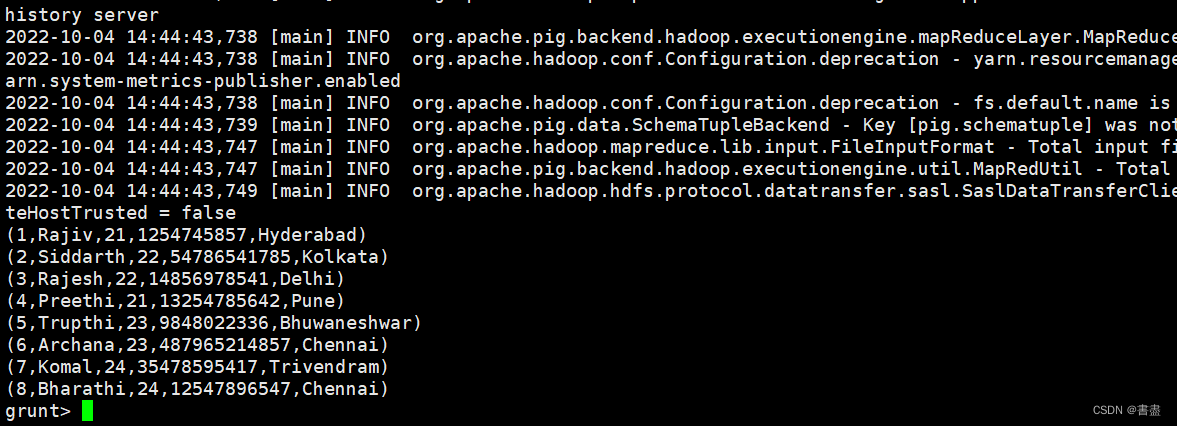
#注意自己设置的 HDFS 端口
temporary = LOAD 'hdfs://hadoop102:8020/pig_input/temporary.txt' USING PigStorage(',') as (id:int,name:chararray,age:int,city:chararray);
dump temporary


- 分别对contract和temporary关系中的数据根据age进行分组
contract_group = GROUP contract BY age;
dump contract_group;


temporary_group = GROUP temporary BY age;
dump temporary_group;

四、连接运算符
- OIN用于组合两个以上关系的记录,在执行该操作时,从每个关系中声明一个或一组元组作为key,当这些key匹配时,元组匹配,否则记录将被丢弃。
自连接
- 用于与自身进行连接,通常使用不同的关系加载数据
Relation3_name = JOIN Relation1_name BY key, Relation2_name BY key;
- 参数说明
- Relation3_name: 连接后的数据保存的目标关系名称
- Relation1_name, Relation2_name :两个拥有相同数据的关系
- key: 连接键值
示例
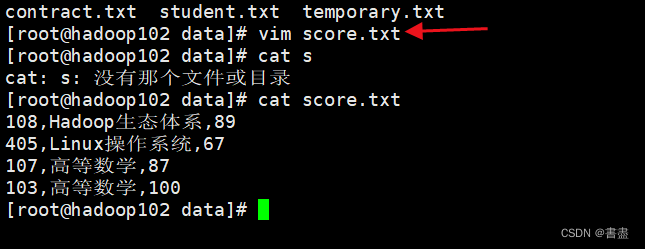
- 创建名为score.txt的数据文件,并上传到HDFS的/pig_input目录下
vim score.txt
108,Hadoop生态体系,89
405,Linux操作系统,67
107,高等数学,87
103,高等数学,100
- 上传HDFS
hadoop fs -put ~/data/score.txt /pig_input
hadoop fs -ls /pig_input

- 以mapreduce的方式进入Grunt Shell命令行,分别将HDFS中的score.txt文件中的数据加载到score1和score2的关系中,并进行自连接
#注意自己设置的 HDFS 端口
score1 = LOAD 'hdfs://hadoop102:8020/pig_input/score.txt' USING PigStorage(',') as (stu_no:chararray,cname:chararray,degree:int);
#注意自己设置的 HDFS 端口
score2 = LOAD 'hdfs://hadoop102:8020/pig_input/score.txt' USING PigStorage(',') as (stu_no:chararray,cname:chararray,degree:int);
score3 = JOIN score1 BY stu_no, score2 BY stu_no;
dump score3;
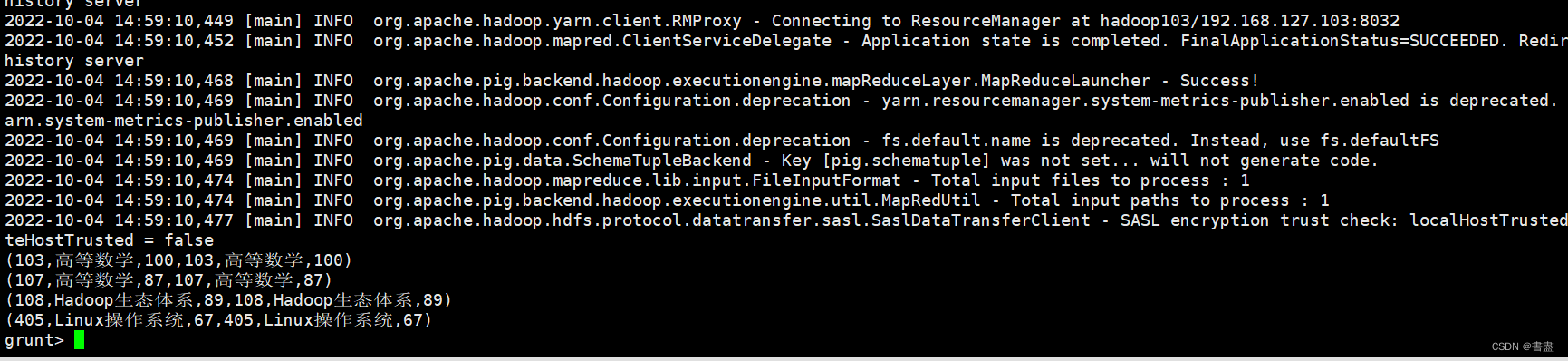
内连接
- 内连接是使用最频繁的连接方式,也称为等值连接,能够连接两个表中拥有共同谓词的数据并创建新关系。
- 内连接在执行过程中会将A的每一行与B的每一行进行比较,以找到满足条件的所有行。
result = JOIN relation1 BY columnname, relation2 BY columnname;
- 参数说明
- relation1, relation2: 要进行连接操作的两个关系
- columnname: 连接谓词
示例
将HDFS的/pig_input目录下的student.txt和score.txt中的数据加载到关系中,对student和score进行内连接操作
#注意自己设置的 HDFS 端口
score = LOAD 'hdfs://hadoop102:8020/pig_input/score.txt' USING PigStorage(',') as (stu_no:chararray,cname:chararray,degree:int);
student= LOAD 'hdfs://hadoop102:8020/pig_input/student.txt' USING PigStorage(',') as (sno:chararray,sname:chararray,ssex:chararray,sbirthday:chararray,class:chararray);
result = JOIN student BY sno, score BY stu_no;
dump result;

外连接
- 左外连接
- 能够返回左表中的全部记录和右表中匹配到的记录,右表中没有匹配到的记录使用空值代替
outer_left = JOIN relation1 BY columnname LEFT, relation2 BY columnname;
- 示例
将HDFS中的/pig_input目录下的student.txt和score.txt两个文件中的数据分别加载到student和score关系中,并进行左外连接操作。
#注意自己设置的 HDFS 端口
score = LOAD 'hdfs://hadoop102:8020/pig_input/score.txt' USING PigStorage(',') as (stu_no:chararray,cname:chararray,degree:int);
student= LOAD 'hdfs://hadoop102:8020/pig_input/student.txt' USING PigStorage(',') as (sno:chararray,sname:chararray,ssex:chararray,sbirthday:chararray,class:chararray);
outer_left = JOIN student BY sno LEFT, score BY stu_no;
dump outer_left;
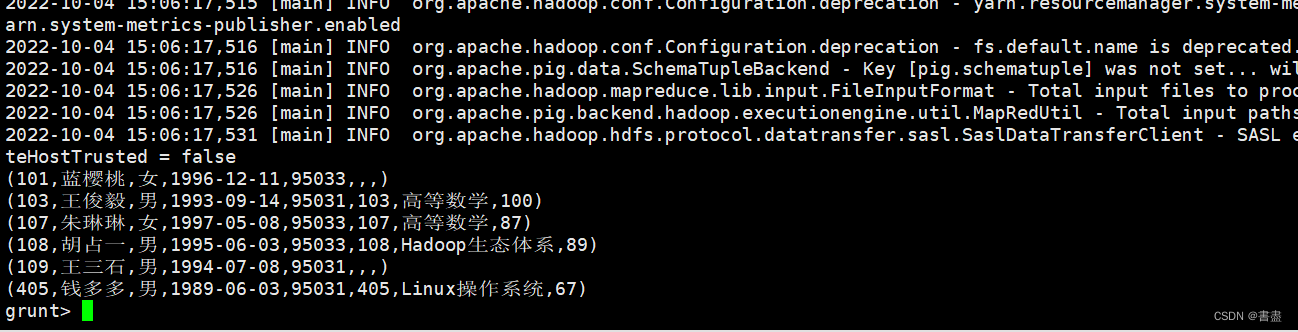
- 右外连接
- 能够返回右表中的全部记录和左表中匹配到的记录,左表中没有匹配到的记录使用空值代替
outer_right = JOIN relation1 BY columnname RIGHT, relation2 BY columnname;
示例
- 将HDFS中的/pig_input目录下的student.txt和score.txt两个文件中的数据分别加载到student和score关系中,并进行右外连接操作。
#注意自己设置的 HDFS 端口
score = LOAD 'hdfs://hadoop102:8020/pig_input/score.txt' USING PigStorage(',') as (stu_no:chararray,cname:chararray,degree:int);
student= LOAD 'hdfs://hadoop102:8020/pig_input/student.txt' USING PigStorage(',') as (sno:chararray,sname:chararray,ssex:chararray,sbirthday:chararray,class:chararray);
outer_right = JOIN student BY sno RIGHT, score BY stu_no;
dump outer_right;
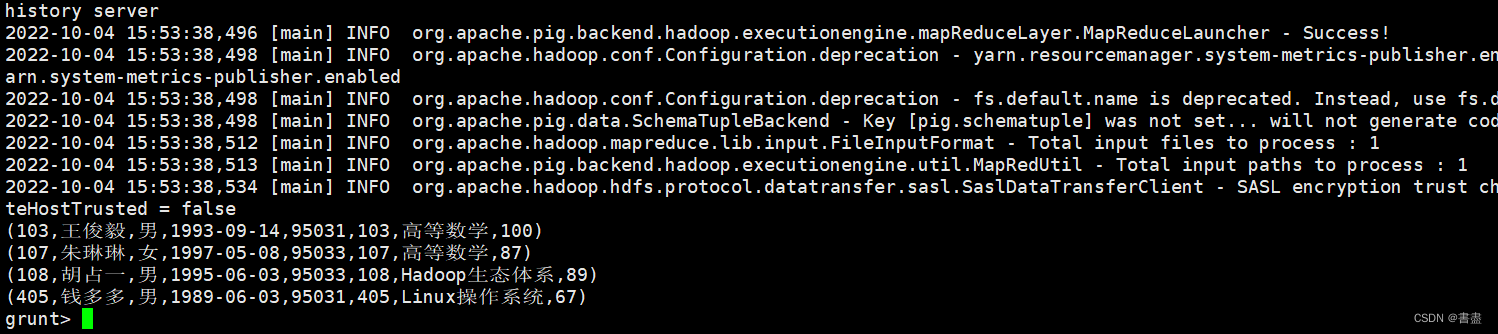
- 全外连接
- 能够返回两个表中的所有记录,表中没有匹配到的记录使用空值代替
outer_full = JOIN relation1 BY columnname FULL OUTER, relation2 BY columnname;
- 示例
- 将HDFS中的/pig_input目录下的student.txt和score.txt两个文件中的数据分别加载到student和score关系中,并进行全外连接操作。
#注意自己设置的 HDFS 端口
score = LOAD 'hdfs://hadoop102:8020/pig_input/score.txt' USING PigStorage(',') as (stu_no:chararray,cname:chararray,degree:int);
student= LOAD 'hdfs://hadoop102:8020/pig_input/student.txt' USING PigStorage(',') as (sno:chararray,sname:chararray,ssex:chararray,sbirthday:chararray,class:chararray);
outer_full = JOIN student BY sno FULL OUTER, score BY stu_no;
dump outer_full;
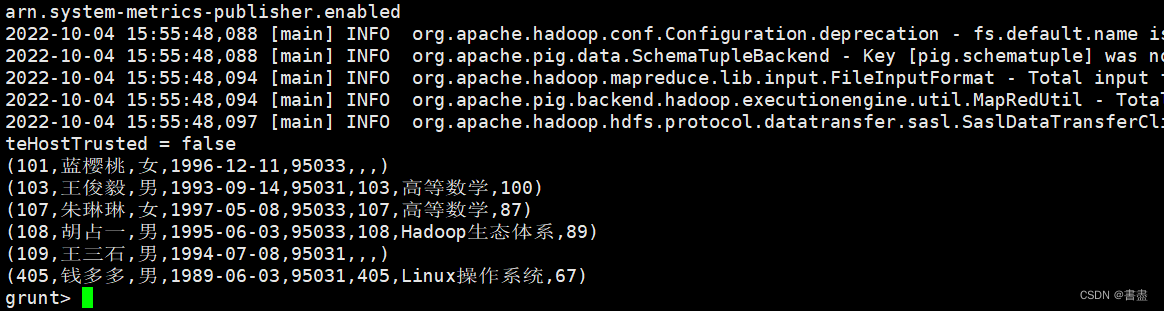
五、过滤运算符
- PigLatin中包含三种过滤运算符
- FILTER
- 根据条件从关系中选择所需的元组
- DISTINCT
- 从关系中删除冗余的元组
- FOREACH
- 基于列数据生成制定的数据转换
语法
#FILTER
FILTER relation BY (condition);
#DISTINCT
DISTINCT relation;
#FOREACH
FOREACH relation GENERATE (required data);
- 创建名为data_details.txt的数据文件,上传到HDFS的/pig_input目录下,并将数据加载到details关系中
vim data_details.txt
001,Rajiv,Reddy,9848022337,Hyderabad
002,Siddarth,Battacharya,9848022338,Kolkata
002,Siddarth,Battacharya,9848022338,Kolkata
003,Rajesh,Khanna,9848022339,Delhi
003,Rajesh,Khanna,9848022339,Delhi
004,Preethi,Agarwal,9848022330,Pune
005,Trupthi,Mohanthy,9848022336,Bhuwaneshwar
006,Archana,Mishra,9848022335,Chennai
006,Archana,Mishra,9848022335,Chennai
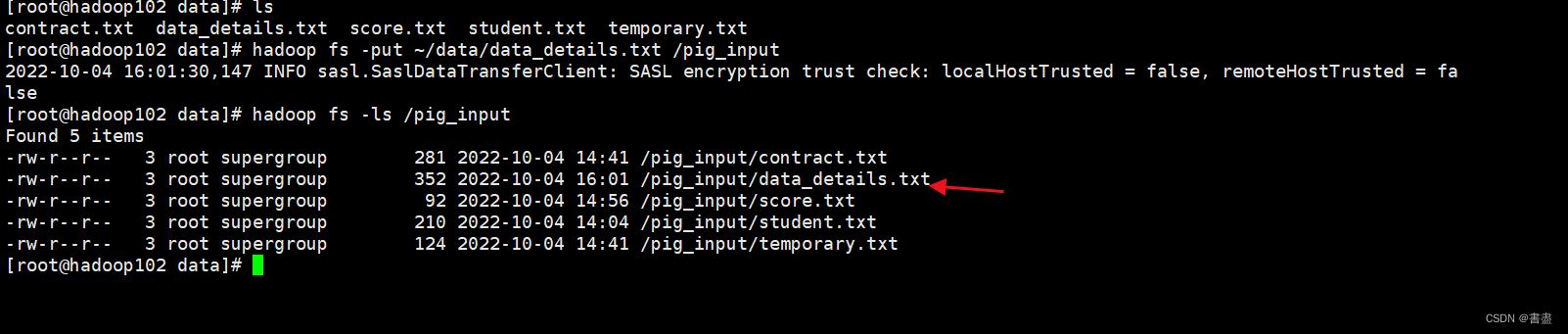
hadoop fs -put ~/data/data_details.txt /pig_input
pig -x mapreduce
details = LOAD 'hdfs://hadoop102:8020/pig_input/data_details.txt' USING PigStorage(',') as (id:int,firstname:chararray,lastname:chararray,phone:chararray,city:chararray);

- FILTER
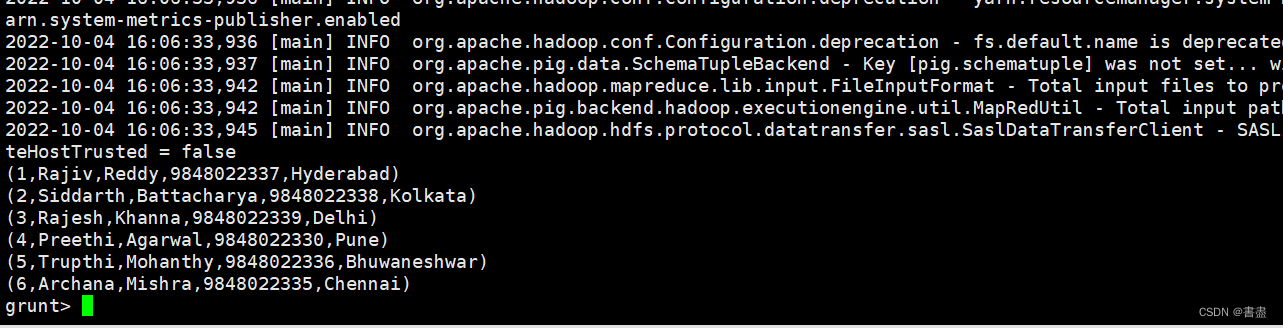
- 使用FILTER运算符过滤出id为005的记录
filter_data = FILTER details BY id == 5;
dump filter_data;

- DISTINCT
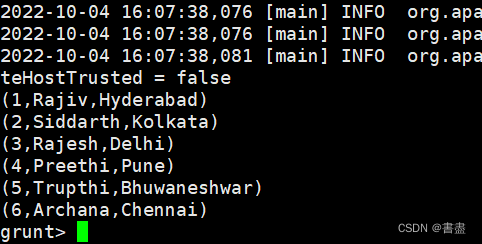
- 使用DICTINCT运算符去掉数据中重复的元组
distinct_data = DISTINCT details;
dump distinct_data;
- FOREACH
- 使用FOREACH运算符从distinct_data关系中获取id, firstname和city的值,并将其存储到名为foreach_data的关系中
foreach_data = FOREACH distinct_data GENERATE id,firstname,city;
dump foreach_data;
六、排序运算符
- 使用ORDER BY关键字,针对一个或多个字段进行排序。ORDER BY通常与LIMIT运算符一起使用。LIMIT运算符主要用于截取显示排序后的关系中指定数量的元组
# ORDER运算符
ORDER Realtion BY (ASC|DESC);
#LIMIT运算符
LIMIT Relation required number of tuples;
- 将HDFS的/pig_input目录下的student.txt文件中的数据加载到名为student的关系中并按照sno进行升序排序,最后显示前两个元组
student = LOAD 'hdfs://hadoop102:8020/pig_input/student.txt' USING PigStorage(',') as (sno:chararray,sname:chararray,ssex:chararray,sbirthday:chararray,class:chararray);
order_by_data = ORDER student BY sno ASC;
limit_data = LIMIT order_by_data 2;
dump limit_data;


















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











