







Python pandas库的简单使用
简洁:# numpy创建的数组中元素要求是同种数据类型,对数据分析、挖掘有较大的局限性,所以我们需要学习pandas库
pandas基于Numpy而创建可以处理不同的数据类型,而且有非常利于数据处理的数据结构:序列series和数据框dataframe
序列由两部分组成,一部分是索引,一部分是对应的值
序列的创建和访问
import pandas as pd
import numpy as np
s1=pd.Series([1,-2,2.3,'hq']) # 指定列表创建默序列
# 指定列表和索引,创建个性化序列
s2 = pd.Series([1,-2,2.3,'hq'],index=['a','b','c','d'])
s3 = pd.Series((1,2,3,4,'h1')) # 指定元祖创建默认序列
s4 = pd.Series(np.array([1,2,4,7.1])) # 指定数组创建默认序列
# 通过字典创建序列
mydict = {'red':2000,'blue':1000,'yello':500}
ss = pd.Series(mydict)
# 序列中的元素访问方式非常简单,通过索引可以访问对应的元素值。
# 访问序列s1和s2中的元素的实例代码如下;
print(s1[3])
print(s2['c'])
# 执行结果如下:
# hq
# 2.3
序列属性
序列有两个属性,分别是值和索引,通过index和values可以获得其内容
import pandas as pd
s1=pd.Series([1,-2,2.3,'hq'])# 创建序列s1
val = s1.values
in1 = s1.index
print(val)
print(in1)
执行结果如下:
[1 -2 2.3 ‘hq’]
RangeIndex(start=0, stop=4, step=1)
序列方法
1.unique()
** 通过序列中的unique()方法,去掉序列中重复的元素值,**
import pandas as pd
s5 =[1,2,2,3,'hq','hq','he'] # 定义列表s5
s5 = pd.Series(s5) # 将定义的列表转化为序列
s51 = s5.unique() # 调用unique方法去重
print(s51)
执行结果如下
[1 2 3 ‘hq’ ‘he’】
2.isin()
# 通过isin()方法判断元素值是否存在,存在true,不存在false
import pandas as pd
s5 =[1,2,2,3,'hq','hq','he'] # 定义列表s5
s5 = pd.Series(s5) # 将定义的列表转化为序列
s52 =s5.isin([0,'he'])
print(s52)
# 执行结果如下
'''
0 False
1 False
2 False
3 False
4 False
5 False
6 True
dtype: bool
'''
3.value_counts()
使用序列中的value_counts()方法,统计序列元素值出现的次数,
import pandas as pd
s5 =[1,2,2,3,'hq','hq','he'] # 定义列表s5
s5 = pd.Series(s5) # 将定义的列表转化为序列
# 例如统计s5中序列中每个元素值出现的次数
s53 =s5.value_counts()
print(s53)
# 执行结果如下
'''2 2
hq 2
1 1
3 1
he 1
dtype: int64
其中索引为云序列元素的值,值为出现的次数
'''
4空值处理方法
在序列中处理空值的方法有3个,isnull()notnull(),dropa() **
isnull()判断序列是否有空值,如果是返回True,否则返回false
** notnull()判断序列中是否有非空值,如果是返回True,否则返回False
** dropan()负责清洗序列中的空值**
import pandas as pd
import numpy as np
ss1 = pd.Series([10,'hq',60,np.nan,20])# 定义序列ss1,其中np.nan为空值
tt1 = ss1[ss1.isnull()]
tt2 = ss1[ss1.notnull()]
tt3 = ss1.dropna()
print(tt1)
print(tt2)
print(tt3)
执行结果:
3 NaN
dtype: object
0 10
1 hq
2 60
4 20
dtype: object
0 10
1 hq
2 60
4 20
dtype: object
序列切片
切片,连续或者间断的批量获取序列中的元素。
import pandas as pd
import numpy as np
s1 = pd.Series([1,-2,2.3,'hq'])
s2 = pd.Series([1,-2,2.3,'hq'],index=['a','b','c','d'])
s4 = pd.Series(np.array([1,2,4,7.1]))
s22 = s2[['a','b']] # 取索引号为字符a,b的元素
s11 = s1[0:1] # 索引为连续的数组
s12 = s1[[0,2,3]] # 索引为不连续的数组
s41 = s4[s4>2] # 索引为逻辑数组
print(s22)
print('-'*20)
print(s11)
print('-'*20)
print(s12)
print('-'*20)
print(s41)
运行结果

序列聚合运算
# 序列的聚合运算,主要包括对序列中的元素求和、平均数,最大值,最小值,中位数,方差,标准差等
import pandas as pd
s = pd.Series([1,2,3,4,5])
su =s.sum() # 求和
sm = s.mean() # 求平均数据
ss = s.std() # 求标准差
smx = s.max() # 最大值
smi = s.min() # 最小值
smed = s.median() # 中位数
svar = s.var() # 方差
数据框
**pandas 中另一个重要的数据对象为数据框,由多个序列按照相同的索引组织在一起的形成的二维表。
数据框的每一列为序列。数据框的属性包括index,列名和values。
由于数据框是更为广泛的一种数据组织形式,再将去外部数据文件读取到python中时大部分会采用数据框的形式进行存取。如数据库Excel,TXT文件。
同时数据框也提供了极为丰富的方法用于处理数据和完成计算任务。
数据框是python完成数据分析与挖掘任务的重要数据结构之一。
**
数据框的创建
基于字典,利用pandas中的Dataframe()函数,可以创建数据框。其中字典的键转化为列名,字典的值转化为列值,而索引转化为默认值,即从0开始由大到小排列

数据框属性
数据框有三个属性,列名、列值和索引

数据框方法
数据框作为数据挖掘分析的重要数据结构,提供了非常丰富的方法用于数据处理及计算。
去掉空值(nan)值,按照值进行排序,按照索引进行排序,取钱n行数据,删除列、数据框之间的水平连接,数据框转化为Numpy数组、数据导出到Excel文件、相关统计分析等。
1.dropna() 去掉空值
注意:原来的数据集不会发生改变,新数据集需要重新定义。

fillna() 空值填充
默认情况下所有空值可以填充一个元素值(数值或者字符串),也可以指定不同的列填充不同的值。
import pandas as pd
import numpy as np
data ={'a':[2,2,np.nan,5,6],'b':['kl','kl','kl',np.nan,'kl'],'c':[4,5,6,np.nan,6],'d':[7,9,np.nan,9,8]}
df = pd.DataFrame(data)
# np.nan是一个float类型的数据, 什么时候numpy中出现nan,我们读取本地文件为float时,如果有缺失,或者做了不合适的计算。
print(df)
df2 = df.fillna(0) # 所有空值元素填充0
print(df2)
df3 = df.fillna('love') # 所有空值元素填充love
print(df3)
df4 = df.fillna({'a':0,'b':1,'c':2,'d':3}) # 全部列填充
print(df4)
df5 = df.fillna({'a':10,'b':20}) # 部分列填充
print(df5)
输出结果如下图:

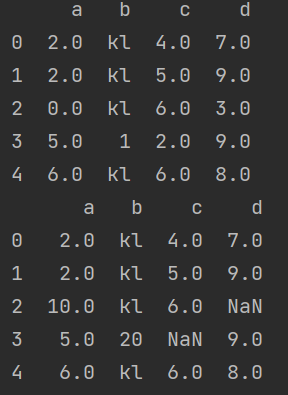
sort_values() 指定列按值进行排序

sort_index() 按索引进行排序

head() 取数据集中的前n行

drop() 删除数据集中的制定的列

join()实现两个数据框之间的水平连接
import pandas as pd
data = {'a':[5,3,4,1,6],'b':['d','c','a','e','q'],'c':[4,6,5,5,6]}
Df = pd.DataFrame(data)
print(Df)
print('--'*20)
Df3 = pd.DataFrame({'d':[1,2,3,4,5]})
print(Df3)
print('-'*30)
Df4 = Df.join(Df3)
print(Df4)

to_numpy() 将数据框转换为Numpy数组的形式
import pandas as pd
list1 = ['a','b','c','d','e','f']
list2 = [1,2,3,4,5,6]
list3 = [1.4,3.5,2,6,7,8]
list4 = [4,5,6,7,8,9]
list5 = ['t',5,6,7,'k',9.6]
# 定义字典D,值为字符、数值混合数据
D = {'M1':list1,'M2':list2,'M3':list3,'M4':list4,'M5':list5}
print(D)
# 定义字典G。值为纯数值数据
G = {'M1':list2,'M2':list3,'M3':list4}
print(G)
# 将字典D转化为数据框
D = pd.DataFrame(D)
print(D)
# 将数据框D转化为Numpy数组D1
D1=D.to_numpy()
print(D1)
# 将字典G转化为数据框
G = pd.DataFrame(G)
print(G)
# 将数据框G转化为Numpy数组G1
G1 = G.to_numpy()
print(G1)
输出结果如下图:


通过to_excel() 可以将数据框导出到Excel文件中。
注意:查看excel文件需要通过在pycharm中alt+F12 通过pip install openpyxl,安装openpyxl
# 将数据框导出到excel中
D.to_excel('D.xlsx')
G.to_excel('G.xlsx')
统计方法 对数据框中各列求和,平均值等。
import pandas as pd
data = {'a':[5,3,4,1,6],'b':['d','c','a','e','q'],'c':[4,6,5,5,6]}
Df = pd.DataFrame(data)
# print(Df)
# print('--'*20)
Df3 = pd.DataFrame({'d':[1,2,3,4,5]})
# print(Df3)
# print('-'*30)
Df4 = Df.join(Df3)
print(Df4)
import warnings
warnings.filterwarnings('ignore') # 消除警告
DDD = Df4.drop('b',axis=1) # D中删除b列
print(DDD)
R1 = Df4.sum() # 各列求和
print(R1)
R2 = Df4.mean() # 各列求平均值
print(R2)
R3 = Df4.describe() #各列做描述性统计
print(R3)


数据框切片
利用数据框中的iloc属性进行切片
import pandas as pd
import numpy as np
data ={'a':[2,2,np.nan,5,6],'b':['kl','kl','kl',np.nan,'kl'],'c':[4,5,6,np.nan,6],'d':[7,9,np.nan,9,8]}
df = pd.DataFrame(data)
# np.nan是一个float类型的数据, 什么时候numpy中出现nan,我们读取本地文件为float时,如果有缺失,或者做了不合适的计算。
# print(df)
df2 = df.fillna(0) # 所有空值元素填充0
print(df2)
c3 = df2.iloc[1:3,2] # 获取从0开始1,2行 从0开始第2列的数据框
print(c3)
c4 = df2.iloc[1:3,0:2] # 获取从0开始1,2行,从0开始0,1列的数据框
print(c4)
c5 = df2.iloc[1:3,:] # 获取从0开始 1,2行 所有列的数据框
print(c5)
c6 = df2.iloc[[0,2,3],[1,2]] # 获取从0开始 0,2,3行,第1,2列数据框
print(c6)
TF=[True,False,False,True,True]
print(TF)
c7 = df2.iloc[TF,[1]] # 获取第0、3、4行 从0开始,第1列的数据
print(c7)

利用loc属性进行切片
数据框中的loc属性,主要基于列标签进行索引,对列值进行行定位,通过指定列,从而实现数据切片操作。获取数据的所有列,使用‘:’表示。切片操作或的的数据还可以筛选前n行。
import pandas as pd
import numpy as np
data ={'a':[2,2,np.nan,5,6],'b':['kl','kl','kl',np.nan,'kl'],'c':[4,5,6,np.nan,6],'d':[7,9,np.nan,9,8]}
df = pd.DataFrame(data)
# np.nan是一个float类型的数据, 什么时候numpy中出现nan,我们读取本地文件为float时,如果有缺失,或者做了不合适的计算。
# print(df)
df2 = df.fillna(0) # 所有空值元素填充0
print(df2)
c8 = df2.loc[df2['b'] == 'kl',:] # 选取所有列,且b行有由kl的元素,组成数据框
print(c8)
c9 = df2.loc[df2['b']== 'kl',:].head(3) # 选取所有列,且b行有由kl的元素, 选出前三行,组成数据框
print(c9)
c10 =df2.loc[df2['b'] == 'kl',['a','c']].head(3) # 选取a,c列且有kl的元素,选出前三行,组成数据框
print(c10)
c11 = df2.loc[df2['b'] == 'kl',['a','c']] # 选取a,c列且有kl的元素,组成数据框 第四行没有kl所以没有第四行数据。
print(c11)

外部文件读取
在数据分析与挖掘中,业务数据大多存储在外部文件中,如Excel TXT CSV文件等。因此,需要将外部文件读取到python中进行分析
Excel文件读取
通过read_excel()函数可以读取Excel文件,可以读取指定的工作簿(sheet)也可以设置读取有表头或无表头的数据表,示例代码如下:
import pandas as pd
path = '2014年各省市售电量.xlsx'
data =pd.read_excel(path)
print(data)
# 读取Sheet2里的数据,
data1 = pd.read_excel(path,'Sheet2')
print(data1)
# 读取没有表头的数据
dta = pd.read_excel('Excel1.xls',header=None)
print(dta)
注意:默认情况读取会省略中间的行、列

我们可以设置set_option出现完整数据。

TXT文件读取
**通过read_table()函数读取 **
注意:TXT文件数据列之间会使用特殊字符作为分隔,常见的有tab键、空格,逗号,还有TXT文件是没有表头的。
示例代码如下:

CSV文件读取
使用read_csv()函数,实例代码如下:
csv文件可以存储大规模的数据文件,比如单个数据文件大小可达数GB、数10GB,这时候可以此阿勇分块的方式进行读取,示例代码如下:

本案例介绍了对数据文件每次读取50000行记录,读取的字段为指定的第3,4,10列。不足50000行的,按实际数据量读取。其中对于reader为一个数据阅读器可以通过循环的方式依次把每次读取的数据取出来并进行处理,实际上,对于大规模的csv数据文件,读取该文件的部分数据也是很有必要的,比如读取其前1000行,实例代码如下:

本次对pandas库的简单知识,个人做了简要阐述。
如果有前辈大牛们,发现文章中,有错误,不足之处,请在评论区指出!!!














 2669
2669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









