






沐
李沐老师这个讲的很泛,记了一点新启发
如果有一个节点缺失值
用他连着的边和全局向量(整个图的平均)求得
即,面对缺失值
缺节点——用边
缺边——用节点
但是在聚合体现图结构的时候
是用该节点和与它相连的节点一起f
公式及代码
综述
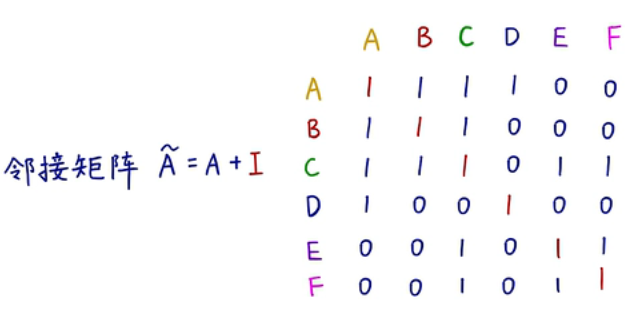
D:对角矩阵,标注每个节点有多少个相连的边,然后就可以求平均
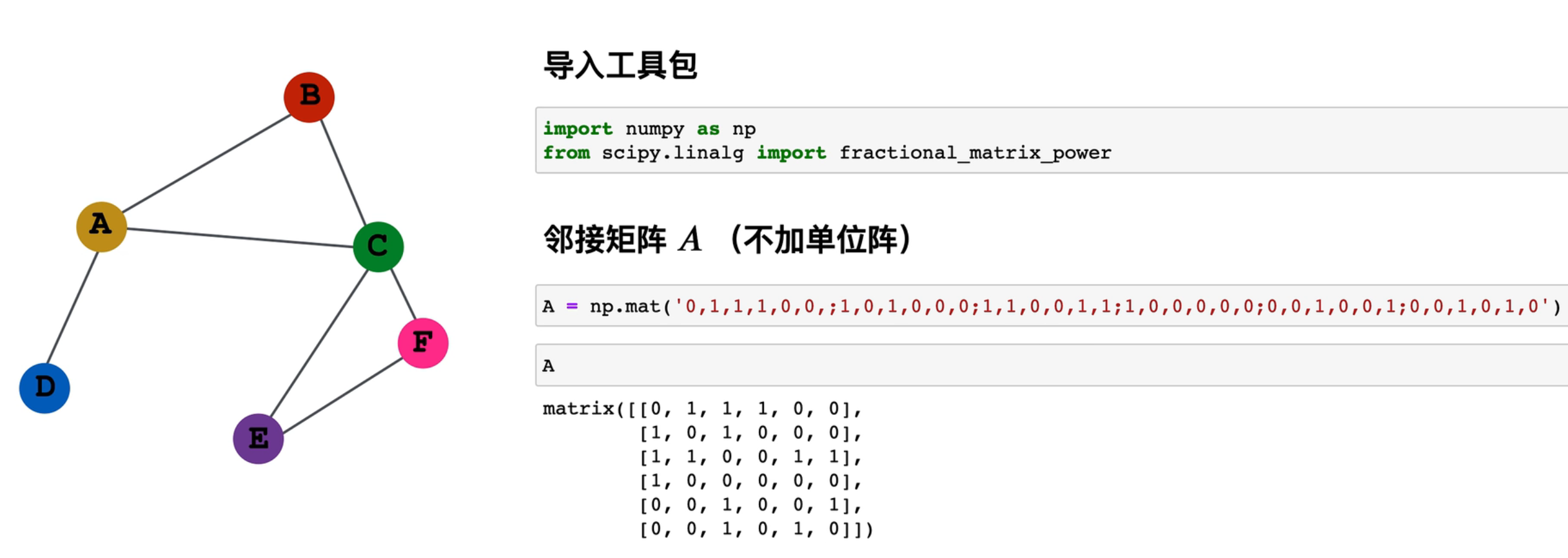

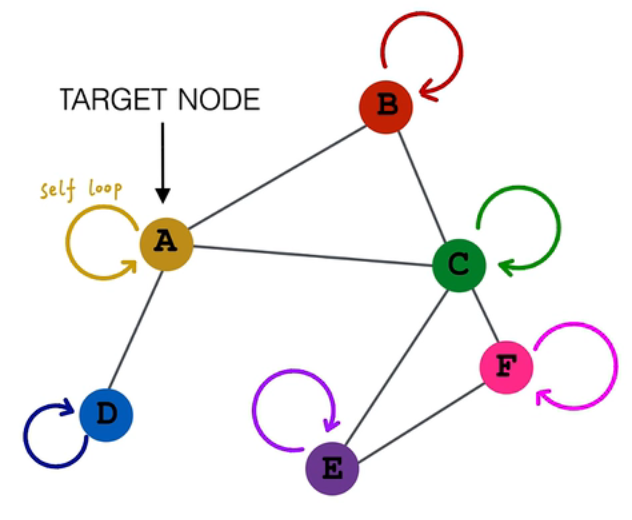
一个例子
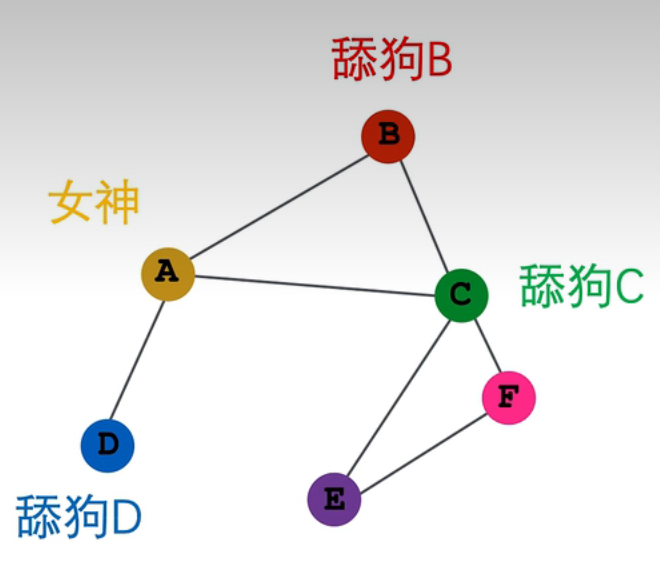
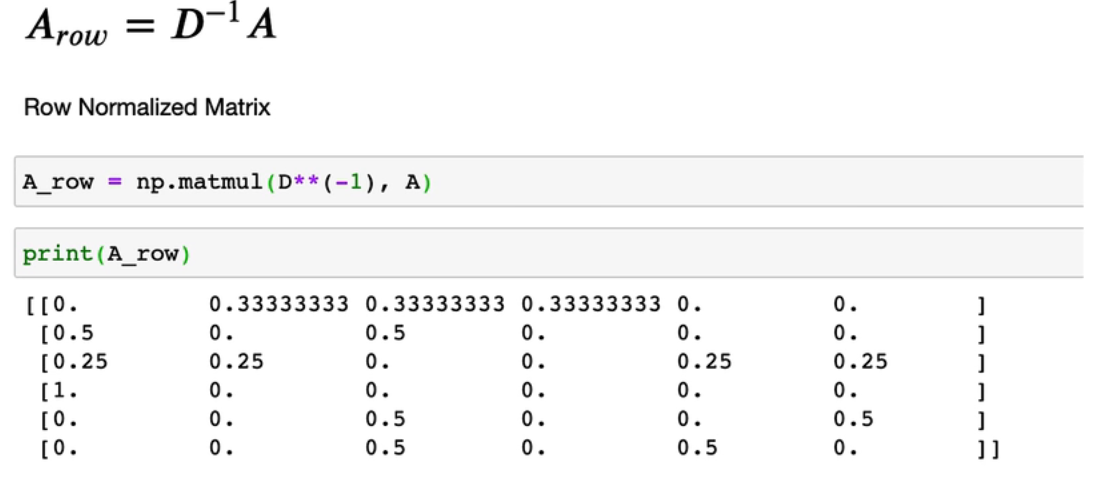
这种方式对每个相连节点分配相同权重不好,比如D比B专一(虽然很不喜欢这样的例子,但方便理解)
一个较好的解决方法——
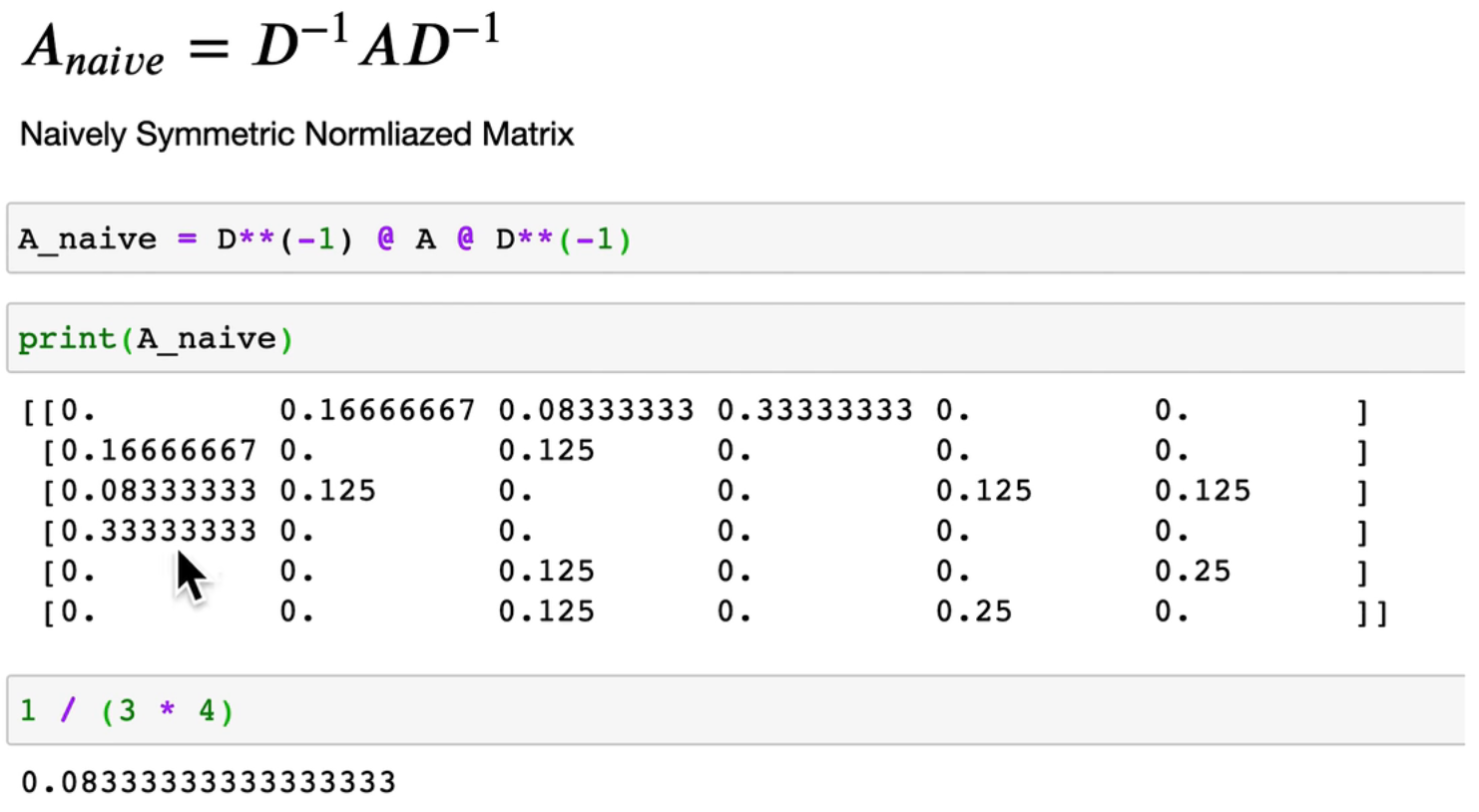
相当于权重是,除以本节点与相连节点一共的边的个数,比如A有三条,C有四条,A对C就除3*4
但存在一个问题,这个得到的矩阵的特征值范围在(-1,1),最大特征值不是1
也就意味着,输入向量在经过这个矩阵乘法后,幅值会变小
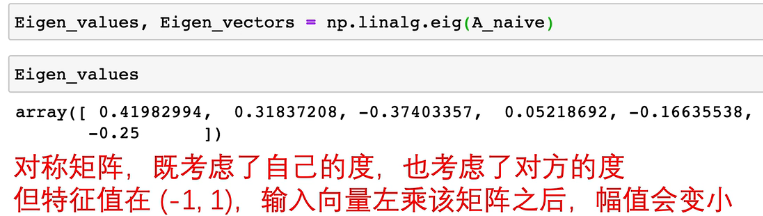
关于特征值与特征向量
一个矩阵在变换时,保持不变的向量,就是特征向量,特征向量的长度变化倍数就是特征值
(在没看到下面图里这个公式的时候,还只是写了上面这句话,看到这个公式,突然就悟了上面的话,大一的线性代数开始攻击我)
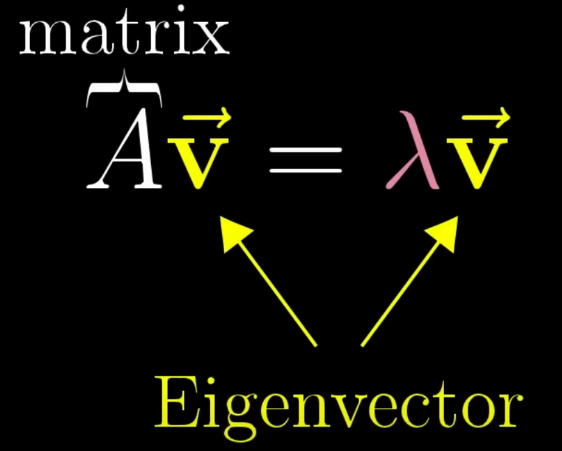
一个更好的改进
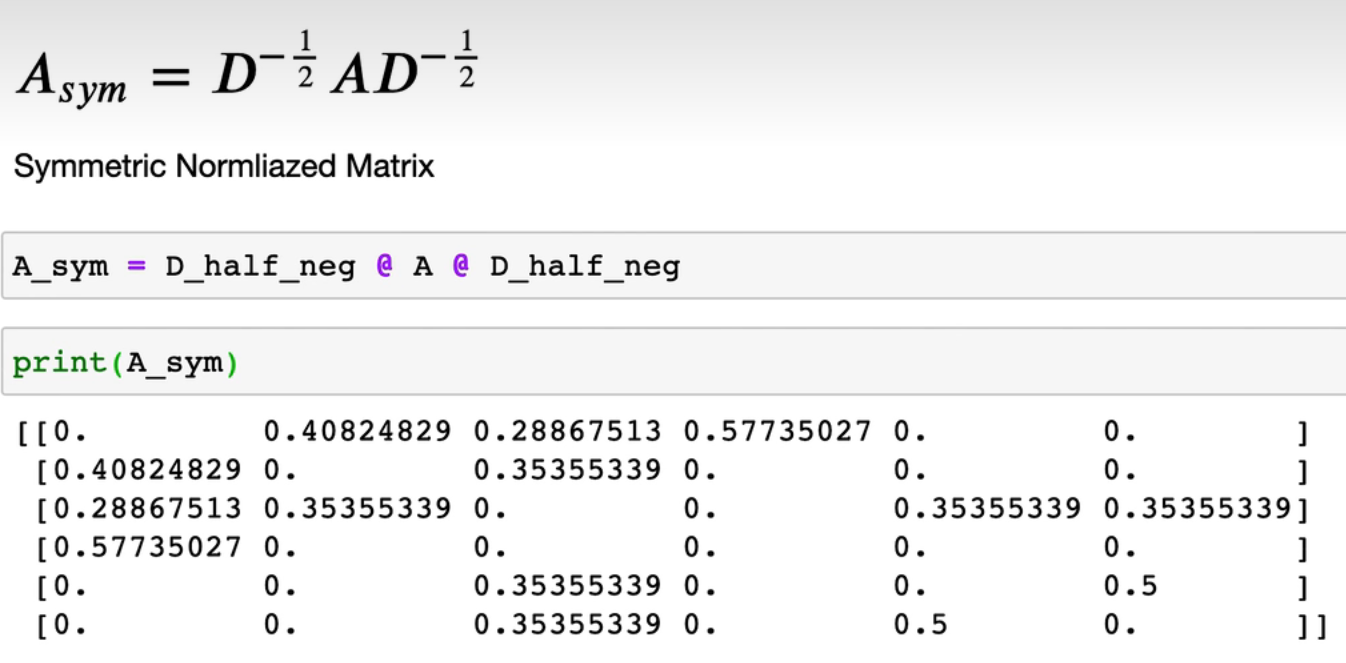
最大特征值为1,nice!

且可以得到此方法的节点权重分配为
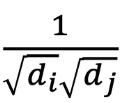
所以在论文中可以看到如下公式,H(k)是k层的嵌入,这个公式是在计算H(k+1)

目前为止的总结
所以最终的公式是这样的
l+1层的嵌入H(l+1)要通过l层的嵌入H(l)和神经网络的权重W(l)经过激活函数sigma
![]()
一个更更好的改进(计算图优化)
加上自己的影响,self-embedding
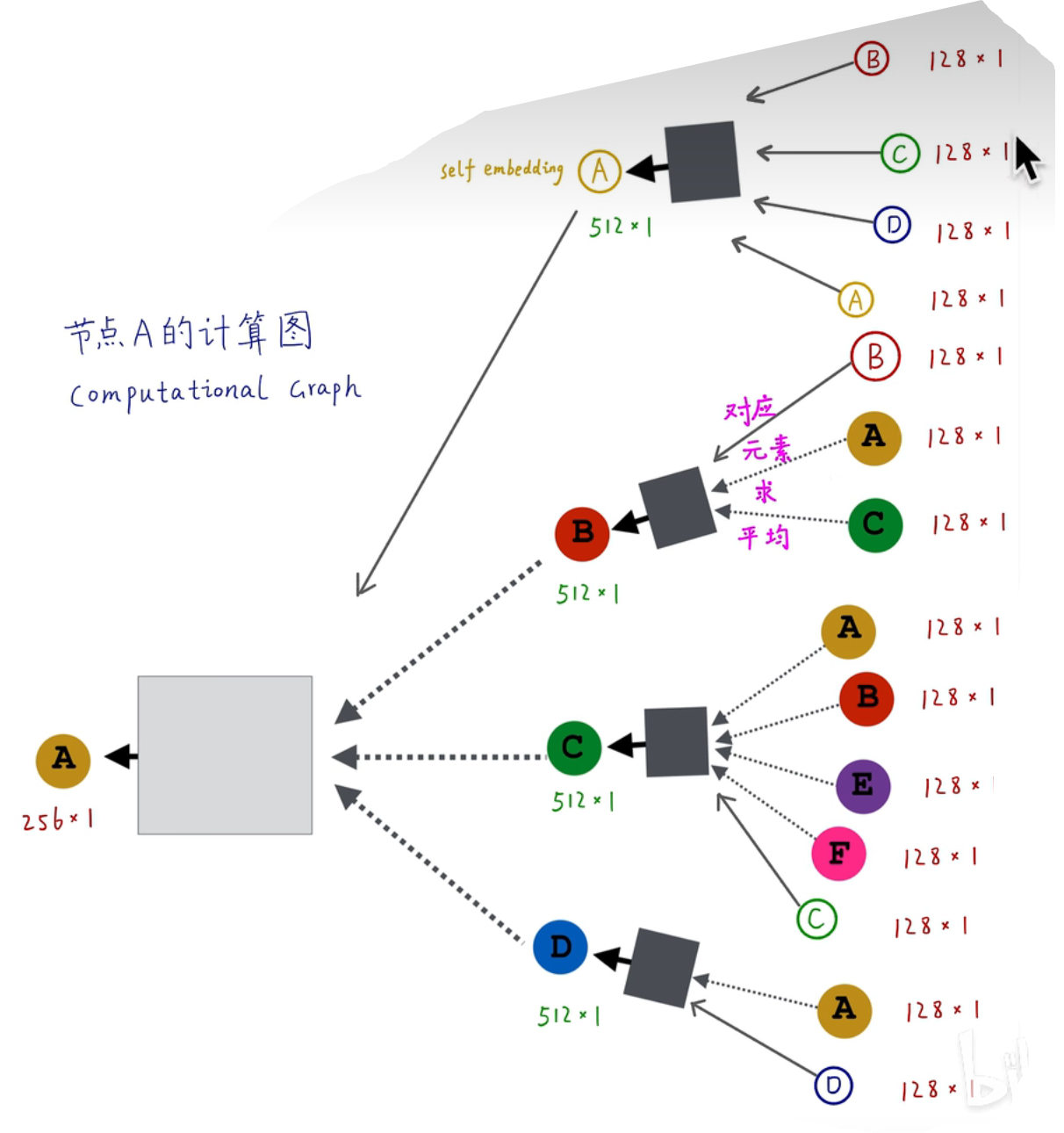
(这张图是想提示以后看的自己,最相邻的节点共用一个神经网络层(灰色的块),次相邻的节点共用一个神经网络层(黑色的块))
从而这里有一个可以小小优化的
就是其他次相邻的节点还是用同样的黑色,self-embedding自己用一种

杂谈(优点)
1、方便加入新节点
当有新节点加入时,不用重新计算这个来获得新节点的嵌入,直接运行已有的图神经网络,用新节点相连的节点就能获得新节点的嵌入
2、可以捕获节点的功能结构角色
3、节点、链接、子图、全图都可以有特征
(看到最后发现视频自己有总结)

















 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









