







锁及锁的应用问题
4.Collection线程不安全
4.1 前言
当我们执行下面语句的时候,底层进行了什么操作?
new ArrayList<Integer>();
底层创建了一个空的数组,伴随着初始值为10
当执行add方法后,如果超过了10,那么会进行扩容,扩容的大小为原值的一半,也就是5个,使用下列方法扩容
Arrays.copyOf(elementData, netCapacity)
4.2 单线程环境下
单线程环境的ArrayList是不会有问题的
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
for (String element : list) {
System.out.println(element);
}
}
4.3 多线程环境下
为什么ArrayList是线程不安全的?因为在进行写操作的时候,方法上为了保证并发性,是没有添加synchronized修饰,所以并发写的时候,就会出现问题
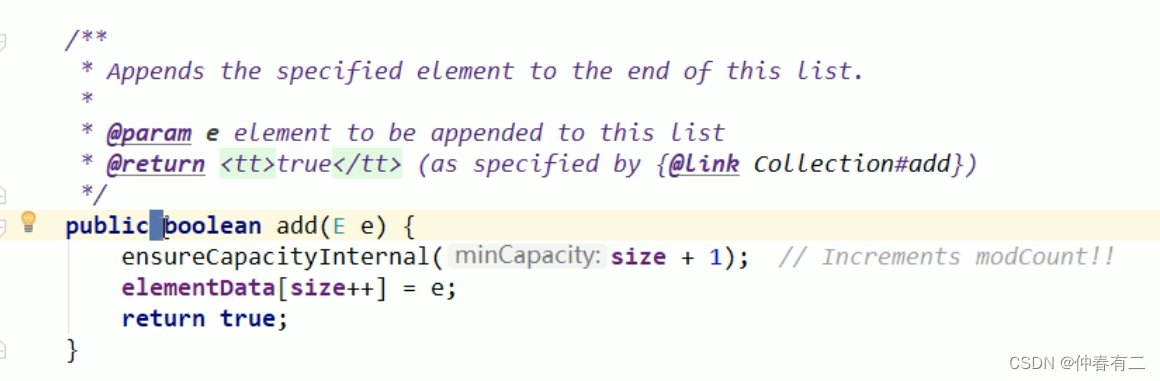
当我们同时启动30个线程去操作List的时候
public static void main(String[] args) {
List<String> list = new ArrayList<>();
for (int i = 1; i <= 30; i++) {
new Thread(() -> {
list.add(UUID.randomUUID().toString().substring(0, 8));
System.out.println(list);
}, String.valueOf(i)).start();
}
}
这个时候出现了错误,也就是java.util.ConcurrentModificationException

这个异常是 并发修改的异常
4.4 解决方案
方案一:Vector
第一种方法,就是不用ArrayList这种不安全的List实现类,而采用Vector,线程安全的
关于Vector如何实现线程安全的,而是在方法上加了锁,即synchronized

这样就每次只能够一个线程进行操作,所以不会出现线程不安全的问题,但是因为加锁了,导致并发性基于下降。
方案二:Collections.synchronized()
List<String> list = Collections.synchronizedList(new ArrayList<>());
采用Collections集合工具类,在ArrayList外面包装一层同步机制
方案三:采用JUC里面的方法
CopyOnWriteArrayList:写时复制,主要是一种读写分离的思想
写时复制,CopyOnWrite容器即写时复制的容器,往一个容器中添加元素的时候,不直接往当前容器Object[]添加,而是先将Object[]进行copy,复制出一个新的容器object[] newElements,然后新的容器Object[] newElements里添加原始,添加元素完后,在将原容器的引用指向新的容器 setArray(newElements);这样做的好处是可以对copyOnWrite容器进行并发的读 ,而不需要加锁,因为当前容器不需要添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。就是写的时候,把ArrayList扩容一个出来,然后把值填写上去,在通知其他的线程,ArrayList的引用指向扩容后的
查看底层add方法源码
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
首先需要加锁,然后在末尾扩容一个单位,然后在把扩容后的空间,填写上需要add的内容,最后把内容set到Array中。
4.5 HashSet线程不安全
CopyOnWriteArraySet
底层还是使用CopyOnWriteArrayList进行实例化
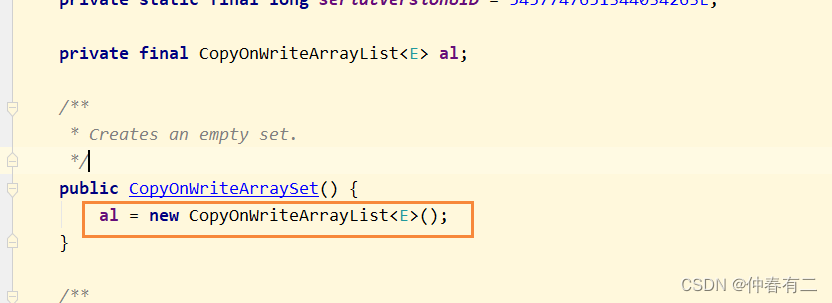
HashSet底层结构
同理HashSet的底层结构就是HashMap

但是为什么调用 HashSet.add()的方法,只需要传递一个元素,而HashMap是需要传递key-value键值对?
首先查看hashSet的add方法
public boolean add(E e) {
return map.put(e, PRESENT)==null; //其中PRESENT是一个Object的常量
}
能发现调用add的时候,存储一个值进入map中,只是作为key进行存储,而value存储的是一个Object类型的常量,也就是说HashSet只关心key,而不关心value
4.6 HashMap线程不安全
同理HashMap在多线程环境下,也是不安全的
解决方法:
* 使用Collections.synchronizedMap(new HashMap<>());
* 使用 ConcurrentHashMap
5.TransforValue
public class TransferValueDemo {
public void changeValue1(int age) {
age = 30;
}
public void changeValue2(Person person) {
person.setPersonName("XXXX");
}
public void changeValue3(String str) {
str = "XXX";
}
public static void main(String[] args) {
TransferValueDemo test = new TransferValueDemo();
// 定义基本数据类型
int age = 20;
test.changeValue1(age);
System.out.println("age ----" + age);
// 实例化person类
Person person = new Person("abc");
test.changeValue2(person);
System.out.println("personName-----" + person.getPersonName());
// String
String str = "abc";
test.changeValue3(str);
System.out.println("string-----" + str);
}
}
class Person {
private Integer id;
private String personName;
public Person(String personName) {
this.personName = personName;
}
public String getPersonName() {
return personName;
}
public void setPersonName(String personName) {
this.personName = personName;
}
}
changeValue1的执行过程
八种基本数据类型,在栈里面分配内存,属于值传递,栈管运行,堆管存储
当们执行 changeValue1的时候,因为int是基本数据类型,所以传递的是int = 20这个值,相当于传递的是一个副本,main方法里面的age并没有改变,因此输出的结果 age还是20,属于值传递
changeValue2的执行过程
因为Person是属于对象,传递的是内存地址,当执行changeValue2的时候,会改变内存中的Person的值,属于引用传递,两个指针都是指向同一个地址
changeValue3的执行过程
String不属于基本数据类型,但是为什么执行完成后,还是abc呢?
这是因为String的特殊性,当我们执行String str = "abc"的时候,它会把 abc 放入常量池中
当我们执行changeValue3的时候,会重新新建一个xxx,并没有销毁abc,然后指向xxx,然后最后我们输出的是main中的引用,还是指向的abc,因此最后输出结果还是abc
6.Java的锁
6.1 公平锁和非公平锁
- 公平锁:是指多个线程按照申请锁的顺序来获取锁,类似于排队买饭,先来后到,先来先服务,就是公平的,也就是队列
- 非公平锁:是指多个线程获取锁的顺序,并不是按照申请锁的顺序,有可能申请的线程比先申请的线程优先获取锁,在高并发环境下,有可能造成优先级翻转,或者饥饿的线程(也就是某个线程一直得不到锁)
创建:
并发包中ReentrantLock的创建可以指定析构函数的boolean类型来得到公平锁或者非公平锁,默认是非公平锁
/**
* 创建一个可重入锁,true 表示公平锁,false 表示非公平锁。默认非公平锁
*/
Lock lock = new ReentrantLock(true);
两者区别:
公平锁:就是很公平,在并发环境中,每个线程在获取锁时会先查看此锁维护的等待队列,如果为空,或者当前线程是等待队列中的第一个,就占用锁,否者就会加入到等待队列中,以后安装FIFO的规则从队列中取到自己
非公平锁: 非公平锁比较粗鲁,上来就直接尝试占有锁,如果尝试失败,就再采用类似公平锁那种方式。
6.2 可重入锁和递归锁ReentrantLock
概念:
可重入锁就是递归锁
**指的是同一线程外层函数获得锁之后,内层递归函数仍然能获取到该锁的代码,在同一线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。**也就是说:线程可以进入任何一个它已经拥有的锁所同步的代码块
ReentrantLock / Synchronized 就是一个典型的可重入锁
代码:
可重入锁就是,在一个method1方法中加入一把锁,方法2也加锁了,那么他们拥有的是同一把锁
public synchronized void method1() {
method2();
}
public synchronized void method2() {
}
也就是说我们只需要进入method1后,那么它也能直接进入method2方法,因为他们所拥有的锁,是同一把。
作用:
可重入锁的最大作用就是避免死锁
可重入锁验证:
1.Synchronized
/**
* 可重入锁(也叫递归锁)
* 指的是同一线程外层函数获得锁之后,内层递归函数仍然能获取到该锁的代码,在同一线程在外层方法获取锁的时候,在进入内层方法会自动获取锁
*
* 也就是说:`线程可以进入任何一个它已经拥有的锁所同步的代码块`
*/
class Phone {
//发短信
public synchronized void sendSMS() throws Exception{
System.out.println(Thread.currentThread().getName() + "\t invoked sendSMS()");
// 在同步方法中,调用另外一个同步方法
sendEmail();
}
//发邮件
public synchronized void sendEmail() throws Exception{
System.out.println(Thread.currentThread().getId() + "\t invoked sendEmail()");
}
}
public class ReenterLockDemo {
public static void main(String[] args) {
Phone phone = new Phone();
// 两个线程操作资源列
new Thread(() -> {
try {
phone.sendSMS();
} catch (Exception e) {
e.printStackTrace();
}
}, "t1").start();
new Thread(() -> {
try {
phone.sendSMS();
} catch (Exception e) {
e.printStackTrace();
}
}, "t2").start();
}
}
在这里,我们编写了一个资源类phone,拥有两个加了synchronized的同步方法,分别是sendSMS 和 sendEmail,我们在sendSMS方法中,调用sendEmail。最后在主线程同时开启了两个线程进行测试,最后得到的结果为:

这就说明当 t1 线程进入sendSMS的时候,拥有了一把锁,同时t2线程无法进入,直到t1线程拿着锁,执行了sendEmail 方法后,才释放锁,这样t2才能够进入

2.ReentrantLock
/**
* 资源类
*/
class Phone implements Runnable{
Lock lock = new ReentrantLock();
/**
* set进去的时候,就加锁,调用set方法的时候,能否访问另外一个加锁的set方法
*/
public void getLock() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "\t get Lock");
setLock();
} finally {
lock.unlock();
}
}
public void setLock() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "\t set Lock");
} finally {
lock.unlock();
}
}
@Override
public void run() {
getLock();
}
}
public class ReenterLockDemo {
public static void main(String[] args) {
Phone phone = new Phone();
/**
* 因为Phone实现了Runnable接口
*/
Thread t3 = new Thread(phone, "t3");
Thread t4 = new Thread(phone, "t4");
t3.start();
t4.start();
}
}
现在我们使用ReentrantLock进行验证,首先资源类实现了Runnable接口,重写Run方法,里面调用get方法,get方法在进入的时候,就加了锁
public void getLock() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "\t get Lock");
setLock();
} finally {
lock.unlock();
}
}
然后在方法里面,又调用另外一个加了锁的setLock方法
public void setLock() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "\t set Lock");
} finally {
lock.unlock();
}
}
最后输出结果我们能发现,结果和加synchronized方法是一致的,都是在外层的方法获取锁之后,线程能够直接进入里层

当我们在getLock方法加两把锁会是什么情况呢? (阿里面试)
public void getLock() {
lock.lock();
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "\t get Lock");
setLock();
} finally {
lock.unlock();
lock.unlock();
}
}
最后得到的结果也是一样的,因为里面不管有几把锁,其它他们都是同一把锁,也就是说用同一个钥匙都能够打开
当我们在getLock方法加两把锁,但是只解一把锁会出现什么情况呢?
public void getLock() {
lock.lock();
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "\t get Lock");
setLock();
} finally {
lock.unlock();
}
}
这个时候,程序会卡死
6.3 自旋锁
自旋锁:spinlock,是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU
原来提到的比较并交换,底层使用的就是自旋,自旋就是多次尝试,多次访问,不会阻塞的状态就是自旋。
优缺点:
* 优点:循环比较获取直到成功为止,没有类似于wait的阻塞
* 缺点:当不断自旋的线程越来越多的时候,会因为执行while循环不断的消耗CPU资源
手写自旋锁:
通过CAS操作完成自旋锁,A线程先进来调用myLock方法自己持有锁5秒,B随后进来发现当前有线程持有锁,不是null,所以只能通过自旋等待,直到A释放锁后B随后抢到
/**
* 手写自旋锁
*
* @author HiJ
* @create 2022-07-31 16:44
*/
public class SpinLockDemo {
//原子引用线程
AtomicReference<Thread> atomicReference = new AtomicReference<>();
public void myLock() {
// 获取当前进来的线程
Thread thread = Thread.currentThread();
System.out.println(Thread.currentThread().getName() + "\t come in ");
// 开始自旋,期望值是null,更新值是当前线程,如果是null,则更新为当前线程,否者自旋
while (!atomicReference.compareAndSet(null, thread)) {
}
}
//解锁
public void myUnLock() {
// 获取当前进来的线程
Thread thread = Thread.currentThread();
// 自己用完了后,把atomicReference变成null
atomicReference.compareAndSet(thread, null);
System.out.println(Thread.currentThread().getName() + "\t invoked myUnlock()");
}
public static void main(String[] args) {
SpinLockDemo spinLockDemo = new SpinLockDemo();
// 启动t1线程,开始操作
new Thread(()->{
// 开始占有锁
spinLockDemo.myLock();
try {TimeUnit.SECONDS.sleep(5);} catch (InterruptedException e) {e.printStackTrace();}
// 开始释放锁
spinLockDemo.myUnLock();
},"t1").start();
// 让main线程暂停1秒,使得t1线程,先执行
try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}
// 1秒后,启动t2线程,开始占用这个锁
new Thread(() -> {
// 开始占有锁
spinLockDemo.myLock();
try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}
// 开始释放锁
spinLockDemo.myUnLock();
}, "t2").start();
}
}

首先输出的是 t1 come in
然后1秒后,t2线程启动,发现锁被t1占有,所有不断的执行 compareAndSet方法,来进行比较,直到t1释放锁后,也就是5秒后,t2成功获取到锁,然后释放
6.4 读写锁
概念:
独占锁:指该锁一次只能被一个线程所持有。对ReentrantLock和Synchronized而言都是独占锁
共享锁:指该锁可以被多个线程锁持有
对ReentrantReadWriteLock其读锁是共享,其写锁是独占
写的时候只能一个人写,但是读的时候,可以多个人同时读
为什么会有写锁和读锁?
原来我们使用ReentrantLock创建锁的时候,是独占锁,也就是说一次只能一个线程访问,但是有一个读写分离场景,读的时候想同时进行,因此原来独占锁的并发性就没这么好了,因为读锁并不会造成数据不一致的问题,因此可以多个人共享读
多个线程 同时读一个资源类没有任何问题,所以为了满足并发量,读取共享资源应该可以同时进行,但是如果一个线程想去写共享资源,就不应该再有其它线程可以对该资源进行读或写
* 读-读:能共存
* 读-写:不能共存
* 写-写:不能共存
代码实现:
/**读写锁
* @author HiJ
* @create 2022-07-31 18:24
*/
public class ReadWriteLockDemo {
public static void main(String[] args) {
MyCache myCache = new MyCache();
// 线程操作资源类,5个线程写
for (int i = 1; i <= 5; i++) {
// lambda表达式内部必须是final
final int tempInt = i;
new Thread(()-> myCache.put(tempInt + "", tempInt + ""),String.valueOf(i)).start();
}
// 线程操作资源类, 5个线程读
for (int i = 1; i <= 5; i++) {
// lambda表达式内部必须是final
final int tempInt = i;
new Thread(()-> myCache.get(tempInt + ""),String.valueOf(i)).start();
}
}
}
//资源类
class MyCache {
private volatile Map<String, Object> map = new HashMap<>();
// private Lock lock = null;
//定义写操作
//满足:原子 + 独占
public void put(String key, Object value) {
System.out.println(Thread.currentThread().getName() + "\t 正在写入:" + key);
// 模拟网络拥堵,延迟0.3秒
try {TimeUnit.MILLISECONDS.sleep(300);} catch (InterruptedException e) {e.printStackTrace();}
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "\t 写入完成");
}
public void get(String key) {
System.out.println(Thread.currentThread().getName() + "\t 正在读取:");
// 模拟网络拥堵,延迟0.3秒
try {TimeUnit.MILLISECONDS.sleep(300);} catch (InterruptedException e) {e.printStackTrace();}
Object value = map.get(key);
System.out.println(Thread.currentThread().getName() + "\t 读取完成:" + value);
}
}
分别创建5个线程写入缓存,5个线程读取缓存,最后运行结果:

可以看到,在写入的时候,写操作都没其它线程打断了,这就造成了,还没写完,其它线程又开始写,这样就造成数据不一致
解决方法:
上面的代码是没有加锁的,这样就会造成线程在进行写入操作的时候,被其它线程频繁打断,从而不具备原子性,这个时候,就需要用到读写锁来解决了
/**
* 创建一个读写锁
* 它是一个读写融为一体的锁,在使用的时候,需要转换
*/
private ReentrantReadWriteLock rwLock = new ReentrantReadWriteLock();
当我们在进行写操作的时候,就需要转换成写锁
// 创建一个写锁
rwLock.writeLock().lock();
// 写锁 释放
rwLock.writeLock().unlock();
当们在进行读操作的时候,在转换成读锁
// 创建一个读锁
rwLock.readLock().lock();
// 读锁 释放
rwLock.readLock().unlock();
这里的读锁和写锁的区别在于,写锁一次只能一个线程进入,执行写操作,而读锁是多个线程能够同时进入,进行读取的操作
完整代码:
/**读写锁
* @author HiJ
* @create 2022-07-31 18:24
*/
public class ReadWriteLockDemo {
public static void main(String[] args) {
MyCache myCache = new MyCache();
// 线程操作资源类,5个线程写
for (int i = 1; i <= 5; i++) {
// lambda表达式内部必须是final
final int tempInt = i;
new Thread(()-> myCache.put(tempInt + "", tempInt + ""),String.valueOf(i)).start();
}
// 线程操作资源类, 5个线程读
for (int i = 1; i <= 5; i++) {
// lambda表达式内部必须是final
final int tempInt = i;
new Thread(()-> myCache.get(tempInt + ""),String.valueOf(i)).start();
}
}
}
//资源类
class MyCache {
private volatile Map<String, Object> map = new HashMap<>();
private ReentrantReadWriteLock rwLock = new ReentrantReadWriteLock();
//定义写操作
//满足:原子 + 独占
public void put(String key, Object value) {
rwLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "\t 正在写入:" + key);
// 模拟网络拥堵,延迟0.3秒
try {TimeUnit.MILLISECONDS.sleep(300);} catch (InterruptedException e) {e.printStackTrace();}
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "\t 写入完成");
}catch (Exception e) {
e.printStackTrace();
} finally {
rwLock.writeLock().unlock();
}
}
public void get(String key) {
rwLock.readLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "\t 正在读取:");
// 模拟网络拥堵,延迟0.3秒
try {TimeUnit.MILLISECONDS.sleep(300);} catch (InterruptedException e) {e.printStackTrace();}
Object value = map.get(key);
System.out.println(Thread.currentThread().getName() + "\t 读取完成:" + value);
}catch (Exception e) {
e.printStackTrace();
} finally {
rwLock.readLock().unlock();
}
}
/**
* 清空缓存
*/
public void clean() {
map.clear();
}
}
运行结果:

从运行结果我们可以看出,写入操作是一个一个线程进行执行的,并且中间不会被打断,而读操作的时候,是同时5个线程进入,然后并发读取操作
6.5 Synchronized无法禁止指令重排,却能保证有序性
为了进一步提升计算机各方面能力,在硬件层面做了很多优化,如处理器优化和指令重排等,但是这些技术的引入就会导致有序性问题。
先解释什么是有序性问题,也知道是什么原因导致的有序性问题
我们也知道,最好的解决有序性问题的办法,就是禁止处理器优化和指令重排,就像volatile中使用内存屏障一样。
表明你知道啥是指令重排,也知道他的实现原理
但是,虽然很多硬件都会为了优化做一些重排,但是在Java中,不管怎么排序,都不能影响单线程程序的执行结果。这就是as-if-serial语义,所有硬件优化的前提都是必须遵守as-if-serial语义。
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器,runtime 和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。as-if-serial语义使单线程程序员无需担心重排序会 干扰他们,也无需担心内存可见性问题。
重点!解释下什么是as-if-serial语义,因为这是这道题的第一个关键词,答上来就对了一半了
再说下synchronized,他是Java提供的锁,可以通过他对Java中的对象加锁,并且他是一种排他的、可重入的锁。
所以,当某个线程执行到一段被synchronized修饰的代码之前,会先进行加锁,执行完之后再进行解锁。在加锁之后,解锁之前,其他线程是无法再次获得锁的,只有这条加锁线程可以重复获得该锁。
介绍synchronized的原理,这是本题的第二个关键点,到这里基本就可以拿满分了。
synchronized通过排他锁的方式就保证了同一时间内,被synchronized修饰的代码是单线程执行的。所以呢,这就满足了as-if-serial语义的一个关键前提,那就是单线程,因为有as-if-serial语义保证,单线程的有序性就天然存在了。
7.CountDownLatch、CyclicBarrier、Semaphore的使用
7.1 CountDownLatch
概念:
让一些线程阻塞直到另一些线程完成一系列操作才被唤醒
CountDownLatch主要有两个方法,当一个或多个线程调用await方法时,调用线程就会被阻塞。其它线程调用CountDown方法会将计数器减1(调用CountDown方法的线程不会被阻塞),当计数器的值变成零时,因调用await方法被阻塞的线程会被唤醒,继续执行
场景:
现在有这样一个场景,假设一个自习室里有7个人,其中有一个是班长,班长的主要职责就是在其它6个同学走了后,关灯,锁教室门,然后走人,因此班长是需要最后一个走的,那么有什么方法能够控制班长这个线程是最后一个执行,而其它线程是随机执行的
解决方案:
这个时候就用到了CountDownLatch,计数器了。我们一共创建6个线程,然后计数器的值也设置成6
// 计数器
CountDownLatch countDownLatch = new CountDownLatch(6);
然后每次学生线程执行完,就让计数器的值减1
for (int i = 0; i <= 6; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t 上完自习,离开教室");
countDownLatch.countDown();
}, String.valueOf(i)).start();
}
最后我们需要通过CountDownLatch的await方法来控制班长主线程的执行,这里 countDownLatch.await()可以想成是一道墙,只有当计数器的值为0的时候,墙才会消失,主线程才能继续往下执行
countDownLatch.await();
System.out.println(Thread.currentThread().getName() + "\t 班长最后关门");
不加CountDownLatch的执行结果,我们发现main线程提前已经执行完成了
1 上完自习,离开教室
0 上完自习,离开教室
main 班长最后关门
2 上完自习,离开教室
3 上完自习,离开教室
4 上完自习,离开教室
5 上完自习,离开教室
6 上完自习,离开教室
引入CountDownLatch后的执行结果,我们能够控制住main方法的执行,这样能够保证前提任务的执行
0 上完自习,离开教室
2 上完自习,离开教室
4 上完自习,离开教室
1 上完自习,离开教室
5 上完自习,离开教室
6 上完自习,离开教室
3 上完自习,离开教室
main 班长最后关门
完整代码:
public class CountDownLatchDemo {
public static void main(String[] args) throws InterruptedException {
// 计数器
CountDownLatch countDownLatch = new CountDownLatch(6);
for (int i = 0; i <= 6; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t 上完自习,离开教室");
countDownLatch.countDown();
}, String.valueOf(i)).start();
}
countDownLatch.await();
System.out.println(Thread.currentThread().getName() + "\t 班长最后关门");
}
}
7.2 CyclicBarrier
概念:
和CountDownLatch相反,需要集齐七颗龙珠,召唤神龙。也就是做加法,开始是0,加到某个值的时候就执行
CyclicBarrier的字面意思就是可循环(cyclic)使用的屏障(Barrier)。它要求做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活,线程进入屏障通过CyclicBarrier的await方法
案例:
集齐7个龙珠,召唤神龙的Demo,我们需要首先创建CyclicBarrier
/**
* 定义一个循环屏障,参数1:需要累加的值,参数2 需要执行的方法
*/
CyclicBarrier cyclicBarrier = new CyclicBarrier(7, () -> {
System.out.println("召唤神龙");
});
然后同时编写七个线程,进行龙珠收集,但一个线程收集到了的时候,我们需要让他执行await方法,等待到7个线程全部执行完毕后,我们就执行原来定义好的方法
for (int i = 0; i < 7; i++) {
final Integer tempInt = i;
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t 收集到 第" + tempInt + "颗龙珠");
try {
// 先到的被阻塞,等全部线程完成后,才能执行方法
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}, String.valueOf(i)).start();
}
完整代码:
public class CyclicBarrierDemo {
public static void main(String[] args) {
/**
* 定义一个循环屏障,参数1:需要累加的值,参数2 需要执行的方法
*/
CyclicBarrier cyclicBarrier = new CyclicBarrier(7, () -> {
System.out.println("召唤神龙");
});
for (int i = 0; i < 7; i++) {
final Integer tempInt = i;
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t 收集到 第" + tempInt + "颗龙珠");
try {
// 先到的被阻塞,等全部线程完成后,才能执行方法
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}, String.valueOf(i)).start();
}
}
}
7.3 Semaphore
概念:
信号量主要用于两个目的
* 一个是用于共享资源的互斥使用
* 另一个用于并发线程数的控制
代码:
我们模拟一个抢车位的场景,假设一共有6个车,3个停车位
那么我们首先需要定义信号量为3,也就是3个停车位
/**
* 初始化一个信号量为3,默认是false 非公平锁, 模拟3个停车位
*/
Semaphore semaphore = new Semaphore(3, false);
然后我们模拟6辆车同时并发抢占停车位,但第一个车辆抢占到停车位后,信号量需要减1
// 代表一辆车,已经占用了该车位
semaphore.acquire(); // 抢占
同时车辆假设需要等待3秒后,释放信号量
// 每个车停3秒
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
最后车辆离开,释放信号量
// 释放停车位
semaphore.release();
完整代码:
public class SemaphoreDemo {
public static void main(String[] args) {
/**
* 初始化一个信号量为3,默认是false 非公平锁, 模拟3个停车位
*/
Semaphore semaphore = new Semaphore(3, false);
// 模拟6部车
for (int i = 0; i < 6; i++) {
new Thread(() -> {
try {
// 代表一辆车,已经占用了该车位
semaphore.acquire(); // 抢占
System.out.println(Thread.currentThread().getName() + "\t 抢到车位");
// 每个车停3秒
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "\t 离开车位");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放停车位
semaphore.release();
}
}, String.valueOf(i)).start();
}
}
}
运行结果:
0 抢到车位
2 抢到车位
1 抢到车位
2 离开车位
1 离开车位
3 抢到车位
0 离开车位
4 抢到车位
5 抢到车位
4 离开车位
3 离开车位
5 离开车位















 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









