







MapReduce
入门案例练习
- 统计文件中每一个单词出现的次数(文件:words.txt)
- 对IP去重(文件:ip.txt)
组件
序列化 - Writable
-
统计每一个人花费的上行流量、下行流量以及总流量(文件:flow.txt)
-
在MapReduce中,各个节点之间基本上都是通过RPC的方式来进行调用,也因此要求传输的数据必须被序列化
-
Hadoop并没有使用Java的原生序列化机制,底层默认采用了AVRO来进行的序列化。在AVRO的基础上,MapReduce进行了封装,从而简化了序列化操作 - 让需要被序列化的对象对应的类实现接口
Writable,覆盖其中的write和readFields方法即可 -
由于AVRO的限制,所以要求被序列化的类中必须有无参构造,同时不允许属性值为
null -
MapReduce针对常用的类都提供了序列化形式
Java类 序列化类 Byte ByteWritable Short ShortWritable Integer IntWritable Long LongWritable Float FloatWritable Double DoubleWritable Boolean BooleanWritable String Text Null NullWritable Array ArrayWritable Map MapWritable
分区 - Partitioner
-
按地区,统计每一个人花费的总流量(文件:flow.txt)
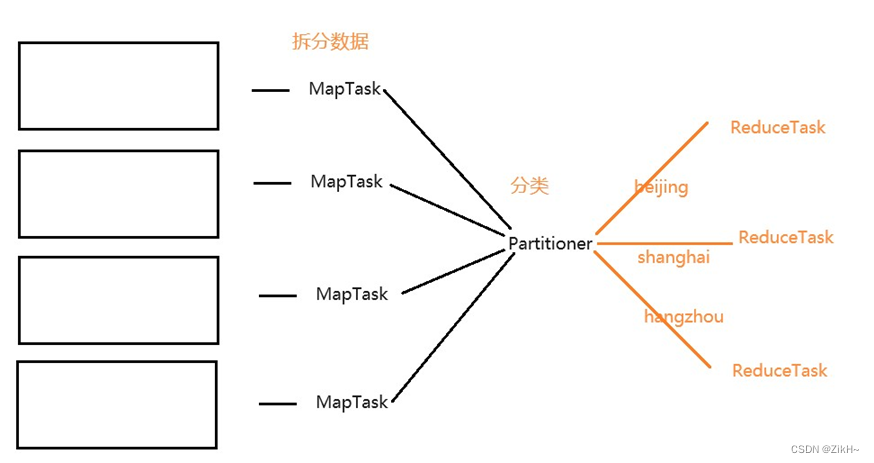
-
Partitioner(分区)的作用是对数据进行分类
-
默认情况下,MapReduce中,只有一个1个分区,所以也只有1个ReduceTask。如果进行了分类,那么就需要指定多个ReduceTask。每一个分区都需要对应一个ReduceTask,每一个ReduceTask都会产生一个结果文件 - 分区的数量决定了ReduceTask的数量,ReduceTask的数量决定了结果文件的数量
-
在MapReduce中,会对分区进行编号,编号是从0开始的
排序 - Comparable
- 在MapReduce中,无论逻辑是否需要,默认会对MapTask的输出的键进行排序,也因此要求放在Mapper输出的键对应的类必须实现
Comparable接口。考虑到还要进行序列化,需要实现WritableComparable接口 - 如果需要指定自己的排序规则,那么需要定义类实现
WritableComparable接口 - 案例:先按照月份升序排序,如果是同一个月,那么按照利润降序排序(文件:profit.txt)
合并 - Combiner
-
Combiner是在不改变结果的前提下,减少ReduceTask的计算条数

-
如果需要使用Combiner,只需要在入口类中添加
job.setCombinerClass(XXXReducer.class); -
可以传递结果的运算,可以使用Combiner,例如求和、求积、去重、取最值等;不能传递结果的运算,不能使用Combiner,例如求平均值等
















 1451
1451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











